Bevor Sie einen NAS-Job (Neural Architecture Search) ausführen, um nach einem optimalen Modell zu suchen, definieren Sie Ihre Proxy-Aufgabe. Stage1-search verwendet eine viel kleinere Darstellung eines vollständigen Modelltrainings, die normalerweise innerhalb von zwei Stunden abgeschlossen ist. Diese Darstellung wird alsProxyaufgabe und verringert dieSuchkosten erheblich. Bei jedem Test während der Suche wird ein Modell mit den Einstellungen der Proxy-Aufgabe trainiert.
In den folgenden Abschnitten wird beschrieben, was bei der Anwendung von Proxyaufgaben berücksichtigt wird:
- Ansätze zum Erstellen einer Proxyaufgabe
- Anforderungen einer guten Proxyaufgabe.
- Informationen dazu, wie Sie mit den drei Proxy-Aufgabendesigns die optimale Proxyaufgabe ermitteln, die die Suchkosten senkt und die Qualität der Suche beibehält.
Ansätze zum Erstellen einer Proxyaufgabe
Es gibt drei gängige Methoden zum Erstellen einer Proxyaufgabe, die Folgendes umfassen:
- Verwenden Sie weniger Trainingsschritte.
- Verwenden Sie ein Trainings-Dataset mit Stichproben.
- Verwenden Sie ein reduziertes Modell.
Weniger Trainingsschritte verwenden
Die einfachste Methode zum Erstellen einer Proxyaufgabe besteht darin, die Anzahl der Trainingsschritte für Ihren Trainer zu reduzieren und eine Punktzahl auf der Grundlage dieses partiellen Trainings an den Controller zu melden.
Teilweises Trainings-Dataset verwenden
In diesem Abschnitt wird die Verwendung eines Teildatensatz-Trainings-Datasets für eine Architektursuche und eine Erweiterungsrichtliniensuche beschrieben.
Architektursuche
Eine Proxyaufgabe kann durch Verwendung eines Teilstichproben-Trainings-Datasets während der Architektursuche erstellt werden. Beachten Sie beim Subsampling jedoch folgende Richtlinien:
- Vermischen Sie die Daten willkürlich zwischen den Shards.
- Wenn die Trainingsdaten nicht ausgeglichen sind, führen Sie eine Teilprobe aus, um sie auszugleichen.
Suche nach Benachrichtigungsrichtlinie mithilfe der automatischen Erweiterung
Überspringen Sie diesen Abschnitt, wenn Sie nur die reguläre Architektursuche und keine Suche mit Datenaugmentation ausführen. Verwenden Sie die automatische Erweiterung, um nach Erweiterungsrichtlinien zu suchen. Es ist wünschenswert, die Trainingsdaten vorab zu erfassen und ein vollständiges Training auszuführen, als die Anzahl der Trainingsschritte zu reduzieren. Wenn Sie ein vollständiges Training mit starker Erweiterung ausführen, bleiben die Punktzahlen stabiler. Verwenden Sie außerdem die reduzierten Trainingsdaten, um die Suchkosten zu senken.
Proxyaufgabe basierend auf dem herunterskalierten Modell
Sie können das Modell auch relativ zum Basismodell herunterskalieren, um eine Proxyaufgabe zu erstellen. Dies ist auch nützlich, wenn Sie block-design-search von scale-search trennen möchten.
Wenn Sie jedoch das Modell herunterskalieren und eine Latenzbeschränkung verwenden möchten, verwenden Sie eine engere Latenzeinschränkung für das herunterskalierte Modell. Hinweis: Sie können das Basismodell herunterskalieren und seine Latenz messen, um diese strengere Latenzeinschränkung festzulegen.
Für das herunterskalierte Modell können Sie auch den Umfang der Erweiterung und Regularisierung im Vergleich zum ursprünglichen Basismodell reduzieren.
Beispiele für ein reduziertes Modell
Für Computer Vision-Aufgaben, bei denen Sie mit Bildern trainieren, gibt es drei gängige Methoden zum Herunterskalieren eines Modells:
- Modellbreite reduzieren: Anzahl der Kanäle.
- Modelltiefe reduzieren: Anzahl der Ebenen und Blockwiederholungen.
- Größe des Trainingsbilds wurde geringfügig reduziert, sodass sich keine Merkmale entfernen oder Trainingsbilder zugeschnitten werden, sofern dies von Ihrer Aufgabe zugelassen wird.
Vorgeschlagener Lesevorgang: Das EfficientNet-Papier bietet gute Einblicke in die Modellskalierung für Aufgaben des maschinellen Sehens. Außerdem wird erläutert, wie alle drei Skalierungsmöglichkeiten miteinander zusammenhängen.
Spinenet-Suche ist ein weiteres Beispiel für die Modellskalierung mit der Neural Architecture Search. Bei stage1-search wird die Anzahl der Kanäle und die Bildgröße herunterskaliert.
Proxyaufgabe auf Basis einer Kombination
Die Ansätze funktionieren unabhängig und können in unterschiedlichen Grad kombiniert werden, um eine Proxy-Aufgabe zu erstellen.
Anforderungen an eine gute Proxyaufgabe
Eine Proxyaufgabe muss bestimmte Anforderungen erfüllen, bevor sie dem Controller eine stabile Belohnung zurückgeben und die Qualität der Suche aufrechterhalten..
Rangkorrelation zwischen stage-1-Suche und vollständigem stage2-Training
Bei der Verwendung einer Proxy-Aufgabe für die Neural Architecture Search ist eine Schlüsselannahme für eine erfolgreiche Suche, dass, wenn Modell-A beim Training der Proxy-Aufgabe in Phase 1 besser abschneidet als Modell-B, Modell-A auch beim vollständigen Training in Phase 2 besser abschneiden wird als Modell-B. Zur Prüfung dieser Annahme sollten Sie die Rangkorrelation zwischen der Suche in Phase 1 und den vollen Trainingsprämien in Phase 2 an ~10 Modellen in Ihrem Suchbereich auswerten. Diese Modelle werden als Korrelationskandidatenmodelle bezeichnet.
Die folgende Abbildung zeigt ein Beispiel für eine schlechte Korrelation (Korrelationspunktzahl - 0,03), die diese Proxy-Aufgabe zu einem schlechten Kandidaten für eine Suche macht:
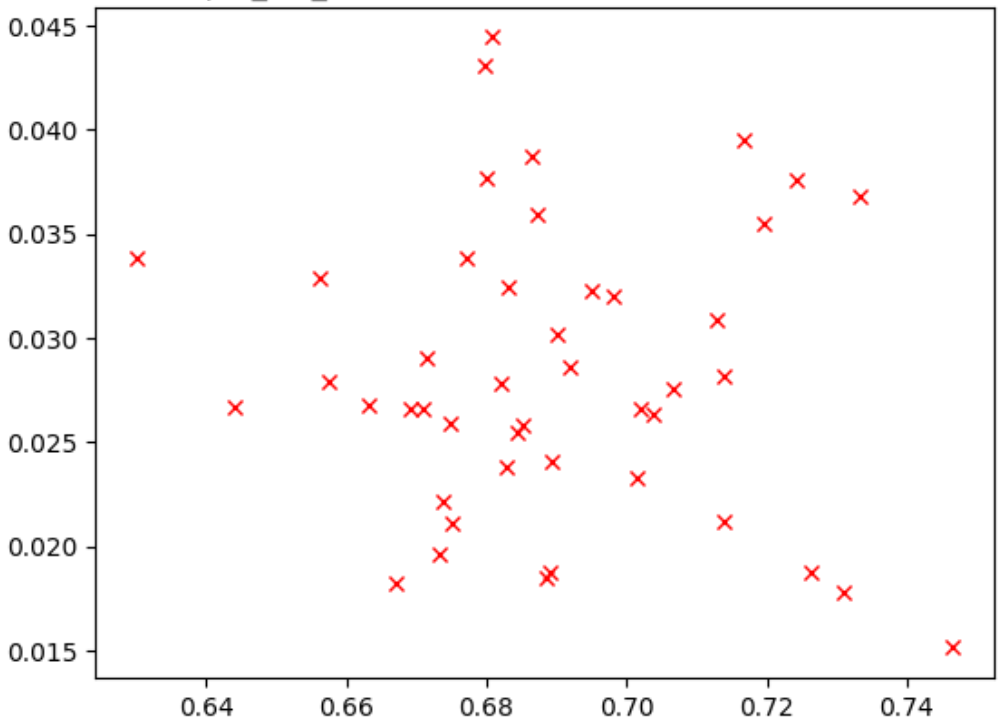
Jeder Punkt im Diagramm stellt ein Korrelationskandidatenmodell dar.
Die x-Achse repräsentiert die vollständigen stage-2-Trainingsphasen für die Modelle und die y-Achse die Punktzahl-Proxy-Aufgabenpunktzahlen für die gleichen Modelle.
Beobachten Sie den höchsten Punkt. Dieses Modell hat den höchsten Wert für die Proxyaufgabe (y-Achse), aber bietet eine schlechte Leistung während des vollständigen stage-2-Trainingsphase (x-Achse) im Vergleich zu anderen Modellen. Im Gegensatz dazu zeigt die folgende Abbildung ein Beispiel für eine gute Korrelation (Korrelationspunktzahl = 0,67), die diese Proxyaufgabe zu einem guten Kandidaten für eine Suche macht:

Wenn Ihre Suche eine Latenzbeschränkung aufweist, prüfen Sie auch eine gute Korrelation für Latenzwerte.
Die Präferenzen der Korrelationskandidaten haben einen guten Bereich und ein angemessenes Sampling des Prämienbereichs. Wenn nicht, können Sie die Rangkorrelation nicht auswerten. Wenn beispielsweise die Phasen-Korrelationskandidaten der Phase 1 um nur zwei Werte zentriert werden: 0,9 und 0,1, ergibt dies nicht genügend Stichprobenabweichung.
Varianzprüfung
Eine weitere Anforderung einer Proxyaufgabe ist, dass sie keine großen Abweichungen bei der Genauigkeit oder dem Latenzwert haben sollte, wenn sie für dasselbe Modell ohne Änderungen wiederholt werden. In diesem Fall gibt es ein "Rauschen"-Signal an den Controller zurück. Ein Tool zum Messen dieser Varianz wird bereitgestellt.
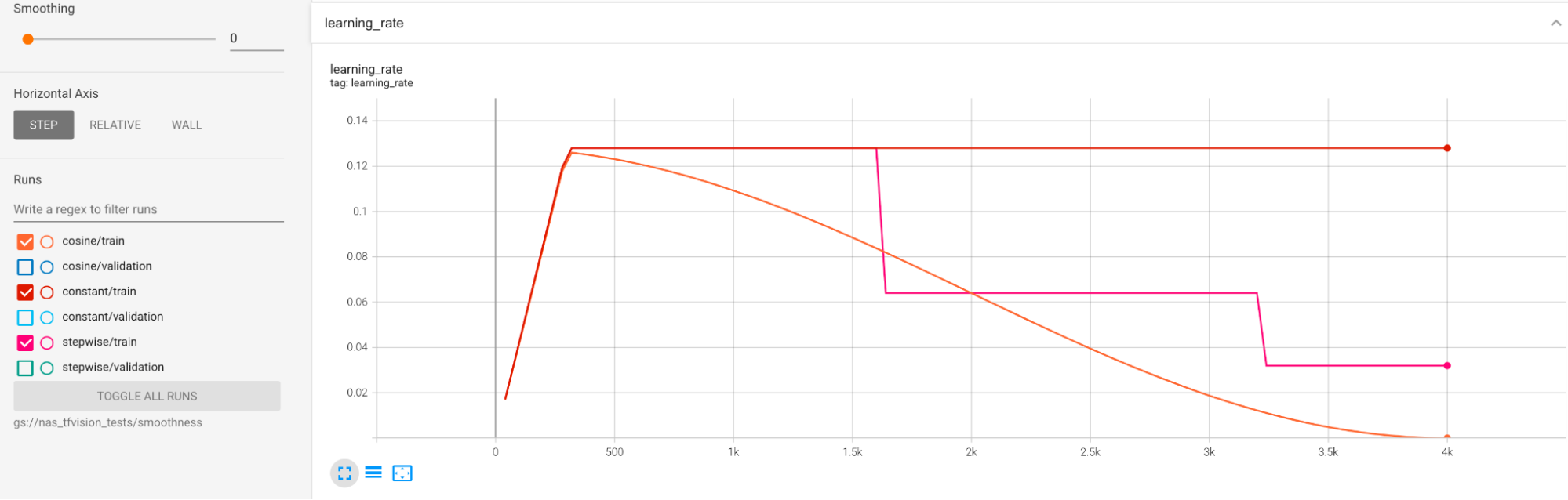
Beispiele werden bereitgestellt, um große Abweichungen während des Trainings zu minimieren. Eine Möglichkeit ist die Verwendung von cosine decay als Lernplan. Im folgenden Diagramm werden drei Strategien für die Lernrate verglichen:

Die niedrigste Darstellung entspricht einer konstanten Lernrate. Wenn der Wert am Ende des Trainings springt, kann eine kleine Änderung der Auswahl der reduzierten Trainingsschritte zu einer großen Änderung der endgültigen Prämienaufgabe in der Proxyaufgabe führen. Damit die Proxyaufgaben-Prämie stabiler wird, ist es besser, einen Abfall der Kosinus-Lernrate zu verwenden, wie durch die entsprechenden Validierungsergebnisse im höchsten Diagramm dargestellt. Beachten Sie, wie die höchste Darstellung am Ende des Trainings gleichmäßiger wird. Die mittlere Darstellung zeigt die Punktzahl, die dem schrittweisen Abfall der Lernrate entspricht. Sie ist besser als die konstante Rate, aber noch nicht so gleichmäßig wie der Kosinus-Abklinger und erfordert auch eine manuelle Abstimmung.
Die Zeitpläne für die Lernrate werden unten dargestellt:
Zusätzliche Glättung
Wenn Sie eine starke Erweiterung verwenden, wird Ihre Validierungskurve möglicherweise noch nicht stabil genug mit dem Kosinus-Abfall. Eine starke Erweiterung zeigt an, dass keine Trainingsdaten vorhanden sind. In diesem Fall wird die Verwendung der neuronalen Suche nicht empfohlen. Wir empfehlen stattdessen die Verwendung der augmentation-search.
Wenn die starke Erweiterung nicht die Ursache ist und Sie den Kosinusabfall bereits getestet haben, aber trotzdem eine gleichmäßigere Ausführung erreichen möchten, verwenden Sie den exponentiellen gleitenden Durchschnitt für TensorFlow-2 oder den stochastic-Weighted-averaging für PyTorch. In diesem Codepunkt finden Sie ein Beispiel, in dem das Optimierungstool für exponentielle gleitende Mittelwerte mit TensorFlow 2 verwendet wird, und dieses Beispiel für stochastisch-gewichtete Mittelwerte für PyTorch.
Wenn Ihre Genauigkeits-/Epochendiagramme für Tests so aussehen:

können Sie die oben erwähnten Glättungstechniken (z. B. stochastische gewichtete Durchschnittsverwaltung oder die Verwendung des exponentiellen gleitenden Durchschnitts) anwenden, um einen konsistenteren Graphen zu erhalten, wie:

OOM-Fehler (Out-of-Memory) und Fehler im Zusammenhang mit der Lernrate
Der Architektursuchbereich kann Modelle generieren, die viel größer sind als Ihre Referenz. Möglicherweise haben Sie die Batchgröße für das Basismodell optimiert. Diese Einstellung schlägt jedoch möglicherweise fehl, wenn bei der Suche größere Modelle abgetastet werden, was zu OOM-Fehlern führt. In diesem Fall müssen Sie die Batchgröße reduzieren.
Die andere Art von Fehler, die angezeigt wird, ist der NaN-Fehler (Not-a-Number). Sie sollten entweder die anfängliche Lernrate reduzieren oder das Gradienten-Cliping hinzufügen.
Wie in Anleitung-2 erwähnt, wird nicht die vollständige Suche ausgeführt, wenn mehr als 20 % Ihrer Suchbereichsmodelle ungültige Punktzahlen zurückgeben. Unsere Proxy-Task-Designtools bieten eine Möglichkeit, die Fehlerrate zu bewerten.
Designtools für Proxyaufgaben
In den vorherigen Abschnitten werden die Prinzipien des Proxy-Aufgabendesigns erläutert. Dieser Abschnitt enthält drei Tools zur Gestaltung von Proxy-Aufgaben, um automatisch die optimale Proxy-Aufgabe basierend auf den verschiedenen Designansätzen zu finden, die alle Anforderungen erfüllt.
Erforderliche Codeänderungen
Sie müssen den Trainercode zuerst leicht ändern, damit er während eines iterativen Prozesses mit den Designtools der Proxyaufgabe interagieren kann.
Die tf_vision/train_lib.py zeigt ein Beispiel. Sie müssen zuerst unsere Bibliothek importieren:
from google.cloud.visionsolutions.nas.proxy_task import proxy_task_utils
Bevor ein Trainingszyklus in Ihrer Trainingsschleife beginnt, sollten Sie prüfen, ob Sie das Training frühzeitig beenden müssen, da das Proxy-Task-Design-Tool Sie auf unsere Bibliothek ausgelegt ist:
if proxy_task_utils.get_stop_training(
model_dir,
end_training_cycle_step=<last-training-step-idx done so far>,
total_training_steps=<total-training-steps>):
break
Nachdem jeder Trainingszyklus in der Trainingsschleife abgeschlossen wurde, aktualisieren Sie den neuen Genauigkeitswert, den Beginn und das Ende des Trainingszyklus, die Trainingszykluszeit in Sekunden und die gesamten Trainingsschritte.
proxy_task_utils.update_trial_training_accuracy_metric(
model_dir=model_dir,
accuracy=<latest accuracy value>,
begin_training_cycle_step=<beginning training step for this cycle>,
end_training_cycle_step=<end training step for this cycle>,
training_cycle_time_in_secs=<training cycle time (excluding validation)>,
total_training_steps=<total-training-steps>)
Beachten Sie, dass die Zeit des Trainingszyklus keine Zeit für die Bewertung des Validierungsergebnisses enthalten sollte. Achten Sie darauf, dass der Trainer häufig Validierungsergebnisse berechnet (Bewertungshäufigkeit), damit Sie genügend Stichproben der Validierungskurve haben. Wenn Sie die Latenzeinschränkung verwenden, aktualisieren Sie den Latenzmesswert, nachdem Sie Latenz berechnen:
proxy_task_utils.update_trial_training_latency_metric(
model_dir=model_dir,
latency=<measured_latency>)
Für das Modellauswahltool muss der vorherige Prüfpunkt für die aufeinanderfolgende Iteration geladen werden.
Fügen Sie Ihrem Trainer ein Flag hinzu, um die Wiederverwendung eines vorherigen Prüfpunkts zu aktivieren, wie in tf_vision/cloud_search_main.py gezeigt:
parser.add_argument(
"--retrain_use_search_job_checkpoint",
type=cloud_nas_utils.str_2_bool,
default=False,
help="True to use previous NAS search job checkpoint."
)
Laden Sie diesen Prüfpunkt, bevor Sie Ihr Modell trainieren:
if FLAGS.retrain_use_search_job_checkpoint:
prev_checkpoint_dir = cloud_nas_utils.get_retrain_search_job_model_dir(
retrain_search_job_trials=FLAGS.retrain_search_job_trials,
retrain_search_job_dir=FLAGS.retrain_search_job_dir)
logging.info("Setting checkpoint to %s.", prev_checkpoint_dir)
# Now set your checkpoint using 'prev_checkpoint_dir'.
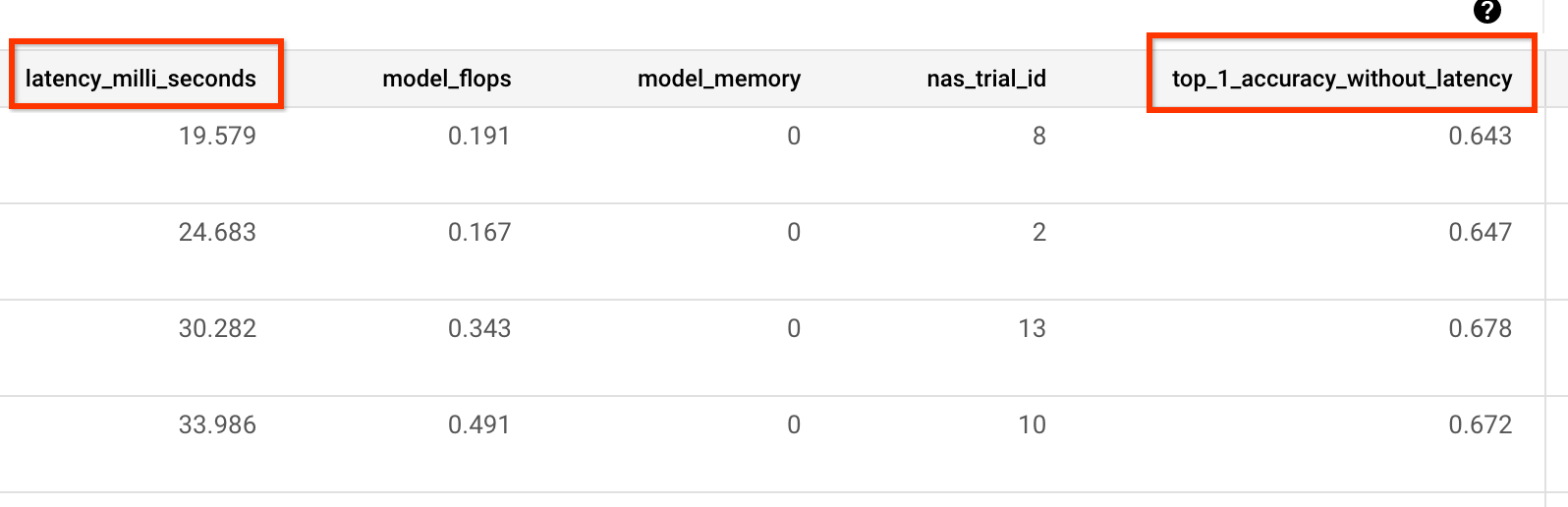
Sie benötigen außerdem den metric-id, der den von Ihrem Trainer gemeldeten Genauigkeits- und Latenzwerten entspricht. Wenn sich die Trainerbelohnung (die manchmal eine Kombination aus Genauigkeit und Latenz darstellt) von der Genauigkeit unterscheidet, dann stellen Sie sicher, dass Sie auch auch die reine Genauigkeitskennzahl mit other_metrics von Ihrem Trainer zurückmelden.
Das folgende Beispiel zeigt beispielsweise nur Genauigkeits- und Latenzmesswerte, die von unserem vordefinierten Trainer gemeldet wurden:
Varianzmessung
Nachdem Sie den Trainercode geändert haben, besteht der erste Schritt darin, die Varianz für den Trainer zu messen. Ändern Sie für die Varianzmessung die Referenztrainingskonfiguration so:
- Verringern Sie die Trainingsschritte, sodass die Ausführung nur etwa eine Stunde mit nur einer oder zwei GPUs benötigt. Wir benötigen ein kleines Sample für ein vollständiges Training.
- Verwenden Sie die Kosinus-Abkling-Lernrate und legen Sie deren Schritte so fest, dass diese Lernschritte fast null erreichen.
Das Tool zur Varianzmessung erstellt ein Modell aus dem Suchbereich. Es sorgt dafür, dass dieses Modell das Training ohne OOM- oder NAN-Fehler starten kann. Es führt fünf Kopien dieses Modells mit Ihren Einstellungen für etwa eine Stunde aus und meldet dann die Varianz und Glättung des Trainingswerts. Die Gesamtkosten für die Ausführung dieses Tools entsprechen ungefähr den Kosten für die Ausführung von fünf Modellen mit Ihren Einstellungen für etwa eine Stunde.
Starten Sie den Job für die Varianzmessung. Führen Sie dazu folgenden Befehl aus. Sie benötigen dazu ein Dienstkonto:
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
region=<your job region such as 'us-central1'>
search_space_module=<path to your search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
####### Variance measurement related parameters ######
proxy_task_variance_measurement_docker_id=${USER}_variance_measurement_${DATE}
# Use the service account that you set-up for your project.
service_account=<your service account>
job_name=<your job name>
############################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--proxy_task_variance_measurement_docker_id=${proxy_task_variance_measurement_docker_id}
# The command below passes 'dummy' arguments for the training docker.
# You need to modify them for your own docker.
python3 vertex_nas_cli.py measure_proxy_task_variance \
--proxy_task_variance_measurement_docker_id=${proxy_task_variance_measurement_docker_id} \
--project_id=${project_id} \
--service_account=${service_account} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
Sobald Sie diesen Job zur Messung der Varianz gestartet haben, erhalten Sie einen Job-Link. Der Jobname muss mit dem Präfix Variance_Measurement beginnen. Hier sehen Sie ein Beispiel für eine Job-UI:
variance_measurement_dir enthält alle Ausgaben. Sie können die Logs durch Klicken auf den Link Logs ansehen prüfen.
Dieser Job verwendet standardmäßig eine CPU in der Cloud, um im Hintergrund als benutzerdefinierter Job ausgeführt zu werden, und startet und verwaltet dann untergeordnete NAS-Jobs.
Unter NAS-Jobs wird ein Job mit dem Namen Find_workable_model_<your job name> angezeigt. Bei diesem Job wird ein Suchbereich für das Modell gesucht, um ein Modell zu finden, das keinen Fehler generiert. Sobald ein solches Modell gefunden wird, startet der Varianzmessungsjob einen weiteren NAS-Job <your job name>, der fünf Kopien dieses Modells für die Anzahl der Trainingsschritte ausführt, die Sie zuvor festgelegt haben. Sobald das Training für diese Modelle abgeschlossen ist, misst der Varianzmessungsjob seine Punktzahlabweichung und -glättung und meldet diese in den Logs:
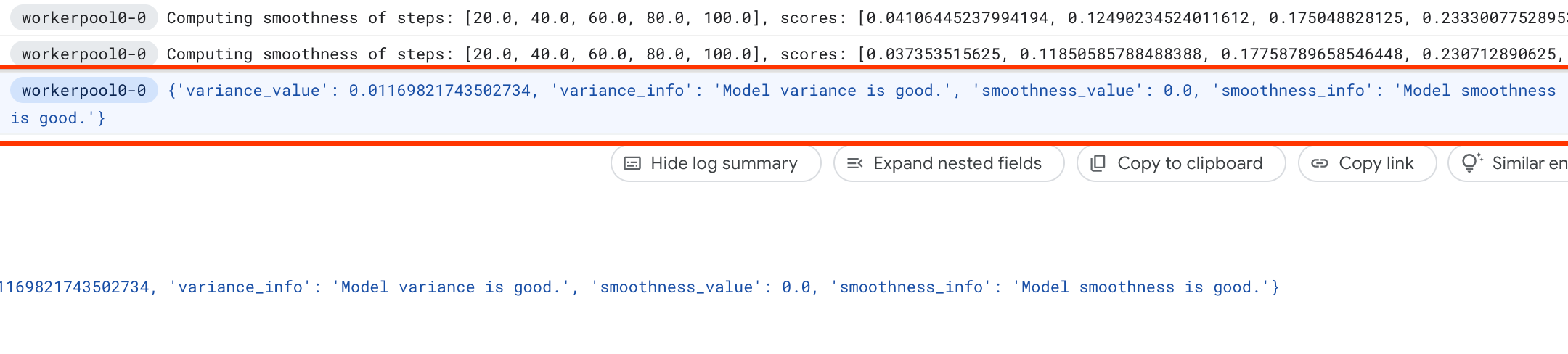
Wenn die Varianz hoch ist, können Sie sich die hier aufgeführten Techniken ansehen.
Modellauswahl
Nachdem Sie bestätigt haben, dass der Trainer keine hohe Varianz hat, können Sie so vorgehen:
- bis ca. 10 Korrelationskandidaten-Modelle finden
- Berechnen Sie die vollständigen Trainingspunktzahlen, die als Referenz dienen, wenn Sie die Proxy-Korrelationspunktzahlen für verschiedene Proxy-Aufgabenoptionen später berechnen.
Unser Tool sucht automatisch und effizient diese Korrelationskandidaten und stellt sicher, dass sie eine gute Punktzahlverteilung für Genauigkeit und Latenz haben, sodass die zukünftige Korrelationsberechnung eine gute Basis hat. Dabei geht das Tool so vor:
- Es erfasst zufällige Stichproben von
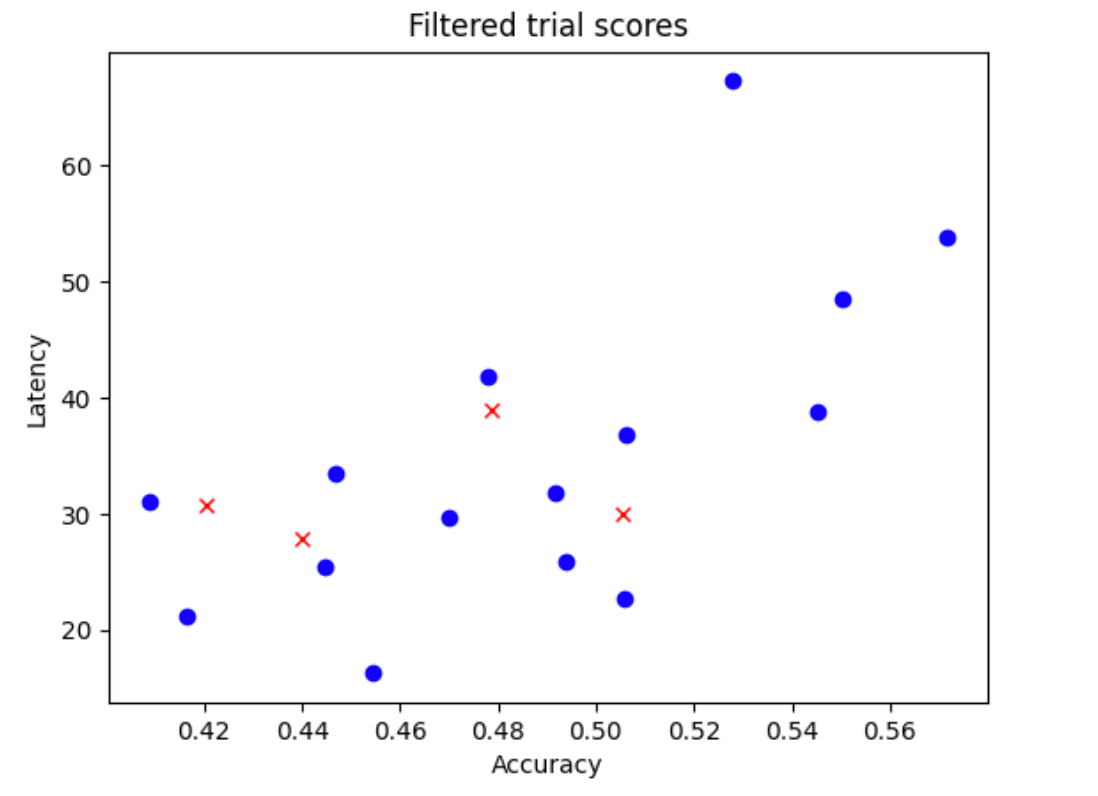
N_begin-Modellen aus Ihrem Suchbereich. Nehmen wir für das BeispielN_begin = 30an. Das Tool trainiert sie für ein 30tel der vollständigen Trainingszeit. - Lehnen Sie fünf von 30 Modellen ab, die nicht zur Verteilung von Genauigkeit und Latenz beitragen. Die folgende Abbildung zeigt dies als Beispiel. Die abgelehnten Modelle werden als rote Punkte angezeigt:
- Trainieren Sie die ausgewählten 25 Modelle für 1/25 der vollständigen Trainingszeit und lehnen Sie dann fünf weitere Modelle anhand der bisher Bewertungen ab. Beachten Sie, dass das Training der 25 Modelle vom vorherigen Prüfpunkt aus fortgesetzt wird.
- Wiederholen Sie diesen Vorgang, bis nur
NModelle mit einer guten Verteilung verbleiben. - Trainieren Sie diese letzten
N-Modelle bis zum Abschluss.
Die Standardeinstellung für N_begin ist 30 und befindet sich in der Datei proxy_task/proxy_task_model_selection_lib_constants.py als START_NUM_MODELS.
Die Standardeinstellung für N ist 10 und befindet sich in der Datei proxy_task/proxy_task_model_selection_lib_constants.py als FINAL_NUM_MODELS.
Die zusätzlichen Kosten für diesen Modellauswahlprozess werden so berechnet:
= (30*1/30 + 25*1/25 + 20*1/20 + 15*1/15 + 10*(remaining-training-time-fraction)) * full-training-time
= (4 + 10*(0.81)) * full-training-time
~= 12 * full-training-time
Die Einstellung sollte jedoch über N=10 liegen. Das Suchtool für Proxy-Aufgaben führt diese N-Modelle parallel aus. Achten Sie daher darauf, dass Ihr GPU-Kontingent ausreicht. Beispiel: Wenn Ihre Proxy-Aufgabe zwei GPUs für ein Modell verwendet, sollten Sie ein Kontingent von mindestens 2*N GPUs haben.
Verwenden Sie für den Modellauswahljob dieselbe Dataset-Partition wie der vollständige Trainingsjob "stage-2" und dieselbe Trainerkonfiguration für das vollständige Basistraining.
Jetzt können Sie den Modellauswahljob mit folgendem Befehl starten (Sie benötigen dazu ein Dienstkonto):
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
latency_calculator_docker_id=${USER}_model_selection_${DATE}
latency_calculator_docker_file=${USER}_latency_${DATE}
region=<your job region such as 'us-central1'>
search_space_module=<path to your search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
# Your latency computation device.
target_device_type="CPU"
####### Proxy task model-selection related parameters ######
proxy_task_model_selection_docker_id=${USER}_model_selection_${DATE}
# Use the service account that you set-up for your project.
service_account=<your service account>
job_name=<your job name>
# The value below depends on your accelerator quota. By default
# the model-selection job runs 30 trials. However, depending on
# your quota, you can choose to only run 10 trials in parallel at a time.
# However, lowering this number can increase the overall runtime for the job.
max_parallel_nas_trial=<num parallel trials>
# The value below is the 'metric-id' corresponding to the accuracy ONLY
# metric reported by your trainer. Note that this metric may
# be different from the 'reward'.
accuracy_metric_id=<set accuracy metric id used by your trainer>
latency_metric_id=<set latency metric id used by your trainer>
############################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_calculator_docker_file=${latency_calculator_docker_file} \
--proxy_task_model_selection_docker_id=${proxy_task_model_selection_docker_id}
# The command below passes 'dummy' arguments for trainer-docker
# and latency-docker. You need to modify them for your own docker.
python3 vertex_nas_cli.py select_proxy_task_models \
--service_account=${service_account} \
--proxy_task_model_selection_docker_id=${proxy_task_model_selection_docker_id} \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--max_parallel_nas_trial=${max_parallel_nas_trial} \
--accuracy_metric_id=${accuracy_metric_id} \
--latency_metric_id=${latency_metric_id} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_docker_flags \
dummy_latency_flag1="dummy_latency_val" \
--target_device_type=${target_device_type} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
Sobald Sie diesen Controller-Job für die Modellauswahl starten, wird ein Joblink empfangen. Der Jobname beginnt mit dem Präfix Model_Selection_. Hier sehen Sie ein Beispiel für eine Job-UI:
model_selection_dir enthält alle Ausgaben. Prüfen Sie die Logs durch Klicken auf View logs.
Dieser Controller-Job für die Modellauswahl verwendet standardmäßig eine CPU in Google Cloud , die im Hintergrund als benutzerdefinierter Job ausgeführt wird, und startet dann untergeordnete NAS-Jobs und verwaltet diese für alle Iterationen der Modellauswahl.
Jeder untergeordnete NAS-Job hat einen Namen wie <your_job_name>_iter_3 (mit Ausnahme der Iteration 0). Es wird jeweils nur eine Iteration ausgeführt. Bei jedem Durchlauf reduziert sich die Anzahl der Modelle (Anzahl der Tests) und die Trainingsdauer erhöht sich. Am Ende jeder Iteration speichert jeder NAS-Job die Datei gs://<job-output-dir>/search/filtered_trial_scores.png, die visuell anzeigt, welche Modelle bei diesem Durchlauf abgelehnt wurden.
Sie können auch folgenden Befehl ausführen:
gcloud storage cat gs://<path to 'model_selection_dir'>/MODEL_SELECTION_STATE.json
zeigt eine Zusammenfassung der Iterationen und des aktuellen Status des Controller-Jobs zur Modellauswahl, des Jobnamens und der Links pro Iteration:
{
"start_num_models": 30,
"final_num_models": 10,
"num_models_to_remove_per_iter": 5,
"accuracy_metric_id": "top_1_accuracy_without_latency",
"latency_metric_id": "latency_milli_seconds",
"iterations": [
{
"num_trials": 30,
"trials_to_retrain": [
"27",
"16",
...,
"14"
],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2111217356469436416",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2111217356469436416/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/6909239809479278592",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/6909239809479278592/cpu?project=my-project",
"desired_training_step_pct": 2.0
},
...,
{
"num_trials": 15,
"trials_to_retrain": [
"14",
...,
"5"
],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/7045544066951413760",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/7045544066951413760/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/2790768318993137664",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2790768318993137664/cpu?project=my-project",
"desired_training_step_pct": 28.57936507936508
},
{
"num_trials": 10,
"trials_to_retrain": [],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2742864796394192896",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2742864796394192896/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/1490864099985195008",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/1490864099985195008/cpu?project=my-project",
"desired_training_step_pct": 101.0
}
]
}
Der letzte Durchlauf enthält die endgültige Anzahl von Referenzmodellen mit einer guten Punktzahlverteilung. Diese Modelle und ihre Punktzahlen werden im nächsten Schritt für die Proxy-Aufgabensuche verwendet. Wenn die endgültige Genauigkeit und der Latenzwertbereich für die Referenzmodelle besser aussehen oder sich Ihrem vorhandenen Basismodell ähneln, ist dies ein guter Hinweis auf Ihren Suchbereich. Wenn der endgültige Genauigkeits- und Latenzwertbereich deutlich schlechter als die Referenzversion ist, prüfen Sie noch einmal Ihren Suchbereich.
Wenn mehr als 20 % der Tests im ersten Durchlauf fehlschlagen, brechen Sie den Modellauswahljob ab und identifizieren Sie die Hauptursache für Fehler. Dies kann ein Problem mit dem Suchbereich oder den Batchgrößen und Einstellungen für die Lernrate sein.
Lokales Latenzgerät für die Modellauswahl verwenden
Wenn Sie ein lokales Latenzgerät für die Modellauswahl verwenden möchten, führen Sie den Befehl select_proxy_task_models ohne den Latenz-Docker und die Latenz-Docker-Flags aus, da Sie den Latenz-Docker nicht auf Google Cloudstarten möchten. Verwenden Sie als Nächstes den in Anleitung 4 beschriebenen run_latency_calculator_local-Befehl, um den lokalen Latenzrechner-Job zu starten. Anstatt das --search_job_id-Flag zu übergeben, übergeben Sie das --controller_job_id-Flag mit der numerischen Job-ID der Modellauswahl, die Sie nach dem Ausführen des Befehls select_proxy_task_models erhalten.
Controller-Job zur Modellauswahl fortsetzen
In folgenden Situationen müssen Sie den Controller-Job zur Modellauswahl fortsetzen:
- Der übergeordnete Controller-Job zur Modellauswahl schlägt fehl (selten).
- Sie brechen den Controller-Job zur Modellauswahl versehentlich ab.
Beenden Sie den untergeordneten NAS-Iterationsjob (NAS-Tab) nicht, wenn er bereits ausgeführt wird. Führen Sie dann den select_proxy_task_models-Befehl wie zuvor aus, um den übergeordneten Controller-Job zur Modellauswahl fortzusetzen. Dieses Mal übergeben Sie jedoch das --previous_model_selection_dir-Flag und legen es auf das Ausgabeverzeichnis für den vorherigen Controller-Job zur Modellauswahl fest. Der wiederaufgenommene Controller-Job zur Modellauswahl lädt seinen vorherigen Status aus dem Verzeichnis und funktioniert wie zuvor.
Proxy-Aufgabensuche
Nachdem Sie die Korrelationskandidaten und ihre vollständigen Trainingsergebnisse ermittelt haben, müssen Sie als Nächstes diese verwenden, um die Korrelationspunktzahlen für verschiedene Auswahlmöglichkeiten für die optimale Proxyaufgabe zu bewerten und auszuwählen. Unser Proxy-Aufgabensuchtool kann automatisch eine Proxyaufgabe finden, die Folgendes bietet:
- Die niedrigsten NAS-Suchkosten
- Erfüllt einen minimalen Schwellenwert für die Korrelation, nachdem ein Proxy-Task-Suchbereich definiert wurde.
Wie bereits erwähnt, gibt es drei gängige Dimensionen, um nach einer optimalen Proxyaufgabe zu suchen:
- Reduzierte Anzahl von Trainingsschritten
- Geringere Menge an Trainingsdaten.
- Reduzierte Modellskalierung.
Sie können einen separaten Proxyaufgaben-Suchbereich erstellen, indem Sie diese Dimensionen wie unten gezeigt abtasten:
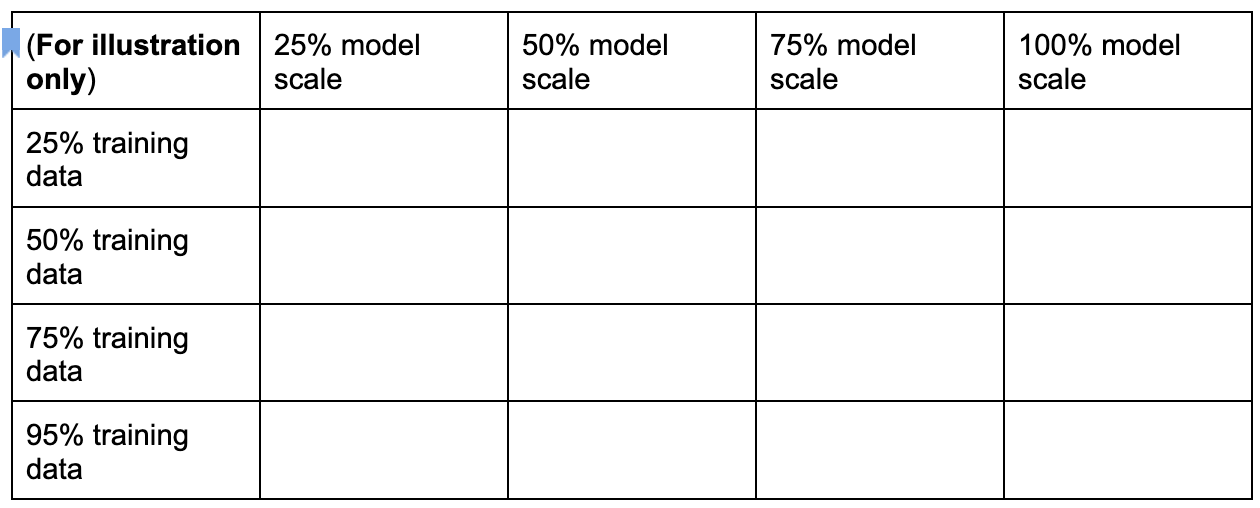
Die Prozentsätze oben wurden nur als ungefähre Vorschläge und Beispiele festgelegt. In der Praxis können Sie jede diskrete Option auswählen.
Beachten Sie, dass die Dimension für Trainingsschritte nicht im obigen Suchbereich enthalten ist. Dies liegt daran, dass das Tool für die Proxy-Aufgabensuche den optimalen Trainingsschritt bei einer Wahl der Proxy-Aufgabe ermittelt.
Betrachten Sie eine Auswahl von Proxyaufgaben von [50% training data, 25% model scale]. Legen Sie die Anzahl der Trainingsschritte auf den gleichen Wert wie für das vollständige Basistraining fest.
Wenn Sie diese Proxyaufgabe bewerten, startet das Tool für die Proxyaufgabe das Training für die Korrelationskandidaten, überwacht ihre aktuellen Genauigkeitspunktzahlen und berechnet kontinuierlich die Rangkorrelationspunktzahl (mithilfe der Vergangenheit vollständige Trainingswerte für die Referenzmodelle):

Das Proxy-Task-Suchtool kann das Training der Proxy-Aufgabe beenden, sobald die gewünschte Korrelation (z. B. 0,65) erreicht wurde, oder es kann vorzeitig beendet werden, wenn das Suchkostenkontingent (z. B. ein Limit von 3 Stunden pro Proxyaufgabe) überschritten ist. Daher müssen Sie in den Trainingsschritten nicht explizit suchen. Das Proxy-Aufgabensuchtool wertet jede Proxyaufgabe aus Ihrem diskreten Suchbereich als Rastersuche aus und bietet Ihnen die beste Option.
Im Folgenden finden Sie ein MnasNet Beispiel für eine Suchdefinition des Proxy-Aufgabenbereichsmnasnet_proxy_task_config_generator , definiert inproxy_task/proxy_task_search_spaces.py der Datei, wie Sie Ihren eigenen Suchbereich definieren können:
# MNasnet training-data size choices.
MNASNET_TRAINING_DATA_PCT_LIST = [25, 50, 75, 95]
# Training data path regex pattern.
_TRAINING_DATA_PATH_REGEX = r"gs://.*/.*"
def update_mnasnet_proxy_training_data(
baseline_docker_args_map: Dict[str, Any],
training_data_pct: int) -> Optional[Dict[str, Any]]:
"""Updates MNasnet baseline docker to use a certain training_data_pct."""
proxy_task_docker_args_map = copy.deepcopy(baseline_docker_args_map)
# Imagenet training data path looks like:
# gs://<path to imagenet data>/train-00[0-7]??-of-01024.
if not re.match(_TRAINING_DATA_PATH_REGEX,
baseline_docker_args_map["training_data_path"]):
raise ValueError(
"Training data path %s does not match the desired pattern." %
baseline_docker_args_map["training_data_path"])
root_path, _ = baseline_docker_args_map["training_data_path"].rsplit("/", 1)
if training_data_% == 25:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-1][0-4]?-of-01024*")
elif training_data_% == 50:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-4]??-of-01024*")
elif training_data_% == 75:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-6][0-4]?-of-01024*")
elif training_data_% == 95:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-8][0-4]?-of-01024*")
else:
logging.warning("Mnasnet training_data_% %d is not supported.",
training_data_pct)
return None
proxy_task_docker_args_map["validation_data_path"] = os.path.join(
root_path, "train-009[0-4]?-of-01024")
return proxy_task_docker_args_map
def mnasnet_proxy_task_config_generator(
baseline_docker_args_map: Dict[str, Any]
) -> List[proxy_task_utils.ProxyTaskConfig]:
"""Returns a list of proxy-task configs to be evaluated for MNasnet.
Args:
baseline_docker_args_map: A set of baseline training-docker arguments in
the form of a dictionary of {'key', val}. The different proxy-task
configs to try can be built by modifying this baseline.
Returns:
A list of proxy-task configs to be evaluated for this
proxy-task search space.
"""
proxy_task_config_list = []
# NOTE: Will not search over model-scale for MNasnet.
for training_data_% in MNASNET_TRAINING_DATA_PCT_LIST:
proxy_task_docker_args_map = update_mnasnet_proxy_training_data(
baseline_docker_args_map=baseline_docker_args_map,
training_data_pct=training_data_pct)
if not proxy_task_docker_args_map:
continue
proxy_task_name = "mnasnet_proxy_training_data_pct_{}".format(
training_data_pct)
proxy_task_config_list.append(
proxy_task_utils.ProxyTaskConfig(
name=proxy_task_name, docker_args_map=proxy_task_docker_args_map))
return proxy_task_config_list
In diesem Beispiel erstellen wir einen einfachen Suchbereich über 25, 50, 75 und 95 für Trainingsdaten. (Beachten Sie, dass 100 % der Trainingsdaten nicht für stage1-search verwendet werden).
Die Funktion mnasnet_proxy_task_config_generator verwendet eine gemeinsame Basisvorlage für Trainings-Docker-Argumente und ändert diese Argumente dann für jede gewünschte Größe der Proxy-Aufgabentrainingsdaten. Anschließend wird eine Liste von proxy-task-config zurückgegeben, die später vom Tool für die Proxy-Aufgabensuche in derselben Reihenfolge verarbeitet wird. Jede Proxy-Aufgabenkonfiguration hat einen name und docker_args_map, d. h. eine Schlüssel/Wert-Zuordnung für die Docker-Argumente der Proxy-Aufgabe.
Sie haben die Möglichkeit, Ihre eigene Suchbereichdefinition gemäß Ihren eigenen Anforderungen zu implementieren und Ihre eigenen Suchbereiche für die Proxyaufgabe zu entwerfen, auch für mehr als die beiden Dimensionen reduzierter Trainingsdaten oder ein reduzierter Modellumfang. Es ist jedoch nicht empfehlenswert, explizit nach Trainingsschritten zu suchen, da dadurch Verschwendung von wiederholten Berechnungen entstehen. Lassen Sie diese Dimension vom Proxytool für die Suche übernehmen.
Bei der ersten Proxy-Aufgabe können Sie versuchen, nur die Trainingsdaten zu reduzieren (wie im Beispiel MnasNet) und die reduzierte Modellskalierung überspringen, da die Modellskalierung mehrere Parameter über image-size, num-filters oder num-blocks beinhalten kann.
In den meisten Fällen sind die reduzierten Trainingsdaten (und die implizite Suche über reduzierte Trainingsschritte) ausreichend, um eine gute Proxy-Aufgabe zu finden.
Legen Sie die Anzahl der Trainingsschritte auf die Anzahl fest, die für das vollständige Basistraining verwendet wird.
Es gibt Unterschiede zwischen vollständigen Trainingsphasen der Phase 2 und der Konfiguration der Phase 1 für Proxyaufgaben. Für die Proxyaufgabe sollten Sie batch-size im Vergleich zur vollständigen Referenzkonfiguration reduzieren, um nur 2 GPUs oder 4 GPUs zu verwenden.
In der Regel verwendet das vollständige Training 4 GPUs, 8 GPUs oder mehr, aber die Proxy-Aufgabe verwendet nur 2 GPUs oder 4 GPUs.
Ein weiterer Unterschied ist die Trainings- und Validierungsaufteilung.
Hier ist ein Beispiel für Änderungen an der MnasNet-Konfiguration, die von vier GPUs für das vollständige Training der Phase 2 zu zwei GPUs und einer anderen Validierungsaufteilung für die Suche nach Proxyaufgaben wechseln:
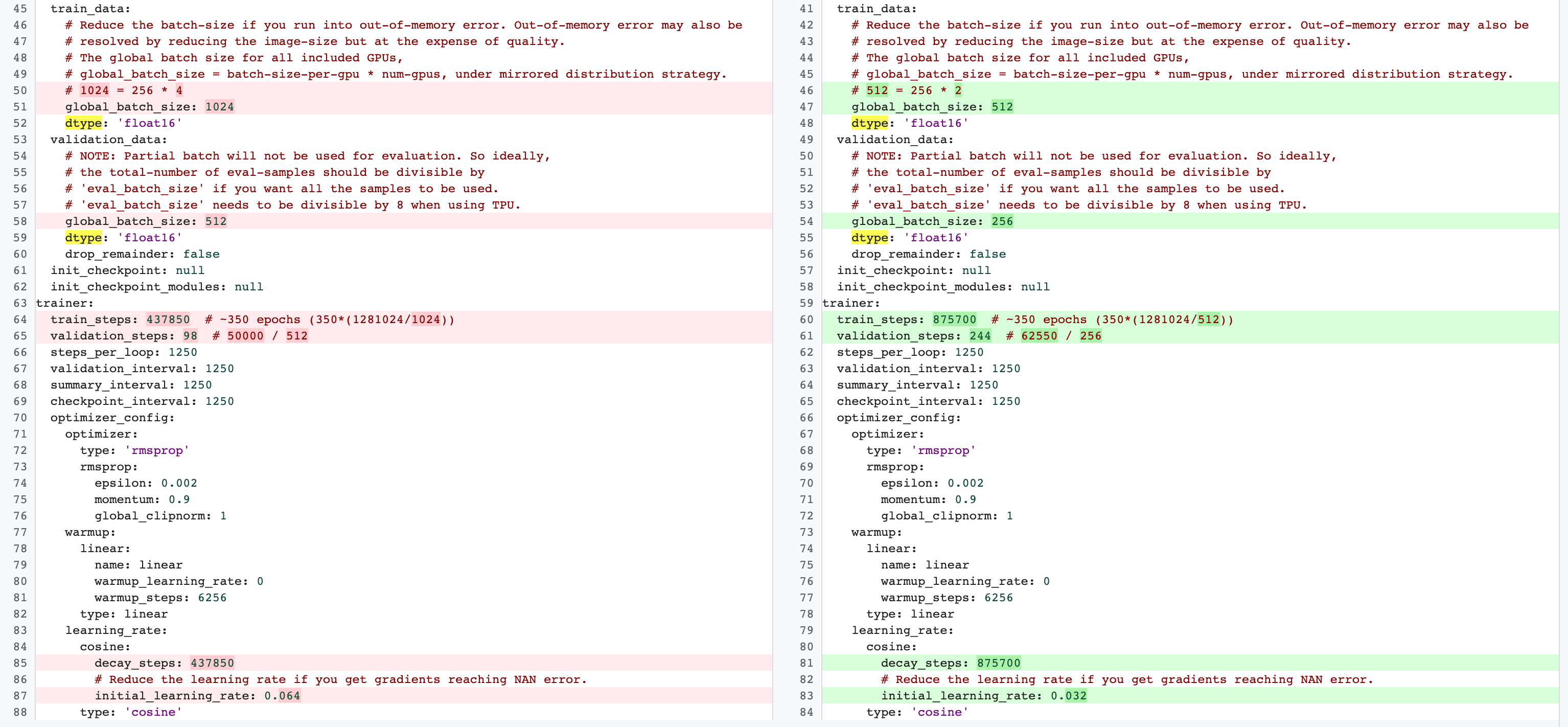
Starten Sie den Job für die Proxy-Aufgabensuche mit folgendem Befehl (Sie benötigen dazu ein Dienstkonto):
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
latency_calculator_docker_id=${USER}_model_selection_${DATE}
latency_calculator_docker_file=${USER}_latency_${DATE}
region=<your job region such as 'us-central1'>
search_space_module=<path to your NAS job search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
# Your latency computation device.
target_device_type="CPU"
####### Proxy task search related parameters ######
proxy_task_search_controller_docker_id=${USER}_proxy_task_search_${DATE}
job_name=<your job name>
# Path to your proxy task search space definition. For ex:
# 'proxy_task.proxy_task_search_spaces.mnasnet_proxy_task_config_generator'
proxy_task_config_generator_module=<path to your proxy task config generator module>
# The previous model-slection job provides the candidate-correlation-models
# and their scores.
proxy_task_model_selection_job_id=<Numeric job id of your previous model-selection>
# During proxy-task search, the proxy-task training is stopped
# when the following correlation score is achieved.
desired_accuracy_correlation=0.65
# During proxy-task search, the proxy-task training is stopped
# if the runtime exceeds this limit: 4 hrs.
training_time_hrs_limit=4
# The proxy-task is marked a good candidate only if the latency
# correlation is also above the required threshold.
# Note: This won't be used if you do not have a latency job.
desired_latency_correlation=0.65
# Early stop a proxy-task evaluation if you already have a better candidate.
# If False, evaluate all proxy-taask candidates.
early_stop_proxy_task_if_not_best=False
# Use the service account that you set-up for your project.
service_account=<your service account>
###################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_calculator_docker_file=${latency_calculator_docker_file} \
--proxy_task_search_controller_docker_id=${proxy_task_search_controller_docker_id}
# The command below passes 'dummy' arguments for trainer-docker
# and latency-docker. You need to modify them for your own docker.
python3 vertex_nas_cli.py search_proxy_task \
--service_account=${service_account} \
--proxy_task_search_controller_docker_id=${proxy_task_search_controller_docker_id} \
--proxy_task_config_generator_module=${proxy_task_config_generator_module} \
--proxy_task_model_selection_job_id=${proxy_task_model_selection_job_id} \
--proxy_task_model_selection_job_region=${region} \
--desired_accuracy_correlation={$desired_accuracy_correlation}\
--training_time_hrs_limit=${training_time_hrs_limit} \
--desired_latency_correlation=${desired_latency_correlation} \
--early_stop_proxy_task_if_not_best=${early_stop_proxy_task_if_not_best} \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_docker_flags \
dummy_latency_flag1="dummy_latency_val" \
--target_device_type=${target_device_type} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
Nachdem Sie diesen -Controller-Job zur Suche einer Proxy-Aufgabe gestartet haben, wird ein Joblink empfangen. Der Jobname beginnt mit dem Präfix Search_controller_. Hier sehen Sie ein Beispiel für eine Job-UI:
search_controller_dir enthält alle Ausgaben und können die Logs durch Klicken auf den Link View logs prüfen.
Dieser Job verwendet standardmäßig eine CPU in der Cloud, um im Hintergrund als benutzerdefinierter Job auszuführen, und startet und verwaltet dann untergeordnete NAS-Jobs für jeden Proxy und Aufgabenbewertung:
Jeder NAS-Job mit einer Proxyaufgabe hat einen Namen wie ProxyTask_<your-job-name>_<proxy-task-name>, wobei <proxy-task-name> das ist, was Ihr Proxy-Aufgabenkonfigurationsmodul für jede Proxy-Aufgabe bereitstellt. Es wird jeweils nur eine Bewertung von Proxyaufgaben ausgeführt.
Sie können auch folgenden Befehl ausführen:
gcloud storage cat gs://<path to 'search_controller_dir'>/SEARCH_CONTROLLER_STATE.json
Dieser Befehl zeigt eine Zusammenfassung aller Proxy-Aufgabenauswertungen und des aktuellen Status des Search-Controller-Jobs, des Jobnamens und der Links für jede Bewertung:
{
"proxy_tasks_map": {
"mnasnet_proxy_training_data_pct_25": {
"proxy_task_stats": {
"training_steps": [
1249,
2499,
...,
18749
],
"accuracy_correlation_over_step": [
-0.06666666666666667,
-0.6,
...,
0.7857142857142856
],
"accuracy_correlation_p_value_over_step": [
0.8618005952380953,
0.016666115520282188,
...,
0.005505952380952381
],
"median_accuracy_over_step": [
0.011478611268103123,
0.04956454783678055,
...,
0.32932570576667786
],
"median_training_time_hrs_over_step": [
0.11611097933475001,
0.22913257125276987,
...,
1.6682701704073444
],
"latency_correlation": 0.9555555555555554,
"latency_correlation_p_value": 5.5114638447971785e-06,
"stopping_state": "Met desired correlation",
"posted_stop_trials_message": true,
"final_training_time_in_hours": 1.6675102778428197,
"final_training_steps": 18512
},
"proxy_task_name": "mnasnet_proxy_training_data_pct_25",
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/4173661476642357248",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/4173661476642357248/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/8785347495069745152",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/8785347495069745152/cpu?project=my-project"
},
...,
"mnasnet_proxy_training_data_pct_95": {
"proxy_task_stats": {
"training_steps": [
1249,
...,
18749
],
"accuracy_correlation_over_step": [
-0.3333333333333333,
...,
0.7857142857142856,
-5.0
],
"accuracy_correlation_p_value_over_step": [
0.21637345679012346,
...,
0.005505952380952381,
-5.0
],
"median_accuracy_over_step": [
0.01120645459741354,
...,
0.38238024711608887,
-1.0
],
"median_training_time_hrs_over_step": [
0.11385884770307843,
...,
1.5466042930547819,
-1.0
],
"latency_correlation": 0.9555555555555554,
"latency_correlation_p_value": 5.5114638447971785e-06,
"stopping_state": "Met desired correlation",
"posted_stop_trials_message": true,
"final_training_time_in_hours": 1.533235285929564,
"final_training_steps": 17108
},
"proxy_task_name": "mnasnet_proxy_training_data_pct_95",
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2341822328209408000",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2341822328209408000/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/7575005095213924352",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/7575005095213924352/cpu?project=my-project"
}
},
"best_proxy_task_name": "mnasnet_proxy_training_data_pct_75"
}
proxy_tasks_map speichert die Ausgabe für jede Bewertung der Proxyaufgabe und best_proxy_task_name zeichnet die beste Proxyaufgabe für die Suche auf. Jeder Proxy-Aufgabeneintrag enthält zusätzliche Daten wie proxy_task_stats, die den Fortschritt der Genauigkeitskorrelation, seine p-Werte, die mittlere Genauigkeit und die mittlere Trainingszeit über Trainingsschritte aufzeichnen. Außerdem wird die latenzbezogene Korrelation aufgezeichnet, falls zutreffend, und der Grund für das Beenden dieses Jobs (z. B. das Limit für die Trainingszeit) und der Trainingsschritt, bei dem er angehalten wird. Sie können diese Statistiken auch als Diagramme anzeigen. Kopieren Sie dazu den Inhalt von search_controller_dir in den lokalen Ordner, indem Sie den folgenden Befehl ausführen:
gcloud storage cp gs://<path to 'search_controller_dir'>/* /your/local/dir
und prüfen Sie die Diagrammbilder. Das folgende Diagramm zeigt beispielsweise die Genauigkeitskorrelation und die Trainingszeit für die beste Proxyaufgabe:

Ihre Suche ist abgeschlossen und Sie haben die beste Proxy-Aufgabenkonfiguration gefunden. Gehen Sie dazu so vor:
- Legen Sie die Anzahl der Trainingsschritte auf den
final_training_stepsder Gewinner-Proxy-Aufgabe fest. - Legen Sie die Schritte für den Kosinus-Abkling-Vorgang wie
final_training_stepsfest, sodass die Lernrate bis zum Ende fast null wird. - [Optional] Führen Sie die Bewertung am Ende des Trainings durch, um mehrere Bewertungskosten zu sparen.
Lokales Latenzgerät für die Proxy-Aufgabensuche verwenden
Wenn Sie ein lokales Latenzgerät für die Suche nach einer Proxy-Aufgabe verwenden möchten, führen Sie den search_proxy_task-Befehl ohne den Latenz-Docker und die Latenz-Docker-Flags aus, da Sie den Latenz-Docker nicht auf Google Cloudstarten möchten. Verwenden Sie als Nächstes den in Anleitung 4 beschriebenen run_latency_calculator_local-Befehl, um den lokalen Latenzrechner-Job zu starten. Anstatt das --search_job_id-Flag zu übergeben, übergeben Sie das --controller_job_id-Flag mit der numerischen Job-ID der Suche nach der Proxy-Aufgabe, die Sie nach dem Ausführen des Befehls search_proxy_task erhalten.
Controller-Job für Suche der Proxy-Aufgabe fortsetzen
In folgenden Situationen müssen Sie den Controller-Job zur Suche einer Proxy-Aufgabe fortsetzen:
- Der übergeordnete Controller-Job zur Suche einer Proxy-Aufgabe schlägt fehl (selten).
- Sie brechen den Controller-Job zur Suche einer Proxy-Aufgabe versehentlich ab.
- Sie möchten den Suchbereich der Proxy-Aufgabe später erweitern (auch nach vielen Tagen).
Beenden Sie den untergeordneten NAS-Iterationsjob (NAS-Tab) nicht, wenn er bereits ausgeführt wird. Führen Sie dann den search_proxy_task-Befehl wie zuvor aus, um den übergeordneten Controller-Job zur Suche einer Proxy-Aufgabe fortzusetzen. Dieses Mal übergeben Sie jedoch das --previous_proxy_task_search_dir-Flag und setzen es auf das Ausgabeverzeichnis für den vorherigen Controller-Job zur Suche einer Proxy-Aufgabe. Der wiederaufgenommene Controller-Job zur Suche einer Proxy-Aufgabe lädt seinen vorherigen Status aus dem Verzeichnis und funktioniert wie zuvor.
Letzte Überprüfung
Zwei abschließende Prüfungen für Ihre Proxy-Aufgabe umfassen den Einsatzbereich und das Speichern von Daten für die Analyse nach der Suche.
Prämienbereich
Die an den Controller gemeldeten Prämien sollte im Bereich [1e-3, 10] liegen. Wenn dies nicht der Fall ist, können Sie die Prämien künstlich skalieren, um dieses Ziel zu erreichen.
Daten für die Analyse nach der Suche speichern
Ihr Proxy-Aufgabencode sollte zusätzliche Messwerte und Daten am Cloud Storage-Speicherort speichern. Dies kann hilfreich sein, wenn Sie später den Suchbereich analysieren möchten. Unsere Plattform für die neuronale Architektur unterstützt nur bis zu fünf Gleitkomma-other_metrics, die aufgezeichnet werden können.
Alle zusätzlichen Messwerte sollten am Cloud Storage-Speicherort für eine spätere Analyse gespeichert werden.