使用嵌套和重复字段
BigQuery 可与许多不同的数据建模方法结合使用,并且通常可在许多数据模型方法中提供高性能。如需进一步调整数据模型的性能,您可以考虑的一种方法是数据反规范化,这意味着将数据列添加到单个表中以减少或移除表联接。
最佳实践:使用嵌套和重复字段对数据存储空间进行反规范化并提升查询性能。
反规范化是用于提高之前已规范化的关系型数据集的读取性能的常用策略。在 BigQuery 中对数据进行反规范化的推荐方法是使用嵌套和重复字段。当关系具有分层结构并且经常一起被查询时(例如在父子关系中),推荐使用此策略。
使用规范化数据节省的存储空间对于现代系统来说已不再那么重要。使用反规范化的数据虽然会增加存储费用,但可以提高性能,因此是值得的。联接需要协调数据(通信带宽)。反规范化会将数据本地化到各个槽,因此可以实现并行执行。
要在对数据进行反规范化的同时保持关系,您可以使用嵌套重复字段,而不是完全展平数据。如果将关系型数据完全展平,网络通信(数据重排)会对查询性能产生负面影响。
例如,如果对订单架构进行反规范化而不使用嵌套重复的字段,您可能需要按 order_id 这样的字段进行数据分组(如果存在一对多关系)。由于涉及数据重排,与使用嵌套重复的字段对数据进行反规范化相比,对数据进行分组的做法效率较为低下。
在某些情况下,对数据进行反规范化并使用嵌套重复字段并不会提高性能。例如,星型架构通常是优化的分析架构,因此,如果您尝试进一步反规范化,性能可能不会有显著差异。
使用嵌套和重复字段
BigQuery 不需要完全平展的反规范化操作。您可以使用嵌套和重复字段维持关系。
嵌套数据 (
STRUCT)- 通过嵌套数据,您可以用内嵌方式表示外部实体。
- 查询嵌套数据时将使用“dot”语法来引用 leaf 字段,这与使用联接的语法类似。
- 嵌套数据在 GoogleSQL 中表示为
STRUCT类型。
重复数据 (
ARRAY)- 通过创建类型为
RECORD的字段并将模式设为REPEATED,您可以用内嵌方式保留一对多关系(只要关系不是高基数)。 - 使用重复数据后,便不再需要重排。
- 重复数据表示为
ARRAY。查询重复数据时,您可以在 GoogleSQL 中使用ARRAY函数。
- 通过创建类型为
嵌套和重复数据(
STRUCT的ARRAY)- 嵌套和重复互为补充。
- 例如,在事务记录表中,您可以包含一个具有专列项
STRUCT的数组。
如需了解详情,请参阅指定表架构中嵌套和重复的列。
如需详细了解如何反规范化数据,请参阅反规范化。
示例
假设有一个 Orders 表,其中的每一行对应每个已售订单项:
| Order_Id | Item_Name |
|---|---|
| 001 | A1 |
| 001 | B1 |
| 002 | A1 |
| 002 | C1 |
如果您要分析此表中的数据,则需要使用 GROUP BY 子句,类似于以下内容:
SELECT COUNT (Item_Name) FROM Orders GROUP BY Order_Id;
GROUP BY 子句涉及额外的计算开销,但可以通过嵌套重复的数据来避免这种情况。通过创建每行一个订单的表,其中订单行位于嵌套字段中,这样来避免使用 GROUP BY 子句:
| Order_Id | Item_Name |
|---|---|
| 001 |
A1 B1 |
| 002 |
A1 C1 |
在 BigQuery 中,您通常将嵌套架构指定为 STRUCT 对象的 ARRAY。您可以使用 UNNEST 运算符展平嵌套的数据,如以下查询所示:
SELECT * FROM UNNEST( [ STRUCT('001' AS Order_Id, ['A1', 'B1'] AS Item_Name), STRUCT('002' AS Order_Id, ['A1', 'C1'] AS Item_Name) ] );
该查询会产生如下所示的结果:
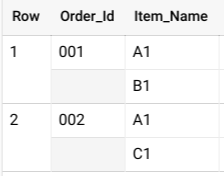
如果此数据未嵌套,则每项订单可能有多个行,每行对应于该订单中销售的每个商品,这会产生较大的表和昂贵的 GROUP BY 操作费用。
锻炼
您可以看到按照本部分中的步骤使用嵌套字段的查询与不按照本部分中的步骤的查询的性能差异。
创建基于
bigquery-public-data.stackoverflow.comments公共数据集的表:CREATE OR REPLACE TABLE `PROJECT.DATASET.stackoverflow` AS ( SELECT user_id, post_id, creation_date FROM `bigquery-public-data.stackoverflow.comments` );
使用
stackoverflow表运行以下查询,以查看每个用户的最早注释:SELECT user_id, ARRAY_AGG(STRUCT(post_id, creation_date AS earliest_comment) ORDER BY creation_date ASC LIMIT 1)[OFFSET(0)].* FROM `PROJECT.DATASET.stackoverflow` GROUP BY user_id ORDER BY user_id ASC;
此查询大约需要 25 秒才能运行完毕,并且会处理 1.88 GB 的数据。
使用创建
comments字段的相同数据来创建第二个表,并使用STRUCT类型来存储post_id和creation_date数据,而不是两个单独的字段:CREATE OR REPLACE TABLE `PROJECT.DATASET.stackoverflow_nested` AS ( SELECT user_id, ARRAY_AGG(STRUCT(post_id, creation_date) ORDER BY creation_date ASC) AS comments FROM `bigquery-public-data.stackoverflow.comments` GROUP BY user_id );
使用
stackoverflow_nested表运行以下查询,以查看每个用户的最早注释:SELECT user_id, (SELECT AS STRUCT post_id, creation_date as earliest_comment FROM UNNEST(comments) ORDER BY creation_date ASC LIMIT 1).* FROM `PROJECT.DATASET.stackoverflow_nested` ORDER BY user_id ASC;
此查询大约需要 10 秒才能运行完毕,并且会处理 1.28 GB 的数据。
完成使用
stackoverflow和stackoverflow_nested表后,请删除它们。