CustomTrainingJob.
Cuando creas un CustomTrainingJob, debes definir una canalización de entrenamiento en segundo plano. Vertex AI usa la canalización de entrenamiento y el código en tu secuencia de comandos de entrenamiento de Python para entrenar y crear tu modelo. Para obtener más información, consulta Crea canalizaciones de entrenamiento.
Define tu canalización de entrenamiento
Para crear una canalización de entrenamiento, debes crear un objeto CustomTrainingJob. En el siguiente paso, usa el comando run de CustomTrainingJob para crear y entrenar tu modelo. Para crear un CustomTrainingJob, pasa los siguientes parámetros a su constructor:
display_name: Es la variableJOB_NAMEque creaste cuando definiste los argumentos del comando para la secuencia de comandos de entrenamiento de Python.script_path: Es la ruta a la secuencia de comandos de entrenamiento de Python que creaste antes en este instructivo.container_url: Es el URI de una imagen de contenedor de Docker que se usa para entrenar el modelo.requirements: Es la lista de las dependencias de paquetes de Python de la secuencia de comandos.model_serving_container_image_uri: El URI de una imagen de contenedor de Docker que entrega predicciones para tu modelo. Este contenedor se puede compilar previamente o tu propia imagen personalizada. En este instructivo, se usa un contenedor compilado previamente.
Ejecuta el siguiente código para crear tu canalización de entrenamiento. El método CustomTrainingJob usa la secuencia de comandos de entrenamiento de Python en el archivo task.py para construir un CustomTrainingJob.
job = aiplatform.CustomTrainingJob(
display_name=JOB_NAME,
script_path="task.py",
container_uri="us-docker.pkg.dev/vertex-ai/training/tf-cpu.2-8:latest",
requirements=["google-cloud-bigquery>=2.20.0", "db-dtypes", "protobuf<3.20.0"],
model_serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest",
)
Crea y entrena tu modelo
En el paso anterior, creaste un CustomTrainingJob llamado job. Para crear y entrenar tu modelo, llama al método run en tu objeto CustomTrainingJob y pasa los siguientes parámetros:
dataset: Es el conjunto de datos tabular que creaste antes en este instructivo. Este parámetro puede ser un conjunto de datos tabular, de imagen, de video o de texto.model_display_name: Es un nombre para tu modelo.bigquery_destination: Es una string que especifica la ubicación de tu conjunto de datos de BigQuery.args: Son los argumentos de línea de comandos que se pasan a la secuencia de comandos de entrenamiento de Python.
Para comenzar a entrenar tus datos y crear tu modelo, ejecuta el siguiente código en tu notebook:
MODEL_DISPLAY_NAME = "penguins_model_unique"
# Start the training and create your model
model = job.run(
dataset=dataset,
model_display_name=MODEL_DISPLAY_NAME,
bigquery_destination=f"bq://{project_id}",
args=CMDARGS,
)
Antes de continuar con el siguiente paso, asegúrate de que aparezca lo siguiente en el resultado del comando job.run para verificar que se haya completado:
CustomTrainingJob run completed
Una vez finalizado el trabajo de entrenamiento, puedes implementar tu modelo.
Implementa tu modelo
Cuando implementas tu modelo, también debes crear un recurso Endpoint que se usa para hacer predicciones. Para implementar tu modelo y crear un extremo, ejecuta el siguiente código en tu notebook:
DEPLOYED_NAME = "penguins_deployed_unique"
endpoint = model.deploy(deployed_model_display_name=DEPLOYED_NAME)
Espera hasta que el modelo se implemente antes de continuar con el siguiente paso. Después de que se implementa el modelo, el resultado incluye el texto, Endpoint model deployed.
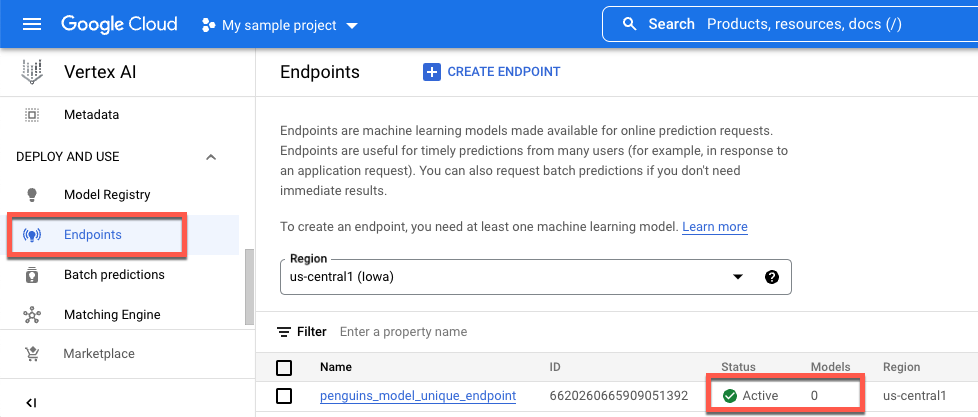
Para ver el estado de tu implementación en la consola de Google Cloud , haz lo siguiente:
En la Google Cloud consola, ve a la página Extremos.
Supervisa el valor en Modelos. El valor es
0después de crear el extremo y antes de implementar el modelo. Una vez que se implementa el modelo, el valor se actualiza a1.A continuación, se muestra un extremo después de su creación y antes de que se implemente un modelo en él.
A continuación, se muestra un extremo después de crearlo y después de implementar un modelo en él.
