在 dbt 中使用 BigQuery DataFrames
dbt(数据构建工具)是一个开源命令行框架,专为在现代数据仓库中进行数据转换而设计。dbt 通过创建可重用的基于 SQL 和 Python 的模型,促进模块化数据转换。该工具可编排目标数据仓库中这些转换的执行,重点在于 ELT 流水线的转换步骤。如需了解详情,请参阅 dbt 文档。
在 dbt 中,Python 模型是一种数据转换,可在 dbt 项目中使用 Python 代码定义和执行。您无需为转换逻辑编写 SQL,而是编写 Python 脚本,然后由 dbt 编排这些脚本以在数据仓库环境中运行。借助 Python 模型,您可以执行可能难以用 SQL 表示或效率低下的数据转换。这样一来,您既可以利用 Python 的功能,又可以受益于 dbt 的项目结构、编排、依赖项管理、测试和文档功能。如需了解详情,请参阅 Python 模型。
dbt-bigquery 适配器支持运行在 BigQuery DataFrames 中定义的 Python 代码。此功能可在 dbt Cloud 和 dbt Core 中使用。
您还可以通过克隆最新版本的 dbt-bigquery 适配器来获取此功能。
所需的角色
dbt-bigquery 适配器支持基于 OAuth 和基于服务账号的身份验证。
如果您计划使用 OAuth 向 dbt-bigquery 适配器进行身份验证,请让管理员授予您以下角色:
- 项目的 BigQuery User 角色 (
roles/bigquery.user) - 项目或保存表的数据集的 BigQuery Data Editor 角色 (
roles/bigquery.dataEditor) - 项目中的 Colab Enterprise User 角色 (
roles/colabEnterprise.user) - 暂存 Cloud Storage 存储桶的 Storage Admin 角色 (
roles/storage.admin),用于暂存代码和日志
如果您计划使用服务账号向 dbt-bigquery 适配器进行身份验证,请让您的管理员向您计划使用的服务账号授予以下角色:
- BigQuery User 角色 (
roles/bigquery.user) - BigQuery Data Editor 角色 (
roles/bigquery.dataEditor) - Colab Enterprise User 角色 (
roles/colabEnterprise.user) - Storage Admin 角色 (
roles/storage.admin)
如果您使用服务账号进行身份验证,还应确保您已获得计划使用的服务账号的 Service Account User 角色 (roles/iam.serviceAccountUser)。
Python 执行环境
dbt-bigquery 适配器利用 Colab Enterprise 笔记本执行器服务来运行 BigQuery DataFrames Python 代码。dbt-bigquery 适配器会自动为每个 Python 模型创建并执行 Colab Enterprise 笔记本。您可以选择要在哪个Google Cloud 项目中执行笔记本。笔记本会执行模型中的 Python 代码,该代码由 BigQuery DataFrames 库转换为 BigQuery SQL。然后,在配置的项目中执行 BigQuery SQL。下图展示了控制流:
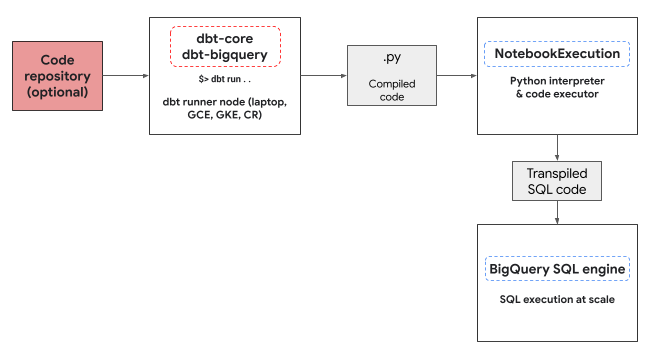
如果项目中尚无可用的笔记本模板,并且执行代码的用户拥有创建模板的权限,则 dbt-bigquery 适配器会自动创建并使用默认笔记本模板。您还可以使用 dbt 配置指定其他笔记本模板。
笔记本执行需要一个暂存 Cloud Storage 存储桶来存储代码和日志。不过,dbt-bigquery 适配器会将日志复制到 dbt 日志中,因此您无需浏览存储桶。
支持的功能
对于运行 BigQuery DataFrames 的 dbt Python 模型,dbt-bigquery 适配器支持以下功能:
- 使用
dbt.source()宏从现有 BigQuery 表中加载数据。 - 使用
dbt.ref()宏加载其他 dbt 模型中的数据,以构建依赖项并使用 Python 模型创建有向无环图 (DAG)。 - 指定和使用可用于执行 Python 代码的 PyPi 中的 Python 软件包。如需了解详情,请参阅配置。
- 为 BigQuery DataFrames 模型指定自定义笔记本运行时模板。
dbt-bigquery 适配器支持以下具体化策略:
- 表实体化,即在每次运行时将数据重建为表。
- 采用合并策略的增量实体化,其中新数据或更新后的数据会添加到现有表中,通常使用合并策略来处理更改。
设置 dbt 以使用 BigQuery DataFrames
如果您使用的是 dbt Core,则需要使用 profiles.yml 文件才能与 BigQuery DataFrames 搭配使用。以下示例使用了 oauth 方法:
your_project_name:
outputs:
dev:
compute_region: us-central1
dataset: your_bq_dateset
gcs_bucket: your_gcs_bucket
job_execution_timeout_seconds: 300
job_retries: 1
location: US
method: oauth
priority: interactive
project: your_gcp_project
threads: 1
type: bigquery
target: dev
如果您使用的是 dbt Cloud,则可以直接在 dbt Cloud 界面中连接到数据平台。在这种情况下,您不需要 profiles.yml 文件。如需了解详情,请参阅 profiles.yml 简介。
以下是 dbt_project.yml 文件的项目级配置示例:
# Name your project! Project names should contain only lowercase characters
# and underscores. A good package name should reflect your organization's
# name or the intended use of these models.
name: 'your_project_name'
version: '1.0.0'
# Configuring models
# Full documentation: https://docs.getdbt.com/docs/configuring-models
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the config(...) macro.
models:
your_project_name:
submission_method: bigframes
notebook_template_id: 7018811640745295872
packages: ["scikit-learn", "mlflow"]
timeout: 3000
# Config indicated by + and applies to all files under models/example/
example:
+materialized: view
您还可以在 Python 代码中使用 dbt.config 方法配置某些参数。如果这些设置与您的 dbt_project.yml 文件冲突,则 dbt.config 中的配置将优先。
如需了解详情,请参阅模型配置和 dbt_project.yml。
配置
您可以使用 Python 模型中的 dbt.config 方法设置以下配置。这些配置会覆盖项目级配置。
| 配置 | 必需 | 用法 |
|---|---|---|
submission_method |
是 | submission_method=bigframes |
notebook_template_id |
否 | 如果未指定,系统会创建并使用默认模板。 |
packages |
否 | 根据需要指定其他 Python 软件包列表。 |
timeout |
否 | 可选:延长作业执行超时时间。 |
Python 模型示例
以下部分介绍了示例场景和 Python 模型。
从 BigQuery 表中加载数据
如需使用现有 BigQuery 表中的数据作为 Python 模型中的来源,您首先需要在 YAML 文件中定义此来源。以下示例是在 source.yml 文件中定义的。
version: 2
sources:
- name: my_project_source # A custom name for this source group
database: bigframes-dev # Your Google Cloud project ID
schema: yyy_test_us # The BigQuery dataset containing the table
tables:
- name: dev_sql1 # The name of your BigQuery table
然后,您构建 Python 模型,该模型可以使用此 YAML 文件中配置的数据源:
def model(dbt, session):
# Configure the model to use BigFrames for submission
dbt.config(submission_method="bigframes")
# Load data from the 'dev_sql1' table within 'my_project_source'
source_data = dbt.source('my_project_source', 'dev_sql1')
# Example transformation: Create a new column 'id_new'
source_data['id_new'] = source_data['id'] * 10
return source_data
引用其他模型
您可以构建依赖于其他 dbt 模型输出的模型,如以下示例所示。这对于创建模块化数据流水线很有用。
def model(dbt, session):
# Configure the model to use BigFrames
dbt.config(submission_method="bigframes")
# Reference another dbt model named 'dev_sql1'.
# It assumes you have a model defined in 'dev_sql1.sql' or 'dev_sql1.py'.
df_from_sql = dbt.ref("dev_sql1")
# Example transformation on the data from the referenced model
df_from_sql['id'] = df_from_sql['id'] * 100
return df_from_sql
指定软件包依赖项
如果您的 Python 模型需要特定的第三方库(例如 MLflow 或 Boto3),您可以在模型的配置中声明该软件包,如以下示例所示。这些软件包安装在执行环境中。
def model(dbt, session):
# Configure the model for BigFrames and specify required packages
dbt.config(
submission_method="bigframes",
packages=["mlflow", "boto3"] # List the packages your model needs
)
# Import the specified packages for use in your model
import mlflow
import boto3
# Example: Create a DataFrame showing the versions of the imported packages
data = {
"mlflow_version": [mlflow.__version__],
"boto3_version": [boto3.__version__],
"note": ["This demonstrates accessing package versions after import."]
}
bdf = bpd.DataFrame(data)
return bdf
指定非默认模板
如需更精细地控制执行环境或使用预配置的设置,您可以为 BigQuery DataFrames 模型指定非默认的笔记本模板,如以下示例所示。
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# ID of your pre-created notebook template
notebook_template_id="857350349023451yyyy",
)
data = {"int": [1, 2, 3], "str": ['a', 'b', 'c']}
return bpd.DataFrame(data=data)
将表实体化
当 dbt 运行 Python 模型时,需要知道如何将结果保存到数据仓库中。这称为“具体化”。
对于标准表实体化,dbt 每次运行时都会在数据仓库中创建或完全替换一个表,其中包含模型的输出。此操作默认完成,也可以通过明确设置 materialized='table' 属性来完成,如以下示例所示。
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# Instructs dbt to create/replace this model as a table
materialized='table',
)
data = {"int_column": [1, 2], "str_column": ['a', 'b']}
return bpd.DataFrame(data=data)
采用合并策略的增量实体化可让 dbt 仅使用新行或修改后的行来更新表。这对于大型数据集非常有用,因为每次都完全重建表可能会效率低下。合并策略是处理这些更新的常用方法。
此方法通过执行以下操作来智能地集成更改:
- 更新已更改的现有行。
- 添加新行。
- 可选,具体取决于配置:删除来源中不再存在的行。
如需使用合并策略,您需要指定一个 unique_key 属性,以便 dbt 可以使用该属性来识别模型输出与现有表之间的匹配行,如以下示例所示。
def model(dbt, session):
dbt.config(
submission_method="bigframes",
materialized='incremental',
incremental_strategy='merge',
unique_key='int', # Specifies the column to identify unique rows
)
# In this example:
# - Row with 'int' value 1 remains unchanged.
# - Row with 'int' value 2 has been updated.
# - Row with 'int' value 4 is a new addition.
# The 'merge' strategy will ensure that only the updated row ('int 2')
# and the new row ('int 4') are processed and integrated into the table.
data = {"int": [1, 2, 4], "str": ['a', 'bbbb', 'd']}
return bpd.DataFrame(data=data)
问题排查
您可以在 dbt 日志中观察 Python 执行情况。
此外,您还可以在 Colab Enterprise 执行页面中查看代码和日志(包括之前的执行)。
结算
将 dbt-bigquery 适配器与 BigQuery DataFrames 搭配使用时,会产生以下费用: Google Cloud
笔记本执行:您需要为笔记本运行时执行付费。如需了解详情,请参阅笔记本运行时价格。
BigQuery 查询执行:在笔记本中,BigQuery DataFrames 会将 Python 转换为 SQL,并在 BigQuery 中执行代码。系统会根据您的项目配置和查询向您收取费用,如 BigQuery DataFrames 价格中所述。
您可以在 BigQuery 结算控制台中使用以下结算标签,过滤出笔记本执行和由 dbt-bigquery 适配器触发的 BigQuery 执行的结算报告:
- BigQuery 执行标签:
bigframes-dbt-api
后续步骤
- 如需详细了解 dbt 和 BigQuery DataFrames,请参阅将 BigQuery DataFrames 与 dbt Python 模型搭配使用。
- 如需详细了解 dbt Python 模型,请参阅 Python 模型和 Python 模型配置。
- 如需详细了解 Colab Enterprise 笔记本,请参阅使用 Google Cloud 控制台创建 Colab Enterprise 笔记本。
- 如需详细了解 Google Cloud 合作伙伴,请参阅 Google Cloud Ready - BigQuery 合作伙伴。