CustomTrainingJob 了。
创建 CustomTrainingJob 时,您将在后台定义一个训练流水线。Vertex AI 使用该训练流水线和 Python 训练脚本中的代码来训练和创建模型。如需了解详情,请参阅创建训练流水线。
定义训练流水线
如需创建训练流水线,请创建一个 CustomTrainingJob 对象。在下一步中,您将使用 CustomTrainingJob 的 run 命令创建和训练模型。如需创建 CustomTrainingJob,请将以下参数传递给其构造函数:
display_name- 您在为 Python 训练脚本定义命令参数时创建的JOB_NAME变量。script_path- 您在本教程前面创建的 Python 训练脚本的路径。container_url- 用于训练模型的 Docker 容器映像的 URI。requirements- 脚本的 Python 软件包依赖项列表。model_serving_container_image_uri- 为模型提供预测的 Docker 容器映像的 URI。此容器可以是预构建的,也可以是您自己的自定义映像。本教程使用预构建容器。
运行以下代码以创建训练流水线。CustomTrainingJob 方法使用 task.py 文件中的 Python 训练脚本来构造 CustomTrainingJob。
job = aiplatform.CustomTrainingJob(
display_name=JOB_NAME,
script_path="task.py",
container_uri="us-docker.pkg.dev/vertex-ai/training/tf-cpu.2-8:latest",
requirements=["google-cloud-bigquery>=2.20.0", "db-dtypes", "protobuf<3.20.0"],
model_serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest",
)
创建和训练模型
在上一步中,您创建了一个名为 job 的 CustomTrainingJob。如需创建和训练模型,请对 CustomTrainingJob 对象调用 run 方法,并向其传递以下参数:
dataset- 您之前在本教程中创建的表格数据集。此参数可以是表格、图片、视频或文本数据集。model_display_name- 模型的名称。bigquery_destination- 指定 BigQuery 数据集位置的字符串。args- 传递给 Python 训练脚本的命令行参数。
如需开始训练数据并创建模型,请在笔记本中运行以下代码:
MODEL_DISPLAY_NAME = "penguins_model_unique"
# Start the training and create your model
model = job.run(
dataset=dataset,
model_display_name=MODEL_DISPLAY_NAME,
bigquery_destination=f"bq://{project_id}",
args=CMDARGS,
)
在转到下一步之前,请确保 job.run 命令的输出中显示以下内容以验证其是否已完成:
CustomTrainingJob run completed。
训练作业完成后,即可部署模型。
部署模型
部署模型时,您还会创建用于进行预测的 Endpoint 资源。如需部署模型并创建端点,请在笔记本中运行以下代码:
DEPLOYED_NAME = "penguins_deployed_unique"
endpoint = model.deploy(deployed_model_display_name=DEPLOYED_NAME)
等待模型部署,然后再转到下一步。模型部署后,输出内容将包含文本 Endpoint model deployed。
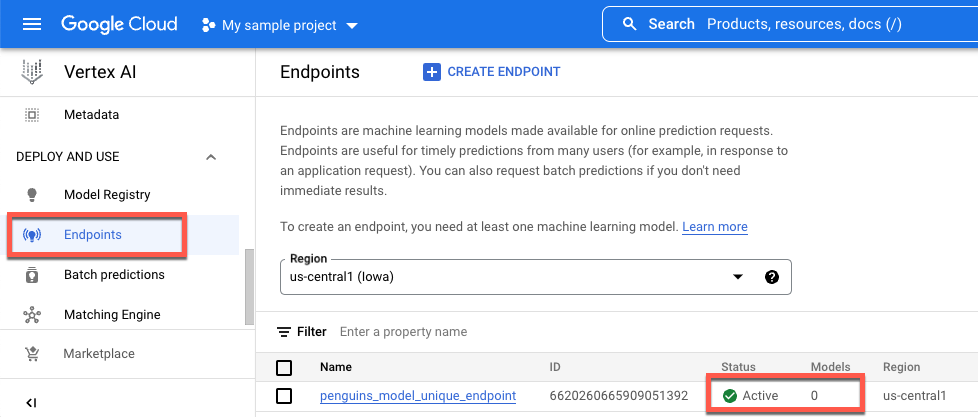
如需在 Google Cloud 控制台中查看部署的状态,请执行以下操作:
在 Google Cloud 控制台中,前往端点页面。
监控模型下的值。在创建端点之后、部署模型之前,该值为
0。模型部署之后,该值将更新为1。下面显示了在创建端点之后、将模型部署到该端点之前的端点。
下面显示了在创建端点之后并将模型部署到该端点之后的端点。
