Prima di eseguire un job di ricerca di architetture neurali per cercare un modello ottimale, definisci l'attività proxy. Stage1-search utilizza una rappresentazione molto più piccola di un'addestramento completo del modello che in genere termina entro due ore. Questa rappresentazione è chiamata attività proxy e riduce notevolmente il costo della ricerca. Ogni prova durante la ricerca addestra un modello utilizzando le impostazioni della task proxy.
Le sezioni seguenti descrivono cosa comporta l'applicazione del design delle attività proxy:
- Approcci per la creazione di un'attività proxy.
- Requisiti di un'attività proxy efficace.
- Come utilizzare i tre strumenti di progettazione delle attività proxy per trovare l'attività proxy ottimale, che riduce il costo della ricerca e mantiene la qualità della ricerca.
Approcci per la creazione di un'attività proxy
Esistono tre approcci comuni per creare un'attività proxy, tra cui:
- Utilizza meno passaggi di addestramento.
- Utilizza un set di dati di addestramento sottocampionato.
- Utilizza un modello ridotto.
Utilizza meno passaggi di addestramento
Il modo più semplice per creare un'attività proxy è ridurre il numero di passaggi di addestramento per l'addestratore e segnalare un punteggio al controllore in base a questo addestramento parziale.
Utilizzare un set di dati di addestramento sottocampionato
Questa sezione descrive l'utilizzo di un set di dati di addestramento sottocampionato sia per la ricerca di un'architettura sia per la ricerca di un criterio di aumento.
Ricerca dell'architettura
È possibile creare un'attività proxy utilizzando un set di dati di addestramento sottoposto a sottocampionamento durante la ricerca dell'architettura. Tuttavia, quando esegui il sottocampionamento, segui queste linee guida:
- Mescola i dati in modo casuale tra i vari shard.
- Se i dati di addestramento non sono bilanciati, sottocampionali per bilanciarli.
Ricerca dei criteri di aumento utilizzando l'aumento automatico
Salta questa sezione se non stai eseguendo una ricerca solo per l'aumento e stai eseguendo solo la ricerca dell'architettura standard. Utilizza aumento automatico per cercare le norme relative all'aumento. È preferibile sottocampionare i dati di addestramento ed eseguire un addestramento completo piuttosto che ridurre il numero di passaggi di addestramento. L'esecuzione dell'addestramento completo con un'esagerazione elevata mantiene i punteggi più stabili. Inoltre, utilizza i dati di addestramento ridotti per mantenere basso il costo della ricerca.
Attività proxy basata su modello ridotto
Puoi anche ridurre il modello rispetto al modello di riferimento per creare un'attività proxy. Questo può essere utile anche quando vuoi separare ricerca-design-blocco da ricerca-scalabilità.
Tuttavia, quando riduci il modello e vuoi utilizzare un vincolo di latenza, utilizza un vincolo di latenza più stringente per il modello ridotto. Suggerimento:puoi ridurre il modello di riferimento e misurarne la latenza per impostare questo vincolo di latenza più stringente.
Per il modello ridotto, puoi anche ridurre la quantità di aumento e regolarizzazione rispetto al modello di riferimento originale.
Esempi di un modello ridotto
Per le attività di visione artificiale in cui l'addestramento avviene su immagini, esistono tre modi comuni per ridurre le dimensioni di un modello:
- Riduzione della larghezza del modello: un numero di canali.
- Riduzione della profondità del modello: un numero di ripetizioni di livelli e blocchi.
- Riduci leggermente le dimensioni delle immagini di addestramento (in modo da non eliminare le funzionalità) o ritaglia le immagini di addestramento, se consentito dall'attività.
Lettura consigliata: il documento EfficientNet fornisce ottime informazioni sul ridimensionamento dei modelli per le attività di visione artificiale. Inoltre, spiega in che modo tutti e tre i metodi di scalabilità sono correlati tra loro.
La ricerca di Spinenet è un altro esempio di scalabilità del modello utilizzata con Neural Architecture Search. Per la ricerca di primo livello, riduce il numero di canali e le dimensioni delle immagini.
Attività proxy basata su una combinazione
Gli approcci funzionano in modo indipendente e possono essere combinati in gradi diversi per creare un'attività proxy.
Requisiti di un'attività proxy efficace
Un'attività proxy deve soddisfare determinati requisiti prima di poter fornire un premio stabile al controller e mantenere la qualità della ricerca.
Correlazione del ranking tra la ricerca di fase 1 e l'addestramento completo di fase 2
Quando utilizzi un'attività proxy per la ricerca di architetture neurali, un'ipotesi chiave per una ricerca efficace è che se il modello A ha un rendimento migliore del modello B durante l'addestramento dell'attività proxy di primo livello, il modello A avrà un rendimento migliore del modello B per l'addestramento completo di secondo livello. Per convalidare questa ipotesi, devi valutare la correlazione del ranking tra la ricerca di fase 1 e i premi dell'addestramento completo di fase 2 su circa 10-20 modelli nel tuo spazio di ricerca. Questi modelli sono chiamati correlation-candidate-models.
La figura seguente mostra un esempio di correlazione scarsa (correlation-score = -0.03), che rende questa tarefa proxy un cattivo candidato per una ricerca:
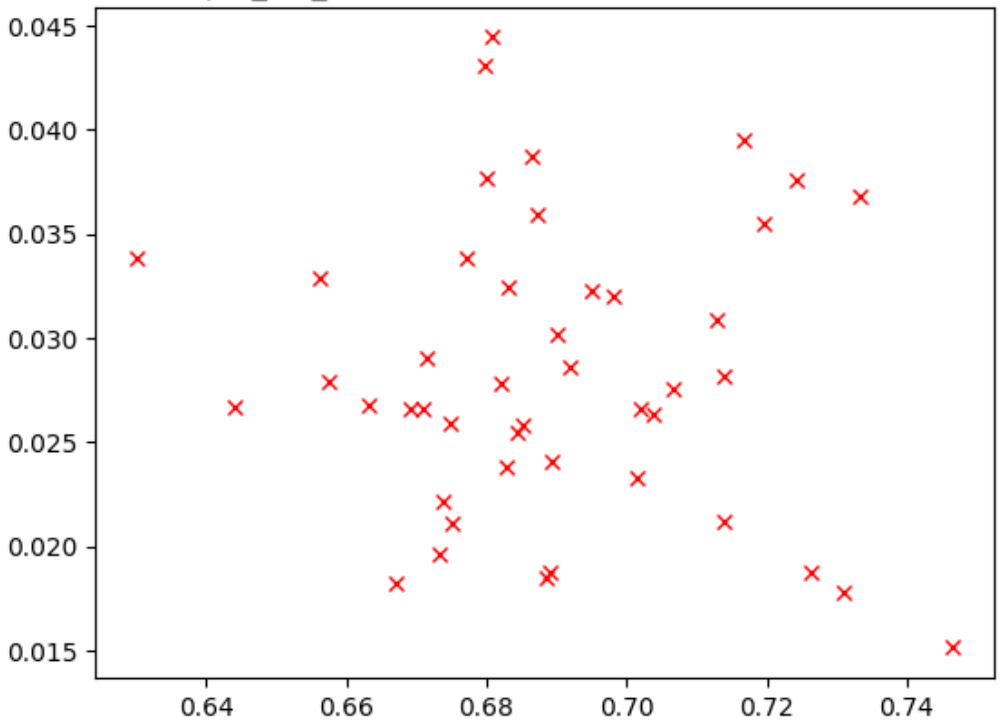
Ogni punto nel grafico rappresenta un modello candidato per la correlazione.
L'asse x rappresenta i punteggi dell'addestramento completo della fase 2 per i modelli, mentre l'asse y rappresenta i punteggi delle attività proxy della fase 1 per gli stessi modelli.
Osserva il punto più alto. Questo modello ha fornito il punteggio più alto per le attività proxy (asse y), ma ha un rendimento scadente durante l'addestramento completo della fase 2 (asse x) rispetto ad altri modelli. Al contrario,
la figura seguente mostra un esempio di una buona correlazione
(punteggio-correlazione = 0,67) che rende questa
attività proxy una buona candidata per una ricerca:

Se la ricerca prevede un vincolo di latenza, verifica anche una buona correlazione per i valori di latenza.
Tieni presente che i premi dei modelli di candidati con correlazione hanno un buon intervallo e un campionamento decente dell'intervallo dei premi. In caso contrario, non puoi valutare la correlazione del ranking. Ad esempio, se tutti i premi della fase 1 dei modelli candidati per la correlazione sono incentrati su soli due valori: 0,9 e 0,1, la variazione del campionamento non è sufficiente.
Controllo della varianza
Un altro requisito di un'attività proxy è che non deve avere una grande variazione di accuratezza o del punteggio di latenza se ripetuta più volte per lo stesso modello senza modifiche. In questo caso, restituisce un segnale rumoroso al controller. È fornito uno strumento per misurare questa varianza.
Gli esempi vengono forniti per ridurre la varianza elevata
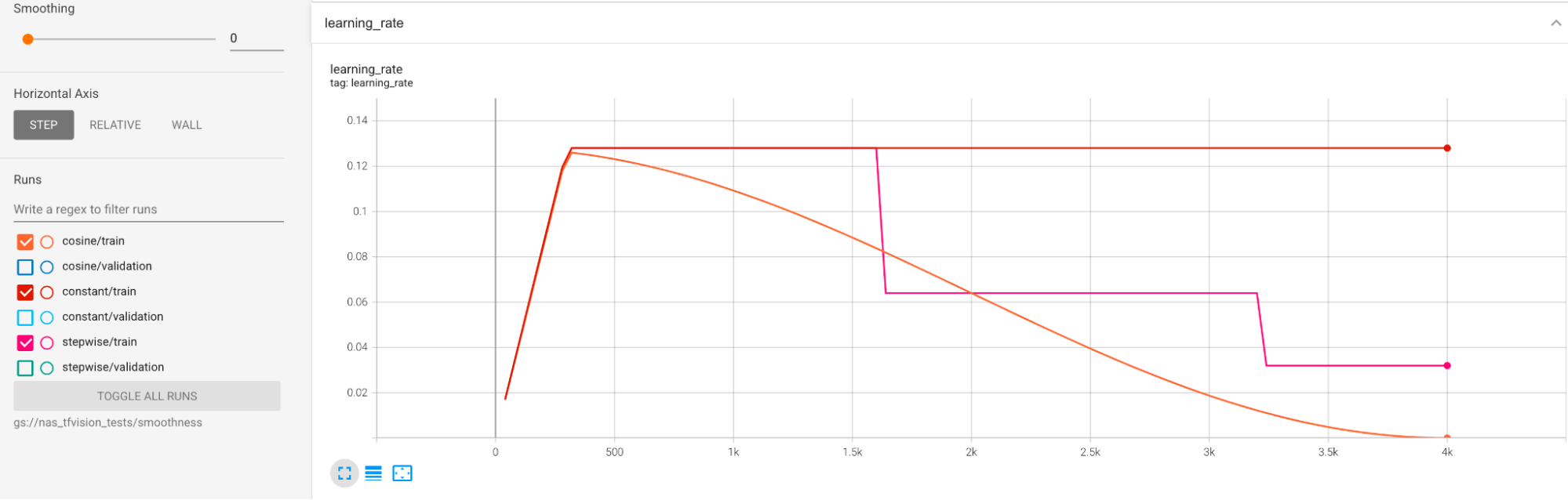
durante l'addestramento. Un modo è utilizzare cosine decay come programma per la frequenza di apprendimento. Il seguente grafico mette a confronto tre strategie di frequenza di apprendimento:

Il grafico più basso corrisponde a un tasso di apprendimento costante. Quando il punteggio oscilla alla fine dell'addestramento, una piccola modifica nella scelta del numero ridotto di passaggi di addestramento può causare un grande cambiamento nel premio finale della task proxy. Per rendere più stabile il premio della task proxy, è meglio utilizzare un decadimento del tasso di apprendimento in funzione della cotangente, come mostrato dai punteggi di convalida corrispondenti nel grafico più alto. Nota come il grafico più alto diventa più uniforme verso la fine dell'addestramento. Il grafico al centro mostra il punteggio corrispondente al decadimento graduale della frequenza di apprendimento. È migliore della frequenza costante, ma non è ancora così fluida come il decadimento sinusoidale e richiede anche la regolazione manuale.
Le pianificazioni del tasso di apprendimento sono riportate di seguito:
Ulteriore levigatura
Se utilizzi un'aumento elevato, la curva di convalida potrebbe non essere sufficientemente uniforme con il decadimento della funzione coseno. L'uso di un'esagerata applicazione di tecniche di aumento indica la mancanza di dati di addestramento. In questo caso, non è consigliato l'utilizzo di Neural Architecture Search e suggeriamo di utilizzare augmentation-search.
Se l'aumento eccessivo non è la causa e hai già provato la media mobile esponenziale, ma vuoi comunque ottenere una maggiore uniformità, utilizza la media mobile esponenziale per TensorFlow-2 o la media ponderata stocastica per PyTorch. Consulta questo puntatore di codice per un esempio che utilizza l'ottimizzatore della media mobile esponenziale con TensorFlow 2 e questo esempio di media ponderata stocastica per PyTorch.
Se i grafici di precisione/epoca per i trial hanno il seguente aspetto:
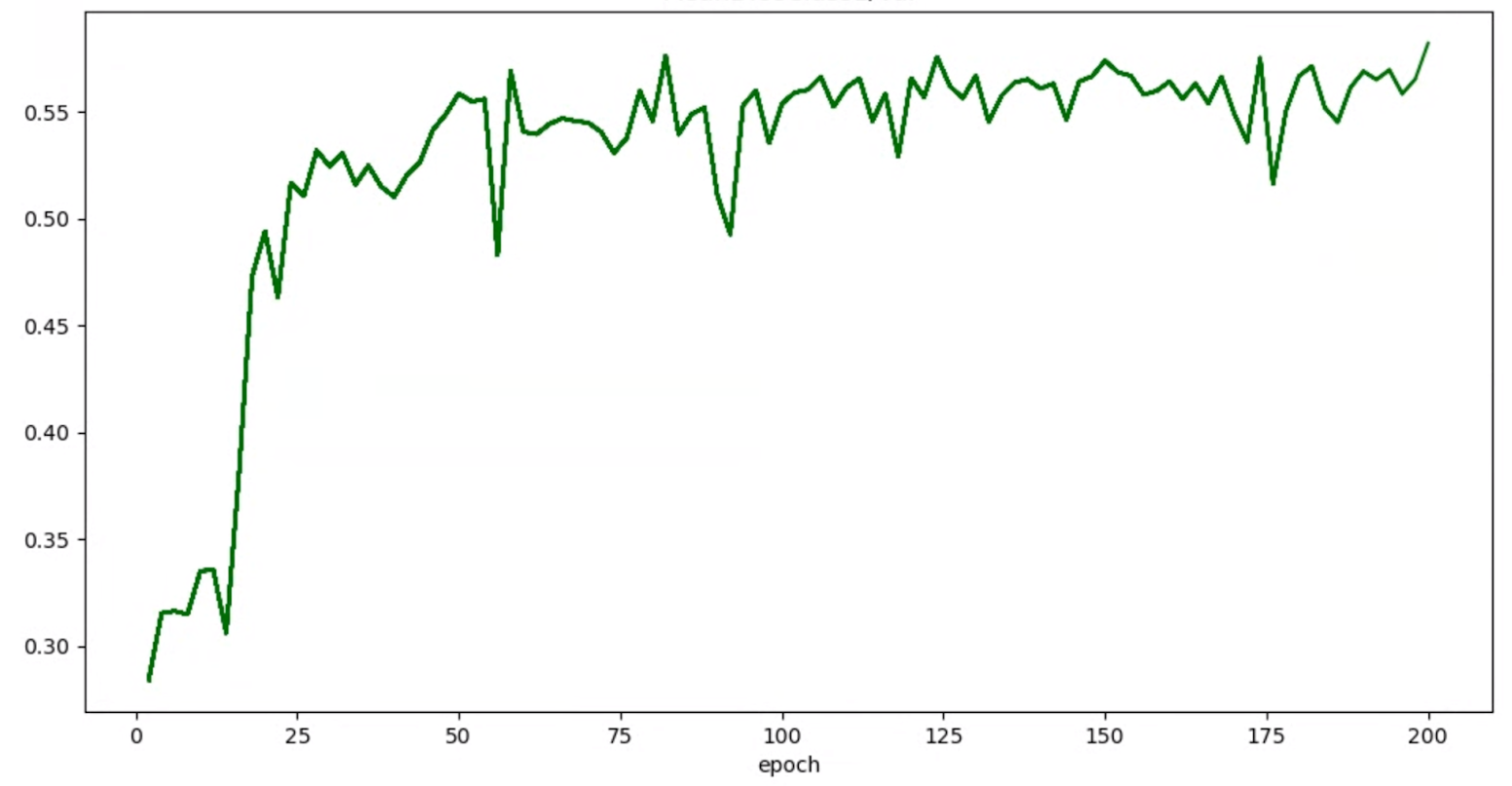
puoi applicare le tecniche di spianamento sopra indicate (ad esempio la media ponderata stocastica o l'utilizzo della media mobile esponenziale) per ottenere un grafico più coerente come:
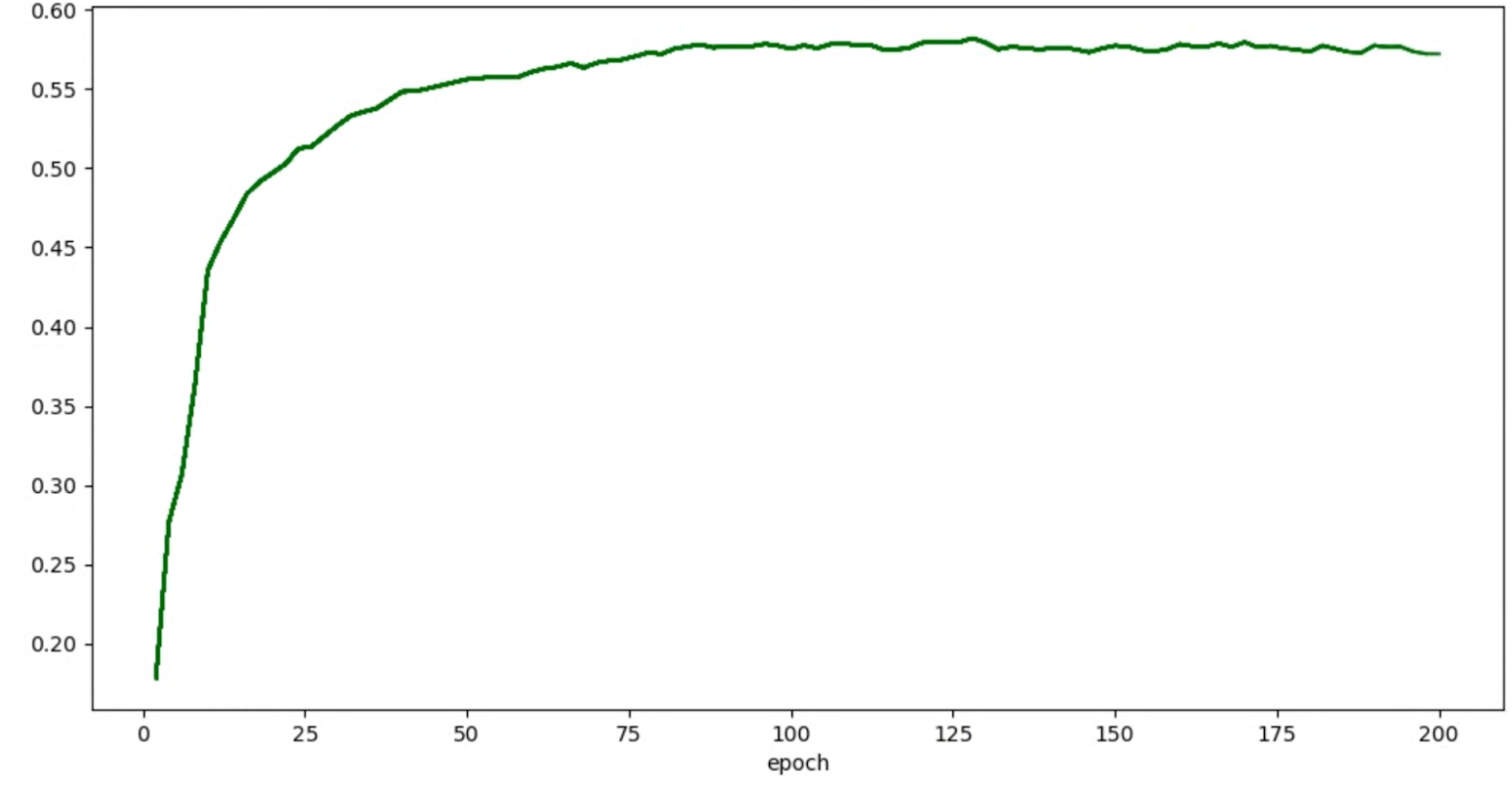
Errori relativi a esaurimento della memoria (OOM) e tasso di apprendimento
Lo spazio di ricerca dell'architettura può generare modelli molto più grandi del tuo valore di riferimento. Potresti aver ottimizzato la dimensione del batch per il tuo modello di riferimento, ma questa impostazione potrebbe non riuscire quando i modelli più grandi vengono campionati durante la ricerca, causando errori di OOM. In questo caso, devi ridurre la dimensione del batch.
L'altro tipo di errore che viene visualizzato è un errore NaN (not-a-number). Dovresti ridurre il tasso di apprendimento iniziale o aggiungere il taglio del gradiente.
Come indicato nel tutorial-2, se più del 20% dei modelli dello spazio di ricerca restituisce punteggi non validi, non esegui la ricerca completa. I nostri strumenti di progettazione delle attività proxy offrono un modo per valutare il tasso di errore.
Strumenti di progettazione delle attività proxy
Le sezioni precedenti parlano dei principi di progettazione delle attività proxy. Questa sezione fornisce tre strumenti di progettazione delle attività proxy per trovare automaticamente l'attività proxy ottimale in base ai diversi approcci di progettazione e che soddisfa tutti i requisiti.
Modifiche al codice richieste
Devi prima modificare leggermente il codice dell'addestratore in modo che possa interagire con gli strumenti di progettazione delle attività proxy durante un processo iterativo.
tf_vision/train_lib.py
mostra un esempio. Devi prima
importare la nostra libreria:
from google.cloud.visionsolutions.nas.proxy_task import proxy_task_utils
Prima dell'inizio di un ciclo di addestramento nel tuo loop di addestramento, controlla se devi interrompere l'addestramento in anticipo, perché lo strumento di progettazione delle attività proxy pretende che tu utilizzi la nostra libreria:
if proxy_task_utils.get_stop_training(
model_dir,
end_training_cycle_step=<last-training-step-idx done so far>,
total_training_steps=<total-training-steps>):
break
Al termine di ogni ciclo di addestramento nel ciclo di addestramento, aggiorna il nuovo punteggio di accuratezza, il passaggio iniziale e finale del ciclo di addestramento, il tempo del ciclo di addestramento in secondi e i passaggi di addestramento totali.
proxy_task_utils.update_trial_training_accuracy_metric(
model_dir=model_dir,
accuracy=<latest accuracy value>,
begin_training_cycle_step=<beginning training step for this cycle>,
end_training_cycle_step=<end training step for this cycle>,
training_cycle_time_in_secs=<training cycle time (excluding validation)>,
total_training_steps=<total-training-steps>)
Tieni presente che il tempo del ciclo di addestramento non deve includere il tempo per la valutazione del voto di convalida. Assicurati che l'addestratore calcoli i punteggi di convalida frequentemente (evaluation-frequency) in modo da avere un campionamento sufficiente della curva di convalida. Se utilizzi il vincolo di latenza, aggiorna la metrica della latenza dopo aver calcolato la latenza:
proxy_task_utils.update_trial_training_latency_metric(
model_dir=model_dir,
latency=<measured_latency>)
Lo strumento di selezione del modello richiede il caricamento del checkpoint precedente per l'iterazione successiva.
Per abilitare il riutilizzo di un checkpoint precedente, aggiungi un flag al tuo trainer come mostrato in tf_vision/cloud_search_main.py:
parser.add_argument(
"--retrain_use_search_job_checkpoint",
type=cloud_nas_utils.str_2_bool,
default=False,
help="True to use previous NAS search job checkpoint."
)
Carica questo checkpoint prima di addestrare il modello:
if FLAGS.retrain_use_search_job_checkpoint:
prev_checkpoint_dir = cloud_nas_utils.get_retrain_search_job_model_dir(
retrain_search_job_trials=FLAGS.retrain_search_job_trials,
retrain_search_job_dir=FLAGS.retrain_search_job_dir)
logging.info("Setting checkpoint to %s.", prev_checkpoint_dir)
# Now set your checkpoint using 'prev_checkpoint_dir'.
Inoltre, devi disporre del valore metric-id corrispondente ai valori di accuratezza e latenza riportati dall'addestratore. Se il premio del tuo trainer
(a volte una combinazione di accuratezza e latenza) è diverso
dall'accuratezza, assicurati di generare anche
la metrica solo sull'accuratezza utilizzando other_metrics dal tuo trainer.
Ad esempio, l'esempio seguente mostra le metriche di accuratezza e latenza riportate dal nostro trainer predefinito:
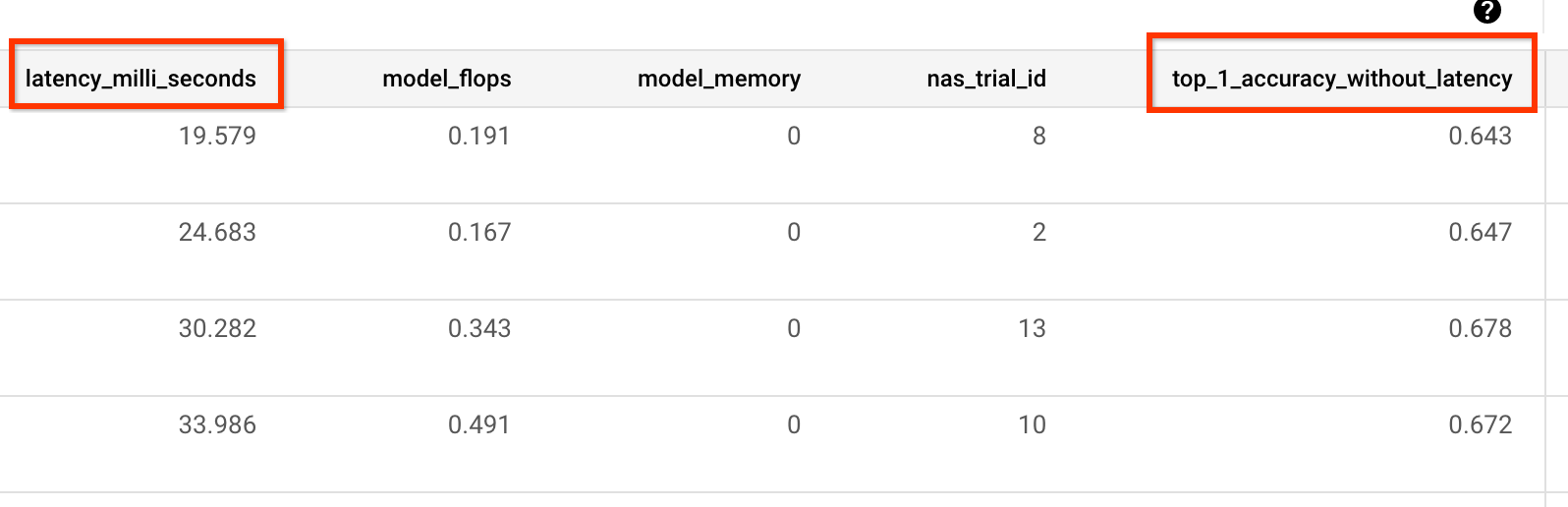
Misurazione della varianza
Dopo aver modificato il codice dell'allenatore, il primo passaggio consiste nel misurare la varianza per l'allenatore. Per la misurazione della varianza, modifica la configurazione dell'addestramento della base di riferimento per quanto segue:
- ridurre i passaggi di addestramento in modo che vengano eseguiti per circa un'ora con una o due GPU. Abbiamo bisogno di un piccolo campione di addestramento completo.
- Utilizza il tasso di apprendimento con decadimento armonico e imposta i relativi passaggi in modo che corrispondano a questi passaggi ridotti, in modo che il tasso di apprendimento diventi quasi nullo verso la fine.
Lo strumento di misurazione della varianza esegue il campionamento di un modello dallo spazio di ricerca, si assicura che questo modello possa iniziare l'addestramento senza generare errori OOM o NAN, esegue cinque copie di questo modello con le tue impostazioni per circa un'ora e poi genera un report sulla varianza e sulla regolarità del punteggio di addestramento. Il costo totale per l'esecuzione di questo strumento è approssimativamente uguale a quello di cinque modelli con le tue impostazioni per circa un'ora.
Avvia il job di misurazione della varianza eseguendo il seguente comando (è necessario un account di servizio):
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
region=<your job region such as 'us-central1'>
search_space_module=<path to your search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
####### Variance measurement related parameters ######
proxy_task_variance_measurement_docker_id=${USER}_variance_measurement_${DATE}
# Use the service account that you set-up for your project.
service_account=<your service account>
job_name=<your job name>
############################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--proxy_task_variance_measurement_docker_id=${proxy_task_variance_measurement_docker_id}
# The command below passes 'dummy' arguments for the training docker.
# You need to modify them for your own docker.
python3 vertex_nas_cli.py measure_proxy_task_variance \
--proxy_task_variance_measurement_docker_id=${proxy_task_variance_measurement_docker_id} \
--project_id=${project_id} \
--service_account=${service_account} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
Una volta lanciato questo job di misurazione della varianza, riceverai un link al job. Il nome job deve iniziare con il prefisso Variance_Measurement. Di seguito è riportata un'UI di job di esempio:
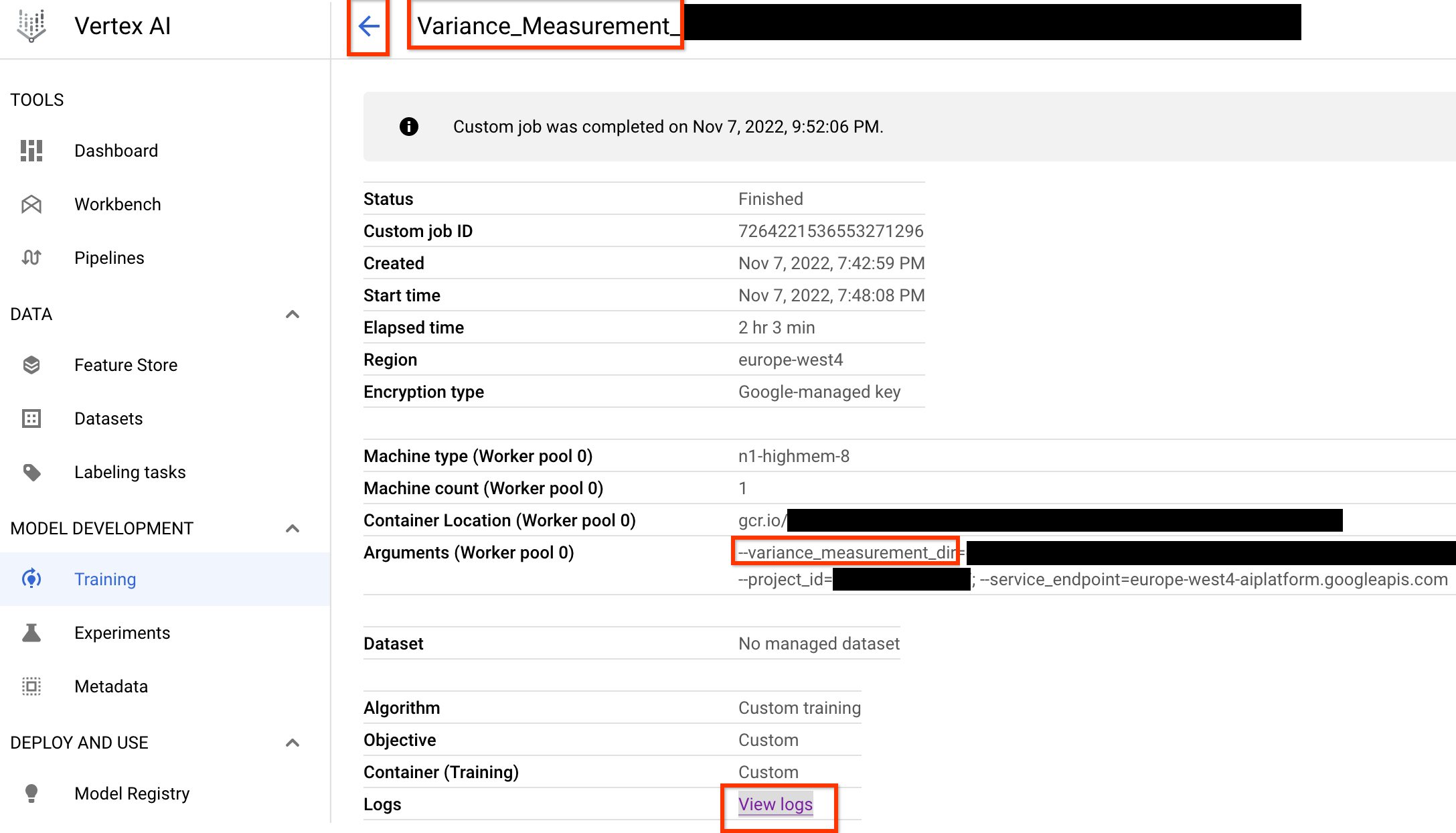
variance_measurement_dir conterrà tutti gli output e potrai controllare i log facendo clic sul link Visualizza log.
Per impostazione predefinita, questo job utilizza una CPU sul cloud per essere eseguito in background come job personalizzato, quindi avvia e gestisce i job NAS secondari.
In Job NAS, vedrai un job denominatoFind_workable_model_<your job name>. Questo job eseguirà il campionamento dello spazio di ricerca per trovare un modello che non genera errori. Una volta trovato un modello di questo tipo, il job di misurazione della varianza avvia un altro job NAS <your job name>, che esegue cinque copie di questo modello per il numero di passaggi di addestramento impostato in precedenza. Al termine dell'addestramento di questi modelli, il job di misurazione della varianza misura la varianza e la fluidità del punteggio e le registra nei log:

Se la varianza è elevata, puoi esplorare le tecniche elencate qui.
Selezione del modello
Dopo aver verificato che il tuo allenatore non ha una varianza elevata, i passaggi successivi sono:
- per trovare circa 10 modelli di correlazione candidati
- calcola i relativi punteggi di addestramento completo, che serviranno da riferimento quando calcolerai in un secondo momento i punteggi di correlazione delle attività proxy per le diverse opzioni di attività proxy.
Il nostro strumento individua in modo automatico ed efficiente questi modelli candidati per la correlazione e garantisce che abbiano una buona distribuzione dei punteggi sia per l'accuratezza che per la latenza, in modo che il calcolo della correlazione futura abbia una buona base. A questo scopo, lo strumento esegue le seguenti operazioni:
- Estrae in modo casuale modelli
N_begindallo spazio di ricerca. Per l'esempio qui, supponiamoN_begin = 30. Lo strumento li addestra per 1/30 del tempo di addestramento completo. - Rifiutare cinque modelli su 30, che non contribuiscono alla distribuzione di accuratezza e latenza. La figura seguente mostra un esempio. I modelli rifiutati vengono visualizzati come punti rossi:
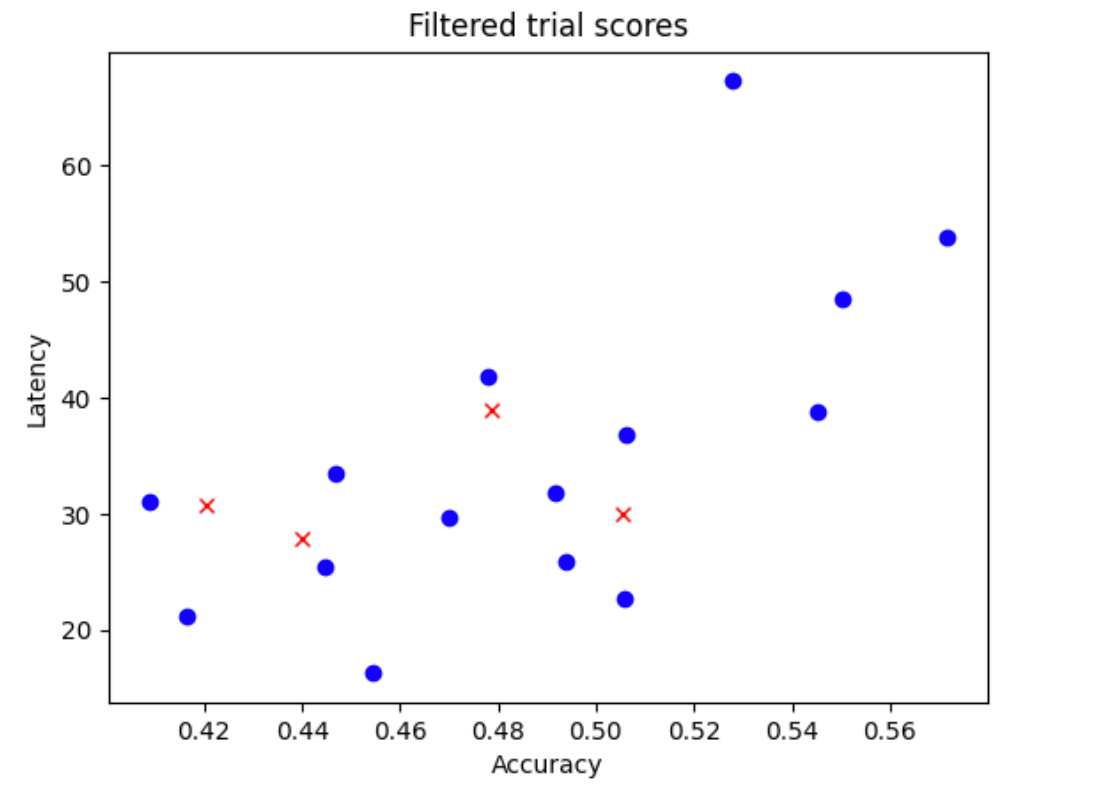
- Addestra i 25 modelli selezionati per 1/25 del tempo di addestramento completo e poi rifiuta altri cinque modelli in base ai punteggi ottenuti fino a quel momento. Tieni presente che l'addestramento dei 25 modelli viene continuato dal checkpoint precedente.
- Ripeti questa procedura finché non rimangono solo
Nmodelli con una buona distribuzione. - Addestra questi ultimi
Nmodelli fino al completamento.
L'impostazione predefinita per N_begin è 30 e puoi trovarla come START_NUM_MODELS
nel file proxy_task/proxy_task_model_selection_lib_constants.py.
L'impostazione predefinita per N è 10 e puoi trovarla come FINAL_NUM_MODELS
nel file proxy_task/proxy_task_model_selection_lib_constants.py.
Il costo aggiuntivo di questa procedura di selezione del modello viene calcolato come segue:
= (30*1/30 + 25*1/25 + 20*1/20 + 15*1/15 + 10*(remaining-training-time-fraction)) * full-training-time
= (4 + 10*(0.81)) * full-training-time
~= 12 * full-training-time
Tuttavia, non superare l'impostazione N=10. Lo strumento di ricerca delle attività proxy successivamente esegue questi modelli N in parallelo. Pertanto, assicurati di disporre di una quota GPU sufficiente. Ad esempio, se la tua attività proxy utilizza due GPU per un modello, devi disporre di una quota di almeno 2*N GPU.
Per il job di selezione del modello, utilizza la stessa partizione del set di dati del job di addestramento completo della fase 2 e la stessa configurazione dell'addestramento completo per il tuo modello di riferimento.
Ora è tutto pronto per lanciare il job di selezione del modello eseguendo il seguente comando (è necessario un account di servizio):
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
latency_calculator_docker_id=${USER}_model_selection_${DATE}
latency_calculator_docker_file=${USER}_latency_${DATE}
region=<your job region such as 'us-central1'>
search_space_module=<path to your search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
# Your latency computation device.
target_device_type="CPU"
####### Proxy task model-selection related parameters ######
proxy_task_model_selection_docker_id=${USER}_model_selection_${DATE}
# Use the service account that you set-up for your project.
service_account=<your service account>
job_name=<your job name>
# The value below depends on your accelerator quota. By default
# the model-selection job runs 30 trials. However, depending on
# your quota, you can choose to only run 10 trials in parallel at a time.
# However, lowering this number can increase the overall runtime for the job.
max_parallel_nas_trial=<num parallel trials>
# The value below is the 'metric-id' corresponding to the accuracy ONLY
# metric reported by your trainer. Note that this metric may
# be different from the 'reward'.
accuracy_metric_id=<set accuracy metric id used by your trainer>
latency_metric_id=<set latency metric id used by your trainer>
############################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_calculator_docker_file=${latency_calculator_docker_file} \
--proxy_task_model_selection_docker_id=${proxy_task_model_selection_docker_id}
# The command below passes 'dummy' arguments for trainer-docker
# and latency-docker. You need to modify them for your own docker.
python3 vertex_nas_cli.py select_proxy_task_models \
--service_account=${service_account} \
--proxy_task_model_selection_docker_id=${proxy_task_model_selection_docker_id} \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--max_parallel_nas_trial=${max_parallel_nas_trial} \
--accuracy_metric_id=${accuracy_metric_id} \
--latency_metric_id=${latency_metric_id} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_docker_flags \
dummy_latency_flag1="dummy_latency_val" \
--target_device_type=${target_device_type} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
Una volta lanciato questo job del controller di selezione del modello, viene ricevuto un link al job. Il nome job inizia con il prefisso Model_Selection_. Di seguito è riportata un'UI di job di esempio:
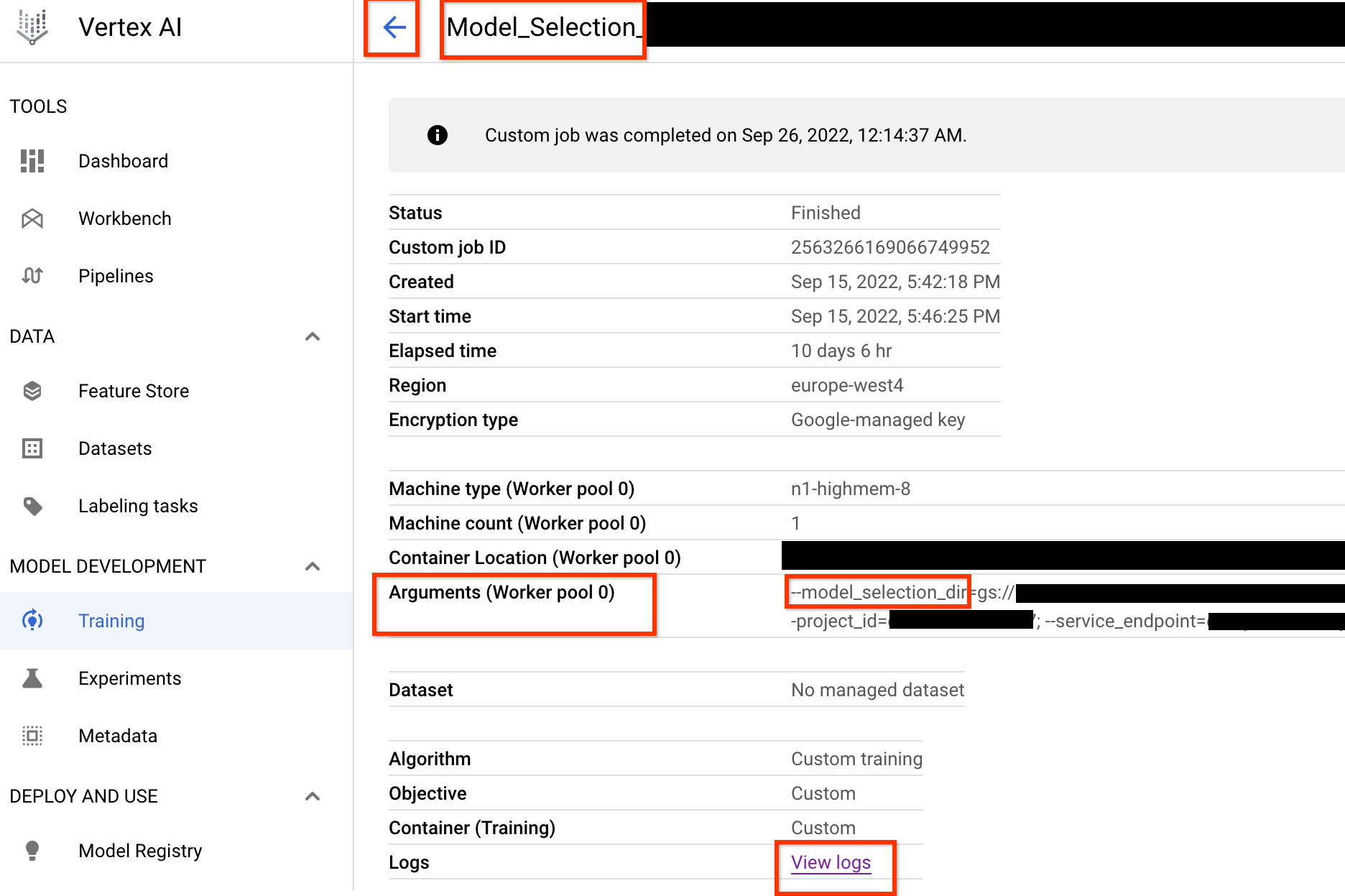
model_selection_dir contiene tutti gli output. Controlla i log facendo clic sul link View logs.
Per impostazione predefinita, questo job di controllo della selezione del modello utilizza una CPU per Google Cloud eseguirsi in background come job personalizzato, quindi avvia e gestisce i job NAS secondari per ogni iterazione della selezione del modello.
Ogni job NAS secondario
ha un nome come <your_job_name>_iter_3 (tranne l'iterazione 0).
Viene eseguita una sola iterazione alla volta. A ogni iterazione, il numero di modelli (numero di prove) diminuisce e la durata dell'addestramento aumenta. Al termine di ogni iterazione, ogni job NAS salva un
gs://<job-output-dir>/search/filtered_trial_scores.png file
che mostra visivamente i modelli rifiutati in questa iterazione.
Puoi anche eseguire il seguente comando:
gcloud storage cat gs://<path to 'model_selection_dir'>/MODEL_SELECTION_STATE.json
che mostra un riepilogo delle iterazioni e dello stato corrente del job del controller di selezione del modello, il nome del job e i link per ogni iterazione:
{
"start_num_models": 30,
"final_num_models": 10,
"num_models_to_remove_per_iter": 5,
"accuracy_metric_id": "top_1_accuracy_without_latency",
"latency_metric_id": "latency_milli_seconds",
"iterations": [
{
"num_trials": 30,
"trials_to_retrain": [
"27",
"16",
...,
"14"
],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2111217356469436416",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2111217356469436416/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/6909239809479278592",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/6909239809479278592/cpu?project=my-project",
"desired_training_step_pct": 2.0
},
...,
{
"num_trials": 15,
"trials_to_retrain": [
"14",
...,
"5"
],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/7045544066951413760",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/7045544066951413760/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/2790768318993137664",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2790768318993137664/cpu?project=my-project",
"desired_training_step_pct": 28.57936507936508
},
{
"num_trials": 10,
"trials_to_retrain": [],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2742864796394192896",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2742864796394192896/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/1490864099985195008",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/1490864099985195008/cpu?project=my-project",
"desired_training_step_pct": 101.0
}
]
}
L'ultima iterazione ha il numero finale di modelli di riferimento con una buona distribuzione dei punteggi. Questi modelli e i relativi punteggi vengono utilizzati per la ricerca di attività proxy nel passaggio successivo. Se l'intervallo di punteggi di accuratezza e latenza finale per i modelli di riferimento è migliore o simile al tuo modello di riferimento esistente, questo fornisce una buona indicazione preliminare sullo spazio di ricerca. Se l'intervallo di punteggi di precisione e latenza finale è notevolmente peggiore rispetto alla baseline, rivedi lo spazio di ricerca.
Tieni presente che se più del 20% dei tentativi nella prima iterazione non va a buon fine, annulla il job di selezione del modello e identifica la causa principale degli errori. Potrebbe trattarsi di un problema con lo spazio di ricerca o con le impostazioni di dimensione del batch e del tasso di apprendimento.
Utilizzo di un dispositivo di latenza on-premise per la selezione del modello
Per utilizzare il dispositivo di latenza on-premise per la selezione del modello, esegui il comandoselect_proxy_task_models senza il flag Docker per la latenza e i flag latency-docker, perché non vuoi avviare Docker per la latenza su Google Cloud. Poi, utilizza il comando run_latency_calculator_local descritto nel
tutorial 4
per avviare il job del calcolatore della latenza on-premise. Anziché passare il flag --search_job_id, passa il flag --controller_job_id con l'ID job numerico di selezione del modello che ottieni dopo aver eseguito il comando select_proxy_task_models.
Riavviare il job del controller di selezione del modello
Le seguenti situazioni richiedono di riprendere il job del controller di selezione del modello:
- Il job del controller di selezione del modello principale non va a buon fine (caso raro).
- Per sbaglio annulli il job del controller di selezione del modello.
Innanzitutto, non annullare il job di iterazione NAS secondario (scheda NAS) se è già in esecuzione. Per riprendere il job del controller di selezione del modello principale, esegui il comando select_proxy_task_models come prima, ma questa volta passa il flag --previous_model_selection_dir e impostalo sulla directory di output del job del controller di selezione del modello precedente. Il job del controller di selezione del modello ripreso carica il suo stato precedente dalla directory e continua a funzionare come prima.
Ricerca di attività proxy
Dopo aver trovato i modelli candidati per la correlazione e i relativi punteggi di addestramento completo, il passaggio successivo consiste nell'utilizzarli per valutare i punteggi di correlazione per diverse scelte di attività proxy e scegliere l'attività proxy ottimale. Il nostro strumento di ricerca delle attività proxy può trovare automaticamente un'attività proxy, che offre quanto segue:
- Il costo di ricerca NAS più basso.
- Soddisfa una soglia minima di requisiti di correlazione dopo aver fornito una definizione di spazio di ricerca delle attività proxy.
Ricorda che esistono tre dimensioni comuni per cercare un'attività proxy ottimale, tra cui:
- Numero ridotto di passaggi di addestramento.
- Quantità ridotta di dati di addestramento.
- Scala del modello ridotta.
Puoi creare uno spazio di ricerca delle attività proxy discreto selezionando come campione queste dimensioni, come mostrato di seguito:

I numeri percentuali riportati sopra sono impostati solo come suggerimento approssimativo
e come esempio. In pratica, puoi scegliere qualsiasi opzione discreta.
Tieni presente che non abbiamo incluso la dimensione Passaggi di addestramento nello spazio di ricerca sopra indicato. Questo perché lo strumento di ricerca delle attività proxy
trovare il passaggio di addestramento ottimale in base a una scelta di attività proxy.
Valuta la possibilità di scegliere un'attività proxy di
[50% training data, 25% model scale]. Imposta il
numero di passaggi di addestramento uguale a quello per l'addestramento completo di riferimento.
Durante la valutazione di questa attività proxy, lo strumento di ricerca delle attività proxy avvia l'addestramento per i modelli candidati alla correlazione, monitora i relativi punteggi di accuratezza correnti e calcola continuamente il punteggio di correlazione del ranking (utilizzando i punteggi dell'addestramento completo precedente per i modelli di riferimento):
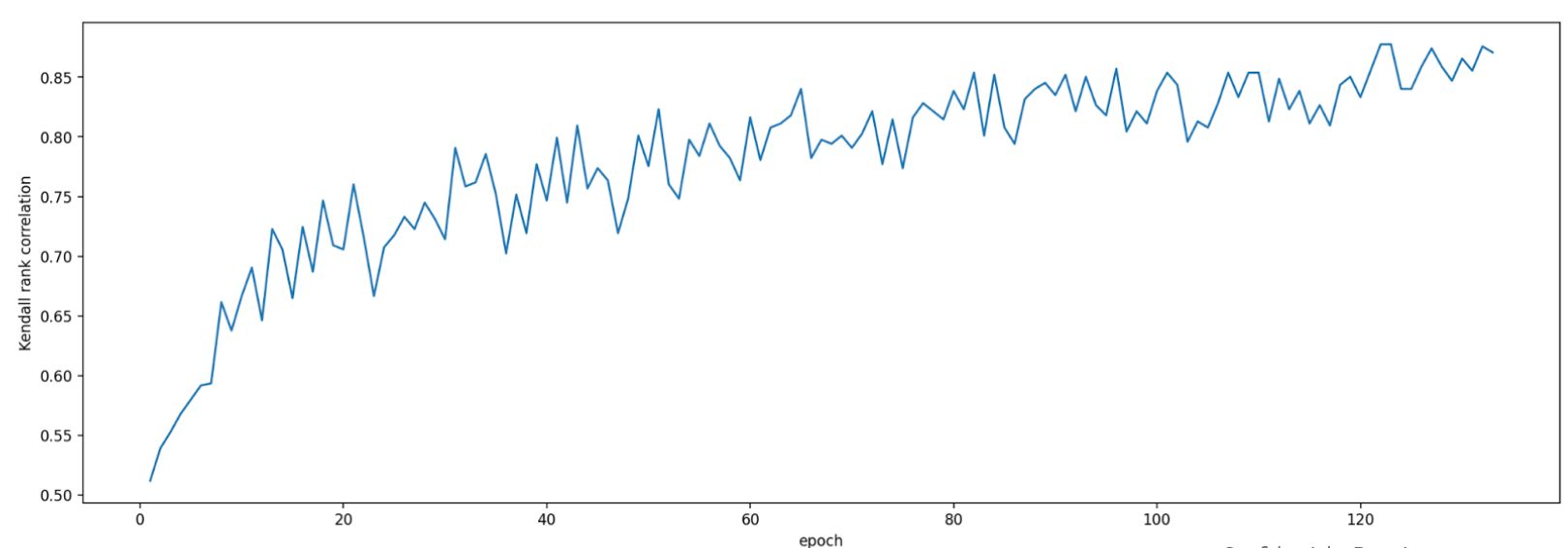
Pertanto, lo strumento di ricerca delle attività proxy può interrompere l'addestramento delle attività proxy quando viene ottenuta la correlazione desiderata (ad es. 0,65) o anche interrompersi in anticipo se viene superata la quota del costo di ricerca (ad es. il limite di 3 ore per attività proxy). Pertanto, non è necessario eseguire una ricerca esplicita nei passaggi di addestramento. Lo strumento di ricerca delle attività proxy valuta ogni attività proxy dello spazio di ricerca discreto come ricerca a griglia e fornisce l'opzione migliore.
Di seguito è riportato un MnasNetesempio di definizione dello spazio di ricerca delle attività proxymnasnet_proxy_task_config_generator, definito nel file proxy_task/proxy_task_search_spaces.py, per dimostrare come puoi definire il tuo spazio di ricerca:
# MNasnet training-data size choices.
MNASNET_TRAINING_DATA_PCT_LIST = [25, 50, 75, 95]
# Training data path regex pattern.
_TRAINING_DATA_PATH_REGEX = r"gs://.*/.*"
def update_mnasnet_proxy_training_data(
baseline_docker_args_map: Dict[str, Any],
training_data_pct: int) -> Optional[Dict[str, Any]]:
"""Updates MNasnet baseline docker to use a certain training_data_pct."""
proxy_task_docker_args_map = copy.deepcopy(baseline_docker_args_map)
# Imagenet training data path looks like:
# gs://<path to imagenet data>/train-00[0-7]??-of-01024.
if not re.match(_TRAINING_DATA_PATH_REGEX,
baseline_docker_args_map["training_data_path"]):
raise ValueError(
"Training data path %s does not match the desired pattern." %
baseline_docker_args_map["training_data_path"])
root_path, _ = baseline_docker_args_map["training_data_path"].rsplit("/", 1)
if training_data_% == 25:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-1][0-4]?-of-01024*")
elif training_data_% == 50:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-4]??-of-01024*")
elif training_data_% == 75:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-6][0-4]?-of-01024*")
elif training_data_% == 95:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-8][0-4]?-of-01024*")
else:
logging.warning("Mnasnet training_data_% %d is not supported.",
training_data_pct)
return None
proxy_task_docker_args_map["validation_data_path"] = os.path.join(
root_path, "train-009[0-4]?-of-01024")
return proxy_task_docker_args_map
def mnasnet_proxy_task_config_generator(
baseline_docker_args_map: Dict[str, Any]
) -> List[proxy_task_utils.ProxyTaskConfig]:
"""Returns a list of proxy-task configs to be evaluated for MNasnet.
Args:
baseline_docker_args_map: A set of baseline training-docker arguments in
the form of a dictionary of {'key', val}. The different proxy-task
configs to try can be built by modifying this baseline.
Returns:
A list of proxy-task configs to be evaluated for this
proxy-task search space.
"""
proxy_task_config_list = []
# NOTE: Will not search over model-scale for MNasnet.
for training_data_% in MNASNET_TRAINING_DATA_PCT_LIST:
proxy_task_docker_args_map = update_mnasnet_proxy_training_data(
baseline_docker_args_map=baseline_docker_args_map,
training_data_pct=training_data_pct)
if not proxy_task_docker_args_map:
continue
proxy_task_name = "mnasnet_proxy_training_data_pct_{}".format(
training_data_pct)
proxy_task_config_list.append(
proxy_task_utils.ProxyTaskConfig(
name=proxy_task_name, docker_args_map=proxy_task_docker_args_map))
return proxy_task_config_list
In questo esempio, creiamo uno spazio di ricerca semplice per percentuale-dati-addestramento
25, 50, 75 e 95 (tieni presente che il 100% dei dati di addestramento non viene
utilizzato per la ricerca di fase 1).
La funzione mnasnet_proxy_task_config_generator utilizza un modello di base comune di argomenti Docker di addestramento e poi modifica questi argomenti per ogni dimensione dei dati di addestramento delle attività proxy desiderata. Restituisce quindi un elenco di proxy-task-config che viene successivamente elaborato dallo strumento di ricerca delle attività proxy una alla volta nello stesso ordine. Ogni configurazione della task proxy ha un name e un docker_args_map, che è una mappa chiave-valore per gli argomenti docker della task proxy.
Sei libero di implementare la tua definizione dello spazio di ricerca in base ai tuoi requisiti e di progettare i tuoi spazi di ricerca delle attività proxy anche per più di due dimensioni di dati di addestramento ridotti o di scala del modello ridotta. Tuttavia, non è consigliabile eseguire una ricerca esplicita tra i passaggi di addestramento perché comporterebbe un calcolo ripetuto e sprecato. Lascia che lo strumento di ricerca delle attività proxy gestisca questa dimensione per te.
Per la prima ricerca di attività proxy, puoi provare a ridurre solo i dati di addestramento (come nell'esempio MnasNet) e saltare la scalatura del modello ridotta perché la scalatura del modello può comportare più parametri rispetto a image-size, num-filters o num-blocks.
Nella maggior parte dei casi, i dati di addestramento ridotti (e la ricerca implicita su
passaggi di addestramento ridotti) sono sufficienti per trovare un'attività proxy valida.
Imposta il numero di passaggi di addestramento
sul numero utilizzato nell'addestramento con base completa.
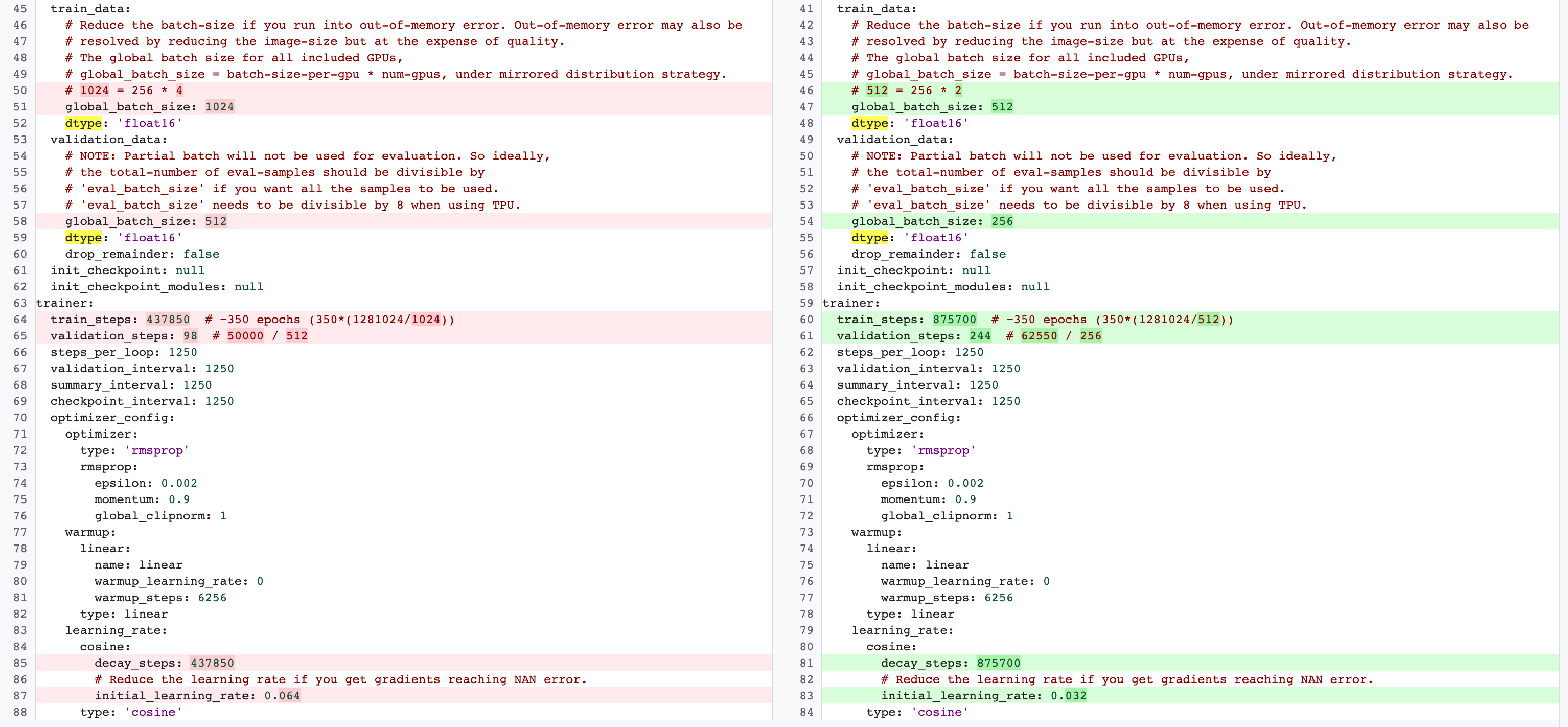
Esistono differenze tra le configurazioni di addestramento completo della fase 2 e quelle di addestramento delle attività proxy della fase 1. Per l'attività proxy,
devi ridurre batch-size rispetto alla configurazione di addestramento con base completa per utilizzare solo 2 o 4 GPU.
In genere, l'addestramento completo utilizza 4, 8 o più GPU, ma l'attività proxy utilizza solo 2 o 4 GPU.
Un'altra differenza è la
suddivisione in addestramento e convalida.
Ecco un esempio di modifiche per la configurazione di MnasNet che passano da 4 GPU per l'addestramento completo della fase 2 a 2 GPU e una suddivisione della convalida diversa per la ricerca di attività proxy:
Avvia il job del controller di ricerca delle attività proxy eseguendo il seguente comando (è necessario un account di servizio):
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
latency_calculator_docker_id=${USER}_model_selection_${DATE}
latency_calculator_docker_file=${USER}_latency_${DATE}
region=<your job region such as 'us-central1'>
search_space_module=<path to your NAS job search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
# Your latency computation device.
target_device_type="CPU"
####### Proxy task search related parameters ######
proxy_task_search_controller_docker_id=${USER}_proxy_task_search_${DATE}
job_name=<your job name>
# Path to your proxy task search space definition. For ex:
# 'proxy_task.proxy_task_search_spaces.mnasnet_proxy_task_config_generator'
proxy_task_config_generator_module=<path to your proxy task config generator module>
# The previous model-slection job provides the candidate-correlation-models
# and their scores.
proxy_task_model_selection_job_id=<Numeric job id of your previous model-selection>
# During proxy-task search, the proxy-task training is stopped
# when the following correlation score is achieved.
desired_accuracy_correlation=0.65
# During proxy-task search, the proxy-task training is stopped
# if the runtime exceeds this limit: 4 hrs.
training_time_hrs_limit=4
# The proxy-task is marked a good candidate only if the latency
# correlation is also above the required threshold.
# Note: This won't be used if you do not have a latency job.
desired_latency_correlation=0.65
# Early stop a proxy-task evaluation if you already have a better candidate.
# If False, evaluate all proxy-taask candidates.
early_stop_proxy_task_if_not_best=False
# Use the service account that you set-up for your project.
service_account=<your service account>
###################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_calculator_docker_file=${latency_calculator_docker_file} \
--proxy_task_search_controller_docker_id=${proxy_task_search_controller_docker_id}
# The command below passes 'dummy' arguments for trainer-docker
# and latency-docker. You need to modify them for your own docker.
python3 vertex_nas_cli.py search_proxy_task \
--service_account=${service_account} \
--proxy_task_search_controller_docker_id=${proxy_task_search_controller_docker_id} \
--proxy_task_config_generator_module=${proxy_task_config_generator_module} \
--proxy_task_model_selection_job_id=${proxy_task_model_selection_job_id} \
--proxy_task_model_selection_job_region=${region} \
--desired_accuracy_correlation={$desired_accuracy_correlation}\
--training_time_hrs_limit=${training_time_hrs_limit} \
--desired_latency_correlation=${desired_latency_correlation} \
--early_stop_proxy_task_if_not_best=${early_stop_proxy_task_if_not_best} \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_docker_flags \
dummy_latency_flag1="dummy_latency_val" \
--target_device_type=${target_device_type} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
Dopo aver avviato questo job del controller di ricerca delle attività proxy, viene ricevuto un link al job. Il nome del job inizia con il prefisso Search_controller_. Di seguito è riportata un'UI di job di esempio:
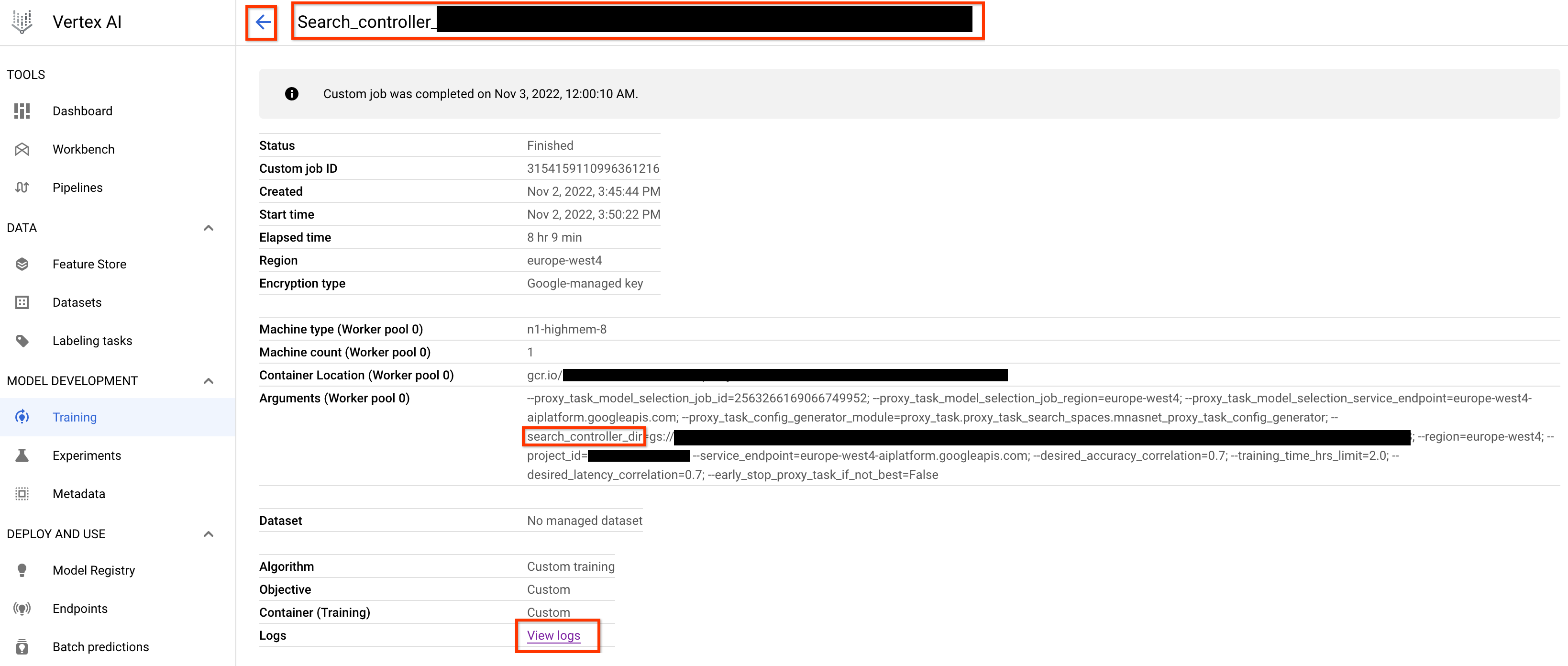
search_controller_dir conterrà tutti gli output e potrai controllare i log facendo clic sul link View logs.
Per impostazione predefinita, questo job utilizza una CPU sul cloud per essere eseguito in background come job personalizzato e poi avvia e gestisce i job NAS secondari per ogni valutazione delle attività proxy.
Ogni job NAS proxy-task ha un nome, ad esempio ProxyTask_<your-job-name>_<proxy-task-name>, dove <proxy-task-name> è il valore fornito dal modulo di generazione della configurazione proxy-task per ogni proxy-task. Viene eseguita solo una valutazione della task proxy alla volta.
Puoi anche eseguire il seguente comando:
gcloud storage cat gs://<path to 'search_controller_dir'>/SEARCH_CONTROLLER_STATE.json
Questo comando mostra un riepilogo di tutte le valutazioni delle attività proxy e lo stato corrente del job del controller di ricerca, il nome del job e i link per ogni valutazione:
{
"proxy_tasks_map": {
"mnasnet_proxy_training_data_pct_25": {
"proxy_task_stats": {
"training_steps": [
1249,
2499,
...,
18749
],
"accuracy_correlation_over_step": [
-0.06666666666666667,
-0.6,
...,
0.7857142857142856
],
"accuracy_correlation_p_value_over_step": [
0.8618005952380953,
0.016666115520282188,
...,
0.005505952380952381
],
"median_accuracy_over_step": [
0.011478611268103123,
0.04956454783678055,
...,
0.32932570576667786
],
"median_training_time_hrs_over_step": [
0.11611097933475001,
0.22913257125276987,
...,
1.6682701704073444
],
"latency_correlation": 0.9555555555555554,
"latency_correlation_p_value": 5.5114638447971785e-06,
"stopping_state": "Met desired correlation",
"posted_stop_trials_message": true,
"final_training_time_in_hours": 1.6675102778428197,
"final_training_steps": 18512
},
"proxy_task_name": "mnasnet_proxy_training_data_pct_25",
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/4173661476642357248",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/4173661476642357248/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/8785347495069745152",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/8785347495069745152/cpu?project=my-project"
},
...,
"mnasnet_proxy_training_data_pct_95": {
"proxy_task_stats": {
"training_steps": [
1249,
...,
18749
],
"accuracy_correlation_over_step": [
-0.3333333333333333,
...,
0.7857142857142856,
-5.0
],
"accuracy_correlation_p_value_over_step": [
0.21637345679012346,
...,
0.005505952380952381,
-5.0
],
"median_accuracy_over_step": [
0.01120645459741354,
...,
0.38238024711608887,
-1.0
],
"median_training_time_hrs_over_step": [
0.11385884770307843,
...,
1.5466042930547819,
-1.0
],
"latency_correlation": 0.9555555555555554,
"latency_correlation_p_value": 5.5114638447971785e-06,
"stopping_state": "Met desired correlation",
"posted_stop_trials_message": true,
"final_training_time_in_hours": 1.533235285929564,
"final_training_steps": 17108
},
"proxy_task_name": "mnasnet_proxy_training_data_pct_95",
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2341822328209408000",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2341822328209408000/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/7575005095213924352",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/7575005095213924352/cpu?project=my-project"
}
},
"best_proxy_task_name": "mnasnet_proxy_training_data_pct_75"
}
proxy_tasks_map memorizza l'output per ogni valutazione della task proxy e best_proxy_task_name registra la task proxy migliore per la ricerca. Ogni voce della task proxy contiene dati aggiuntivi, come proxy_task_stats, che registra l'avanzamento della correlazione dell'accuratezza, i relativi valori p, l'accuratezza mediana e il tempo di addestramento mediano nei vari passaggi di addestramento. Registra inoltre la correlazione correlata alla latenza, se applicabile, e il motivo dell'interruzione del job (ad esempio il superamento del limite di tempo di addestramento) e il passaggio di addestramento in cui si interrompe. Puoi anche visualizzare queste statistiche come grafici copiando i contenuti di search_controller_dir nella tua cartella locale eseguendo il seguente comando:
gcloud storage cp gs://<path to 'search_controller_dir'>/* /your/local/dir
e controlla le immagini del grafico. Ad esempio, il seguente grafico mostra la correlazione tra accuratezza e tempo di addestramento per la task proxy migliore:

La ricerca è completata e hai trovato la configurazione proxy-task migliore. Devi fare quanto segue:
- Imposta il numero di passaggi di addestramento su
final_training_stepsdell'attività proxy vincente. - Imposta i passaggi di decadimento armonico come per
final_training_stepsin modo che il tasso di apprendimento tenda a zero verso la fine. - [Facoltativo] Esegui una valutazione del punteggio di convalida al termine dell'addestramento, in modo da risparmiare sui costi di più valutazioni.
Utilizzo del dispositivo di latenza on-premise per la ricerca di attività proxy
Per utilizzare il dispositivo di latenza on-premise per la ricerca di attività proxy, esegui il comando search_proxy_task senza il docker di latenza e i flag latency-docker, perché non vuoi avviare il docker di latenza su Google Cloud. Poi, utilizza il comando run_latency_calculator_local descritto nel
tutorial 4
per avviare il job del calcolatore della latenza on-premise. Anziché passare il flag --search_job_id, passa il flag --controller_job_id con l'ID job di ricerca di attività proxy numerico che ottieni dopo aver eseguito il comando search_proxy_task.
Ripresa del job del controller di ricerca delle attività proxy
Le seguenti situazioni richiedono di riprendere il job del controller di ricerca delle attività proxy:
- Il job del controller di ricerca delle attività proxy principale non va a buon fine (caso raro).
- Per errore annulli il job del controller di ricerca delle attività proxy.
- Vuoi estendere lo spazio di ricerca delle attività proxy in un secondo momento (anche dopo molti giorni).
Innanzitutto, non annullare il job di iterazione NAS secondario (scheda NAS) se è già in esecuzione. Per riprendere il job del controller di ricerca delle attività proxy principale, esegui il comando search_proxy_task come prima, ma questa volta passa il flag --previous_proxy_task_search_dir e impostalo sulla directory di output del job del controller di ricerca delle attività proxy precedente. Il job del controller di ricerca delle attività proxy ripreso carica il suo stato precedente dalla directory e continua a funzionare come prima.
Controlli finali
Due controlli finali per l'attività proxy includono la fascia di premio e il salvataggio dei dati per l'analisi post-ricerca.
Intervallo di premio
Il premio segnalato al controller deve essere compreso nell'intervallo [1e-3, 10]. In caso contrario, puoi aumentare artificialmente il premio per raggiungere questo obiettivo.
Salvare i dati per l'analisi post-ricerca
Il codice dell'attività proxy dovrebbe salvare eventuali metriche e dati aggiuntivi nella posizione di Cloud Storage, il che potrebbe essere utile per analizzare in un secondo momento lo spazio di ricerca. La nostra piattaforma Neural Architecture Search supporta solo la registrazione di cinque valori other_metrics in virgola mobile.
Eventuali metriche aggiuntive devono essere salvate nella posizione Cloud Storage per un'analisi successiva.