Qu'est-ce que la génération augmentée de récupération (RAG) ?
La RAG (génération augmentée de récupération) est un framework d'IA qui combine les points forts des systèmes traditionnels de récupération d'informations (tels que la recherche et les bases de données) avec les capacités des grands modèles de langage génératifs (LLM). En combinant vos données et vos connaissances du monde avec les compétences linguistiques des LLM, la génération ancrée est plus précise, à jour et adaptée à vos besoins spécifiques. Consultez cet e-book pour découvrir votre Enterprise Truth.
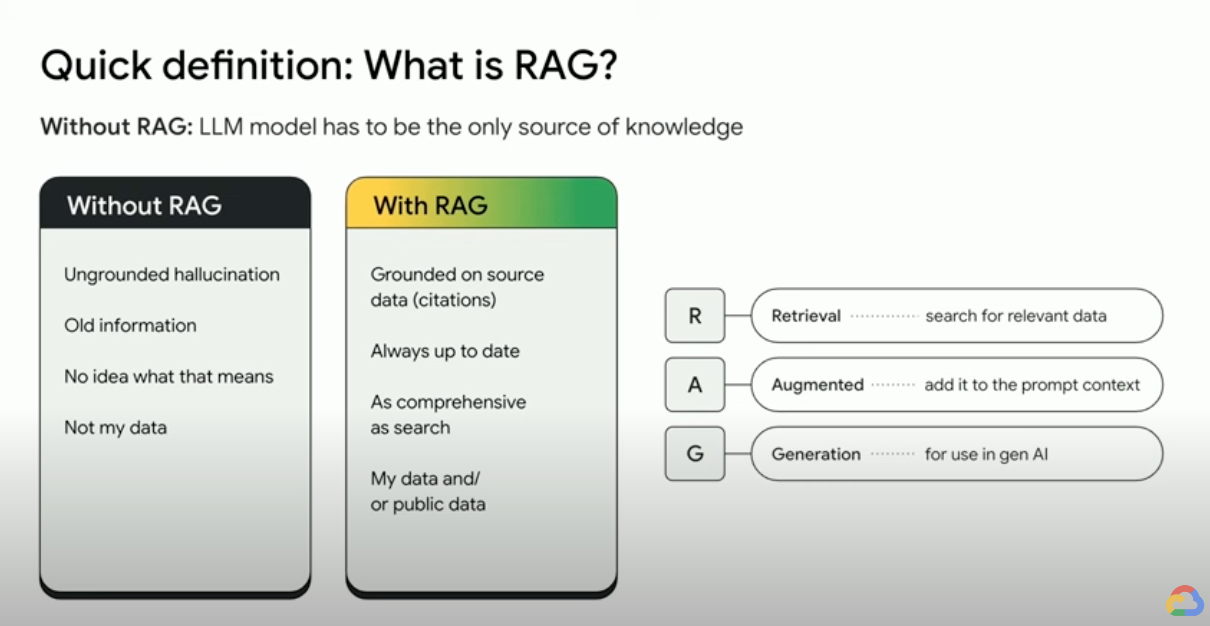
Comment fonctionne la génération augmentée par récupération ?
Les RAG s'appuient sur quelques étapes principales pour améliorer les résultats de l'IA générative :
- Récupération et prétraitement : les RAG exploitent de puissants algorithmes de recherche pour interroger des données externes, tels que des pages Web, des bases de connaissances et des bases de données. Une fois récupérées, les informations pertinentes font l'objet d'un prétraitement, y compris la tokenisation, la recherche de radical et la suppression des mots vides.
- Génération ancrée : les informations récupérées prétraitées sont ensuite intégrées de manière transparente au LLM pré-entraîné. Cette intégration améliore le contexte du LLM en lui permettant de mieux comprendre le sujet. Ce contexte amélioré permet au LLM de générer des réponses plus précises, informatives et plus engageantes.
Pourquoi utiliser le RAG ?
La RAG offre plusieurs avantages par rapport aux méthodes traditionnelles de génération de texte, en particulier lorsqu'il s'agit d'informations factuelles ou de réponses basées sur les données. Voici quelques raisons clés pour lesquelles l'utilisation du RAG peut être bénéfique :
Accès à des informations à jour
Les LLM sont limités à leurs données pré-entraînées. Cela entraîne des réponses obsolètes et potentiellement inexactes. La RAG résout ce problème en fournissant des informations à jour aux LLM.
Ancrage factuel
Les LLM sont de puissants outils permettant de générer du texte créatif et attrayant, mais ils peuvent parfois avoir du mal à fournir des informations factuelles. En effet, les LLM sont entraînés sur d'énormes quantités de données textuelles, qui peuvent contenir des inexactitudes ou des biais.
Fournir des "faits" au LLM dans le prompt d'entrée peut atténuer les hallucinations de l'IA générative. L'essentiel de cette approche consiste à s'assurer que les faits les plus pertinents sont fournis au LLM et que la sortie du LLM est entièrement basée sur ces faits, tout en répondant à la question de l'utilisateur et en respectant les instructions du système et les contraintes de sécurité.
La grande fenêtre de contexte de Gemini est un excellent moyen de fournir des sources au LLM.Si vous devez fournir plus d'informations que ce qui peut être stocké dans la grande fenêtre de contexte, ou si vous devez améliorer les performances, vous pouvez utiliser une approche RAG qui réduira le nombre de jetons, ce qui vous fera gagner du temps et de l'argent.
Recherche avec des bases de données vectorielles et des outils de reclassement par pertinence
Les RAG récupèrent généralement des faits via une recherche, et les moteurs de recherche modernes exploitent désormais des bases de données vectorielles pour récupérer efficacement les documents pertinents. Les bases de données vectorielles stockent les documents sous forme d'embeddings dans un espace de grande dimension, ce qui permet une récupération rapide et précise basée sur la similarité sémantique.Les embeddings multimodaux peuvent être utilisés pour des images, des fichiers audio, des vidéos et plus encore. Ces embeddings multimédias peuvent être récupérés en même temps que des embeddings textuels ou multilingues.
Les moteurs de recherche avancés comme Agent Search sur Gemini Enterprise Agent Platform utilisent à la fois la recherche sémantique et la recherche par mots clés (appelée recherche hybride), ainsi qu'un reclasseur qui attribue des scores aux résultats de recherche pour s'assurer que les premiers résultats renvoyés sont les plus pertinents.De plus, les recherches sont plus efficaces avec une requête claire et ciblée sans fautes d'orthographe. C'est pourquoi, avant de lancer une recherche, les moteurs de recherche sophistiqués transforment une requête et corrigent les fautes d'orthographe.
Pertinence, justesse et qualité
Le mécanisme de récupération dans la RAG est essentiel.Vous avez besoin de la meilleure recherche sémantique sur une base de connaissances organisée pour vous assurer que les informations récupérées sont pertinentes pour la requête ou le contexte d'entrée.Si les informations récupérées sont inappropriées, votre génération peut être fondée, mais hors sujet ou incorrecte.
En ajustant finement le LLM ou en créant des requêtes pour qu'il génère du texte entièrement basé sur les connaissances récupérées, la RAG aide à minimiser les contradictions et les incohérences dans le texte généré.Cela améliore considérablement la qualité du texte généré et l'expérience utilisateur.
La fonction d'évaluation des modèles dans Gemini Enterprise Agent Platform attribue désormais une note aux textes générés par les LLM et aux extraits récupérés en fonction de métriques telles que la cohérence, la fluidité, la précision, la sécurité, le respect des instructions, la qualité des réponses aux questions, etc.Ces métriques vous aident à mesurer le texte ancré que vous obtenez du LLM (pour certaines métriques, il s'agit d'une comparaison avec une réponse de vérité terrain que vous avez fournie).L'implémentation de ces évaluations vous permet d'obtenir une mesure de référence. Vous pouvez optimiser la qualité de la RAG en configurant votre moteur de recherche, en sélectionnant vos données sources, en améliorant les stratégies d'analyse ou de découpage de la mise en page de la source, ou en précisant la question de l'utilisateur avant la recherche.Une approche RAG Ops basée sur les métriques comme celle-ci vous aidera à atteindre une génération RAG et ancrée de haute qualité.
RAG, agents et chatbots
Les RAG et l'ancrage peuvent être intégrés à n'importe quelle application ou agent LLM qui a besoin d'accéder à des données récentes, privées ou spécialisées. En accédant à des informations externes, les chatbots et les agents conversationnels optimisés par RAG exploitent les connaissances externes pour fournir des réponses plus complètes, plus informatives et contextuelles, améliorant ainsi l'expérience utilisateur globale.
Ce qui différencie ce que vous créez avec l'IA générative, ce sont vos données et votre cas d'utilisation.Le rafraîchissement des données et le recentrage permettent d'intégrer vos données aux LLM de manière efficace et évolutive.
Quels produits et services Google Cloud sont associés à la RAG ?
Les produits Google Cloud suivants sont liés à la génération augmentée par récupération :
 Moteur RAG de Gemini Enterprise Agent PlatformFramework de données permettant de développer des applications LLM augmentées par le contexte et facilitant la génération augmentée par récupération.
Moteur RAG de Gemini Enterprise Agent PlatformFramework de données permettant de développer des applications LLM augmentées par le contexte et facilitant la génération augmentée par récupération.- Agent Search sur Gemini Enterprise Agent PlatformAgent Search est la recherche Google pour vos données, un outil de recherche et de création de rapports RAG entièrement géré et prêt à l'emploi.
 Vector Search sur Gemini Enterprise Agent PlatformL'index vectoriel ultra performant qui alimente Agent Search permet d'effectuer des recherches sémantiques et hybrides et de récupérer des données à partir d'énormes collections d'embeddings, avec un rappel élevé et un taux de requête élevé.
Vector Search sur Gemini Enterprise Agent PlatformL'index vectoriel ultra performant qui alimente Agent Search permet d'effectuer des recherches sémantiques et hybrides et de récupérer des données à partir d'énormes collections d'embeddings, avec un rappel élevé et un taux de requête élevé. BigQueryEnsembles de données volumineux que vous pouvez utiliser pour entraîner des modèles de machine learning, y compris des modèles pour Vector Search sur Agent Platform.
BigQueryEnsembles de données volumineux que vous pouvez utiliser pour entraîner des modèles de machine learning, y compris des modèles pour Vector Search sur Agent Platform.- API Grounded GenerationMode haute fidélité Gemini ancré à la recherche Google ou à des faits intégrés, ou utilisez votre propre moteur de recherche.
 AlloyDB AIExécutez des modèles dans Agent Platform et accédez-y dans votre application à l'aide de requêtes SQL que vous connaissez déjà. Utilisez des modèles Google, tels que Gemini, ou vos propres modèles personnalisés.
AlloyDB AIExécutez des modèles dans Agent Platform et accédez-y dans votre application à l'aide de requêtes SQL que vous connaissez déjà. Utilisez des modèles Google, tels que Gemini, ou vos propres modèles personnalisés.
Documentation complémentaire
Apprenez-en plus sur l'utilisation de la génération augmentée de récupération avec ces ressources.
- RAG optimisées par la technologie de recherche Google
- RAG avec bases de données sur Google Cloud
- API permettant de créer vos propres systèmes de génération augmentée de récupération (RAG) et de recherche
- Utiliser le RAG dans BigQuery pour renforcer les LLM
- Exemple de code et guide de démarrage rapide pour vous familiariser avec le RAG
- Infrastructure pour une application d'IA générative compatible avec RAG à l'aide de GKE
Passez à l'étape suivante
Commencez à créer sur Google Cloud avec 300 $ de crédits inclus et plus de 20 produits toujours sans frais.
Vous avez besoin d'aide pour démarrer ?
Contacter le service commercialFaites appel à un partenaire de confiance
Trouver un partenairePoursuivez vos recherches
Voir tous les produits


















