从 IBM Netezza 迁移
本文档提供了有关从 Netezza 迁移到 BigQuery 的概要指南。介绍了 Netezza 和 BigQuery 之间的基本架构差异,并介绍了 BigQuery 提供的其他功能。此外,还介绍了如何重新设计现有的数据模型以及提取、转换和加载 (ETL) 流程,以最大限度地利用 BigQuery 的优势。
本文档适用于希望从 Netezza 迁移到 BigQuery 并解决迁移过程中的技术挑战的企业架构师、DBA、应用开发者和 IT 安全专业人员。本文档详细介绍了迁移过程的以下阶段:
- 导出数据
- 提取数据
- 利用第三方工具
您还可以使用批量 SQL 转换来批量迁移 SQL 脚本,或使用交互式 SQL 转换来转换临时查询。两个预览版的工具都支持 IBM Netezza SQL/NZPLSQL。
架构比较
Netezza 是一个强大的系统,可帮助您存储和分析大量数据。但是,Netezza 这样的系统需要在硬件、维护和许可方面进行大量投资。由于节点管理、每个来源的数据量和归档费用等方面的挑战,可能难以扩容。使用 Netezza 时,存储和处理容量受硬件设备限制。当达到最大利用率时,扩展设备容量的过程会非常复杂,有时甚至不可能实现。
而使用 BigQuery 时,您不必管理基础架构,也不需要数据库管理员。BigQuery 是一个全代管式 PB 级无服务器数据仓库,可在几十秒内扫描数十亿行,而不使用索引。由于 BigQuery 共享 Google 的基础架构,因此可以并行处理每个查询,并在数以万计的服务器上同时运行查询。以下核心技术使 BigQuery 有别于其他产品:
- 列式存储:数据按列(而不是按行)存储,从而实现极高的压缩率和扫描吞吐量。
- 树形架构:系统在几秒钟内通过数以千计的机器调度查询并汇总结果。
Netezza 架构
Netezza 是具有软件数据抽象层的硬件加速设备。数据抽象层管理设备中的数据分布,通过在底层 CPU 和 FPGA 之间分配数据处理来优化查询。
Netezza TwinFin 和 Striper 模型已于 2019 年 6 月停止提供支持。
下图显示了 Netezza 中的数据抽象层:
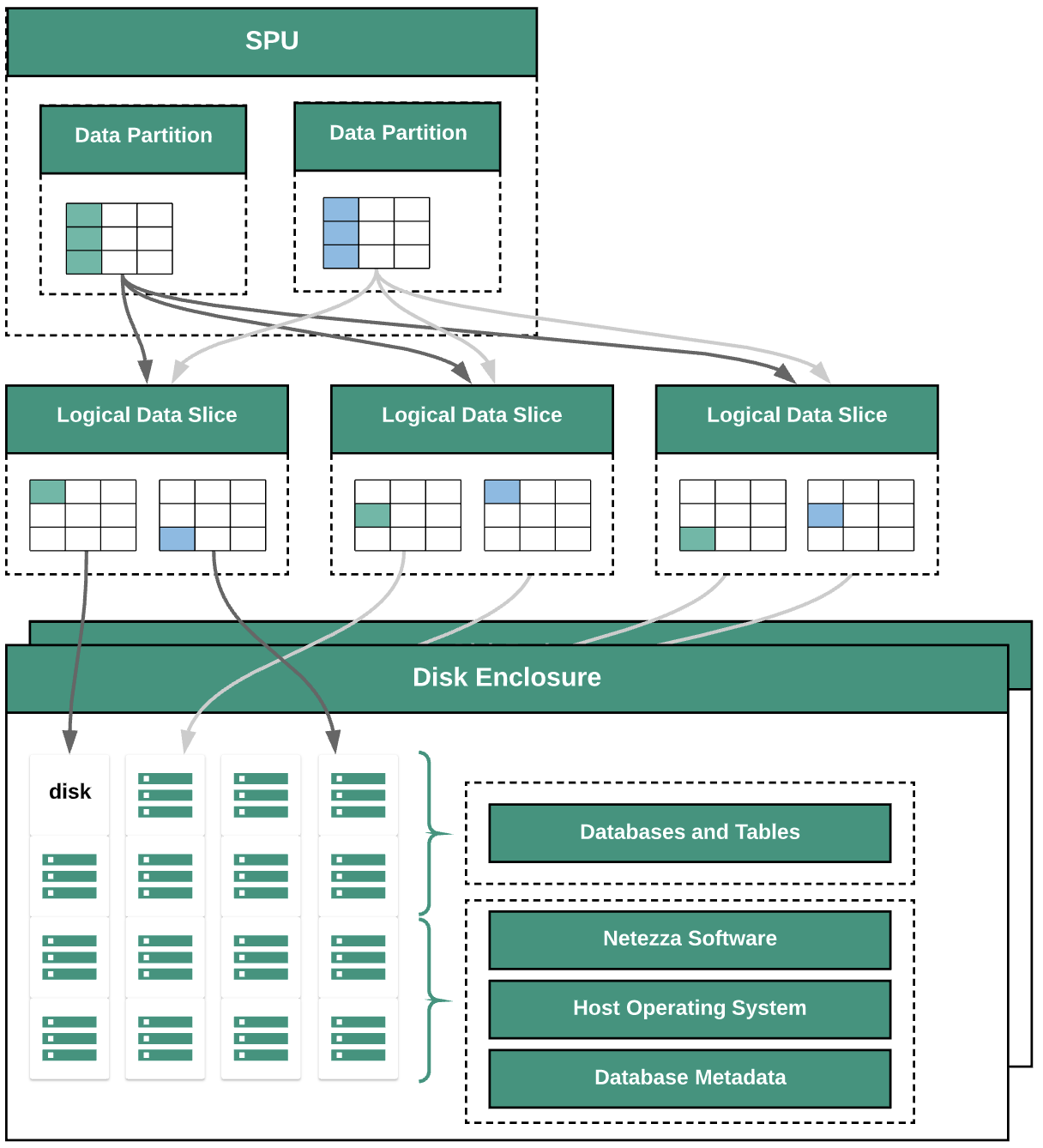
该图表展示了以下数据抽象层:
- 磁盘柜。设备内装载磁盘的物理空间。
- 磁盘。磁盘柜内的物理驱动器,存储数据库和表。
- 数据切片。保存在磁盘上的数据的逻辑表示形式。数据使用分布键分布在数据切片中。您可以使用
nzds命令监控数据切片的状态。 - 数据分区。由特定代码段处理单元 (SPU) 管理的数据切片的逻辑表示形式。每个 SPU 都拥有一个或多个数据分区,其中包含查询期间 SPU 负责处理的用户数据。
所有系统组件都通过网络架构连接。Netezza 设备基于 IP 地址运行自定义协议。
BigQuery 架构
BigQuery 是一种全代管式企业数据仓库,可帮助您使用机器学习、地理空间分析和商业智能等内置功能管理和分析数据。如需了解详情,请参阅什么是 BigQuery?。
BigQuery 会处理存储和计算,以便为分析查询提供持久数据存储和高性能响应。如需了解详情,请参阅 BigQuery 说明。
如需了解 BigQuery 价格,请参阅了解 BigQuery 的快速扩缩和简单价格。
迁移前
为确保数据仓库迁移成功,请在项目时间轴的早期阶段开始规划迁移策略。如需了解如何系统地规划迁移工作,请参阅迁移的内容和方式:迁移框架。
BigQuery 容量规划
BigQuery 中的分析吞吐量以槽为单位衡量。BigQuery 槽是执行 SQL 查询所需的计算、RAM 和网络吞吐量的 Google 专有单位。BigQuery 会根据查询大小和复杂程度,自动计算每个查询所需的槽数。
如需在 BigQuery 中运行查询,请选择以下价格模式之一:
- 按需。默认价格模式,您需要为每个查询处理的字节数付费。
- 基于容量的价格。 您要购买槽(虚拟 CPU)。购买槽时,您将购买可以用于运行查询的专用处理容量。槽的使用承诺方案如下:
- 每年。承诺使用 365 天。
- 3 年。承诺使用 365*3 天。
BigQuery 槽与 Netezza 的 SPU 具有一些相似之处,例如 CPU、内存和数据处理;但它们并不代表相同的度量单位。Netezza SPU 具有与底层硬件组件的固定映射,而 BigQuery 槽表示用于执行查询的虚拟 CPU。为了帮助估算槽,我们建议您设置使用 Cloud Monitoring 监控 BigQuery 和使用 BigQuery 分析审核日志。如需直观呈现 BigQuery 槽利用率,您还可以使用 Looker 数据洞察或 Looker 等工具。定期监控和分析槽利用率可帮助您估算组织在 Google Cloud上发展时所需的总槽数。
例如,假设您最初预留 2,000 个 BigQuery 槽以同时运行 50 个中等复杂度查询。如果查询的运行时间始终超过几小时,并且信息中心显示槽利用率较高,则您的查询可能未优化,或者您可能需要更多 BigQuery 槽来帮助支持工作负载。如需通过每年或三年承诺自行购买槽,您可以使用 Google Cloud 控制台或 bq 命令行工具创建 BigQuery 预留。如果您是通过签署线下协议基于容量购买,您的方案可能会与此处所述的详情有所不同。
如需了解如何控制 BigQuery 上的存储和查询处理费用,请参阅优化工作负载。
Google Cloud中的安全性
以下部分介绍了常见的 Netezza 安全控制措施以及您可以如何帮助保护 Google Cloud 环境中的数据仓库。
身份和访问权限管理
Netezza 数据库包含一组完全集成的系统访问权限控制功能,可让用户访问已获授权的资源。
通过管理可登录操作系统的 Linux 用户账号,可以通过连接到 Netezza 设备的网络来控制对 Netezza 的访问权限。使用能够与系统建立 SQL 连接的 Netezza 数据库用户账号来管理对 Netezza 数据库、对象和任务的访问权限。
BigQuery 使用 Google 的 Identity and Access Management (IAM) 服务来管理对资源的访问权限。BigQuery 中提供的资源类型包括组织、项目、数据集、表和视图。在 IAM 政策层次结构中,数据集是项目的子资源。表从其所属的数据集继承权限。
如需授予对某项资源的访问权限,您需要为用户、群组或服务账号分配一个或多个角色。组织角色和项目角色控制运行作业或管理项目的权限,而数据集角色控制查看或修改项目内数据的权限。
IAM 提供以下类型的角色:
- 预定义角色。支持常见使用场景和访问权限控制模式。
- 基本角色。包括 Owner、Editor 和 Viewer 角色。基本角色针对特定服务提供精细访问权限,并由 Google Cloud管理。
- 自定义角色。根据用户指定的权限列表提供精细访问权限。
如果您向某用户同时分配了预定义角色和基本角色,则授予的权限是每个角色所拥有权限的并集。
行级安全性
多级安全性是一种抽象安全模型,Netezza 使用该模型来定义规则,以控制用户对行安全表 (RST) 的访问权限。行安全表是行上带有安全标签的数据库表,用于过滤掉没有适当权限的用户。查询返回的结果因查询用户的权限而异。
如需在 BigQuery 中实现行级安全性,您可以使用授权视图和行级访问权限政策。如需详细了解如何设计和实现这些政策,请参阅 BigQuery 行级安全性简介。
数据加密
Netezza 设备使用自加密驱动器 (SED),可增强设备中存储的数据的安全性和保护。SED 会在数据写入磁盘时加密数据。每个磁盘都有一个磁盘加密密钥 (DEK),该加密密钥在出厂时设置并存储在磁盘上。磁盘使用 DEK 在数据写入时加密数据,然后在从磁盘读取数据时解密数据。对于读写数据的用户而言,磁盘的操作及其加密和解密是透明的。这种默认的加密和解密模式称为安全擦除模式。
在安全擦除模式下,您无需身份验证密钥或密码即可解密和读取数据。SED 提供更强的功能,当磁盘必须更改用途或出于支持或维修原因需要返回时,可以轻松快速地进行安全擦除。
Netezza 使用对称加密;如果您的数据是在字段级层加密的,则以下解密函数可以帮助您读取和导出数据:
varchar = decrypt(varchar text, varchar key [, int algorithm [, varchar IV]]); nvarchar = decrypt(nvarchar text, nvarchar key [, int algorithm[, varchar IV]]);
BigQuery 中存储的所有数据均为静态加密。如果您想自行控制加密,可为 BigQuery 使用客户管理的加密密钥 (CMEK)。使用 CMEK 时,您可以控制和管理 Cloud Key Management Service 中的密钥加密密钥,而不是由 Google 管理保护您数据的密钥加密密钥。如需了解详情,请参阅静态加密。
性能基准化分析
为了跟踪整个迁移过程的进度和改进,为当前 Netezza 环境建立基准性能非常重要。如需建立基准,请选择一组从使用方应用(如 Tableau 或 Cognos)捕获的代表性查询。
| 环境 | Netezza | BigQuery |
|---|---|---|
| 数据大小 | 大小 TB | - |
| 查询 1:名称(全表扫描) | mm:ss.ms | - |
| 查询 2:名称 | mm:ss.ms | - |
| 查询 3:名称 | mm:ss.ms | - |
| 总时长 | mm:ss.ms | - |
基础项目设置
在预配存储资源以迁移数据之前,您需要完成项目设置。
- 如需设置项目并在项目级层启用 IAM,请参阅 Google Cloud Well-Architected Framework。
- 如需设计基础资源以实现企业级云部署,请参阅 Google Cloud中的着陆区设计。
- 如需了解数据治理以及将本地数据仓库迁移到 BigQuery 时所需的控制措施,请参阅数据安全和治理概览。
网络连接
本地数据中心(运行 Netezza 实例)与 Google Cloud环境之间需要可靠且安全的网络连接。如需了解如何帮助确保连接安全,请参阅 BigQuery 中的数据治理简介。上传数据提取时,网络带宽可成为限制因素。如需了解如何满足数据转移要求,请参阅增加网络带宽。
支持的数据类型和属性
Netezza 数据类型与 BigQuery 数据类型不同。如需了解 BigQuery 数据类型,请参阅数据类型。如需查看 Netezza 和 BigQuery 数据类型之间的详细比较,请参阅 IBM Netezza SQL 转换指南。
SQL 比较
Netezza 数据 SQL 由 DDL、DML 和 Netezza 专用数据控制语言 (DCL) 组成,这些语言与 GoogleSQL 不同。GoogleSQL 符合 SQL 2011 标准,并且具有支持查询嵌套数据和重复数据的扩展。如果您使用的是 BigQuery 旧版 SQL,请参阅旧版 SQL 函数和运算符。如需查看 Netezza 和 BigQuery SQL 和函数之间的详细比较,请参阅 IBM Netezza SQL 转换指南。
为帮助迁移 SQL 代码,请使用批量 SQL 转换来批量迁移 SQL 代码,或使用交互式 SQL 转换来转换临时查询。
函数比较
了解 Netezza 函数如何映射到 BigQuery 函数是非常重要的。例如,Netezza Months_Between 函数输出一个小数,而 BigQuery DateDiff 函数输出一个整数。因此,您必须使用自定义 UDF 函数来输出正确的数据类型。如需详细了解 Netezza SQL 和 GoogleSQL 函数之间的比较,请参阅 IBM Netezza SQL 转换指南。
数据迁移
如需将数据从 Netezza 迁移到 BigQuery,您需要将数据从 Netezza 导出,在 Google Cloud上转移和暂存数据,然后将数据加载到 BigQuery 中。本部分介绍数据迁移过程的概要步骤。如需详细了解数据迁移过程,请参阅架构和数据迁移过程。如需查看 Netezza 和 BigQuery 支持的数据类型之间的详细比较,请参阅 IBM Netezza SQL 转换指南。
从 Netezza 导出数据
如需浏览 Netezza 数据库表中的数据,我们建议您以 CSV 格式导出到外部表。如需了解详情,请参阅将数据卸载到远程客户端系统。您还可以使用 Informatica(或自定义 ETL)等第三方系统和 JDBC/ODBC 连接器读取数据以生成 CSV 文件。
Netezza 仅支持为每个表导出未压缩的平面文件 (CSV)。但是,如果您要导出大型表,则未压缩的 CSV 可能会变得非常大。如果可能,请考虑将 CSV 转换为架构感知格式(如 Parquet、Avro 或 ORC),这会生成较小的导出文件,且可靠性更高。如果 CSV 是唯一的可用格式,我们建议您压缩导出文件以减小文件大小,然后再上传到 Google Cloud。减小文件大小有助于加快上传速度并提高转移可靠性。如果将文件转移到 Cloud Storage,则可以在 gcloud storage cp 命令中使用 --gzip-local 标志,此标志会在上传文件之前进行压缩。
数据转移和暂存
导出数据后,需要将其转移并暂存在Google Cloud中。有几种转移数据的选项,具体取决于您转移的数据量和可用的网络带宽。如需了解详情,请参阅架构和数据转移概览。
使用 Google Cloud CLI 时,您可以自动并行执行到 Cloud Storage 的文件转移。请将文件大小限制为 4 TB(未压缩),以更快地加载到 BigQuery 中。但是,您必须事先导出架构。这是使用分区和聚簇来优化 BigQuery 的好机会。
使用 gcloud storage bucket create 创建用于存储导出数据的暂存存储桶,并使用 gcloud storage cp 将数据导出文件转移到 Cloud Storage 存储桶。
gcloud CLI 会自动结合使用多线程和多处理来执行复制操作。
将数据加载到 BigQuery 中
将数据暂存到 Google Cloud上后,您可以通过多种方式将数据加载到 BigQuery 中。如需了解详情,请参阅将架构和数据加载到 BigQuery 中。
合作伙伴工具和支持
您可以在迁移过程中获取合作伙伴支持。为帮助迁移 SQL 代码,请使用批量 SQL 转换来批量迁移 SQL 代码。
许多 Google Cloud 合作伙伴还提供数据仓库迁移服务。 如需查看合作伙伴及其提供的解决方案的列表,请参阅与具备 BigQuery 专业知识的合作伙伴携手。
迁移后
数据迁移完成后,您可以开始优化Google Cloud 的使用以解决业务需求。这可能包括使用Google Cloud的探索和可视化工具为业务利益相关方获取数据洞见、优化性能不佳的查询,或开发项目来改善用户采用。
通过互联网连接到 BigQuery API
下图显示了外部应用如何使用 API 连接到 BigQuery:
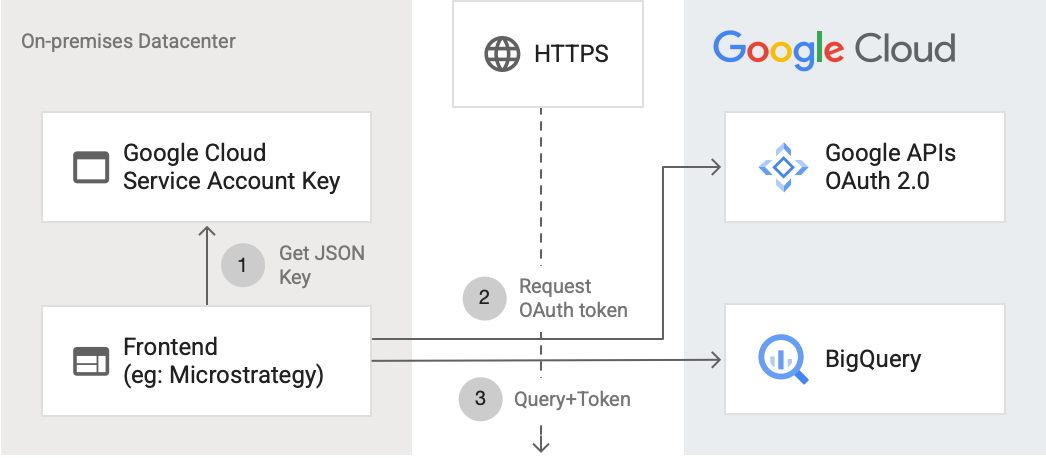
该图显示了以下步骤:
- 在 Google Cloud中,系统使用 IAM 权限创建服务账号。生成 JSON 格式的服务账号密钥,并复制到前端服务器(例如 MicroStrategy)。
- 前端读取密钥,并通过 HTTPS 向 Google API 请求 OAuth 令牌。
- 然后,前端将 BigQuery 请求以及令牌发送到 BigQuery。
如需了解详情,请参阅向 API 请求授权。
针对 BigQuery 进行优化
GoogleSQL 符合 SQL 2011 标准,并且具有支持查询嵌套和重复数据的扩展。优化 BigQuery 查询对于改善性能和响应时间至关重要。
将 BigQuery 中的 Months_Betbetween 函数替换为 UDF
Netezza 将一个月的天数视为 31。以下自定义 UDF 会重新创建具有更高准确性的 Netezza 函数,您可以通过查询调用该函数:
CREATE TEMP FUNCTION months_between(date_1 DATE, date_2 DATE) AS ( CASE WHEN date_1 = date_2 THEN 0 WHEN EXTRACT(DAY FROM DATE_ADD(date_1, INTERVAL 1 DAY)) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(date_1,date_2, MONTH) WHEN EXTRACT(DAY FROM date_1) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(DATE_ADD(date_1, INTERVAL -1 DAY), date_2, MONTH) + 1/31 ELSE date_diff(date_1, date_2, MONTH) - 1 + ((EXTRACT(DAY FROM date_1) + (31 - EXTRACT(DAY FROM date_2))) / 31) END );
迁移 Netezza 存储过程
如果您使用 ETL 工作负载中的 Netezza 存储过程来构建事实表,则必须将这些存储过程迁移到与 BigQuery 兼容的 SQL 查询。Netezza 使用 NZPLSQL 脚本语言来处理存储过程。NZPLSQL 基于 Postgres PL/pgSQL 语言。如需了解详情,请参阅 IBM Netezza SQL 转换指南。
模拟 Netezza ASCII 的自定义 UDF
以下适用于 BigQuery 的自定义 UDF 可纠正列中的编码错误:
CREATE TEMP FUNCTION ascii(X STRING) AS (TO_CODE_POINTS(x)[ OFFSET (0)]);
后续步骤
- 了解如何优化工作负载以优化整体性能和降低费用。
- 了解如何优化 BigQuery 存储。
- 参考 IBM Netezza SQL 转换指南。