Esta página explica como publicar previsões do seu modelo de classificação de imagens e ver estas previsões numa app Web.
Este tutorial tem várias páginas:Preparar um modelo de classificação de imagens personalizado.
Publicação de previsões a partir de um modelo de classificação de imagens personalizado.
Cada página pressupõe que já executou as instruções das páginas anteriores do tutorial.
O resto deste documento pressupõe que está a usar o mesmo ambiente do Cloud Shell que criou quando seguiu a primeira página deste tutorial. Se a sessão original do Cloud Shell já não estiver aberta, pode regressar ao ambiente fazendo o seguinte:-
In the Google Cloud console, activate Cloud Shell.
-
Na sessão do Cloud Shell, execute o seguinte comando:
cd hello-custom-sample
Na Google Cloud consola, na secção Vertex AI, aceda à página Modelos.
Encontre a linha do modelo que preparou no passo anterior deste tutorial
hello_custome clique no nome do modelo para abrir a página de detalhes do modelo.No separador Implementar e testar, clique em Implementar no ponto final para abrir o painel Implementar no ponto final.
No passo Defina o seu ponto final, adicione algumas informações básicas para o seu ponto final:
Selecione Criar novo ponto final.
No campo Nome do ponto final, introduza
hello_custom.Na secção Definições do modelo, certifique-se de que vê o nome do seu modelo, também denominado
hello_custom. Especifique as seguintes definições do modelo:No campo Divisão de tráfego, introduza
100. O Vertex AI suporta a divisão do tráfego de um ponto final em vários modelos, mas este tutorial não usa essa funcionalidade.No campo Número mínimo de nós de computação, introduza
1.Na lista pendente Tipo de máquina, selecione n1-standard-2 na secção Padrão.
Clique em Concluído.
Na secção Registo, certifique-se de que ambos os tipos de registo de previsões estão ativados.
Clique em Continuar.
No passo Detalhes do ponto final, confirme que o ponto final vai ser implementado em
us-central1 (Iowa).Não selecione a caixa de verificação Usar uma chave de encriptação gerida pelo cliente (CMEK). Este tutorial não usa CMEK.
Clique em Implementar para criar o ponto final e implementar o modelo no ponto final.
Pode configurar uma função do Cloud Run para receber pedidos não autenticados. Além disso, as funções são executadas usando uma conta de serviço com a função de editor por predefinição, que inclui a autorização
aiplatform.endpoints.predictnecessária para receber previsões do seu ponto final do Vertex AI.Esta função também realiza um pré-processamento útil nos pedidos. O ponto final do Vertex AI espera pedidos de previsão no formato da primeira camada do gráfico do TensorFlow Keras preparado: um tensor de números de vírgula flutuante normalizados com dimensões fixas. A função usa o URL de uma imagem como entrada e pré-processa a imagem neste formato antes de pedir uma previsão ao ponto final da Vertex AI.
Na Google Cloud consola, na secção Vertex AI, aceda à página Endpoints.
Encontre a linha do ponto final que criou na secção anterior, com o nome
hello_custom. Nesta linha, clique em Pedido de amostra para abrir o painel Pedido de amostra.No painel Pedido de amostra, encontre a linha de código de shell que corresponde ao seguinte padrão:
ENDPOINT_ID="ENDPOINT_ID"
ENDPOINT_ID é um número que identifica este ponto final específico.
Copie esta linha de código e execute-a na sua sessão do Cloud Shell para definir a variável
ENDPOINT_ID.Execute o seguinte comando na sessão do Cloud Shell para implementar a função do Cloud Run:
gcloud functions deploy classify_flower \ --region=us-central1 \ --source=function \ --runtime=python37 \ --memory=2048MB \ --trigger-http \ --allow-unauthenticated \ --set-env-vars=ENDPOINT_ID=${ENDPOINT_ID}Defina algumas variáveis de shell para os comandos nos passos seguintes a usar:
PROJECT_ID=PROJECT_ID BUCKET_NAME=BUCKET_NAMESubstitua o seguinte:
- PROJECT_ID: O ID do Google Cloud projeto.
- BUCKET_NAME: o nome do contentor do Cloud Storage que criou quando seguiu a primeira página deste tutorial.
Edite a app para lhe fornecer o URL de acionamento da sua função do Cloud Run:
echo "export const CLOUD_FUNCTION_URL = 'https://us-central1-${PROJECT_ID}.cloudfunctions.net/classify_flower';" \ > webapp/function-url.jsCarregue o diretório
webapppara o seu contentor do Cloud Storage:gcloud storage cp webapp gs://${BUCKET_NAME}/ --recursiveTorne os ficheiros da app Web que acabou de carregar publicamente legíveis:
gcloud storage objects update gs://${BUCKET_NAME}/webapp/** --add-acl-grant=entity=allUsers,role=READERAgora, pode navegar para o seguinte URL para abrir a app Web e receber previsões:
https://storage.googleapis.com/BUCKET_NAME/webapp/index.html
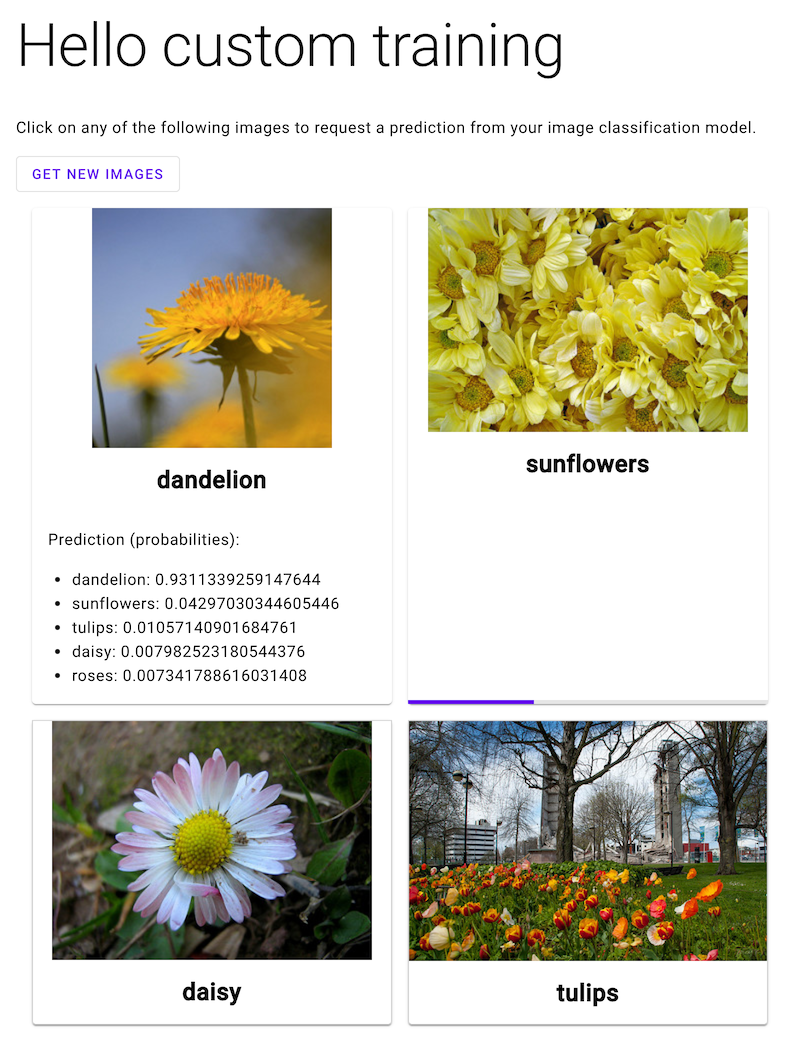
Abra a app Web e clique numa imagem de uma flor para ver a classificação do tipo de flor do seu modelo de ML. A app Web apresenta a previsão como uma lista de tipos de flores e a probabilidade de a imagem conter cada tipo de flor.
Crie um ponto final
Para receber previsões online do modelo de ML que preparou seguindo a página anterior deste tutorial, crie um ponto final do Vertex AI. Os pontos finais publicam previsões online a partir de um ou mais modelos.
Após alguns minutos, é apresentado o ícone junto ao novo ponto final na tabela Pontos finais. Ao mesmo tempo, também recebe um email a indicar que criou o ponto final com êxito e implementou o modelo no ponto final.
Implemente uma função do Cloud Run
Pode receber previsões do ponto final do Vertex AI que acabou de criar enviando pedidos para a interface REST da API Vertex AI. No entanto, apenas os principais com a autorização aiplatform.endpoints.predict podem enviar pedidos de previsão online. Não pode tornar o ponto final público para que qualquer pessoa envie pedidos, por exemplo, através de uma app Web.
Nesta secção, implemente código nas funções do Cloud Run para processar
pedidos não autenticados. O código de exemplo que transferiu quando leu a
primeira página deste tutorial contém código para esta função do
Cloud Run no diretório function/. Opcionalmente, execute o seguinte comando para explorar o código da função do Cloud Run:
less function/main.py
A implementação da função tem as seguintes finalidades:
Para implementar a função do Cloud Run, faça o seguinte:
Implemente uma app Web para enviar pedidos de previsão
Por último, aloje uma app Web estática no Cloud Storage para receber previsões do seu modelo de ML preparado. A app Web envia pedidos para a sua função do Cloud Run, que os pré-processa e recebe previsões do ponto final do Vertex AI.
O diretório webapp do código de amostra que transferiu contém uma amostra de app Web. Na sua sessão do Cloud Shell, execute os seguintes comandos para preparar e implementar a app Web:
Na captura de ecrã seguinte, a app Web já recebeu uma previsão e está a enviar outro pedido de previsão.
O que se segue?
Siga a última página do tutorial para limpar os recursos que criou.