Assuming you have already run the tutorials, this page outlines the best practices for Neural Architecture Search. The first section summarizes a complete workflow, which you can follow for your Neural Architecture Search job. The other sections provide a detailed description for each step. We highly recommend going through this entire page before running your first Neural Architecture Search job.
Suggested workflow
Here we summarize a suggested workflow for Neural Architecture Search and provide links to the corresponding sections for more details:
- Split your training dataset for stage-1 search.
- Ensure that your search space follows our guidelines.
- Run full training with your baseline model and obtain a validation curve.
- Run proxy-task design tools to find the best proxy task.
- Make final checks for your proxy task.
- Set proper number of total trials and parallel trials and then start the search.
- Monitor the search plot and stop it when it converges or shows large number of errors or shows no sign of convergence.
- Run full-training with top ~10 trials chosen from your search for the final result. For full-training, you may use more augmentation or pre-trained weights to get the best possible performance.
- Analyze the saved out metrics/data from the search and draw conclusions for future search space iterations.
Typical Neural Architecture Search
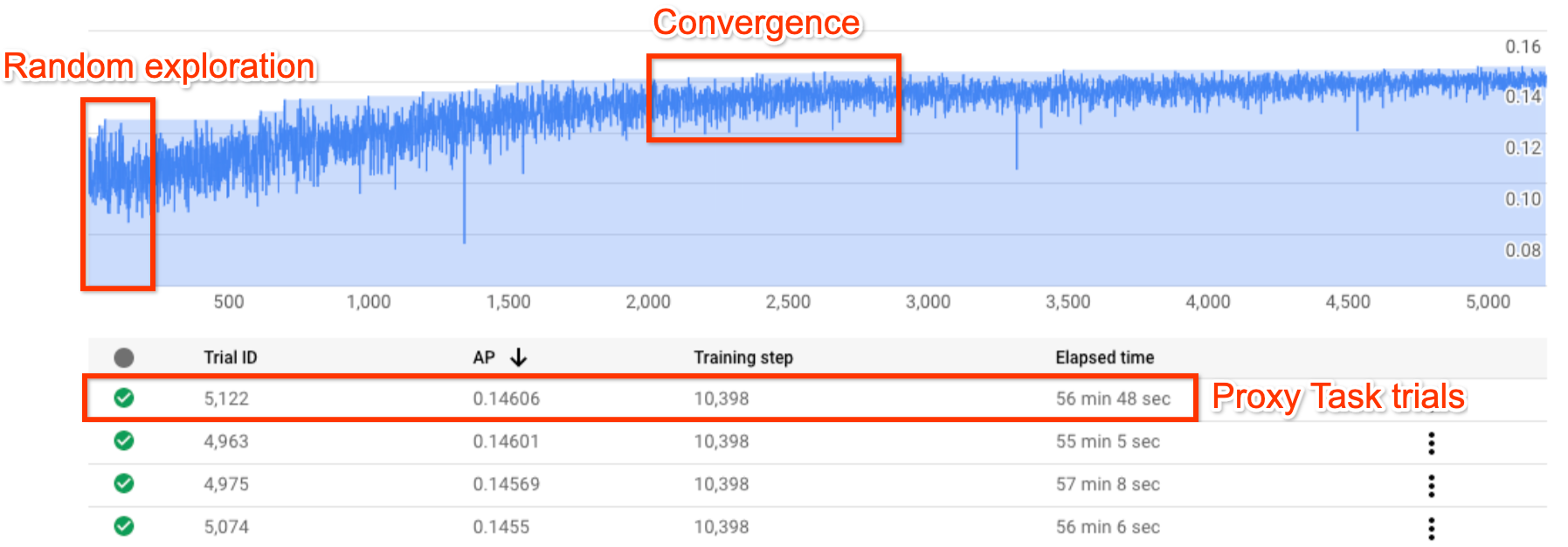
The above figure shows a typical Neural Architecture Search curve.
The Y-axis here shows the trial-rewards and the
X-axis shows the number of trials launched so far.
The first ~100-200 trials are mostly random explorations
of the search space by the controller.
During these initial explorations, the rewards show
a large variance because many kinds of models in
the search space are being tried out.
As the number of trials increase, the controller starts finding better
models. Therefore, first the reward starts increasing and then later the
reward-variance and the reward-growth starts decreasing
thus showing convergence. The number of trials
at which the convergence happens can vary based on the
search-space size but typically it is of the order of ~2000 trials.
Two stages of Neural Architecture Search: proxy-task and full training
The Neural Architecture Search works in two stages:
Stage1-search uses a much smaller representation of the full training which typically finishes within ~1-2 hours. This representation is called a proxy task and it helps keep the search cost down.
Stage2-full-training involves doing full-training for the top ~10 scoring models from stage1-search. Due to the stochastic nature of the search, the topmost model from stage1-search may not be the topmost model during the stage2-full-training and, therefore, it is important to select a pool of models for full-training.
Because the controller gets the reward signal from the smaller proxy task instead of the complete training, it is important to find an optimal proxy-task for your task.
Neural Architecture Search cost
The Neural Architecture Search cost is given by:
search-cost = num-trials-to-converge * avg-proxy-task-cost.
Assuming that the proxy-task compute time is around 1/30th of the
full-training time and the number of trials required to converge
is around ~2000, then the
search cost becomes ~ 67 * full-training-cost.
Since the Neural Architecture Search cost is high, it is advisable to spend time tuning your proxy task and to use a smaller search space for your first search.
Dataset split between two stages of Neural Architecture Search
Assuming that you already have the training-data and the validation-data for your baseline training, the following dataset split is recommended for the two stages of NAS Neural Architecture Search:
- Stage1-search training: ~90% of training-data
Stage1-search validation: ~10% of training-data
Stage2-full-training training: 100% of training-data
Stage2-full-training validation: 100% of validation-data
The stage2-full-training data split is the same as the regular training. But, the stage1-search uses a training data split for validation. Using different validation data in stage1 and stage2 helps detect any model-search bias due to the dataset split. Ensure that the training-data is well shuffled before partitioning it further and that the final 10% training-data-split has similar distribution as the original validation data.
Small or unbalanced data
Architecture search is not recommended with limited training data or for highly imbalanced datasets where some classes are very rare. If you are already using heavy augmentations for your baseline training due to lack of data, then the model-search is not recommended.
In this case you may only run the augmentation-search to search for the best augmentation policy rather than searching for an optimal architecture.
Search space design
The architecture search should not be mixed with augmentation search or hyperparameter search (such as learning rate or optimizer settings). The goal of architecture search is to compare model-A performance with model-B when there are only architecture-based differences. Therefore, the augmentation and hyperparameter settings should remain the same.
The augmentation search can be done as different stage after the architecture search is done.
Neural Architecture Search can go up to 10^20 in search space size. But if your search space is larger, you can divide your search space into mutually-exclusive parts. For example, you can search for encoder separately from the decoder or the head first. If you still want to do a joint search over all of them, then you can create a smaller search space around previously found best individual options.
(Optional) You can model-scaling from block-design when designing a search space. The block design search should be done first with a scaled-down model. This can keep the cost of proxy-task runtime much lower. You can then do a separate search to scale the model up. For more information, see
Examples of scaled down models.
Optimizing training and search time
Before running Neural Architecture Search, it is important to optimize the training time for your baseline model. This will save you cost over the long run. Here are some of the options to optimize the training:
- Maximize data loading speed:
- Ensure that the bucket where your data resides is in the same region as your job.
- If using TensorFlow, see
Best practice summary. You may also try using TFRecord format for your data. - If using PyTorch, follow the guidelines for efficient PyTorch training.
- Use distributed training to take advantage of multiple accelerators or multiple machines.
- Use mixed precision training
to get significant training speedup and reduction in memory usage.
For TensorFlow mixed precision training,
see
Mixed Precision. - Some accelerators (like A100) are typically more cost efficient.
- Tune the batch-size to ensure that you are maximizing GPU utilization.
The following plot shows under-utilization of GPUs (at 50%).
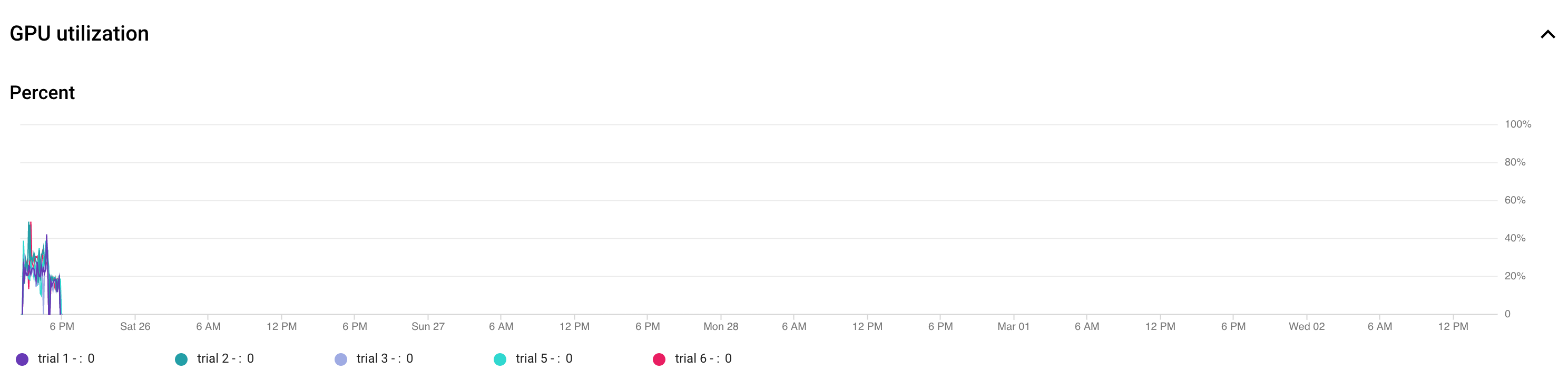 Increasing the batch-size can help utilize GPUs more. However, batch-size
should be increased carefully as it can increase
out-of-memory errors during the search.
Increasing the batch-size can help utilize GPUs more. However, batch-size
should be increased carefully as it can increase
out-of-memory errors during the search. - If certain architecture-blocks are independent of the search space, then you can try loading pretrained checkpoints for these blocks for faster training. The pretrained checkpoints should be the same over the search space and should not introduce a bias. For example, if your search space is only for the decoder, then the encoder can use pretrained checkpoints.
Number of GPUs for each search-trial
Use a smaller number of GPUs per trial to reduce the starting time. For example, 2 GPUs take 5 minutes to start, while 8 GPUs take 20 minutes. It is more efficient to use 2 GPUs per trial to run a Neural Architecture Search job proxy task.
Total trials and parallel trials for search
Total trial setting
Once you have searched and selected the best proxy task, you are ready to launch a full search. It isn't possible to know beforehand about how many trials it will take to converge. The number of trials at which the convergence happens can vary based on the search-space size, but typically, it is of the order of approximately 2,000 trials.
We recommend a very high setting
for the --max_nas_trial: approximately 5,000-10,000 and then
canceling the search-job earlier if the
search plot shows convergence.
You also have an option to resume a previous search job using
the search_resume command.
However, you can't resume the search from another search resume job.
Therefore, you can resume an original search job only once.
Parallel trials setting
The stage1-search job does batch processing by running
--max_parallel_nas_trial number of trials in parallel
at a time. This is critical in reducing the overall runtime
for the search job. You can calculate the expected number of
days for search:
days-required-for-search = (trials-to-converge / max-parallel-nas-trial) * (avg-trial-duration-in-hours / 24)
Note: You can initially use 3000 as a rough
estimate for trials-to-converge which is a good
upper bound to begin with. You can initially use 2 hours
as a rough estimate for the avg-trial-duration-in-hours which
is a good upper bound for the time taken by each proxy task.
It is advisable to
use --max_parallel_nas_trial setting of
~20-to-50 depending on how much accelerator quota
your project has and
days-required-for-search.
For example, if you set --max_parallel_nas_trial as 20
and each proxy task uses two NVIDIA T4 GPUs, then you should have
reserved a quota of at least 40 NVIDIA T4 GPUs. The
--max_parallel_nas_trial setting does not affect the overall search
result, but it does impact the days-required-for-search.
A smaller setting for max_parallel_nas_trial
such as approximately 10 is possible (20 GPUs) as well but then you should
roughly estimate the days-required-for-search and, make sure that
it is within the job timeout limit.
The stage2-full-training job typically trains all the trials in parallel by default. Typically, this is top 10 trials running in parallel. However, if each stage2-full-training trial uses too many GPUs (example, eight GPUs each) for your use case and you don't have a sufficient quota, then you can manually run stage2 jobs in batches such as run a stage2-full-training for just five trials first and then run another stage2-full-training for next 5 trials.
Default job timeout
The default NAS job timeout is set to 14 days and after that, the job gets canceled. If you anticipate running the job for a longer duration, you can try resuming the search job only once more for 14 more days. Overall, you can run a search job for 28 days including resume.
Max failed trials setting
The max failed trials should be set to around 1/3th of max_nas_trial
setting. The job will get cancelled when the number of
failed trials reach this limit.
When to stop the search
You should stop the search when:
The search-curve starts to converge (the variance decreases):
Note: If no latency constraint is used or the hard latency constraint
is used with loose latency limit, then the curve may not show an
increase in reward but should still show convergence. This is because
the controller may already have seen good accuracies
early on in the search.More than 20% of your trials are showing invalid rewards (failures):
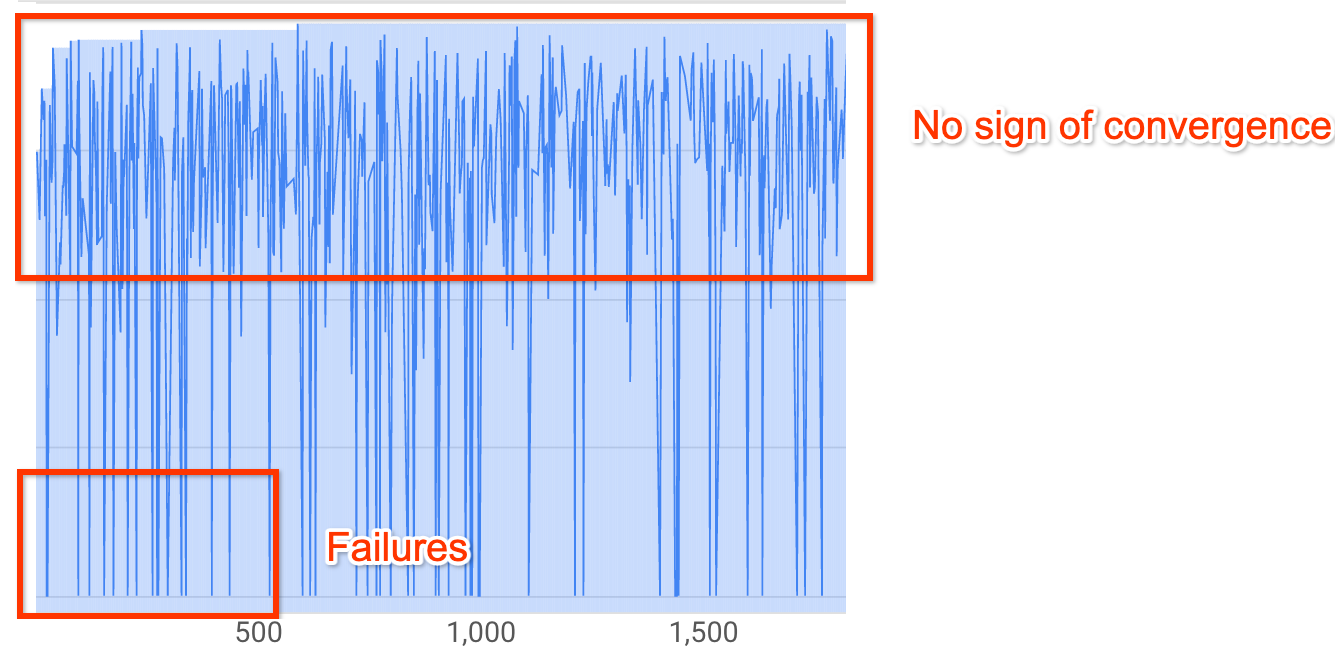
The search curve neither increases nor converges (as shown above) even after ~500 trials. If it shows any of the reward increase or variance decrease then you can continue.