本教程介绍了如何在 BigQuery ML 中使用 k-means 模型识别一组数据中的聚簇。
将数据分组为聚簇的 k-means 算法是非监督式机器学习的一种形式。监督式机器学习与预测分析有关,与此不同的是,非监督式机器学习与描述性分析有关。 非监督式机器学习可帮助您了解数据,以便您根据数据做出决策。
本教程中的查询使用地理空间分析中提供的地理位置函数。如需了解详情,请参阅地理空间分析简介。
本教程使用伦敦自行车租赁公共数据集。数据包括起始和停止时间戳、车站名称和骑行时长。
目标
本教程将指导您完成以下任务:- 检查用于训练模型的数据。
- 创建 k-means 聚簇模型。
- 使用 BigQuery ML 的聚簇可视化,解读生成的数据聚簇。
- 对 k-means 模型运行
ML.PREDICT函数,以预测一组自行车租赁站的可能聚簇。
费用
本教程使用 Google Cloud的可计费组件,包括以下组件:
- BigQuery
- BigQuery ML
如需了解 BigQuery 费用,请参阅 BigQuery 价格页面。
如需了解 BigQuery ML 费用,请参阅 BigQuery ML 价格。
准备工作
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- 新项目会自动启用 BigQuery。如需在现有项目中激活 BigQuery,请前往
Enable the BigQuery API.
如需创建数据集,您需要拥有
bigquery.datasets.createIAM 权限。如需创建模型,您需要以下权限:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
如需运行推理,您需要以下权限:
bigquery.models.getDatabigquery.jobs.create
所需权限
如需详细了解 BigQuery 中的 IAM 角色和权限,请参阅 IAM 简介。
创建数据集
创建 BigQuery 数据集以存储 k-means 模型:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在探索器窗格中,点击您的项目名称。
点击 查看操作 > 创建数据集。
在创建数据集页面上,执行以下操作:
在数据集 ID 部分,输入
bqml_tutorial。在位置类型部分,选择多区域,然后选择 EU (multiple regions in European Union)(欧盟[欧盟的多个区域])。
伦敦自行车租赁公共数据集存储在
EU多区域。数据集必须位于同一位置。保持其余默认设置不变,然后点击创建数据集。

检查训练数据
检查您将用于训练 k-means 模型的数据。在本教程中,您根据以下特性为自行车站划分聚簇:
- 租赁时长
- 每天的行程数量
- 与市中心的距离
SQL
此查询提取有关自行车租赁的数据(包括 start_station_name 和 duration 列),并将此数据与车站信息联接。其中包括创建一个包含车站距离市中心的计算列。然后,查询会在 stationstats 列中计算车站的特性(包括平均骑行时长和行程数量),以及计算出的 distance_from_city_center 列。
请按照以下步骤检查训练数据:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
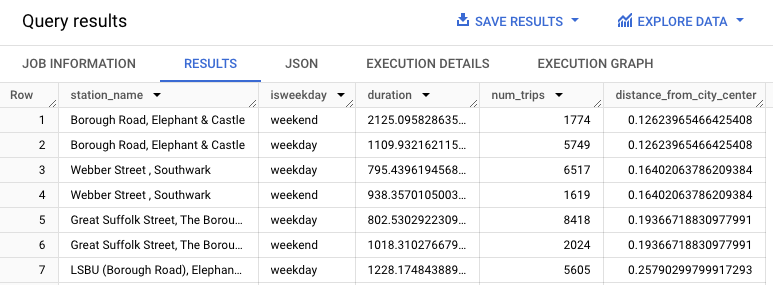
WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * FROM stationstats ORDER BY distance_from_city_center ASC;
结果应如下所示:
BigQuery DataFrame
在尝试此示例之前,请按照《BigQuery 快速入门:使用 BigQuery DataFrames》中的 BigQuery DataFrames 设置说明进行操作。如需了解详情,请参阅 BigQuery DataFrames 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置 ADC。
创建 k-means 模型
使用伦敦自行车租赁训练数据创建 k-means 模型。
SQL
在以下查询中,CREATE MODEL 语句指定要使用的聚簇数量为 4。在 SELECT 语句中,EXCEPT 子句不包括 station_name 列,因为此列不包含特征。此查询为每个 station_name 创建一个唯一行,并且 SELECT 语句中只提及特征。
请按照以下步骤创建 k-means 模型:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
CREATE OR REPLACE MODEL `bqml_tutorial.london_station_clusters` OPTIONS ( model_type = 'kmeans', num_clusters = 4) AS WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT (station_name, isweekday) FROM stationstats;
BigQuery DataFrame
在尝试此示例之前,请按照《BigQuery 快速入门:使用 BigQuery DataFrames》中的 BigQuery DataFrames 设置说明进行操作。如需了解详情,请参阅 BigQuery DataFrames 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置 ADC。
解读数据聚簇
模型的评估标签页中的信息可以帮助您解读模型生成的聚簇。
请按照以下步骤查看模型的评估信息:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在探索器窗格中,展开您的项目,展开
bqml_tutorial数据集,然后展开模型文件夹。选择
london_station_clusters模型。选择评估标签页。此标签页显示 k-means 模型标识的聚簇的可视化。在数值特征部分中,条形图显示每个形心的最重要的数字特征值。每个形心都代表一个给定的数据聚簇。您可以从下拉菜单中选择要可视化的特征。
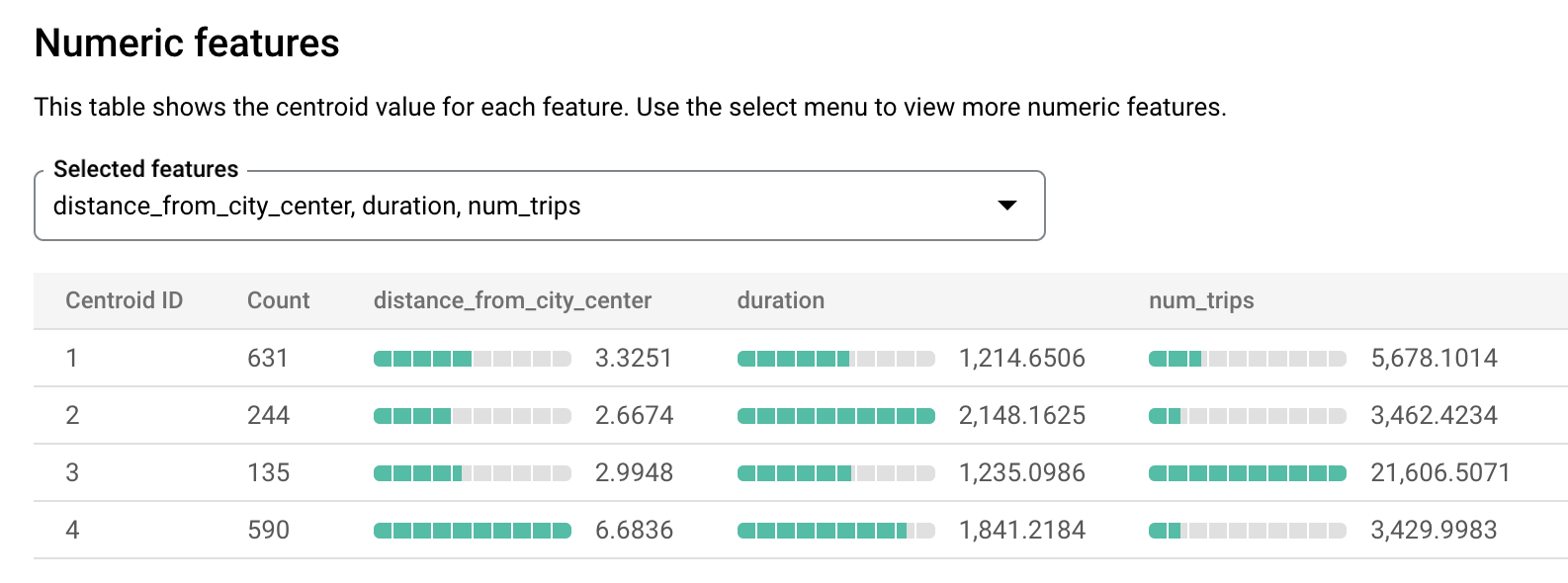
此模型会创建以下形心:
- 形心 1 显示一个不太繁忙的城市车站,租期较短。
- 形心 2 显示第二个城市车站,该车站不太繁忙,用于较长的租期。
- 形心 3 显示靠近市中心的一个繁忙城市车站。
- 形心 4 显示一个行程较长的郊区车站。
如果您经营的是自行车租赁业务,就可以利用这些信息为业务决策提供依据。例如:
假设您需要对一种新型车锁进行实验。您应该选择哪些车站作为此次实验的对象?形心 1、形心 2 或形心 4 中的车站似乎是合乎逻辑的选择,因为它们不是最繁忙的车站。
假设您想要在一些车站投放赛车。您应该选择哪些车站?形心 4 是距离市中心较远且行程最长的车站组。这些车站适合作为赛车的候选车站。
使用 ML.PREDICT 函数预测车站的聚簇
使用 ML.PREDICT SQL 函数或 predict BigQuery DataFrames 函数来识别特定车站所属的聚簇。
SQL
以下查询使用 REGEXP_CONTAINS 函数查找 station_name 列中包含字符串 Kennington 的所有条目。ML.PREDICT 函数使用这些值来预测哪些聚簇将包含这些车站。
请按照以下步骤预测名称中包含字符串 Kennington 的每个车站的聚簇:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,粘贴以下查询,然后点击运行:
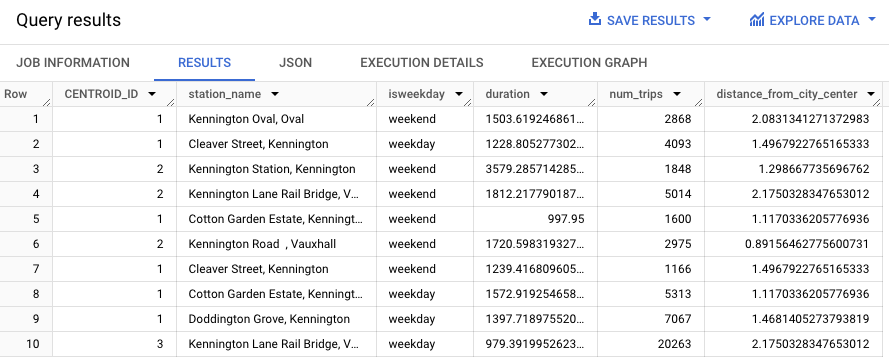
WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT (nearest_centroids_distance) FROM ML.PREDICT( MODEL `bqml_tutorial.london_station_clusters`, ( SELECT * FROM stationstats WHERE REGEXP_CONTAINS(station_name, 'Kennington') ));
结果应类似于以下内容。
BigQuery DataFrame
在尝试此示例之前,请按照《BigQuery 快速入门:使用 BigQuery DataFrames》中的 BigQuery DataFrames 设置说明进行操作。如需了解详情,请参阅 BigQuery DataFrames 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为本地开发环境设置 ADC。
清理
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请删除包含这些资源的项目,或者保留项目但删除各个资源。
- 删除您在教程中创建的项目。
- 或者,保留项目但删除数据集。
删除数据集
删除项目也将删除项目中的所有数据集和所有表。如果您希望重复使用该项目,则可以删除在本教程中创建的数据集:
如有必要,请在Google Cloud 控制台中打开 BigQuery 页面。
在导航窗格中,点击您创建的 bqml_tutorial 数据集。
点击窗口右侧的删除数据集。此操作会删除数据集和模型。
在删除数据集对话框中,通过输入数据集的名称 (
bqml_tutorial) 来确认该删除命令,然后点击删除。
删除项目
如需删除项目,请执行以下操作:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
后续步骤
- 如需大致了解 BigQuery ML,请参阅 BigQuery ML 简介。
- 如需了解如何创建模型,请参阅
CREATE MODEL语法页面。