CustomTrainingJob을 만들 수 있습니다.
CustomTrainingJob을 만들 때 백그라운드에서 학습 파이프라인을 정의합니다. Vertex AI는 학습 파이프라인과 Python 학습 스크립트의 코드를 사용하여 모델을 학습시키고 만듭니다. 자세한 내용은 학습 파이프라인 만들기를 참조하세요.
학습 파이프라인 정의
학습 파이프라인을 만들려면 CustomTrainingJob 객체를 만듭니다. 다음 단계에서는 CustomTrainingJob의 run 명령어를 사용하여 모델을 만들고 학습시킵니다. CustomTrainingJob을 만들려면 해당 생성자에 다음 매개변수를 전달합니다.
display_name- Python 학습 스크립트에 대한 명령어 인수를 정의할 때 만든JOB_NAME변수입니다.script_path- 이 튜토리얼의 앞부분에서 만든 Python 학습 스크립트의 경로입니다.container_url- 모델을 학습시키는 데 사용되는 Docker 컨테이너 이미지의 URI입니다.requirements- 스크립트의 Python 패키지 종속 항목 목록입니다.model_serving_container_image_uri- 모델에 대한 예측을 제공하는 Docker 컨테이너 이미지의 URI입니다. 이 컨테이너는 사전 빌드될 수도 있고 고유한 커스텀 이미지일 수도 있습니다. 이 튜토리얼에서는 사전 빌드된 컨테이너를 사용합니다.
다음 코드를 실행하여 학습 파이프라인을 만듭니다. CustomTrainingJob 메서드는 task.py 파일의 Python 학습 스크립트를 사용하여 CustomTrainingJob을 생성합니다.
job = aiplatform.CustomTrainingJob(
display_name=JOB_NAME,
script_path="task.py",
container_uri="us-docker.pkg.dev/vertex-ai/training/tf-cpu.2-8:latest",
requirements=["google-cloud-bigquery>=2.20.0", "db-dtypes", "protobuf<3.20.0"],
model_serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest",
)
모델 만들기 및 학습
이전 단계에서 job이라는 CustomTrainingJob을 만들었습니다. 모델을 만들고 학습시키려면 CustomTrainingJob 객체에서 run 메서드를 호출하고 다음 매개변수를 전달합니다.
dataset- 이 튜토리얼의 앞부분에서 만든 테이블 형식 데이터 세트입니다. 이 매개변수는 테이블 형식, 이미지, 동영상, 텍스트 데이터 세트일 수 있습니다.model_display_name- 모델의 이름입니다.bigquery_destination- BigQuery 데이터 세트의 위치를 지정하는 문자열입니다.args- Python 학습 스크립트에 전달되는 명령줄 인수입니다.
데이터 학습을 시작하고 모델을 만들려면 노트북에서 다음 코드를 실행합니다.
MODEL_DISPLAY_NAME = "penguins_model_unique"
# Start the training and create your model
model = job.run(
dataset=dataset,
model_display_name=MODEL_DISPLAY_NAME,
bigquery_destination=f"bq://{project_id}",
args=CMDARGS,
)
다음 단계로 계속 진행하기 전에 job.run 명령어 출력에 다음이 표시되는지 확인하여 작업이 완료되었는지 확인합니다.
CustomTrainingJob run completed.
학습 작업이 완료된 후에는 모델을 배포할 수 있습니다.
모델 배포
모델을 배포할 때는 예측에 사용되는 Endpoint 리소스도 만듭니다. 모델을 배포하고 엔드포인트를 만들려면 노트북에서 다음 코드를 실행합니다.
DEPLOYED_NAME = "penguins_deployed_unique"
endpoint = model.deploy(deployed_model_display_name=DEPLOYED_NAME)
다음 단계로 계속 진행하기 전에 모델이 배포될 때까지 기다립니다. 모델이 배포된 후 출력에 Endpoint model deployed 텍스트가 포함됩니다.
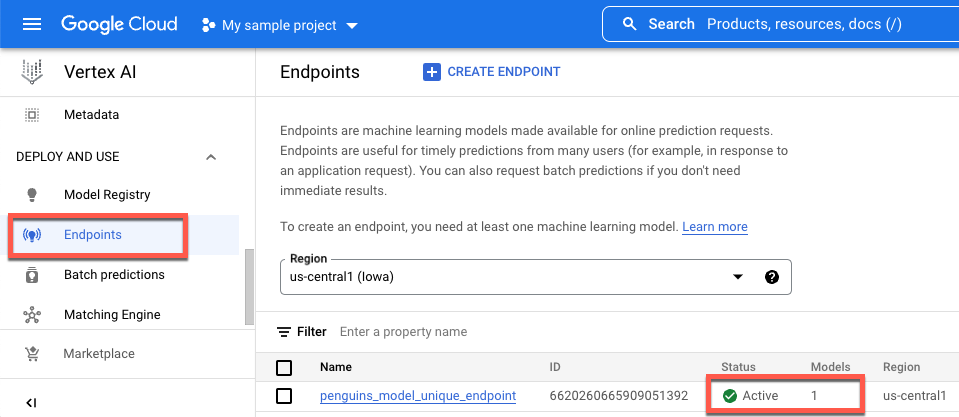
Google Cloud 콘솔에서 배포 상태를 보려면 다음을 수행합니다.
Google Cloud 콘솔에서 엔드포인트 페이지로 이동합니다.
모델에서 값을 모니터링합니다. 엔드포인트가 생성되고 모델이 배포되기 전에는 이 값은
0입니다. 모델이 배포되면 값은1로 업데이트됩니다.다음은 생성된 후 모델이 배포되기 전의 엔드포인트를 보여줍니다.
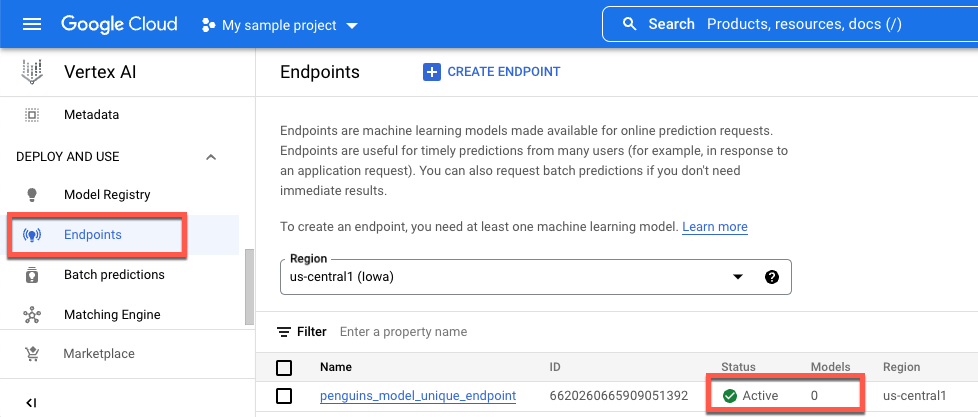
다음은 생성된 후 모델이 배포된 후의 엔드포인트를 보여줍니다.