Die Vektorsuche unterstützt die Hybridsuche, ein beliebtes Architekturmuster beim Informationsabruf (IR), das sowohl die semantische Suche als auch die Stichwortsuche (auch tokenbasierte Suche genannt) kombiniert. Mit der Hybridsuche können Entwickler das Beste aus beiden Ansätzen nutzen und so faktisch eine höhere Suchqualität erzielen.
Auf dieser Seite werden die Konzepte der Hybridsuche, der semantischen Suche und der tokenbasierten Suche erläutert. Außerdem finden Sie Beispiele für die Einrichtung der tokenbasierten Suche und der Hybridsuche:
- Warum ist die Hybridsuche wichtig?
- Beispiel: Tokenbasierte Suche verwenden
- Beispiel: Hybridsuche verwenden
- Verwendung der Hybridsuche starten
- Zusätzliche Konzepte
Warum ist die Hybridsuche wichtig?
Wie in der Übersicht über die Vektorsuche beschrieben, kann die semantische Suche mit der Vektorsuche anhand von Abfragen nach Elementen mit semantischer Ähnlichkeit suchen.
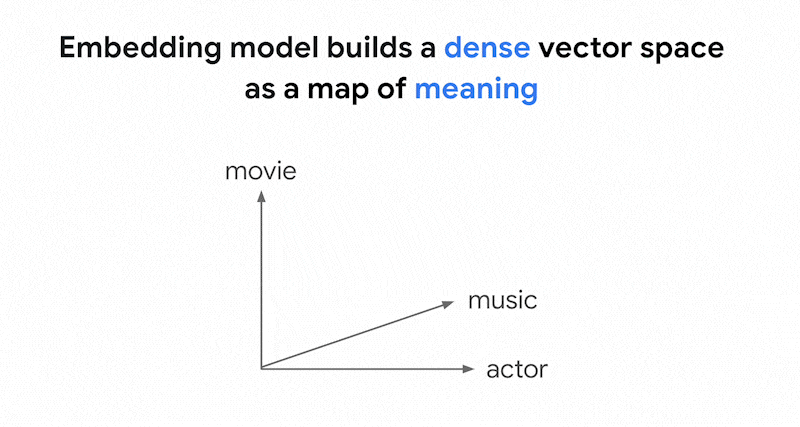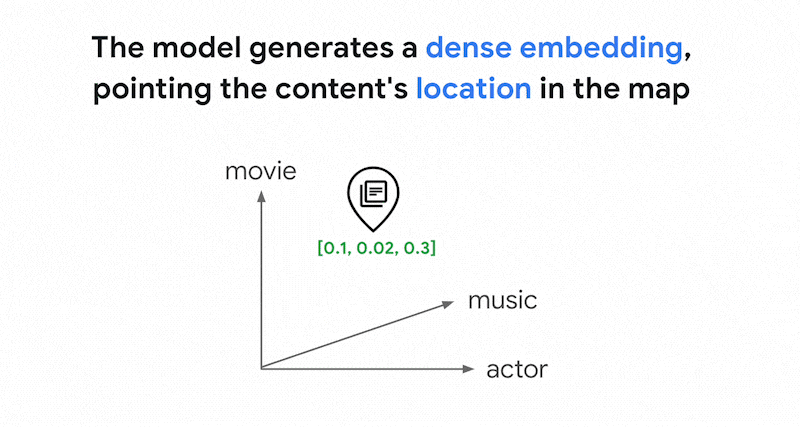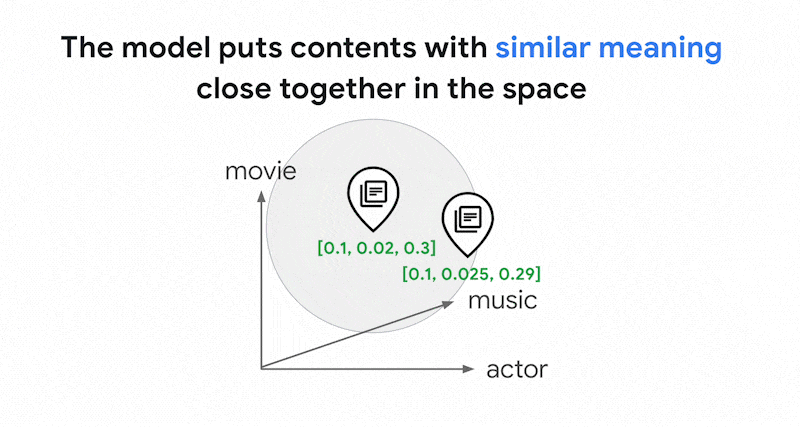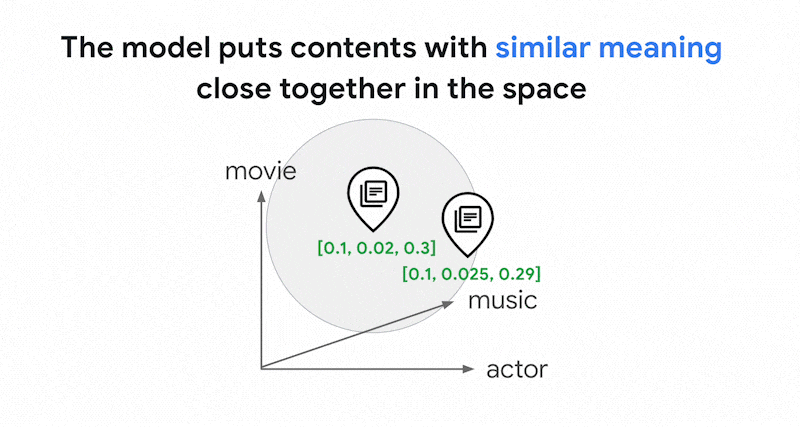
Mit Einbettungsmodellen wie Vertex AI-Embeddings wird ein Vektorbereich als Karte von Inhaltsbedeutungen erstellt. Jede Text- oder multimodale Einbettung ist ein Ort auf der Karte, der die Bedeutung bestimmter Inhalte darstellt. Ein vereinfachtes Beispiel: Wenn ein Einbettungsmodell einen Text verwendet, in dem 10 % über Filme, 2 % über Musik und 30 % über Schauspieler gesprochen wird, könnte es diesen Text mit einer Einbettung [0.1, 0.02,
0.3] darstellen. Mit der Vektorsuche können Sie schnell andere Einbettungen in der Nähe finden. Diese Suche nach der Inhaltsbedeutung wird als semantische Suche bezeichnet.
Die semantische Suche mit Einbettungen und die Vektorsuche können dazu beitragen, IT-Systeme so intelligent wie erfahrene Bibliothekare oder Verkäufer zu machen. Mithilfe von Einbettungen können verschiedene Geschäftsdaten mit ihrer Bedeutung verknüpft werden, z. B. Abfragen und Suchergebnisse; Texte und Bilder; Nutzeraktivitäten und empfohlene Produkte; englische Texte und japanische Texte; oder Sensordaten und Benachrichtigungsbedingungen. Mit dieser Funktion gibt es eine Vielzahl von Anwendungsfällen für Einbettungen.
Warum die semantische Suche mit der stichwortbasierten Suche kombinieren?
Die semantische Suche deckt nicht alle möglichen Anforderungen an Anwendungen zum Informationsabruf ab, z. B. Retrieval Augmented Generation (RAG). Bei der semantischen Suche können nur Daten gefunden werden, die für das Einbettungsmodell verständlich sind. Abfragen oder Datasets mit beliebigen Produktnummern oder SKUs, brandneue Produktnamen, die vor Kurzem hinzugefügt wurden, und proprietäre Codenamen von Unternehmen funktionieren beispielsweise nicht mit der semantischen Suche, da sie nicht im Trainingsdataset des Einbettungsmodells enthalten sind. Diese werden als Daten „außerhalb des Definitionsbereichs“ bezeichnet.
In solchen Fällen müssen Sie die semantische Suche mit der stichwortbasierten Suche (auch als tokenbasiert bezeichnet) kombinieren, um eine Hybridsuche zu bilden. Mit der Hybridsuche können Sie sowohl die semantische als auch die tokenbasierte Suche nutzen, um die Suchqualität zu verbessern.
Eines der beliebtesten Hybridsuchsysteme ist die Google Suche. Der Dienst hat 2015 neben dem tokenbasierten Algorithmus für die Stichwortsuche die semantische Suche mit dem RankBrain-Modell aufgenommen. Mit der Einführung der Hybridsuche konnte die Qualität der Google Suche erheblich verbessert werden, da zwei Anforderungen erfüllt wurden: Suche nach Bedeutung und Suche nach Stichwort.
In der Vergangenheit war es eine komplexe Aufgabe, eine hybride Suchmaschine zu erstellen. Genau wie bei der Google Suche müssen Sie zwei verschiedene Arten von Suchmaschinen (semantische Suche und tokenbasierte Suche) erstellen und betreiben und die Ergebnisse daraus zusammenführen und bewerten. Mit der Unterstützung für die Hybridsuche in der Vektorsuche können Sie ein eigenes Hybridsuchsystem mit einem einzigen Vektorsuchindex erstellen, das an Ihre Geschäftsanforderungen angepasst ist.
So funktioniert die tokenbasierte Suche
Wie funktioniert die tokenbasierte Suche in der Vektorsuche? Nachdem Sie den Text in Tokens unterteilt haben (z. B. Wörter oder Wortgruppen), können Sie gängige Algorithmen für dünnbesetzte Einbettungen wie TF-IDF, BM25 oder SPLADE verwenden, um dünnbesetzte Einbettungen für den Text zu generieren.
Vereinfacht ausgedrückt sind dünnbesetzte Einbettungen Vektoren, die angeben, wie oft jedes Wort oder jedes Teilwort im Text vorkommt. Bei typischen dünnbesetzten Einbettungen wird die Semantik des Textes nicht berücksichtigt.

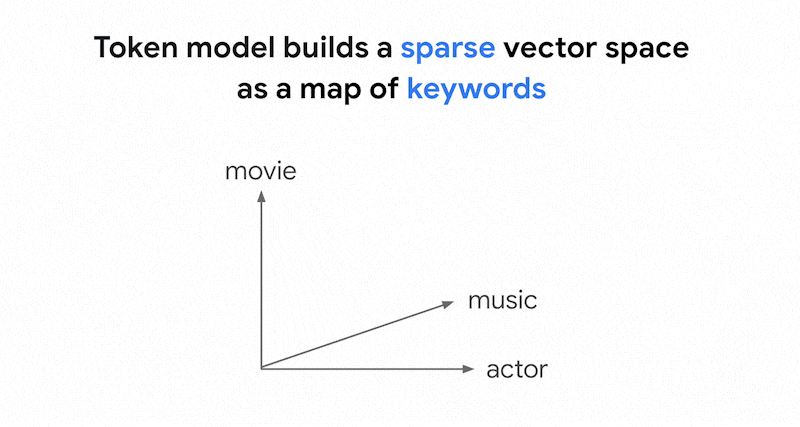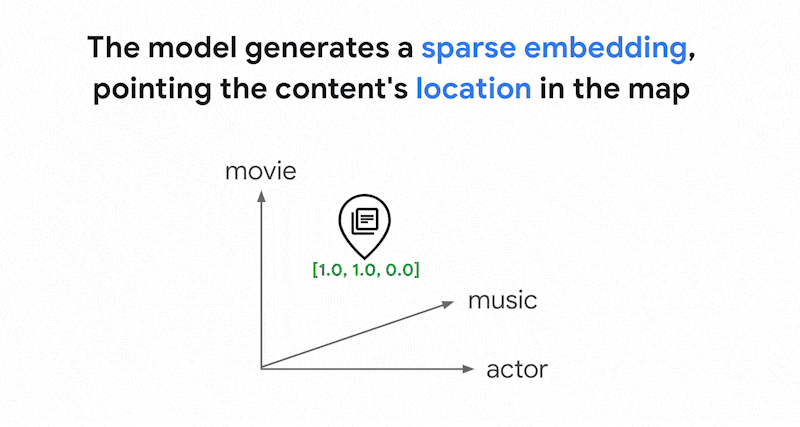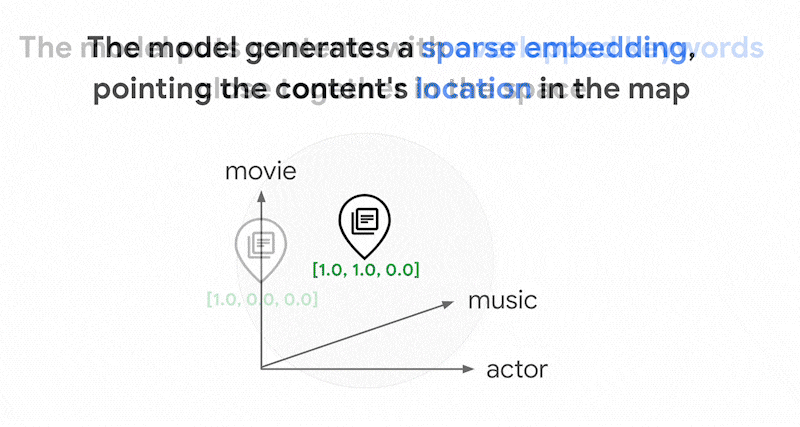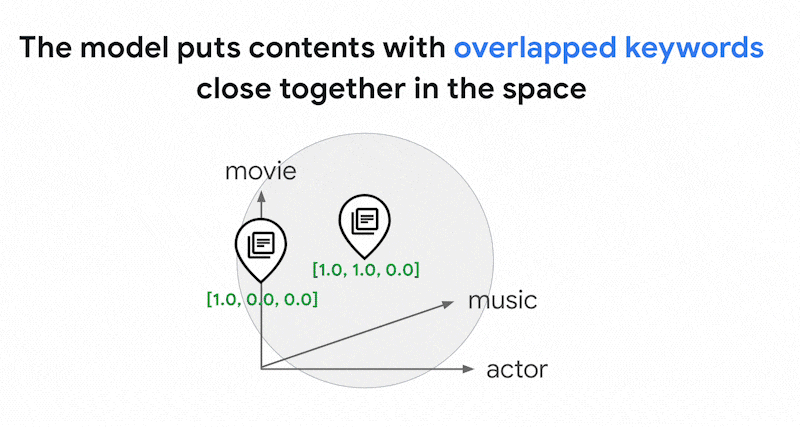
In Texten können Tausende verschiedener Wörter verwendet werden. Daher hat diese Einbettung in der Regel Zehntausende von Dimensionen, von denen nur wenige Werte ungleich Null haben. Daher werden sie als „dünnbesetzte" Einbettungen bezeichnet. Zum Großteil betragen die Werte null. Dieser dünnbesetzte Einbettungsbereich dient als Karte von Stichwörtern, ähnlich wie ein Buchindex.
In diesem dünnbesetzten Einbettungsbereich können Sie ähnliche Einbettungen finden, indem Sie sich die Umgebung einer Abfrage-Einbettung ansehen. Diese Einbettungen sind hinsichtlich der Verteilung der in den Texten verwendeten Stichwörter ähnlich.
Dies ist der grundlegende Mechanismus der tokenbasierten Suche mit dünnbesetzten Einbettungen. Mit der Hybridsuche in der Vektorsuche können Sie sowohl dichte als auch dünnbesetzte Einbettungen in einem einzigen Vektorindex kombinieren und Abfragen mit dichten, dünnbesetzten oder beiden Arten von Einbettungen ausführen. Das Ergebnis ist eine Kombination aus semantischen und tokenbasierten Suchergebnissen.
Die Hybridsuche bietet außerdem eine geringere Abfragelatenz als eine tokenbasierte Suchmaschine mit einem umgekehrten Index-Design. Genau wie bei der Vektorsuche für die semantische Suche wird jede Abfrage mit dichten oder dünnbesetzten Einbettungen innerhalb von Millisekunden abgeschlossen, selbst bei Millionen oder Milliarden von Elementen.
Beispiel: Tokenbasierte Suche verwenden
In den folgenden Abschnitten finden Sie Codebeispiele, die die Verwendung der tokenbasierten Suche veranschaulichen. Dabei werden dünnbesetzte Einbettungen generiert und mit ihnen ein Index in der Vektorsuche erstellt.
Verwenden Sie das Notebook Combining Semantic & Keyword Search: A Hybrid Search Tutorial with Vertex AI Vector Search, um diesen Beispielcode auszuprobieren.
Der erste Schritt besteht darin, eine Datendatei für die Erstellung eines Index für dünnbesetzte Einbettungen vorzubereiten. Verwenden Sie dazu das Datenformat, das unter Format und Struktur von Eingabedaten beschrieben wird.
In JSON sieht die Datendatei so aus:
{"id": "3", "sparse_embedding": {"values": [0.1, 0.2], "dimensions": [1, 4]}}
{"id": "4", "sparse_embedding": {"values": [-0.4, 0.2, -1.3], "dimensions": [10, 20, 30]}}
Jedes Element sollte ein Attribut sparse_embedding mit den Attributen values und dimensions haben. Dünnbesetzte Einbettungen haben Tausende von Dimensionen mit wenigen Werten ungleich null. Dieses Datenformat ist effizient, da es die Werte ungleich Null nur mit ihren Positionen im Bereich enthält.
Beispiel-Dataset vorbereiten
Als Beispiel-Dataset verwenden wir das Dataset Google Merch Shop mit etwa 200 Zeilen mit Waren der Marke Google.
0 Google Sticker
1 Google Cloud Sticker
2 Android Black Pen
3 Google Ombre Lime Pen
4 For Everyone Eco Pen
...
197 Google Recycled Black Backpack
198 Google Cascades Unisex Zip Sweater
199 Google Cascades Womens Zip Sweater
200 Google Cloud Skyline Backpack
201 Google City Black Tote Backpack
TF-IDF-Vectorizer vorbereiten
Mit diesem Dataset trainieren wir einen Vectorizer, ein Modell, das aus einem Text dünnbesetzte Einbettungen generiert. In diesem Beispiel wird TfidfVectorizer in scikit-learn verwendet. Dies ist ein einfacher Vectorizer, der den TF-IDF-Algorithmus verwendet.
from sklearn.feature_extraction.text import TfidfVectorizer
# Make a list of the item titles
corpus = df.title.tolist()
# Initialize TfidfVectorizer
vectorizer = TfidfVectorizer()
# Fit and Transform
vectorizer.fit_transform(corpus)
Die Variable corpus enthält eine Liste der 200 Artikelnamen, z. B. „Google-Sticker“ oder „Chrome-Dino-Anstecker“. Anschließend übergibt der Code sie durch Aufrufen der Funktion fit_transform() an den Vectorizer. Damit wird der Vectorizer für die Generierung dünnbesetzter Einbettungen vorbereitet.
Der TF-IDF-Vectorizer versucht, charakteristischen Wörtern im Dataset (z. B. „T-Shirts“ oder „Dino“) ein höheres Gewicht zu geben als unwichtigen Wörtern (z. B. „Der“, „ein“ oder „von“) und zählt, wie oft diese charakteristischen Wörter im angegebenen Dokument verwendet werden. Jeder Wert einer dünnbesetzten Einbettung entspricht der Häufigkeit eines Wortes basierend auf den Zählungen. Weitere Informationen zu TF-IDF finden Sie unter Wie funktionieren TF-IDF und TfidfVectorizer?.
In diesem Beispiel verwenden wir zur Vereinfachung die grundlegende Tokenisierung auf Wortebene und die TF-IDF-Vektorisierung. Bei der Produktionsentwicklung können Sie je nach Ihren Anforderungen andere Optionen für die Tokenisierung und Vektorisierung auswählen, um dünnbesetzte Einbettungen zu generieren. Bei Tokenizern eignen sich in vielen Fällen Subword-Tokenizer, die im Vergleich zur Tokenisierung auf Wortebene eine gute Leistung erzielen. Bei Vektorizern ist BM25 als verbesserte Version von TF-IDF gängig. SPLADE ist ein weiterer beliebter Vektorisierungsalgorithmus, der einiges an Semantik für die dünnbesetzte Einbettung berücksichtigt.
Dünnbesetzte Einbettung abrufen
Damit der Vectorizer einfacher mit der Vektorsuche verwendet werden kann, definieren wir eine Wrapper-Funktion, get_sparse_embedding():
def get_sparse_embedding(text):
# Transform Text into TF-IDF Sparse Vector
tfidf_vector = vectorizer.transform([text])
# Create Sparse Embedding for the New Text
values = []
dims = []
for i, tfidf_value in enumerate(tfidf_vector.data):
values.append(float(tfidf_value))
dims.append(int(tfidf_vector.indices[i]))
return {"values": values, "dimensions": dims}
Diese Funktion übergibt den Parameter „text“ an den Vectorizer, um eine dünnbesetzte Einbettung zu generieren. Konvertieren Sie sie dann in das bereits erwähnte {"values": ...., "dimensions": ...}-Format, um einen dünnbesetzten Vektorsuchindex zu erstellen.
Sie können diese Funktion testen:
text_text = "Chrome Dino Pin"
get_sparse_embedding(text_text)
Dies sollte die folgende dünnbesetzte Einbettung ausgeben:
{'values': [0.6756557405747007, 0.5212913389979028, 0.5212913389979028],
'dimensions': [157, 48, 33]}
Eingabedatendatei erstellen
In diesem Beispiel generieren wir dünnbesetzte Einbettungen für alle 200 Artikel.
items = []
for i in range(len(df)):
id = i
title = df.title[i]
sparse_embedding = get_sparse_embedding(title)
items.append({"id": id, "title": title, "sparse_embedding": sparse_embedding})
Mit diesem Code wird für jeden Artikel die folgende Zeile generiert:
{
'id': 0,
'title': 'Google Sticker',
'sparse_embedding': {
'values': [0.933008728540452, 0.359853737603667],
'dimensions': [191, 78]
}
}
Speichern Sie sie dann als JSONL-Datei „items.json“ und laden Sie sie in einen Cloud Storage-Bucket hoch.
# output as a JSONL file and save to bucket
with open("items.json", "w") as f:
for item in items:
f.write(f"{item}\n")
! gsutil cp items.json $BUCKET_URI
Dünnbesetzten Einbettungsindex in der Vektorsuche erstellen
Als Nächstes erstellen wir einen Index für dünnbesetzte Einbettungen in der Vektorsuche und stellen ihn bereit. Dies entspricht dem Verfahren, das in der Kurzanleitung für die Vektorsuche beschrieben ist.
# create Index
my_index = aiplatform.MatchingEngineIndex.create_tree_ah_index(
display_name = f"vs-hybridsearch-index-{UID}",
contents_delta_uri = BUCKET_URI,
dimensions = 768,
approximate_neighbors_count = 10,
)
Wenn Sie den Index verwenden möchten, müssen Sie einen Indexendpunkt erstellen. Er fungiert als Serverinstanz, die Abfrageanfragen für Ihren Index akzeptiert.
# create IndexEndpoint
my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint.create(
display_name = f"vs-quickstart-index-endpoint-{UID}",
public_endpoint_enabled = True
)
Stellen Sie mit dem Indexendpunkt den Index bereit, indem Sie eine eindeutige bereitgestellte Index-ID angeben.
DEPLOYED_INDEX_ID = f"vs_quickstart_deployed_{UID}"
# deploy the Index to the Index Endpoint
my_index_endpoint.deploy_index(
index = my_index, deployed_index_id = DEPLOYED_INDEX_ID
)
Nachdem die Bereitstellung abgeschlossen ist, können wir eine Testabfrage ausführen.
Abfrage mit einem dünnbesetzten Einbettungsindex ausführen
Wenn Sie eine Abfrage mit einem dünnbesetzten Einbettungsindex ausführen möchten, müssen Sie ein HybridQuery-Objekt erstellen, um die dünnbesetzte Einbettung des Abfragetexts zu kapseln, wie im folgenden Beispiel:
from google.cloud.aiplatform.matching_engine.matching_engine_index_endpoint import HybridQuery
# create HybridQuery
query_text = "Kids"
query_emb = get_sparse_embedding(query_text)
query = HybridQuery(
sparse_embedding_dimensions=query_emb['dimensions'],
sparse_embedding_values=query_emb['values'],
)
In diesem Beispielcode wird der Text „Kids“ für die Abfrage verwendet. Führen Sie jetzt eine Abfrage mit dem HybridQuery-Objekt aus.
# build a query request
response = my_index_endpoint.find_neighbors(
deployed_index_id=DEPLOYED_INDEX_ID,
queries=[query],
num_neighbors=5,
)
# print results
for idx, neighbor in enumerate(response[0]):
title = df.title[int(neighbor.id)]
print(f"{title:<40}")
Die Ausgabe sollte in etwa so aussehen:
Google Blue Kids Sunglasses
Google Red Kids Sunglasses
YouTube Kids Coloring Pencils
YouTube Kids Character Sticker Sheet
Von den 200 Artikeln enthält das Ergebnis die Artikelnamen, die das Stichwort „Kids“ enthalten.
Beispiel: Hybridsuche verwenden
In diesem Beispiel wird die tokenbasierte Suche mit der semantischen Suche kombiniert, um die Hybridsuche in der Vektorsuche zu erstellen.
Hybridindex erstellen
Um einen Hybridindex zu erstellen, sollte jedes Element sowohl „embedding“ (für ein dichtes Einbettungsmodell) als auch „sparse_embedding“ haben:
items = []
for i in range(len(df)):
id = i
title = df.title[i]
dense_embedding = get_dense_embedding(title)
sparse_embedding = get_sparse_embedding(title)
items.append(
{"id": id, "title": title,
"embedding": dense_embedding,
"sparse_embedding": sparse_embedding,}
)
items[0]
Die Funktion get_dense_embedding() verwendet die Vertex AI Embedding API, um Texteinbettungen mit 768 Dimensionen zu generieren. Dadurch werden sowohl dichte als auch dünnbesetzte Einbettungen im folgenden Format generiert:
{
"id": 0,
"title": "Google Sticker",
"embedding":
[0.022880317643284798,
-0.03315234184265137,
...
-0.03309667482972145,
0.04621824622154236],
"sparse_embedding": {
"values": [0.933008728540452, 0.359853737603667],
"dimensions": [191, 78]
}
}
Der Rest des Vorgangs entspricht dem in Beispiel: Tokenbasierte Suche verwenden: Laden Sie die JSONL-Datei in den Cloud Storage-Bucket hoch, erstellen Sie mit der Datei einen Vektorsuchindex und stellen Sie den Index am Indexendpunkt bereit.
Hybridabfrage ausführen
Nachdem Sie den Hybridindex bereitgestellt haben, können Sie eine Hybridabfrage ausführen:
# create HybridQuery
query_text = "Kids"
query_dense_emb = get_dense_embedding(query_text)
query_sparse_emb = get_sparse_embedding(query_text)
query = HybridQuery(
dense_embedding=query_dense_emb,
sparse_embedding_dimensions=query_sparse_emb['dimensions'],
sparse_embedding_values=query_sparse_emb['values'],
rrf_ranking_alpha=0.5,
)
Erstellen Sie für den Abfragetext „Kids“ sowohl dichte als auch dünnbesetzte Einbettungen für das Wort und kapseln Sie sie in das HybridQuery-Objekt. Der Unterschied zum vorherigen HybridQuery besteht in zwei zusätzlichen Parametern: dense_embedding und rrf_ranking_alpha.
Dieses Mal geben wir die Entfernungen für jeden Artikel aus:
# print results
for idx, neighbor in enumerate(response[0]):
title = df.title[int(neighbor.id)]
dense_dist = neighbor.distance if neighbor.distance else 0.0
sparse_dist = neighbor.sparse_distance if neighbor.sparse_distance else 0.0
print(f"{title:<40}: dense_dist: {dense_dist:.3f}, sparse_dist: {sparse_dist:.3f}")
Jedes neighbor-Objekt enthält das Attribut distance mit der Entfernung zwischen der Abfrage und dem Artikel mit der dichten Einbettung sowie das Attribut sparse_distance mit der Entfernung mit der dünnbesetzten Einbettung. Diese Werte sind umgekehrte Entfernungen. Ein höherer Wert bedeutet also eine kürzere Entfernung.
Wenn Sie eine Abfrage mit HybridQuery ausführen, erhalten Sie das folgende Ergebnis:
Google Blue Kids Sunglasses : dense_dist: 0.677, sparse_dist: 0.606
Google Red Kids Sunglasses : dense_dist: 0.665, sparse_dist: 0.572
YouTube Kids Coloring Pencils : dense_dist: 0.655, sparse_dist: 0.478
YouTube Kids Character Sticker Sheet : dense_dist: 0.644, sparse_dist: 0.468
Google White Classic Youth Tee : dense_dist: 0.645, sparse_dist: 0.000
Google Doogler Youth Tee : dense_dist: 0.639, sparse_dist: 0.000
Google Indigo Youth Tee : dense_dist: 0.637, sparse_dist: 0.000
Google Black Classic Youth Tee : dense_dist: 0.632, sparse_dist: 0.000
Chrome Dino Glow-in-the-Dark Youth Tee : dense_dist: 0.632, sparse_dist: 0.000
Google Bike Youth Tee : dense_dist: 0.629, sparse_dist: 0.000
Neben den tokenbasierten Suchergebnissen mit dem Stichwort „Kids“ sind auch semantische Suchergebnisse enthalten. „Google White Classic Youth Tee“ ist beispielsweise enthalten, weil das Einbettungsmodell weiß, dass „Youth“ und „Kids“ semantisch ähnlich sind.
Zur Zusammenführung der tokenbasierten und semantischen Suchergebnisse verwendet die Hybridsuche Reciprocal Rank Fusion (RRF). Weitere Informationen zu RRF und zur Angabe des Parameters rrf_ranking_alpha finden Sie unter Was ist Reciprocal Rank Fusion?.
Reranking
Mit RRF können Sie das Ranking aus semantischen und tokenbasierten Suchergebnissen zusammenführen. In vielen Systemen für die Informationsabfrage oder Recommender-Systemen in der Produktion werden die Ergebnisse durch weitere Algorithmen für die Präzisionsrangfolge geleitet — das sogenannte Reranking. Durch die Kombination des schnellen Abrufs auf Millisekundenebene mit der Vektorsuche und des präzisen Rerankings der Ergebnisse können Sie mehrstufige Systeme erstellen, die eine höhere Suchqualität oder Empfehlungsleistung bieten.
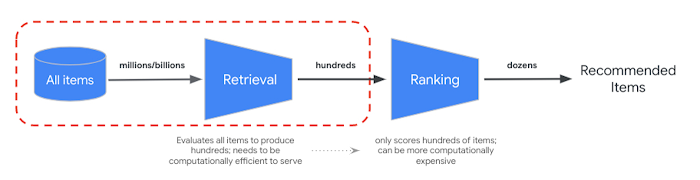
Mit der Vertex AI Ranking API können Sie das Ranking basierend auf der allgemeinen Relevanz zwischen Abfragetext und Suchergebnistexten mit dem vorab trainierten Modell implementieren. TensorFlow Ranking bietet auch eine Einführung in die Entwicklung und das Training von LTR-Modellen (Learning to Rank) für ein erweitertes Reranking, das an verschiedene Geschäftsanforderungen angepasst werden kann.
Verwendung der Hybridsuche starten
Die folgenden Ressourcen sollen Ihnen den Einstieg in die Verwendung der Hybridsuche in der Vektorsuche erleichtern.
Ressourcen zur Hybridsuche
- Combining Semantic & Keyword Search: A Hybrid Search Tutorial with Vertex AI Vector Search: Beispiel-Notebook für den Einstieg in die Hybridsuche
- Input data format and structure: Format der Eingabedaten für die Erstellung eines dünnbesetzten Einbettungsindex
- Query public index to get nearest neighbors: Informationen zum Ausführen von Abfragen mit der Hybridsuche
- Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods: Diskussion des RRF-Algorithmus
Ressourcen zur Vektorsuche
Weitere Konzepte
In den folgenden Abschnitten werden TF-IDF und TfidVectorizer, Reciprical Rank Fusion und der Alpha-Parameter genauer beschrieben.
Wie funktionieren TF-IDF und TfidfVectorizer?
Die Funktion fit_transform() führt zwei wichtige Prozesse des TF-IDF-Algorithmus aus:
Fit: Der Vectorizer berechnet die umgekehrte Dokumenthäufigkeit (IDF) für jeden Begriff im Vokabular. Der IDF-Wert gibt an, wie wichtig ein Begriff im gesamten Korpus ist. Seltene Begriffe erhalten höhere IDF-Werte:
IDF(t) = log_e(Total number of documents / Number of documents containing term t)Transformieren:
- Tokenisierung: Unterteilt die Dokumente in einzelne Begriffe (Wörter oder Wortgruppen).
Berechnung der Begriffshäufigkeit (TF): Zählt, wie oft jeder Begriff in jedem Dokument vorkommt, anhand:
TF(t, d) = (Number of times term t appears in document d) / (Total number of terms in document d)TF-IDF-Berechnung: Kombiniert die TF für jeden Begriff mit dem vorab berechneten IDF, um einen TF-IDF-Wert zu erhalten. Dieser Wert gibt die Bedeutung eines Begriffs in einem bestimmten Dokument im Vergleich zum gesamten Korpus an.
TF-IDF(t, d) = TF(t, d) * IDF(t)Der TF-IDF-Vectorizer versucht, charakteristischen Wörtern im Dataset, z. B. „T-Shirt“ oder „Dino“, ein höheres Gewicht zu geben als unwichtigen Wörtern wie „Der“, „ein“ oder „von“. Außerdem wird gezählt, wie oft diese charakteristischen Wörter im angegebenen Dokument verwendet werden. Jeder Wert einer dünnbesetzten Einbettung entspricht der Häufigkeit eines Wortes basierend auf den Zählungen.
Was ist Reciprocal Rank Fusion?
Für die Zusammenführung der tokenbasierten und semantischen Suchergebnisse verwendet die Hybridsuche Reciprocal Rank Fusion (RRF). RRF ist ein Algorithmus, mit dem mehrere sortierte Listen von Elementen zu einem einzigen, einheitlichen Ranking kombiniert werden. Es ist eine gängige Methode zum Zusammenführen von Suchergebnissen aus verschiedenen Quellen oder Abrufmethoden, insbesondere in Hybridsuchsystemen und Large Language Models.
Bei der Hybridsuche von Vector Search werden die dichte und die dünnbesetzte Entfernung in verschiedenen Bereichen gemessen und können nicht direkt miteinander verglichen werden. Daher eignet sich RRF gut zum Zusammenführen und Sortieren der Ergebnisse aus den beiden verschiedenen Bereichen.
So funktioniert RRF:
- Reziproker Rang: Für jedes Element in einer sortierten Liste wird der reziproke Rang berechnet. Das bedeutet, dass der Kehrwert der Position (Rang) des Elements in der Liste verwendet wird. Das Element auf Platz 1 erhält beispielsweise den reziproken Rang 1/1 = 1 und das Element auf Platz 2 den reziproken Rang 1/2 = 0,5.
- Summe der reziproken Ränge: Die Summe der reziproken Ränge für jedes Element über alle sortierten Listen hinweg. So ergibt sich ein endgültiger Wert für jedes Element.
- Nach endgültigem Wert sortieren: Die Elemente werden in absteigender Reihenfolge nach ihrem endgültigen Wert sortiert. Die Elemente mit den höchsten Werten gelten als die relevantesten oder wichtigsten.
Kurz gesagt: Die Elemente mit den höheren Rängen sowohl in dichten als auch in dünnbesetzten Ergebnissen werden ganz oben in der Liste angezeigt. Daher wird der Artikel „Google Blue Kids Sunglasses“ oben angezeigt, da er sowohl in dichten als auch in dünnbesetzten Suchergebnissen einen höheren Rang hat. Artikel wie „Google White Classic Youth Tee“ haben ein niedriges Ranking, da sie nur in den dichten Suchergebnissen gelistet sind.
Verhalten des Alpha-Parameters
Im Beispiel für die Verwendung der Hybridsuche wird der Parameter rrf_ranking_alpha beim Erstellen des HybridQuery-Objekts auf 0,5 festgelegt. Sie können die Gewichtung für das Ranking der dichten und dünnbesetzten Suchergebnisse mit den folgenden Werten für rrf_ranking_alpha angeben:
1oder nicht angegeben: Bei der Hybridsuche werden nur dichte Suchergebnisse verwendet und dünnbesetzte Suchergebnisse ignoriert.0: Bei der Hybridsuche werden nur dünnbesetzte Suchergebnisse verwendet und dichte Suchergebnisse ignoriert.0bis1: Bei der Hybridsuche werden die Ergebnisse aus dichten und dünnbesetzten Daten mit der vom Wert angegebenen Gewichtung zusammengeführt. 0,5 bedeutet, dass sie mit derselben Gewichtung zusammengeführt werden.