Vector Search est compatible avec la recherche hybride, un modèle d'architecture populaire dans la récupération d'informations (IR) qui combine la recherche sémantique et la recherche par mot clé (également appelée recherche basée sur des jetons). Avec la recherche hybride, les développeurs peuvent tirer parti des deux approches, ce qui améliore la qualité de la recherche.
Cette page explique les concepts de recherche hybride, de recherche sémantique et de recherche basée sur des jetons, et inclut des exemples de configuration de la recherche basée sur des jetons et de la recherche hybride :
- Pourquoi la recherche hybride est-elle importante ?
- Exemple : Utiliser la recherche basée sur des jetons
- Exemple : Utiliser la recherche hybride
- Commencer à utiliser la recherche hybride
- Autres concepts
Pourquoi la recherche hybride est-elle importante ?
Comme décrit dans la présentation de Vector Search, la recherche sémantique avec Vector Search peut trouver des éléments présentant une similitude sémantique à l'aide de requêtes.
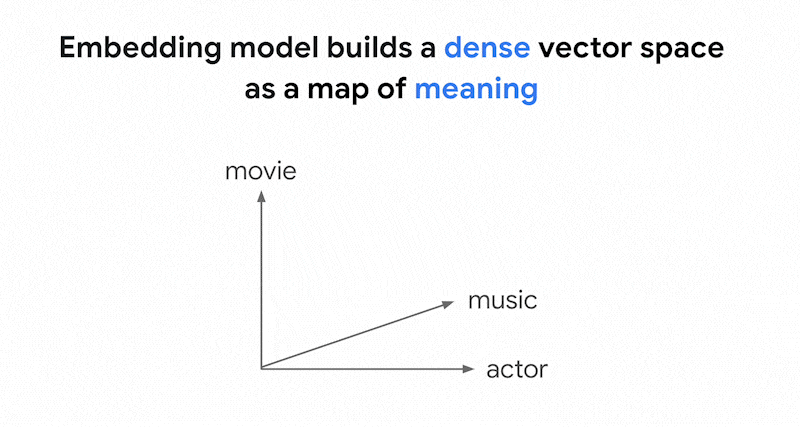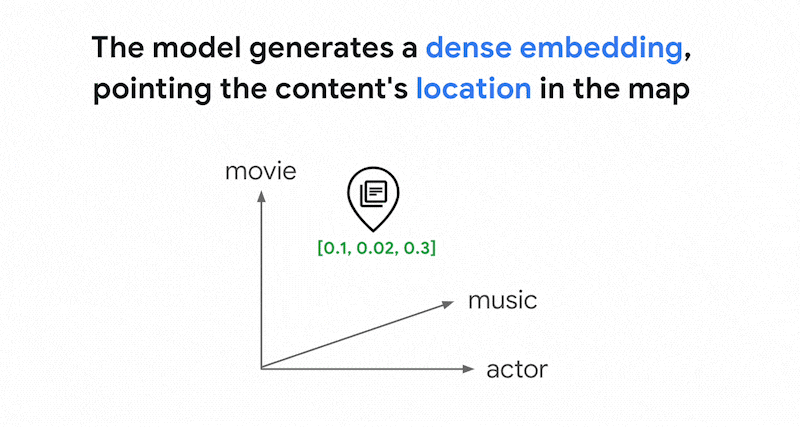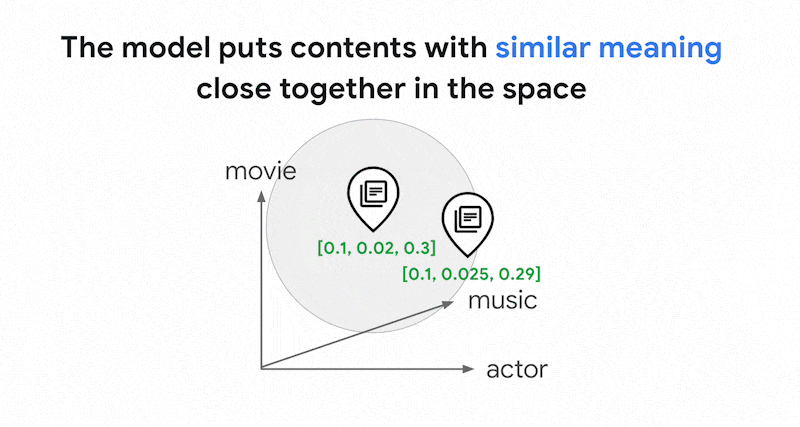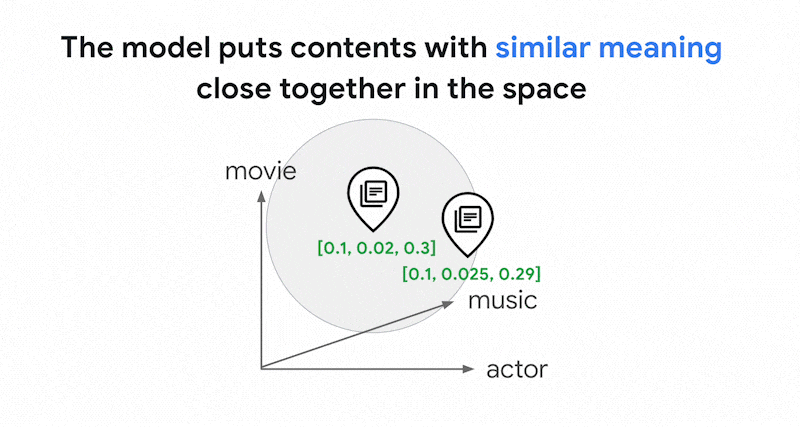
Les modèles d'embedding tels que Vertex AI Embeddings créent un espace vectoriel sous la forme d'une carte des significations du contenu. Chaque texte ou embedding multimodal est un emplacement dans la carte qui représente la signification de certains contenus. Prenons un exemple simplifié : lorsqu'un modèle d'embedding contient un texte qui traite de films pour 10 %, de musique pour 2 % et d'acteurs pour 30 %, il peut représenter ce texte avec un embedding [0.1, 0.02,
0.3]. Vector Search vous permet de trouver rapidement d'autres embeddings dans son voisinage. Cette recherche par signification du contenu est appelée recherche sémantique.
La recherche sémantique avec des embeddings et la recherche vectorielle contribuent à rendre les systèmes informatiques aussi intelligents que des bibliothécaires ou des vendeurs expérimentés. Les embeddings peuvent être utilisés pour associer différentes données métier à leur signification (par exemple, les requêtes et les résultats de recherche, les textes et les images, les activités des utilisateurs et les produits recommandés, les textes en anglais et en japonais, ou les données de capteur et les conditions d'alerte). En raison de ces capacités, les embeddings se prêtent à une grande variété de cas d'utilisation.
Pourquoi combiner la recherche sémantique et la recherche basée sur les mots clés ?
La recherche sémantique ne couvre pas toutes les exigences possibles pour les applications de récupération d'informations, telles que la génération augmentée par récupération (RAG). La recherche sémantique ne peut trouver que les données que le modèle d'embedding peut comprendre. Par exemple, les requêtes ou les ensembles de données avec des numéros ou des SKU de produits arbitraires, les nouveaux noms de produits ajoutés récemment et les noms de code propriétaires de l'entreprise ne fonctionnent pas avec la recherche sémantique, car ils ne sont pas inclus dans l'ensemble de données d'entraînement du modèle d'embedding. On parle alors de données "hors domaine".
Dans ce cas, vous devez combiner la recherche sémantique avec la recherche par mot clé (également appelée recherche par jeton) pour créer une recherche hybride. La recherche hybride vous permet de bénéficier à la fois de la recherche sémantique et de la recherche basée sur les jetons pour améliorer la qualité de la recherche.
La recherche Google est l'un des systèmes de recherche hybride les plus populaires. Le service a intégré la recherche sémantique en 2015 avec le modèle RankBrain, en plus de son algorithme de recherche de mots clés basé sur des jetons. Avec l'introduction de la recherche hybride, la recherche Google a pu améliorer considérablement la qualité des recherches en répondant à ces deux exigences : recherche par signification et recherche par mot clé.
Par le passé, créer un moteur de recherche hybride était une tâche complexe. Comme pour la recherche Google, vous devez créer et exploiter deux types de moteurs de recherche différents (recherche sémantique et recherche basée sur des jetons), puis fusionner et classer les résultats obtenus. La compatibilité avec la recherche hybride dans Vector Search vous permet de créer votre propre système de recherche hybride avec un seul index Vector Search, personnalisé en fonction de vos besoins métier.
Fonctionnement de la recherche basée sur des jetons
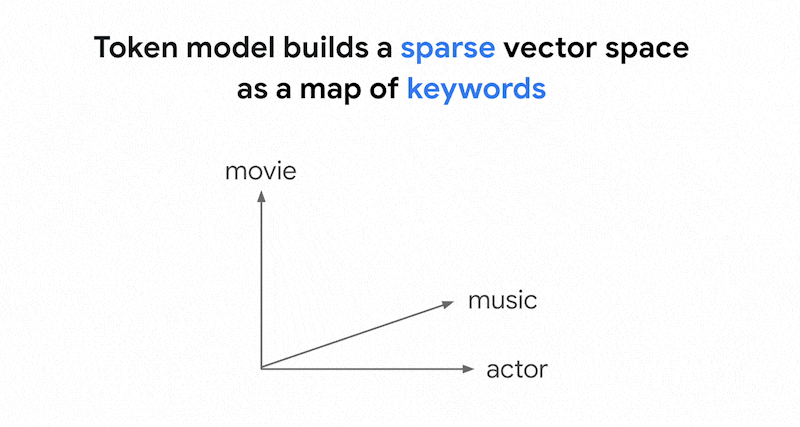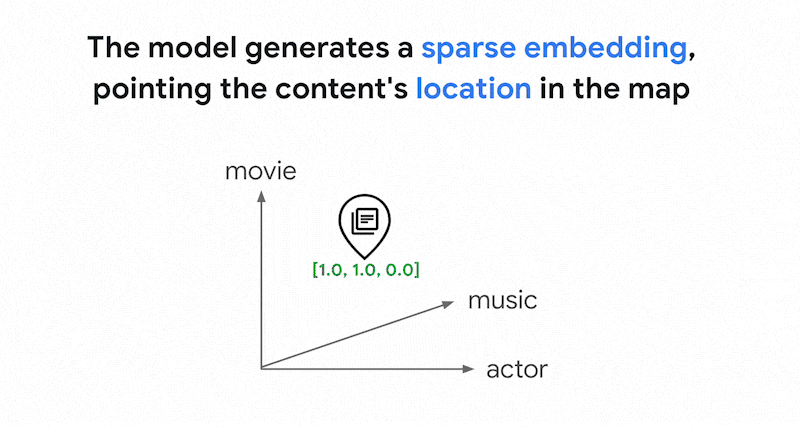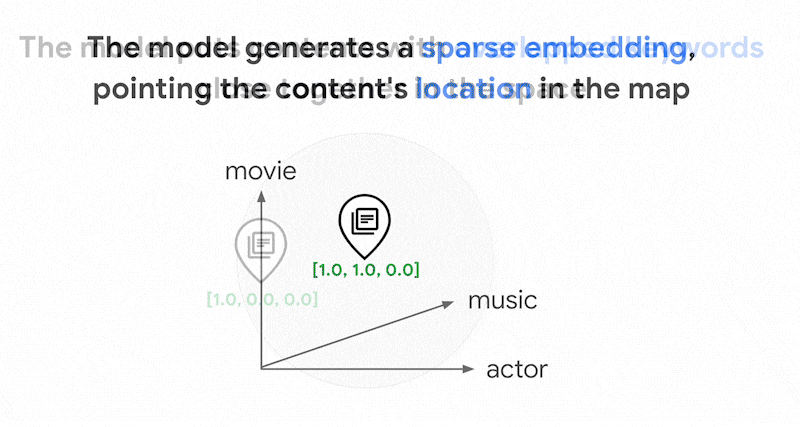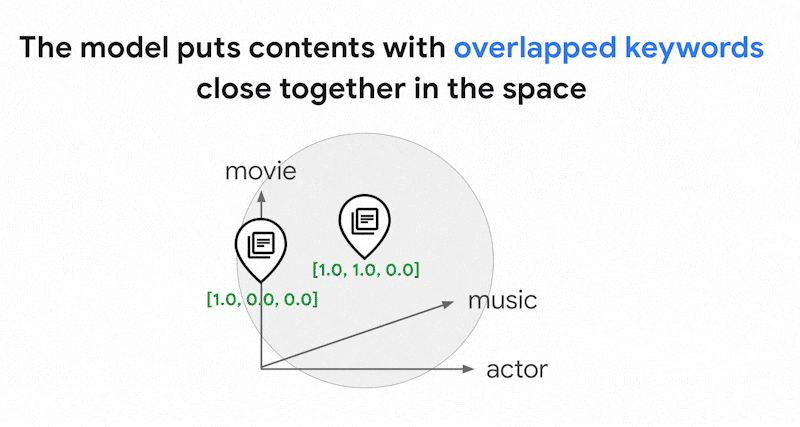
Comment fonctionne la recherche basée sur des jetons dans Vector Search ? Après avoir divisé le texte en jetons (tels que des mots ou des sous-mots), vous pouvez utiliser des algorithmes d'embedding clairsemés courants tels que TF-IDF, BM25 ou SPLADE pour générer un embedding clairsemé pour le texte.
Pour simplifier, les embeddings clairsemés sont des vecteurs qui représentent le nombre de fois où chaque mot ou sous-mot apparaît dans le texte. Les embeddings clairsemés typiques ne tiennent pas compte de la sémantique du texte.

Des milliers de mots différents peuvent être utilisés dans les textes. Ainsi, cet embedding comporte généralement des dizaines de milliers de dimensions, dont seules quelques-unes ont des valeurs non nulles. C'est pourquoi on les appelle des embeddings "clairsemés". La plupart de leurs valeurs sont des zéros. Cet espace d'embedding clairsemé fonctionne comme un mappage de mots clés, semblable à un index de livres.
Dans cet espace d'embedding clairsemé, vous pouvez trouver des représentations vectorielles similaires en examinant le voisinage d'une représentation vectorielle de requête. Ces embeddings sont similaires en termes de répartition des mots clés utilisés dans leurs textes.
Il s'agit du mécanisme élémentaire de la recherche basée sur des jetons avec des embeddings clairsemés. Avec la recherche hybride dans Vector Search, vous pouvez combiner des embeddings denses et clairsemés dans un même index vectoriel, et exécuter des requêtes avec des embeddings denses, clairsemés ou les deux. Le résultat est une combinaison de résultats de recherche sémantique et de résultats de recherche basés sur des jetons.
La recherche hybride offre également une latence de requête inférieure à celle d'un moteur de recherche basé sur des jetons avec un index inversé. Comme pour la recherche vectorielle pour la recherche sémantique, chaque requête avec des embeddings denses ou clairsemés se termine en quelques millisecondes, même avec des millions ou des milliards d'éléments.
Exemple : Utiliser la recherche basée sur des jetons
Pour expliquer comment utiliser la recherche basée sur des jetons, les sections suivantes incluent des exemples de code qui génèrent des embeddings clairsemés et créent un index avec eux sur Vector Search.
Pour essayer cet exemple de code, utilisez le notebook Combining Semantic & Keyword Search: A Hybrid Search Tutorial with Vertex AI Vector Search (Combiner la recherche sémantique et la recherche par mot clé : tutoriel sur la recherche hybride avec Vertex AI Vector Search).
La première étape consiste à préparer un fichier de données pour créer un index pour les embeddings clairsemés, en fonction du format de données décrit dans Format et structure des données d'entrée.
En JSON, le fichier de données se présente comme suit :
{"id": "3", "sparse_embedding": {"values": [0.1, 0.2], "dimensions": [1, 4]}}
{"id": "4", "sparse_embedding": {"values": [-0.4, 0.2, -1.3], "dimensions": [10, 20, 30]}}
Chaque élément doit avoir une propriété sparse_embedding qui comporte des propriétés values et dimensions. Les embeddings clairsemés comportent des milliers de dimensions avec quelques valeurs non nulles. Ce format de données fonctionne efficacement, car il ne contient les valeurs non nulles qu'avec leurs positions dans l'espace.
Préparer un exemple d'ensemble de données
Nous utiliserons l'ensemble de données Google Merch Shop comme exemple. Il contient environ 200 lignes de produits de marque Google.
0 Google Sticker
1 Google Cloud Sticker
2 Android Black Pen
3 Google Ombre Lime Pen
4 For Everyone Eco Pen
...
197 Google Recycled Black Backpack
198 Google Cascades Unisex Zip Sweater
199 Google Cascades Womens Zip Sweater
200 Google Cloud Skyline Backpack
201 Google City Black Tote Backpack
Préparer un vectoriseur TF-IDF
Avec cet ensemble de données, nous allons entraîner un vectoriseur, un modèle qui génère des embeddings clairsemés à partir d'un texte. Cet exemple utilise TfidfVectorizer dans scikit-learn, un vectoriseur de base qui utilise l'algorithme TF-IDF.
from sklearn.feature_extraction.text import TfidfVectorizer
# Make a list of the item titles
corpus = df.title.tolist()
# Initialize TfidfVectorizer
vectorizer = TfidfVectorizer()
# Fit and Transform
vectorizer.fit_transform(corpus)
La variable corpus contient une liste des 200 noms d'éléments, tels que "Google Sticker" ou "Chrome Dino Pin". Le code les transmet ensuite au vectoriseur en appelant la fonction fit_transform(). Le vectoriseur est alors prêt à générer des embeddings clairsemés.
Le vectoriseur TF-IDF essaie de donner un poids plus élevé aux mots signature dans l'ensemble de données (par exemple, "Shirts" ou "Dino") par rapport aux mots d'intérêt secondaire (par exemple, "Le/la", "un/une" ou "de"), et compte le nombre de fois où ces mots signature sont utilisés dans le document spécifié. Chaque valeur d'un embedding clairsemé représente la fréquence de chaque mot en fonction de leur nombre. Pour en savoir plus sur TF-IDF, consultez Comment fonctionnent TF-IDF et TfidfVectorizer ?.
Dans cet exemple, nous utilisons la segmentation de base au niveau des mots et la vectorisation TF-IDF pour plus de simplicité. Dans le développement en production, vous pouvez choisir d'autres options de tokenisation et de vectorisation pour générer des embedding clairsemés en fonction de vos besoins. Dans de nombreux cas, les tokenizers de sous-mots sont performants par rapport à la tokenisation au niveau des mots et sont couramment utilisés. Pour les vectoriseurs, BM25 est une version améliorée de TF-IDF. SPLADE est un autre algorithme de vectorisation populaire qui utilise une sémantique pour l'embedding clairsemé.
Obtenir un embedding clairsemé
Pour faciliter l'utilisation du vectoriseur avec Vector Search, nous allons définir une fonction wrapper, get_sparse_embedding() :
def get_sparse_embedding(text):
# Transform Text into TF-IDF Sparse Vector
tfidf_vector = vectorizer.transform([text])
# Create Sparse Embedding for the New Text
values = []
dims = []
for i, tfidf_value in enumerate(tfidf_vector.data):
values.append(float(tfidf_value))
dims.append(int(tfidf_vector.indices[i]))
return {"values": values, "dimensions": dims}
Cette fonction transmet le paramètre "text" au vectoriseur pour générer un embedding clairsemé. Convertissez-le ensuite au format {"values": ...., "dimensions": ...} mentionné précédemment pour créer un index Vector Search clairsemé.
Vous pouvez tester cette fonction :
text_text = "Chrome Dino Pin"
get_sparse_embedding(text_text)
Le résultat devrait être l'embedding clairsement suivant :
{'values': [0.6756557405747007, 0.5212913389979028, 0.5212913389979028],
'dimensions': [157, 48, 33]}
Créer un fichier de données d'entrée
Dans cet exemple, nous allons générer des embeddings clairsemés pour les 200 éléments.
items = []
for i in range(len(df)):
id = i
title = df.title[i]
sparse_embedding = get_sparse_embedding(title)
items.append({"id": id, "title": title, "sparse_embedding": sparse_embedding})
Ce code génère la ligne suivante pour chaque élément :
{
'id': 0,
'title': 'Google Sticker',
'sparse_embedding': {
'values': [0.933008728540452, 0.359853737603667],
'dimensions': [191, 78]
}
}
Enregistrez-les ensuite en tant que fichier JSONL "items.json", puis importez-les dans un bucket Cloud Storage.
# output as a JSONL file and save to bucket
with open("items.json", "w") as f:
for item in items:
f.write(f"{item}\n")
! gsutil cp items.json $BUCKET_URI
Créer un index d'embeddings clairsemés dans Vector Search
Nous allons maintenant créer et déployer un index d'embeddings clairsemés dans Vector Search. Cette procédure est documentée dans le tutoriel de démarrage rapide de Vector Search.
# create Index
my_index = aiplatform.MatchingEngineIndex.create_tree_ah_index(
display_name = f"vs-hybridsearch-index-{UID}",
contents_delta_uri = BUCKET_URI,
dimensions = 768,
approximate_neighbors_count = 10,
)
Pour utiliser l'index, vous devez créer un point de terminaison d'index. Il fonctionne en tant qu'instance de serveur acceptant les requêtes de type "query" pour votre index.
# create IndexEndpoint
my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint.create(
display_name = f"vs-quickstart-index-endpoint-{UID}",
public_endpoint_enabled = True
)
Avec le point de terminaison d'index, déployez l'index en spécifiant un ID d'index déployé unique.
DEPLOYED_INDEX_ID = f"vs_quickstart_deployed_{UID}"
# deploy the Index to the Index Endpoint
my_index_endpoint.deploy_index(
index = my_index, deployed_index_id = DEPLOYED_INDEX_ID
)
Une fois le déploiement terminé, nous sommes prêts à exécuter une requête de test.
Exécuter une requête avec un index d'embeddings clairsemés
Pour exécuter une requête avec un index d'embedding clairsemé, vous devez créer un objet HybridQuery afin d'encapsuler l'embedding clairsemé du texte de la requête, comme dans l'exemple suivant :
from google.cloud.aiplatform.matching_engine.matching_engine_index_endpoint import HybridQuery
# create HybridQuery
query_text = "Kids"
query_emb = get_sparse_embedding(query_text)
query = HybridQuery(
sparse_embedding_dimensions=query_emb['dimensions'],
sparse_embedding_values=query_emb['values'],
)
Cet exemple de code utilise le texte "Kids" pour la requête. Exécutez maintenant une requête avec l'objet HybridQuery.
# build a query request
response = my_index_endpoint.find_neighbors(
deployed_index_id=DEPLOYED_INDEX_ID,
queries=[query],
num_neighbors=5,
)
# print results
for idx, neighbor in enumerate(response[0]):
title = df.title[int(neighbor.id)]
print(f"{title:<40}")
Vous devriez obtenir un résultat semblable à celui-ci :
Google Blue Kids Sunglasses
Google Red Kids Sunglasses
YouTube Kids Coloring Pencils
YouTube Kids Character Sticker Sheet
Sur les 200 éléments, le résultat contient les noms d'éléments contenant le mot clé "Kids".
Exemple : Utiliser la recherche hybride
Cet exemple combine la recherche basée sur des jetons et la recherche sémantique pour créer une recherche hybride dans Vector Search.
Créer un index hybride
Pour créer un index hybride, chaque élément doit comporter à la fois "embedding" (pour embedding dense) et "sparse_embedding" :
items = []
for i in range(len(df)):
id = i
title = df.title[i]
dense_embedding = get_dense_embedding(title)
sparse_embedding = get_sparse_embedding(title)
items.append(
{"id": id, "title": title,
"embedding": dense_embedding,
"sparse_embedding": sparse_embedding,}
)
items[0]
La fonction get_dense_embedding() utilise l'API Vertex AI Embedding pour générer un embedding textuel à 768 dimensions. Cela génère des embeddings denses et clairsemés au format suivant :
{
"id": 0,
"title": "Google Sticker",
"embedding":
[0.022880317643284798,
-0.03315234184265137,
...
-0.03309667482972145,
0.04621824622154236],
"sparse_embedding": {
"values": [0.933008728540452, 0.359853737603667],
"dimensions": [191, 78]
}
}
Le reste du processus est identique à celui de l'exemple d'utilisation de la recherche basée sur des jetons : importez le fichier JSONL dans le bucket Cloud Storage, créez un index Vector Search avec le fichier, puis déployez l'index sur le point de terminaison de l'index.
Exécuter une requête hybride
Après avoir déployé l'index hybride, vous pouvez exécuter une requête hybride :
# create HybridQuery
query_text = "Kids"
query_dense_emb = get_dense_embedding(query_text)
query_sparse_emb = get_sparse_embedding(query_text)
query = HybridQuery(
dense_embedding=query_dense_emb,
sparse_embedding_dimensions=query_sparse_emb['dimensions'],
sparse_embedding_values=query_sparse_emb['values'],
rrf_ranking_alpha=0.5,
)
Pour le texte de la requête "Kids", générez des embeddings denses et clairsemés pour le mot, puis encapsulez-les dans l'objet HybridQuery. La différence avec la HybridQuery précédente réside dans deux paramètres supplémentaires : dense_embedding et rrf_ranking_alpha.
Cette fois, nous allons imprimer les distances pour chaque élément :
# print results
for idx, neighbor in enumerate(response[0]):
title = df.title[int(neighbor.id)]
dense_dist = neighbor.distance if neighbor.distance else 0.0
sparse_dist = neighbor.sparse_distance if neighbor.sparse_distance else 0.0
print(f"{title:<40}: dense_dist: {dense_dist:.3f}, sparse_dist: {sparse_dist:.3f}")
Dans chaque objet neighbor, il existe une propriété distance qui contient la distance entre la requête et l'élément avec l'embedding dense, et une propriété sparse_distance qui contient la distance avec l'embedding clairsemé. Ces valeurs sont des distances inversées. Par conséquent, une valeur plus élevée correspond à une distance plus courte.
En exécutant une requête avec HybridQuery, vous obtenez le résultat suivant :
Google Blue Kids Sunglasses : dense_dist: 0.677, sparse_dist: 0.606
Google Red Kids Sunglasses : dense_dist: 0.665, sparse_dist: 0.572
YouTube Kids Coloring Pencils : dense_dist: 0.655, sparse_dist: 0.478
YouTube Kids Character Sticker Sheet : dense_dist: 0.644, sparse_dist: 0.468
Google White Classic Youth Tee : dense_dist: 0.645, sparse_dist: 0.000
Google Doogler Youth Tee : dense_dist: 0.639, sparse_dist: 0.000
Google Indigo Youth Tee : dense_dist: 0.637, sparse_dist: 0.000
Google Black Classic Youth Tee : dense_dist: 0.632, sparse_dist: 0.000
Chrome Dino Glow-in-the-Dark Youth Tee : dense_dist: 0.632, sparse_dist: 0.000
Google Bike Youth Tee : dense_dist: 0.629, sparse_dist: 0.000
En plus des résultats de recherche basés sur les jetons qui contiennent le mot clé "Kids", des résultats de recherche sémantiques sont également inclus. Par exemple, "Google White Classic Youth Tee" est inclus, car le modèle d'intégration sait que "Youth" et "Kids" sont sémantiquement similaires.
Pour fusionner les résultats de recherche sémantique et basée sur les jetons, la recherche hybride utilise la Reciprocal Rank Fusion (RRF). Pour en savoir plus sur la RRF et sur la spécification du paramètre rrf_ranking_alpha, consultez la section Qu'est-ce que la Reciprocal Rank Fusion ?.
Reclassement
La RRF permet de fusionner le classement des résultats de recherche sémantiques et basés sur des jetons. Dans de nombreux systèmes de récupération d'informations ou de recommandations, les résultats passent par des algorithmes de classement plus précis, ce que l'on appelle le reclassement. Grâce à la combinaison de la récupération rapide de l'ordre de la milliseconde avec Vector Search et la précision du reclassement des résultats, vous pouvez créer des systèmes à plusieurs étapes qui offrent une qualité de recherche ou des performances de recommandation supérieures.
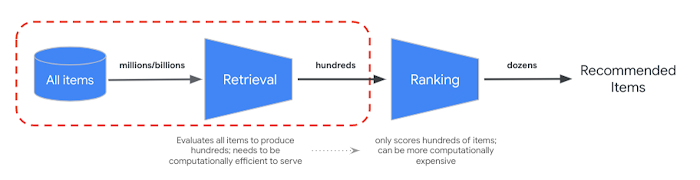
L'API Vertex AI Ranking fournit une méthode de classement en fonction de la pertinence générique entre le texte de la requête et les textes des résultats de recherche avec le modèle pré-entraîné. TensorFlow Ranking présente également comment concevoir et entraîner des modèles d'apprentissage de classification (LTR) pour un reclassement avancé pouvant être personnalisé en fonction de différentes exigences métier.
Commencer à utiliser la recherche hybride
Les ressources suivantes peuvent vous aider à commencer à utiliser la recherche hybride dans la Vector Search.
Ressources de recherche hybride
- Combining Semantic & Keyword Search: A Hybrid Search Tutorial with Vertex AI Vector Search (Combiner la recherche sémantique et la recherche par mot clé : tutoriel sur la recherche hybride avec Vertex AI Vector Search) : exemple de notebook pour découvrir la recherche hybride
- Format et structure des données d'entrée : format des données d'entrée pour créer un index d'embedding clairsemé
- Interroger un index public pour obtenir les voisins les plus proches : exécuter des requêtes avec la recherche hybride
- Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods (La fusion de classements réciproques surpasse les méthodes d'apprentissage de classification Condorcet et individuelles) : discussion sur l'algorithme RRF
Ressources Vector Search
Autres concepts
Les sections suivantes décrivent plus en détail TF-IDF et TfidVectorizer, la Reciprocal Rank Fusion et le paramètre alpha.
Comment fonctionnent TF-IDF et TfidfVectorizer ?
La fonction fit_transform() exécute deux processus importants de l'algorithme TF-IDF :
Fit (Ajustement) : le vectoriseur calcule la fréquence inverse des documents (IDF) pour chaque terme du vocabulaire. L'IDF reflète l'importance d'un terme dans l'ensemble du corpus. Les termes rares obtiennent des scores IDF plus élevés :
IDF(t) = log_e(Total number of documents / Number of documents containing term t)Transformation :
- Tokenisation : divise les documents en termes individuels (mots ou expressions).
Calcul de la fréquence des termes (TF) : compte le nombre de fois où chaque terme apparaît dans chaque document avec :
TF(t, d) = (Number of times term t appears in document d) / (Total number of terms in document d)Calcul TF-IDF : combine la TF de chaque terme avec l'IDF précalculée pour créer un score TF-IDF. Ce score représente l'importance d'un terme dans un document particulier par rapport à l'ensemble du corpus.
TF-IDF(t, d) = TF(t, d) * IDF(t)Le vectoriseur TF-IDF essaie de donner un poids plus élevé aux mots signature dans l'ensemble de données, tels que "Shirts" ou "Dino", par rapport aux mots d'intérêt secondaire, tels que "Le/la", "un/une" ou "de", et compte le nombre de fois où ces mots signature sont utilisés dans le document spécifié. Chaque valeur d'un embedding clairsemé représente la fréquence de chaque mot en fonction des leur nombre.
Qu'est-ce que la Reciprocal Rank Fusion ?
Pour fusionner les résultats de recherche sémantiques et basés sur des jetons, la recherche hybride utilise la Reciprocal Rank Fusion (RRF). Le RRF est un algorithme permettant de combiner plusieurs listes d'éléments classés en un seul classement unifié. Il s'agit d'une technique largement utilisée pour fusionner les résultats de recherche provenant de différentes sources ou méthodes de récupération, en particulier dans les systèmes de recherche hybride et les grands modèles de langage.
Dans le cas de la recherche hybride Vector Search, la distance dense et la distance clairsemée sont mesurées dans des espaces différents et ne peuvent pas être directement comparées. Ainsi, la RRF permet de fusionner et de classer efficacement les résultats des deux espaces.
Voici comment fonctionne la RRF :
- Classement réciproque : pour chaque élément d'une liste classée, calculer son classement réciproque. Cela revient à prendre l'inverse de la position (rang) de l'élément dans la liste. Par exemple, l'élément classé numéro 1 obtient un rang réciproque de 1/1 = 1, et l'élément classé numéro 2 obtient 1/2 = 0,5.
- Somme des rangs réciproques : somme des rangs réciproques pour chaque élément de toutes les listes classées. Vous obtenez ainsi un score final pour chaque élément.
- Tri par score final : trie les éléments par ordre décroissant en fonction de leur score final. Les éléments ayant les scores les plus élevés sont considérés comme les plus pertinents ou les plus importants.
En bref, les éléments dont le rang est plus élevé dans les résultats denses et clairsemés seront placés en haut de la liste. Ainsi, l'article "Google Blue Kids Sunglasses" (Lunettes de soleil bleues pour enfants Google) est en haut de la page, car il est mieux classé dans les résultats de recherche denses et clairsemés. Les articles comme "Google White Classic Youth Tee" sont mal classés, car ils ne sont classés que dans les résultats de recherche denses.
Comportement du paramètre alpha
L'exemple d'utilisation de la recherche hybride définit le paramètre rrf_ranking_alpha sur 0,5 lors de la création de l'objet HybridQuery. Vous pouvez spécifier un poids pour le classement des résultats de recherche denses et clairsemés à l'aide des valeurs suivantes pour rrf_ranking_alpha :
1ou non spécifié : la recherche hybride n'utilise que les résultats de recherche denses et ignore les résultats de recherche clairsemés.0: la recherche hybride n'utilise que les résultats de recherche clairsemés et ignore les résultats de recherche denses.0à1: la recherche hybride fusionne les résultats denses et clairsemés avec le poids spécifié par la valeur. 0,5 signifie qu'ils seront fusionnés avec le même poids.