En esta página se explica cómo publicar predicciones a partir de tu modelo de clasificación de imágenes y cómo verlas en una aplicación web.
Este tutorial tiene varias páginas:Entrenar un modelo de clasificación de imágenes personalizado.
Publicar predicciones a partir de un modelo personalizado de clasificación de imágenes.
En cada página se da por hecho que ya has seguido las instrucciones de las páginas anteriores del tutorial.
En el resto de este documento se presupone que estás usando el mismo entorno de Cloud Shell que creaste en la primera página de este tutorial. Si tu sesión original de Cloud Shell ya no está abierta, puedes volver al entorno haciendo lo siguiente:-
In the Google Cloud console, activate Cloud Shell.
-
En la sesión de Cloud Shell, ejecuta el siguiente comando:
cd hello-custom-sample
En la Google Cloud consola, en la sección Vertex AI, ve a la página Modelos.
Busca la fila del modelo que has entrenado en el paso anterior de este tutorial,
hello_custom, y haz clic en el nombre del modelo para abrir su página de detalles.En la pestaña Desplegar y probar, haz clic en Desplegar en punto final para abrir el panel Desplegar en punto final.
En el paso Define tu endpoint, añade información básica sobre tu endpoint:
Seleccione Crear endpoint.
En el campo Nombre del endpoint, introduce
hello_custom.En la sección Configuración del modelo, comprueba que aparezca el nombre de tu modelo, también llamado
hello_custom. Especifica los siguientes ajustes del modelo:En el campo División del tráfico, introduce
100. Vertex AI permite dividir el tráfico de un endpoint entre varios modelos, pero este tutorial no usa esa función.En el campo Número mínimo de nodos de computación, introduce
1.En la lista desplegable Tipo de máquina, selecciona n1-standard-2 en la sección Estándar.
Haz clic en Listo.
En la sección Registro, comprueba que ambos tipos de registro de predicciones estén habilitados.
Haz clic en Continuar.
En el paso Detalles del endpoint, confirma que el endpoint se implementará en
us-central1 (Iowa).No selecciones la casilla Usar una clave de cifrado gestionada por el cliente (CMEK). En este tutorial no se usan CMEK.
Haga clic en Desplegar para crear el endpoint y desplegar el modelo en él.
Puedes configurar una función de Cloud Run para que reciba solicitudes sin autenticar. Además, las funciones se ejecutan con una cuenta de servicio con el rol Editor de forma predeterminada, que incluye el permiso
aiplatform.endpoints.predictnecesario para obtener predicciones de tu endpoint de Vertex AI.Esta función también realiza un preprocesamiento útil en las solicitudes. El endpoint de Vertex AI espera solicitudes de predicción en el formato de la primera capa del gráfico de TensorFlow Keras entrenado: un tensor de flotantes normalizados con dimensiones fijas. La función toma la URL de una imagen como entrada y la preprocesa en este formato antes de solicitar una predicción al endpoint de Vertex AI.
En la Google Cloud consola, en la sección Vertex AI, ve a la página Endpoints (Endpoints).
Busca la fila del endpoint que has creado en la sección anterior, llamado
hello_custom. En esta fila, haz clic en Solicitud de muestra para abrir el panel Solicitud de muestra.En el panel Solicitud de ejemplo, busca la línea de código shell que coincida con el siguiente patrón:
ENDPOINT_ID="ENDPOINT_ID"
ENDPOINT_ID es un número que identifica este endpoint concreto.
Copia esta línea de código y ejecútala en tu sesión de Cloud Shell para definir la variable
ENDPOINT_ID.Ejecuta el siguiente comando en tu sesión de Cloud Shell para implementar la función de Cloud Run:
gcloud functions deploy classify_flower \ --region=us-central1 \ --source=function \ --runtime=python37 \ --memory=2048MB \ --trigger-http \ --allow-unauthenticated \ --set-env-vars=ENDPOINT_ID=${ENDPOINT_ID}Define un par de variables de shell para que los comandos de los pasos siguientes las usen:
PROJECT_ID=PROJECT_ID BUCKET_NAME=BUCKET_NAMEHaz los cambios siguientes:
- PROJECT_ID: ID de tu Google Cloud proyecto.
- BUCKET_NAME: el nombre del segmento de Cloud Storage que creaste en la primera página de este tutorial.
Edita la aplicación para proporcionarle la URL del activador de tu función de Cloud Run:
echo "export const CLOUD_FUNCTION_URL = 'https://us-central1-${PROJECT_ID}.cloudfunctions.net/classify_flower';" \ > webapp/function-url.jsSube el directorio
webappa tu segmento de Cloud Storage:gcloud storage cp webapp gs://${BUCKET_NAME}/ --recursiveHaz que los archivos de la aplicación web que acabas de subir sean legibles públicamente:
gcloud storage objects update gs://${BUCKET_NAME}/webapp/** --add-acl-grant=entity=allUsers,role=READERAhora puede ir a la siguiente URL para abrir la aplicación web y obtener predicciones:
https://storage.googleapis.com/BUCKET_NAME/webapp/index.html
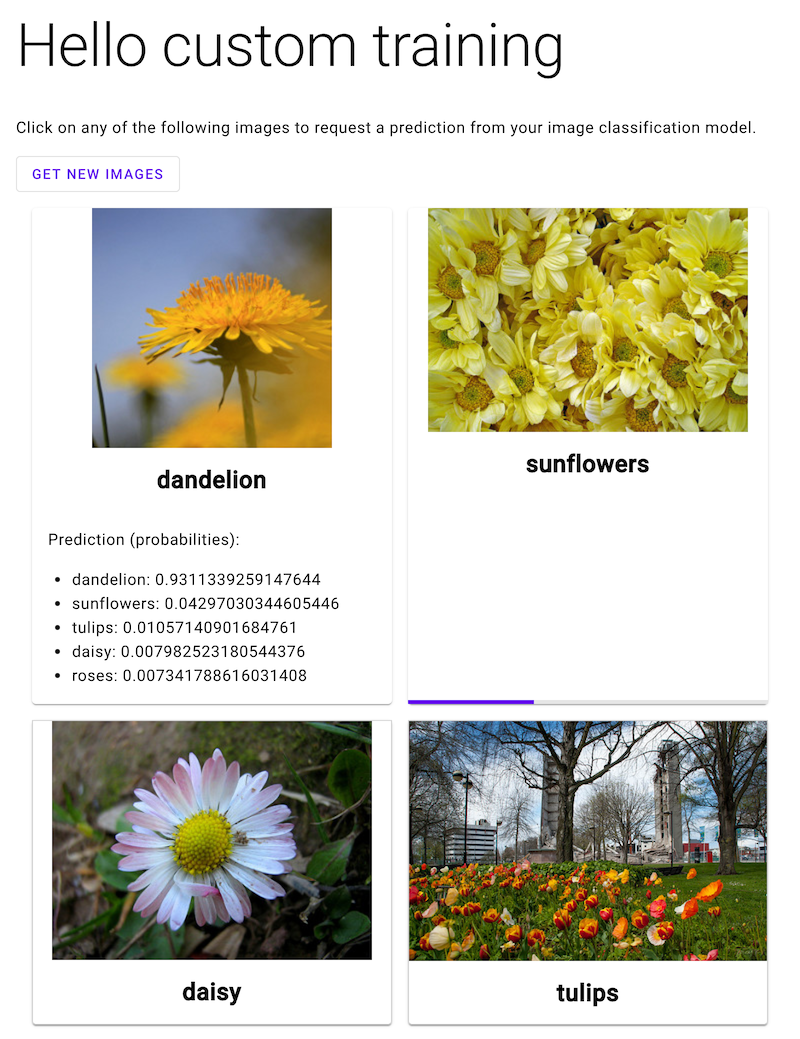
Abre la aplicación web y haz clic en la imagen de una flor para ver la clasificación del tipo de flor que ha hecho tu modelo de aprendizaje automático. La aplicación web muestra la predicción como una lista de tipos de flores y la probabilidad de que la imagen contenga cada tipo de flor.
Crear un punto final
Para obtener predicciones online del modelo de aprendizaje automático que has entrenado en la página anterior de este tutorial, crea un endpoint de Vertex AI. Los endpoints publican predicciones online de uno o varios modelos.
Al cabo de unos minutos, aparecerá junto al nuevo endpoint en la tabla Endpoints. Al mismo tiempo, también recibirás un correo en el que se te indicará que has creado correctamente el endpoint y has desplegado tu modelo en él.
Desplegar una función de Cloud Run
Para obtener predicciones del endpoint de Vertex AI que acabas de crear, envía solicitudes a la interfaz REST de la API de Vertex AI. Sin embargo, solo las entidades con el permiso aiplatform.endpoints.predict pueden enviar solicitudes de predicción online. No puedes hacer que el endpoint sea público para que cualquier persona pueda enviar solicitudes, por ejemplo, a través de una aplicación web.
En esta sección, desplegarás código en Cloud Run functions para gestionar solicitudes no autenticadas. El código de ejemplo que descargaste cuando leíste la primera página de este tutorial contiene el código de esta función de Cloud Run en el directorio function/. También puedes ejecutar el siguiente comando para consultar el código de la función de Cloud Run:
less function/main.py
Implementar la función tiene los siguientes objetivos:
Para desplegar la función de Cloud Run, haz lo siguiente:
Desplegar una aplicación web para enviar solicitudes de predicción
Por último, aloja una aplicación web estática en Cloud Storage para obtener predicciones de tu modelo de AA entrenado. La aplicación web envía solicitudes a tu función de Cloud Run, que las preprocesa y obtiene predicciones del endpoint de Vertex AI.
El directorio webapp del código de ejemplo que has descargado contiene una aplicación web de ejemplo. En tu sesión de Cloud Shell, ejecuta los siguientes comandos para preparar y desplegar la aplicación web:
En la siguiente captura de pantalla, la aplicación web ya ha recibido una predicción y está enviando otra solicitud de predicción.
Siguientes pasos
Sigue las instrucciones de la última página del tutorial para eliminar los recursos que has creado.