在运行神经架构搜索作业以搜索最优模型之前,请先定义代理任务。第 1 阶段搜索使用完整模型训练中非常小的一部分作为其表示法,该阶段通常在两小时内完成。这种表示法称为代理任务,它可以显著降低搜索费用。搜索期间的每次试验都会使用代理任务设置来训练模型。
以下各部分介绍了应用代理任务设计所涉及的内容:
- 创建代理任务的方法。
- 良好的代理任务的要求。
- 如何使用三个代理任务设计工具找到最佳代理任务,从而降低搜索费用,同时保持搜索质量。
创建代理任务的方法
创建代理任务有三种常用方法,其中包括以下方法:
- 使用较少的训练步骤。
- 使用下采样的训练数据集。
- 使用缩减的模型。
使用较少的训练步骤
创建代理任务的最简单方法是减少训练程序的训练步数,并根据此部分训练将分数报告给控制器。
使用下采样的训练数据集
本部分介绍将下采样训练数据集用于架构搜索和增强政策搜索。
架构搜索
可以在架构搜索期间使用下采样的训练数据集创建代理任务。但是,当进行下采样时,请遵循以下准则:
- 在各分片之间随机重排数据。
- 如果训练数据不均衡,则进行下采样以均衡这些数据。
使用自动增强功能实现的增强政策搜索
如果您不运行仅增强搜索,而仅运行常规架构搜索,请跳过此部分。使用自动增强来搜索增强政策。最好对训练数据进行下采样并运行完整训练,而不是减少训练步骤数。以大量增强的方式运行完整训练可以使分数更稳定。此外,应使用减少的训练数据来降低搜索费用。
基于缩减模型的代理任务
您还可以相对于基准模型缩减模型来创建代理任务。当您希望将块设计搜索与扩缩搜索分离开来时,这种方式也非常有用。
但是,当您缩减模型并希望使用延迟时间限制条件时,请对缩减的模型使用更严格的延迟时间限制条件。提示:您可以缩减基准模型并测量其延迟时间,以设置这一更严格的延迟时间限制条件。
对于缩减模型,与原始基准模型相比,您还可以减少增强和正则化的数量。
缩减模型的示例
对于计算机视觉任务(用于训练图片),有三种常用方法可以用来缩减模型:
- 减小模型宽度:通道数量。
- 减小模型深度:层数和块重复次数。
- 略微减小训练图片大小(不得消除特征)或剪裁训练图片(如果任务允许)。
建议参考读物:EfficientNet 论文详细介绍了有关计算机视觉任务的模型扩缩;此外还介绍了全部三种扩缩方式之间的关系。
Spinenet 搜索是神经架构搜索中使用的另一个模型扩缩示例。对于第 1 阶段搜索,该方法会缩减通道数量并减小图片大小。
基于组合的代理任务
这些方法可以独立工作,并且可以按不同程度组合在一起以创建代理任务。
良好的代理任务的要求
代理任务必须满足特定要求才能向控制器提供稳定的奖励并保持搜索的质量。
第 1 阶段搜索和第 2 阶段完整训练之间的排名相关性
在使用代理任务进行神经架构搜索时,成功搜索的一个关键假设是,如果在第 1 阶段的代理任务训练中,模型 A 的性能优于模型 B,那么在第 2 阶段的完整训练中,模型 A 的性能将优于模型 B。如需验证此假设,您必须针对搜索空间中大约 10-20 个模型评估第 1 阶段搜索和第 2 阶段完整训练的奖励之间的排名相关性。这些模型称为相关性候选模型。
下图是一个相关性不佳的示例 (correlation-score = -0.03),导致此代理任务不适合搜索:
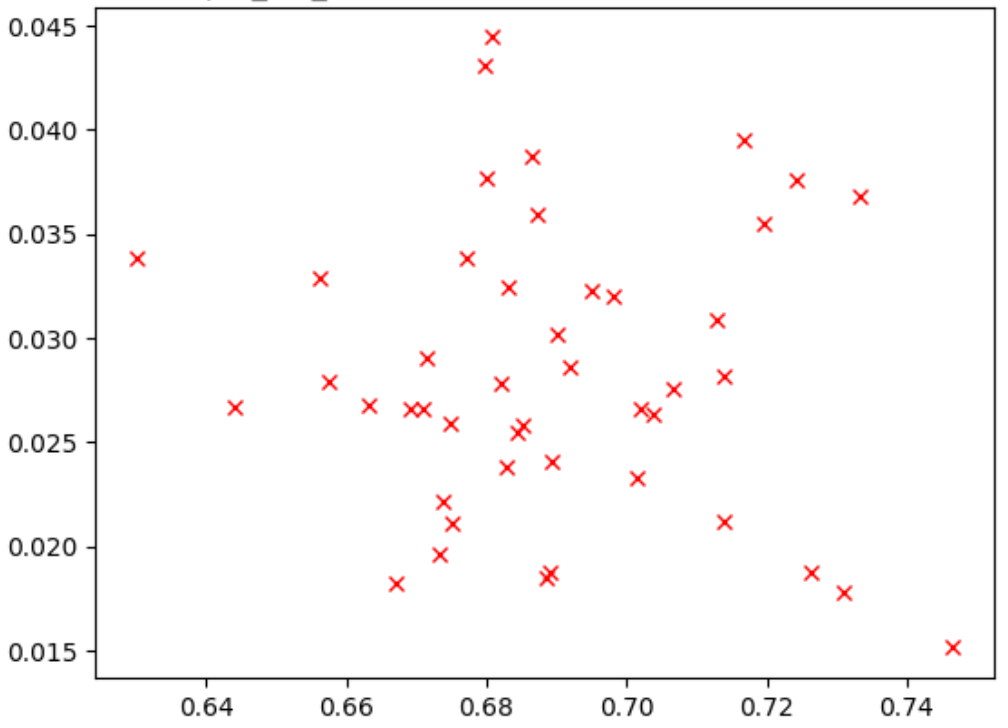
曲线图中的每个点表示一个相关性候选模型。x 轴表示模型的第 2 阶段完整训练分数,y 轴表示相同模型的第 1 阶段代理任务分数。观察最高点。该模型具有最高的代理任务分数(y 轴),但在第 2 阶段完全训练(x 轴)期间性能不佳(与其他模型相比)。相比之下,下图展示了一个良好相关性的示例 (correlation-score = 0.67),这使得此代理任务成为理想的搜索候选对象:

如果搜索涉及延迟时间限制条件,请同时验证延迟时间值的良好相关性。
请注意,相关性候选模型奖励有一个良好的范围和一个不错的奖励范围采样。否则,您将无法评估排名相关性。例如,如果所有相关性候选模型的第 1 阶段奖励都集中在两个值上:0.9 和 0.1,那么这样将无法提供足够的采样变体。
方差检验
代理任务的另一个要求是,在对同一模型多次重复且未进行任何更改时,准确率或延迟时间分数不应该有很大的变化。如果发生这种情况,则会向控制器发回噪声信号。Google 提供了用于测量方差的工具。
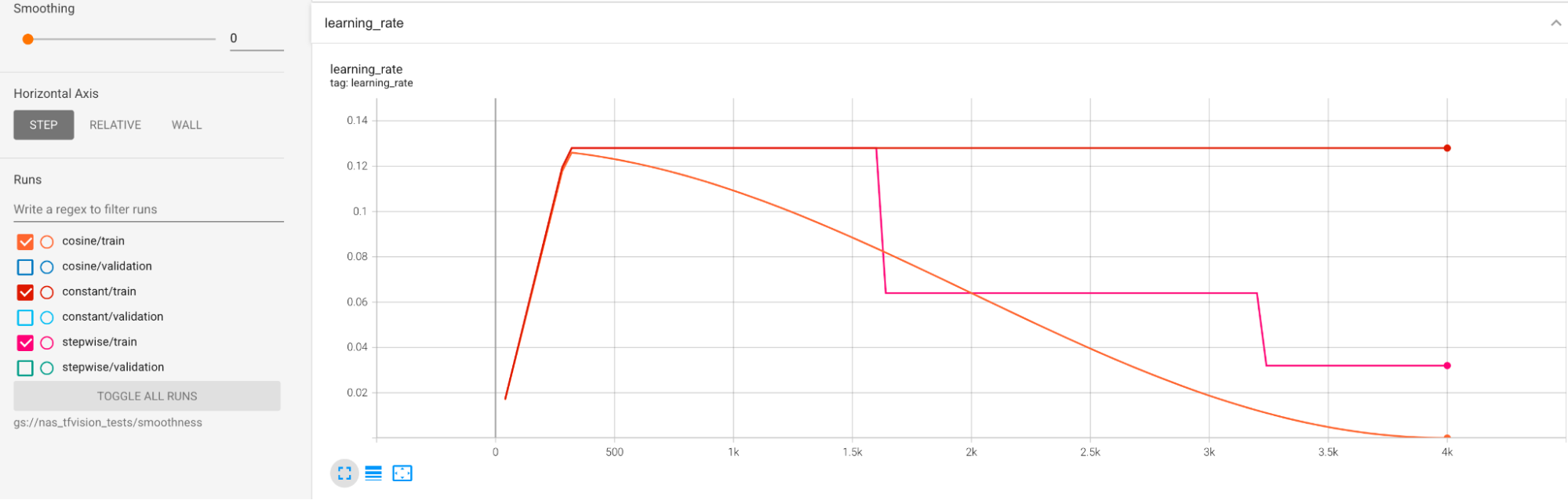
我们提供了一些示例来缓解训练期间的较大方差问题。一种方法是使用 cosine decay 作为学习速率时间表。下面的曲线图比较了三种学习速率策略:

最下面的曲线图对应于恒定的学习速率。如果分数在训练结束时发生跳跃,那么对减少训练步骤数的选择上的微小更改便可能会导致最终代理任务奖励发生大幅变化。为了使代理任务奖励更稳定,最好使用余弦衰减的学习速率,如最上面的曲线图中的相应验证分数所示。请注意最上面的曲线图是如何在训练接近尾声时变得更加平滑的。中间的曲线图显示了与阶梯式衰减的学习速率对应的分数。这种方法比恒定速率效果要更好,但仍不如余弦衰减那样平滑,并且需要手动调整。
学习速率时间表如下所示:
额外平滑
如果您使用大量增强,那么您的验证曲线即便使用余弦衰减可能仍然无法获得足够的平滑度。使用大量增强表明缺乏训练数据。在这种情况下,不建议使用神经架构搜索,我们建议您改用增强搜索。
如果大量增强不是导致平滑度问题的原因,并且您已尝试余弦衰减,但仍想实现更高的平滑度,那么对于 TensorFlow-2 使用指数移动平均数,对于 PyTorch 使用随机加权平均数。请参阅代码指针了解将指数移动平均数优化器与 TensorFlow 2 搭配使用的示例,另请参阅随机加权平均数示例了解 PyTorch 相关用例。
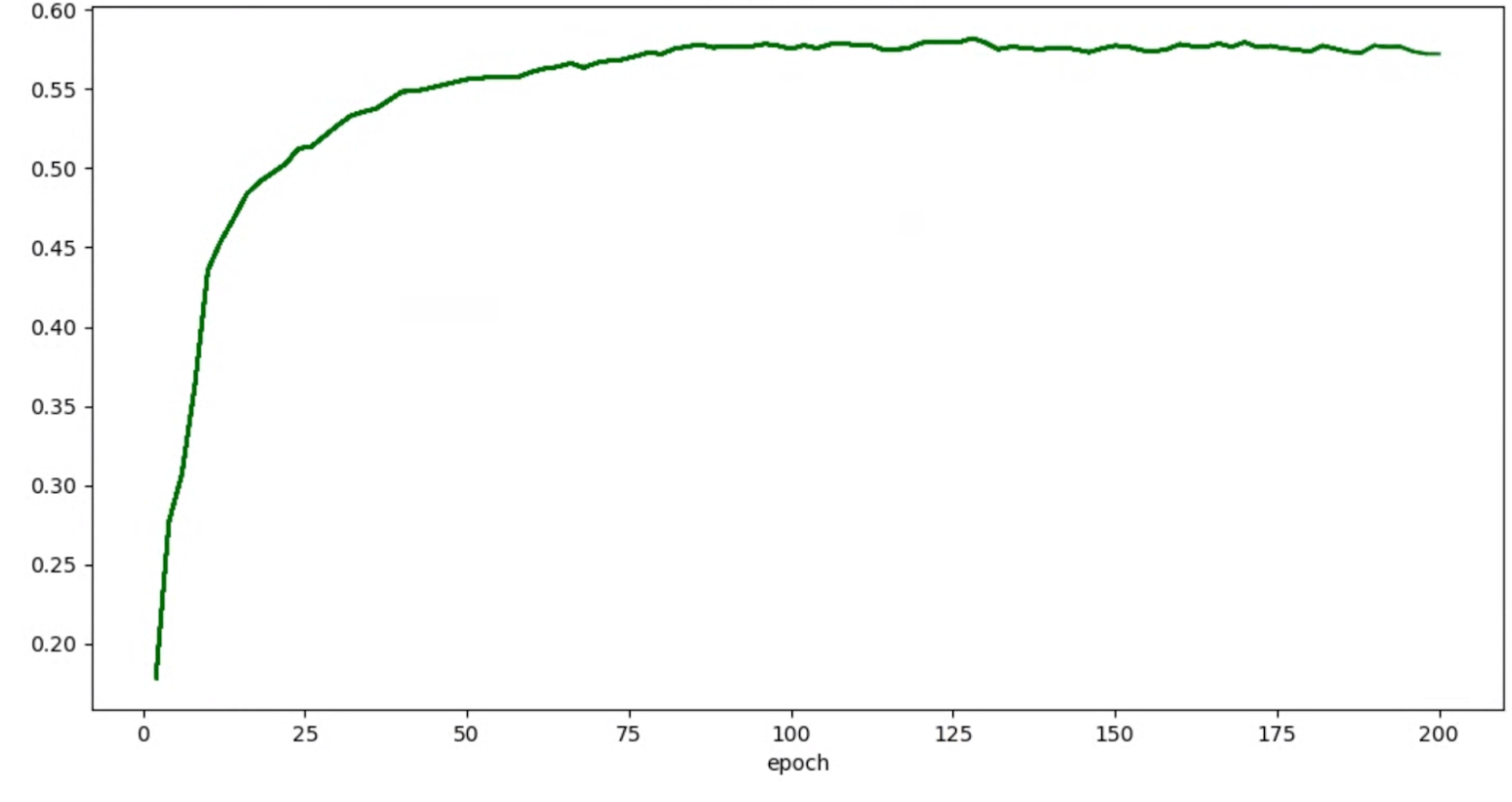
如果试验的准确率/周期图如下所示:

则您可以应用上述平滑方法(例如使用随机加权平均数或指数移动平均数)来获得更为一致的图表:
内存不足 (OOM) 和学习速率相关错误
架构搜索空间可能会生成比基准模型大得多的模型。您可能已为基准模型调整了批次大小,但在搜索期间进行较大模型采样时,此设置可能还是会失败,从而导致 OOM 错误。在这种情况下,您需要减小批次大小。
可能会出现的另一种错误是 NaN(非数字)错误。您应该降低初始学习速率或添加梯度裁剪。
如tutorial-2 中所述,如果搜索空间模型中有超过 20% 返回了无效分数,则不要运行完整搜索。我们的代理任务设计工具提供了一种评估失败率的方法。
代理任务设计工具
上述部分介绍了代理任务设计的原则。本部分提供了三个代理任务设计工具,可根据不同的设计方法自动查找最优且满足所有要求的代理任务。
所需的代码更改
您首先需要对训练程序代码稍加修改,以便它可以在迭代过程中与代理任务设计工具进行交互。tf_vision/train_lib.py 展示了一个示例。您需要先导入我们的库:
from google.cloud.visionsolutions.nas.proxy_task import proxy_task_utils
在训练循环中的训练周期开始之前,请检查您是否需要提前停止训练,因为代理任务设计工具要求您使用我们的库:
if proxy_task_utils.get_stop_training(
model_dir,
end_training_cycle_step=<last-training-step-idx done so far>,
total_training_steps=<total-training-steps>):
break
在训练循环中的每个训练周期完成后,更新新的准确率分数、训练周期的开始和结束步骤、训练周期时间(以秒为单位)以及训练步骤总数。
proxy_task_utils.update_trial_training_accuracy_metric(
model_dir=model_dir,
accuracy=<latest accuracy value>,
begin_training_cycle_step=<beginning training step for this cycle>,
end_training_cycle_step=<end training step for this cycle>,
training_cycle_time_in_secs=<training cycle time (excluding validation)>,
total_training_steps=<total-training-steps>)
请注意,训练周期时间不应包含验证的分数评估时间。确保训练程序经常计算验证分数(评估频率),以便对验证曲线进行足够的采样。如果您使用的是延迟时间限制条件,请在计算延迟时间之后更新延迟时间指标:
proxy_task_utils.update_trial_training_latency_metric(
model_dir=model_dir,
latency=<measured_latency>)
模型选择工具需要加载之前的检查点以进行连续迭代。如需启用重复使用先前的检查点,请在训练程序中添加标志,如 tf_vision/cloud_search_main.py 中所示:
parser.add_argument(
"--retrain_use_search_job_checkpoint",
type=cloud_nas_utils.str_2_bool,
default=False,
help="True to use previous NAS search job checkpoint."
)
在训练模型之前加载此检查点:
if FLAGS.retrain_use_search_job_checkpoint:
prev_checkpoint_dir = cloud_nas_utils.get_retrain_search_job_model_dir(
retrain_search_job_trials=FLAGS.retrain_search_job_trials,
retrain_search_job_dir=FLAGS.retrain_search_job_dir)
logging.info("Setting checkpoint to %s.", prev_checkpoint_dir)
# Now set your checkpoint using 'prev_checkpoint_dir'.
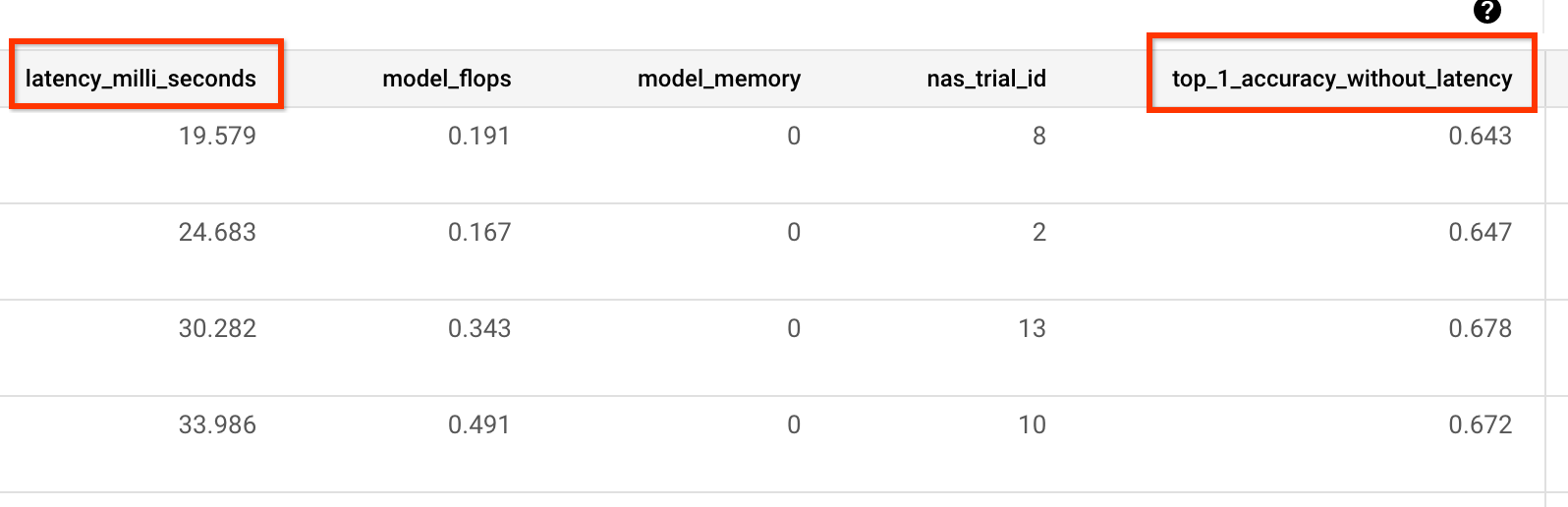
您还需要 metric-id(对应于您的训练程序报告的准确率和延迟时间值)。如果您的训练程序奖励(有时是准确率和延迟时间的组合)与准确率不同,请确保您使用来自您的训练程序的 other_metrics 也报告仅准确率指标。例如,以下示例显示了预构建训练程序报告的仅准确率和延迟时间指标:
方差测量
修改训练程序代码后,第一步是测量训练程序的方差。对于方差测量,请修改以下内容的基准训练配置:
- 减少训练步骤,仅运行约一小时,并且仅使用一个或两个 GPU。我们需要完整训练的一个小型样本。
- 使用余弦衰减学习速率,并将其步骤数设置为与这些减少的步骤数相同,使得结束时学习速率接近于零。
方差测量工具会从搜索空间对一个模型进行采样,确保该模型可以开始训练而不会产生 OOM 或 NAN 错误,并根据您的设置运行此模型的五个副本(运行时长约一小时),然后报告训练得分方差和平滑度。运行此工具的总费用约等于根据您的设置运行五个模型大约一小时。
运行以下命令来启动方差测量作业(您需要服务账号):
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
region=<your job region such as 'us-central1'>
search_space_module=<path to your search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
####### Variance measurement related parameters ######
proxy_task_variance_measurement_docker_id=${USER}_variance_measurement_${DATE}
# Use the service account that you set-up for your project.
service_account=<your service account>
job_name=<your job name>
############################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--proxy_task_variance_measurement_docker_id=${proxy_task_variance_measurement_docker_id}
# The command below passes 'dummy' arguments for the training docker.
# You need to modify them for your own docker.
python3 vertex_nas_cli.py measure_proxy_task_variance \
--proxy_task_variance_measurement_docker_id=${proxy_task_variance_measurement_docker_id} \
--project_id=${project_id} \
--service_account=${service_account} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
启动此方差测量作业后,您将获得一个作业链接。作业名称应以 Variance_Measurement 前缀开头。下面显示了示例作业界面:
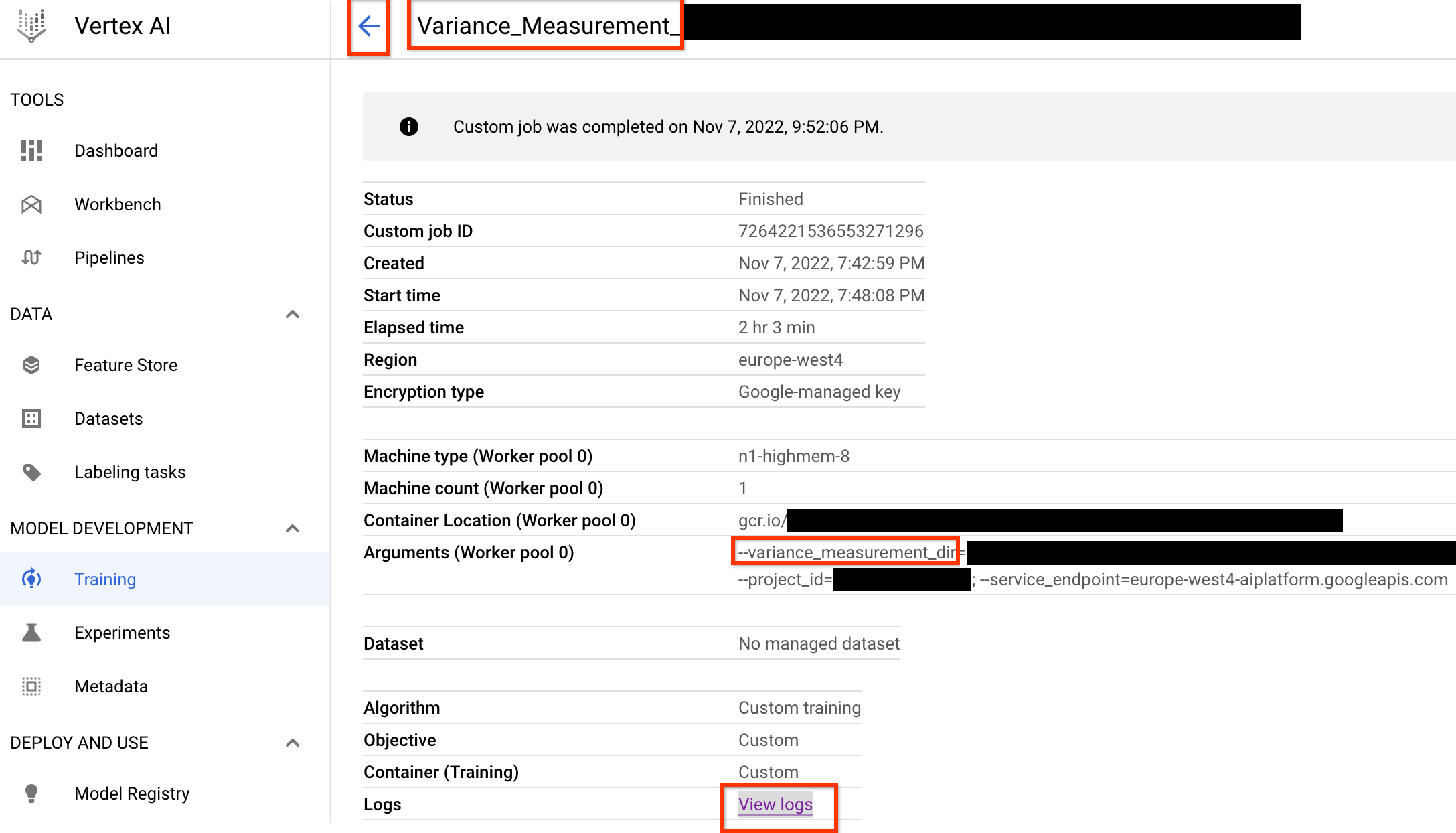
variance_measurement_dir 包含所有输出,您可以通过点击查看日志链接来检查日志。默认情况下,此作业使用一个云端 CPU 以自定义作业的形式在后台运行,然后启动并管理子 NAS 作业。

在 NASNAS 作业下,您会看到一个名为 Find_workable_model_<your job name> 的作业。此作业将对您的搜索空间进行采样,以找到一个不会生成任何错误的模型。找到这样的模型后,方差测量作业将启动另一个 NASNAS 作业 <your job name>,该作业按照您先前设置的训练步骤数运行该模型的五个副本。针对这些模型完成训练后,方差测量作业会测量其分数方差和平滑度,并在其日志中报告这些内容:
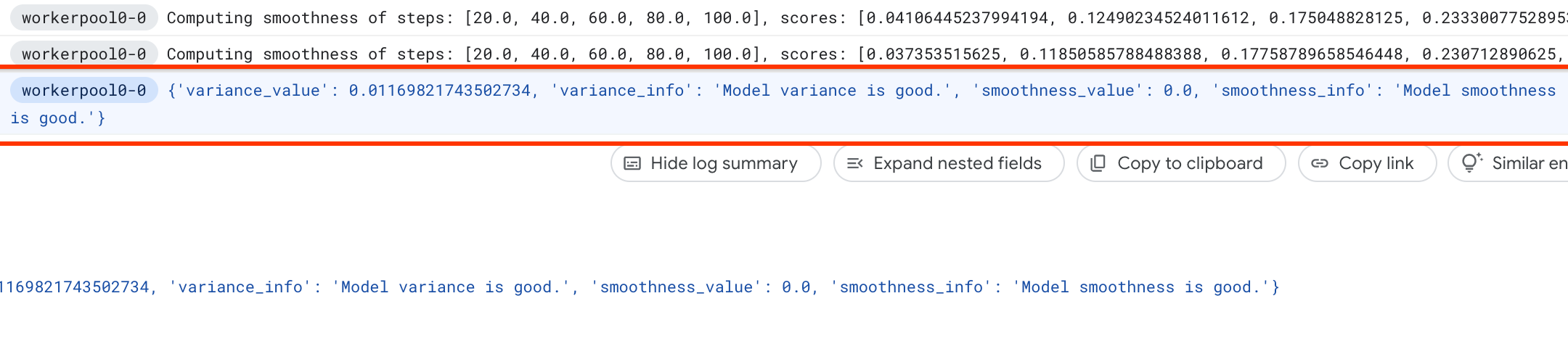
如果方差很大,您可以探索此处列出的技术。
模型选择
确认训练程序没有很大的方差后,后续步骤如下:
- 查找约 10 个相关性候选模型
- 计算它们的完整训练分数,当您稍后计算不同代理任务选项的代理任务相关性分数时,这些分数将作为参考。
我们的工具会自动高效地找到这些相关性候选模型,并确保它们在准确率和延迟时间方面具有良好的分数分布,以使未来的相关性计算具有良好的基础。为此,工具将执行以下操作:
- 从搜索空间中随机采样
N_begin模型。对于此处的示例,我们假设是N_begin = 30。工具对这些模型进行训练,训练时间是完整训练的 1/30。 - 拒绝 30 个模型中的 5 个,这些模型对准确率和延迟时间的分布贡献不大。下图显示了这种情况的一个示例。拒绝的模型显示为红色点:
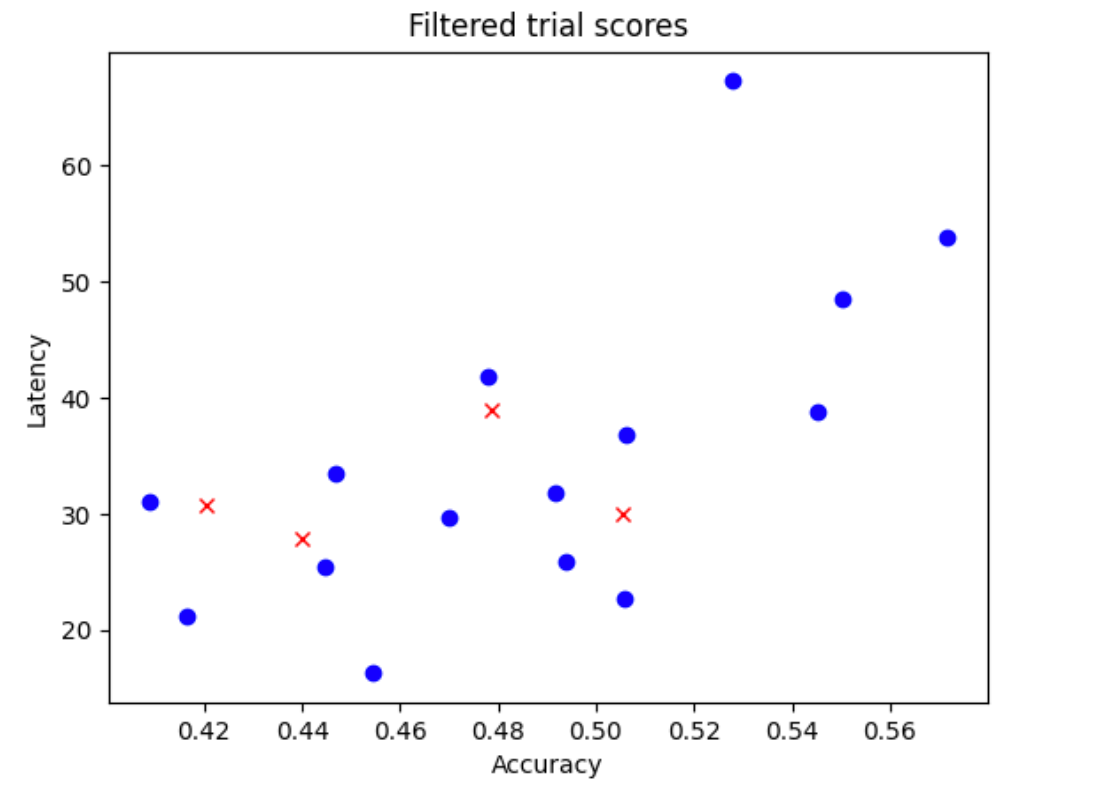
- 以 1/25 的完整训练时间训练 25 个选择的模型,然后根据到目前为止的分数拒绝另外 5 个模型。请注意,25 个模型的训练从它们之前的检查点继续。
- 重复此过程,直到只剩下
N个分布良好的模型。 - 训练最后这
N个模型。
N_begin 的默认设置是 30,您可以在 proxy_task/proxy_task_model_selection_lib_constants.py 文件的 START_NUM_MODELS 中找到。N 的默认设置是 10,您可以在 proxy_task/proxy_task_model_selection_lib_constants.py 文件的 FINAL_NUM_MODELS 中找到。
此模型选择过程的额外费用按以下方式计算:
= (30*1/30 + 25*1/25 + 20*1/20 + 15*1/15 + 10*(remaining-training-time-fraction)) * full-training-time
= (4 + 10*(0.81)) * full-training-time
~= 12 * full-training-time
不过,请保持高于 N=10 设置。代理任务搜索工具稍后会并行运行这些 N 模型。因此,请确保您有足够的 GPU 配额。例如,如果您的代理任务为一个模型使用两个 GPU,您至少应有 2*N 个 GPU 的配额。
对于模型选择作业,请使用与第 2 阶段完整训练作业相同的数据集分区,并将相同的训练程序配置用于基准完整训练。
现在,您可以通过运行以下命令来启动模型选择作业(您需要服务账号):
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
latency_calculator_docker_id=${USER}_model_selection_${DATE}
latency_calculator_docker_file=${USER}_latency_${DATE}
region=<your job region such as 'us-central1'>
search_space_module=<path to your search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
# Your latency computation device.
target_device_type="CPU"
####### Proxy task model-selection related parameters ######
proxy_task_model_selection_docker_id=${USER}_model_selection_${DATE}
# Use the service account that you set-up for your project.
service_account=<your service account>
job_name=<your job name>
# The value below depends on your accelerator quota. By default
# the model-selection job runs 30 trials. However, depending on
# your quota, you can choose to only run 10 trials in parallel at a time.
# However, lowering this number can increase the overall runtime for the job.
max_parallel_nas_trial=<num parallel trials>
# The value below is the 'metric-id' corresponding to the accuracy ONLY
# metric reported by your trainer. Note that this metric may
# be different from the 'reward'.
accuracy_metric_id=<set accuracy metric id used by your trainer>
latency_metric_id=<set latency metric id used by your trainer>
############################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_calculator_docker_file=${latency_calculator_docker_file} \
--proxy_task_model_selection_docker_id=${proxy_task_model_selection_docker_id}
# The command below passes 'dummy' arguments for trainer-docker
# and latency-docker. You need to modify them for your own docker.
python3 vertex_nas_cli.py select_proxy_task_models \
--service_account=${service_account} \
--proxy_task_model_selection_docker_id=${proxy_task_model_selection_docker_id} \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--max_parallel_nas_trial=${max_parallel_nas_trial} \
--accuracy_metric_id=${accuracy_metric_id} \
--latency_metric_id=${latency_metric_id} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_docker_flags \
dummy_latency_flag1="dummy_latency_val" \
--target_device_type=${target_device_type} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
启动此模型选择控制器作业后,您将收到作业链接。作业名称以前缀 Model_Selection_ 开头。下面显示了示例作业界面:
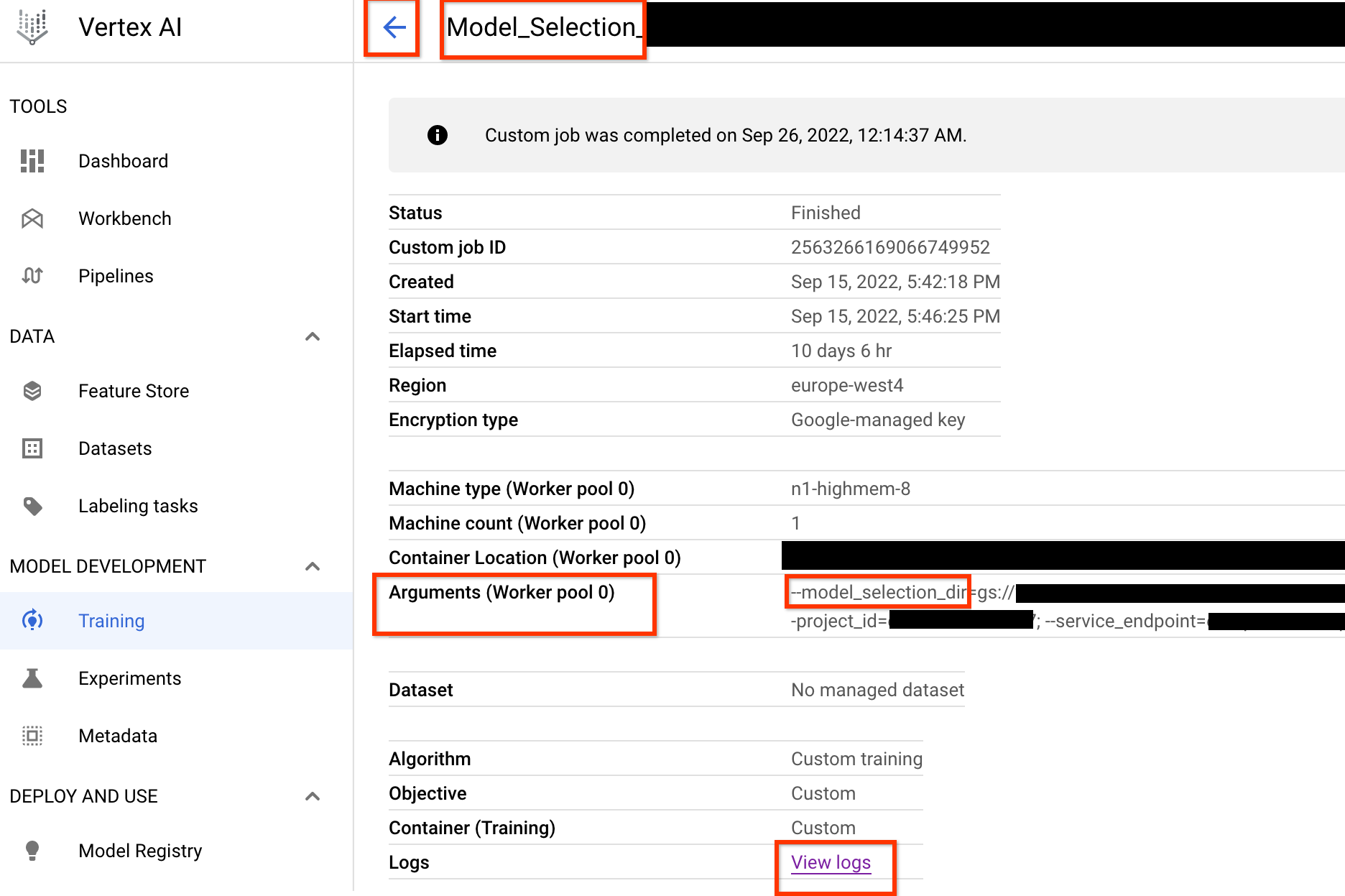
model_selection_dir 包含所有输出。可通过点击 View logs 链接来检查日志。此模型选择控制器作业默认使用 Google Cloud 上的 1 个 CPU 作为自定义作业在后台运行,然后为模型选择的每次迭代启动和管理子 NAS 作业。
每个子级 NAS 作业都有一个名称,例如 <your_job_name>_iter_3(迭代 0 除外)。一次只运行一个迭代。每次迭代时,模型的数量(试验次数)会减少,训练时长会增加。在每次迭代结束时,每个 NASNAS 作业都会保存 gs://<job-output-dir>/search/filtered_trial_scores.png 文件,其直观显示哪些模型在此迭代中被拒绝。您还可以运行以下命令:
gcloud storage cat gs://<path to 'model_selection_dir'>/MODEL_SELECTION_STATE.json
它显示模型选择控制器作业的迭代和当前状态的摘要、作业名称和每次迭代的链接:
{
"start_num_models": 30,
"final_num_models": 10,
"num_models_to_remove_per_iter": 5,
"accuracy_metric_id": "top_1_accuracy_without_latency",
"latency_metric_id": "latency_milli_seconds",
"iterations": [
{
"num_trials": 30,
"trials_to_retrain": [
"27",
"16",
...,
"14"
],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2111217356469436416",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2111217356469436416/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/6909239809479278592",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/6909239809479278592/cpu?project=my-project",
"desired_training_step_pct": 2.0
},
...,
{
"num_trials": 15,
"trials_to_retrain": [
"14",
...,
"5"
],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/7045544066951413760",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/7045544066951413760/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/2790768318993137664",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2790768318993137664/cpu?project=my-project",
"desired_training_step_pct": 28.57936507936508
},
{
"num_trials": 10,
"trials_to_retrain": [],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2742864796394192896",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2742864796394192896/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/1490864099985195008",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/1490864099985195008/cpu?project=my-project",
"desired_training_step_pct": 101.0
}
]
}
最后一次迭代具有分数分布良好的参考模型的最终数量。这些模型及其分数将用于下一步中的代理任务搜索。如果参考模型的最终准确率和延迟时间分数范围看起来更好或接近现有基准模型,则您可以很好地了解搜索空间。如果最终准确率和延迟时间分数范围明显低于基准,则重新访问搜索空间。
请注意,如果在第一次迭代中超过 20% 的试验失败,请取消模型选择作业并确定失败的根本原因。这可能是搜索空间或批次大小和学习速率设置出现问题。
使用本地延迟时间设备进行模型选择
如需使用本地延迟时间设备进行模型选择,请运行 select_proxy_task_models 命令,但不包括延迟时间 Docker 和延迟时间 Docker 标志,因为您不希望在 Google Cloud上启动延迟时间 Docker。接下来,使用教程 4 中所述的 run_latency_calculator_local 命令启动本地延迟时间计算器作业。不传递 --search_job_id 标志,而是传递 --controller_job_id 标志和运行 select_proxy_task_models 命令后获得的数字模型选择作业 ID。
恢复模型选择控制器作业
在以下情况下,您需要恢复模型选择控制器作业:
- 父模型选择控制器作业终止(罕见情况)。
- 您意外取消模型选择控制器作业。
首先,如果子级 NASNAS 迭代作业(“NAS”标签页)已在运行,请不要将其取消。然后,如需恢复父模型选择控制器作业,请像之前一样运行 select_proxy_task_models 命令,但这次传递 --previous_model_selection_dir 标志,并将其设置为上一个模型选择控制器作业的输出目录。恢复的模型选择控制器作业会从目录加载其之前的状态,并继续像之前一样运行。
代理任务搜索
找到相关性候选模型及其完整训练分数后,下一步是使用这些模型来评估不同代理任务选项的相关性分数,并选择最佳代理任务。我们的代理任务搜索工具可以自动找到代理任务,该任务可以提供:
- 最低的 NAS 搜索费用。
- 在获得提供代理任务搜索空间定义后,满足最小相关性要求阈值。
回想一下,有三个用于搜索最佳代理任务的常用维度,包括:
- 减少的训练步骤数。
- 减少的训练数据量。
- 减小的模型规模。
您可以通过对下面所示的这些维度进行采样来创建离散代理任务搜索空间:

上述百分比数字仅为近似建议和示例。实际上,您可以选择任何离散选项。
请注意,上述搜索空间中不包含训练步骤维度。这是因为代理任务搜索工具会根据代理任务选择来确定最佳训练步骤。请考虑代理任务选择 [50% training data, 25% model scale]。将训练步骤数设置为与完整基准训练相同的数量。在评估此代理任务时,代理任务搜索工具会启动相关性候选模型的训练,监控其当前的准确率分数,并持续计算排名相关性分数(使用参考模型的过去的全面训练分数):

因此,一旦获得所需的相关性(例如 0.65),代理任务搜索工具就可以停止代理任务训练,或者如果超过了搜索费用配额(例如每个代理任务的 3 小时),训练也会提前停止。因此,不需要跨训练步骤执行明确搜索。代理任务搜索工具会将离散搜索空间中的每个代理任务以网格搜索的形式进行评估,并为您提供最佳选项。
下面是在 proxy_task/proxy_task_search_spaces.py 文件中定义的 MnasNet 代理任务搜索空间定义示例 mnasnet_proxy_task_config_generator,用于演示如何定义您自己的搜索空间:
# MNasnet training-data size choices.
MNASNET_TRAINING_DATA_PCT_LIST = [25, 50, 75, 95]
# Training data path regex pattern.
_TRAINING_DATA_PATH_REGEX = r"gs://.*/.*"
def update_mnasnet_proxy_training_data(
baseline_docker_args_map: Dict[str, Any],
training_data_pct: int) -> Optional[Dict[str, Any]]:
"""Updates MNasnet baseline docker to use a certain training_data_pct."""
proxy_task_docker_args_map = copy.deepcopy(baseline_docker_args_map)
# Imagenet training data path looks like:
# gs://<path to imagenet data>/train-00[0-7]??-of-01024.
if not re.match(_TRAINING_DATA_PATH_REGEX,
baseline_docker_args_map["training_data_path"]):
raise ValueError(
"Training data path %s does not match the desired pattern." %
baseline_docker_args_map["training_data_path"])
root_path, _ = baseline_docker_args_map["training_data_path"].rsplit("/", 1)
if training_data_% == 25:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-1][0-4]?-of-01024*")
elif training_data_% == 50:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-4]??-of-01024*")
elif training_data_% == 75:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-6][0-4]?-of-01024*")
elif training_data_% == 95:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-8][0-4]?-of-01024*")
else:
logging.warning("Mnasnet training_data_% %d is not supported.",
training_data_pct)
return None
proxy_task_docker_args_map["validation_data_path"] = os.path.join(
root_path, "train-009[0-4]?-of-01024")
return proxy_task_docker_args_map
def mnasnet_proxy_task_config_generator(
baseline_docker_args_map: Dict[str, Any]
) -> List[proxy_task_utils.ProxyTaskConfig]:
"""Returns a list of proxy-task configs to be evaluated for MNasnet.
Args:
baseline_docker_args_map: A set of baseline training-docker arguments in
the form of a dictionary of {'key', val}. The different proxy-task
configs to try can be built by modifying this baseline.
Returns:
A list of proxy-task configs to be evaluated for this
proxy-task search space.
"""
proxy_task_config_list = []
# NOTE: Will not search over model-scale for MNasnet.
for training_data_% in MNASNET_TRAINING_DATA_PCT_LIST:
proxy_task_docker_args_map = update_mnasnet_proxy_training_data(
baseline_docker_args_map=baseline_docker_args_map,
training_data_pct=training_data_pct)
if not proxy_task_docker_args_map:
continue
proxy_task_name = "mnasnet_proxy_training_data_pct_{}".format(
training_data_pct)
proxy_task_config_list.append(
proxy_task_utils.ProxyTaskConfig(
name=proxy_task_name, docker_args_map=proxy_task_docker_args_map))
return proxy_task_config_list
在此示例中,我们针对训练数据百分比 25、50、75 和 95 创建了一个简单的搜索空间(请注意,100% 的训练数据不用于第 1 阶段搜索)。mnasnet_proxy_task_config_generator 函数接受训练 Docker 参数的一个通用基准模板,然后为每个所需代理任务训练数据大小修改这些参数。然后,它返回一个代理任务配置列表,稍后代理任务搜索工具会按相同顺序逐一处理各个配置。每个代理任务配置都有一个 name 和 docker_args_map,这是代理任务 Docker 参数的键值对映射。
您可以根据自己的需求自由实现自己的搜索空间定义,甚至可以为减少的训练数据或减小的模型规模的超过两个维度设计自己的代理任务搜索空间。但是,建议不要跨训练步骤执行明确搜索,因为这涉及徒劳的重复计算。让代理任务搜索工具为您处理此维度。
对于第一个代理任务搜索,您可以尝试仅减少训练数据(就像 MnasNet 示例一样),并跳过减小的模型规模,因为模型扩缩可能涉及 image-size、num-filters 或 num-blocks 的多个参数。
在大多数情况下,减少的训练数据(以及通过减少的训练步骤进行的隐式搜索)足以找到良好的代理任务。
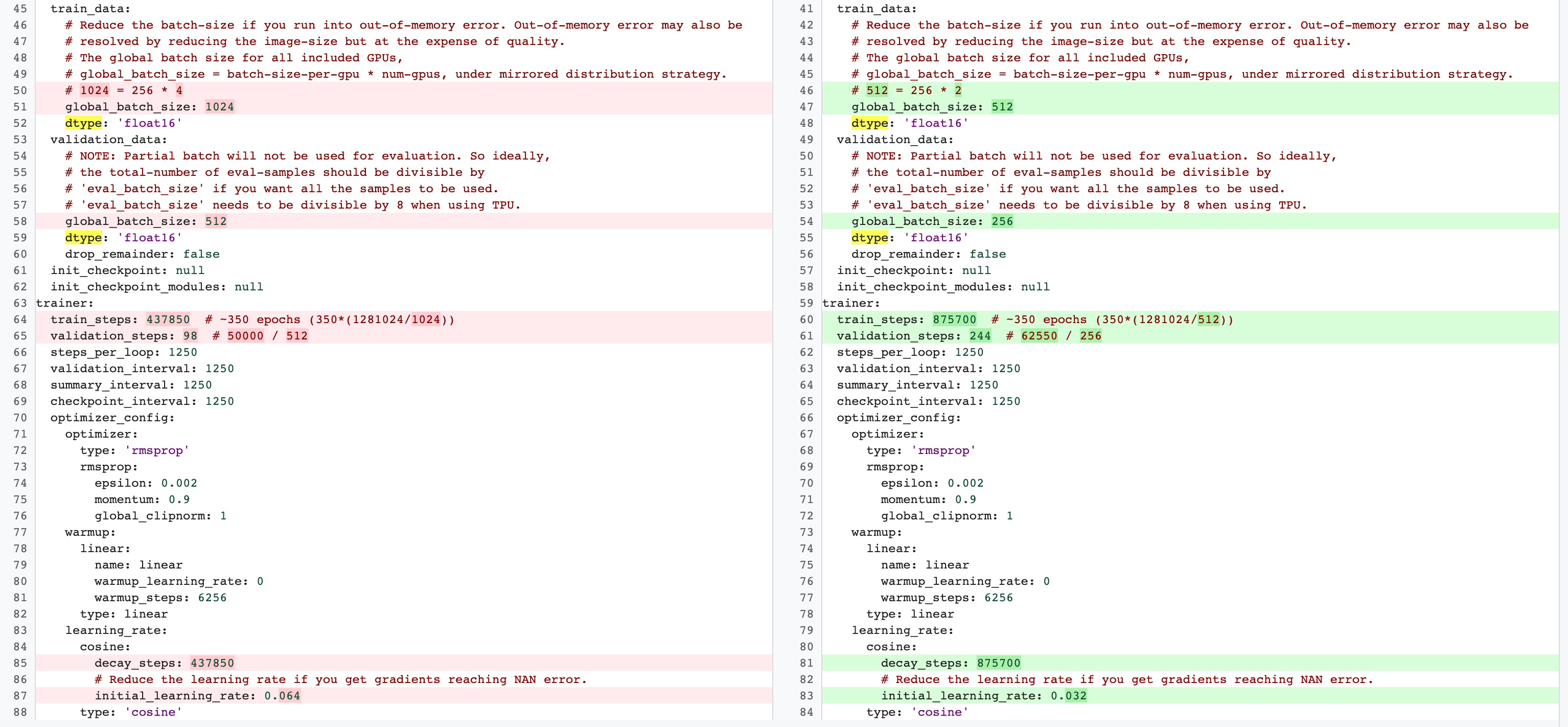
将训练步骤数设置为完整基准训练中使用的步骤数。第 2 阶段完整训练和第 1 阶段代理任务训练配置之间存在差异。对于代理任务,与完整基准训练配置相比,您应该减少 batch-size,以仅使用 2 个 GPU 或 4 个 GPU。一般而言,完整训练使用 4 个 GPU、8 个 GPU 或更多,但代理任务仅使用 2 个 GPU 或 4 个 GPU。另一个区别在于训练和验证拆分。下面显示了一个示例,说明 MnasNet 配置从第 2 阶段完整训练的 4 个 GPU 更改为 2 个 GPU,以及用于代理任务搜索的不同验证拆分:
运行以下命令来启动代理任务搜索控制器作业(您需要服务账号):
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
latency_calculator_docker_id=${USER}_model_selection_${DATE}
latency_calculator_docker_file=${USER}_latency_${DATE}
region=<your job region such as 'us-central1'>
search_space_module=<path to your NAS job search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
# Your latency computation device.
target_device_type="CPU"
####### Proxy task search related parameters ######
proxy_task_search_controller_docker_id=${USER}_proxy_task_search_${DATE}
job_name=<your job name>
# Path to your proxy task search space definition. For ex:
# 'proxy_task.proxy_task_search_spaces.mnasnet_proxy_task_config_generator'
proxy_task_config_generator_module=<path to your proxy task config generator module>
# The previous model-slection job provides the candidate-correlation-models
# and their scores.
proxy_task_model_selection_job_id=<Numeric job id of your previous model-selection>
# During proxy-task search, the proxy-task training is stopped
# when the following correlation score is achieved.
desired_accuracy_correlation=0.65
# During proxy-task search, the proxy-task training is stopped
# if the runtime exceeds this limit: 4 hrs.
training_time_hrs_limit=4
# The proxy-task is marked a good candidate only if the latency
# correlation is also above the required threshold.
# Note: This won't be used if you do not have a latency job.
desired_latency_correlation=0.65
# Early stop a proxy-task evaluation if you already have a better candidate.
# If False, evaluate all proxy-taask candidates.
early_stop_proxy_task_if_not_best=False
# Use the service account that you set-up for your project.
service_account=<your service account>
###################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_calculator_docker_file=${latency_calculator_docker_file} \
--proxy_task_search_controller_docker_id=${proxy_task_search_controller_docker_id}
# The command below passes 'dummy' arguments for trainer-docker
# and latency-docker. You need to modify them for your own docker.
python3 vertex_nas_cli.py search_proxy_task \
--service_account=${service_account} \
--proxy_task_search_controller_docker_id=${proxy_task_search_controller_docker_id} \
--proxy_task_config_generator_module=${proxy_task_config_generator_module} \
--proxy_task_model_selection_job_id=${proxy_task_model_selection_job_id} \
--proxy_task_model_selection_job_region=${region} \
--desired_accuracy_correlation={$desired_accuracy_correlation}\
--training_time_hrs_limit=${training_time_hrs_limit} \
--desired_latency_correlation=${desired_latency_correlation} \
--early_stop_proxy_task_if_not_best=${early_stop_proxy_task_if_not_best} \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_docker_flags \
dummy_latency_flag1="dummy_latency_val" \
--target_device_type=${target_device_type} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
启动此代理任务搜索控制器作业后,您会收到作业链接。作业名称以前缀 Search_controller_ 开头。下面显示了示例作业界面:
search_controller_dir 包含所有输出,您可以通过点击 View logs 链接来检查日志。默认情况下,此作业使用一个云端 CPU 以自定义作业的形式在后台运行,然后为每次代理任务评估启动并管理子 NAS 作业。
每个代理任务 NASNAS 作业的名称类似于 ProxyTask_<your-job-name>_<proxy-task-name>,其中 <proxy-task-name> 是您的代理任务配置生成器模块为每个代理提供的名称任务。一次只运行一个代理任务评估。您还可以运行以下命令:
gcloud storage cat gs://<path to 'search_controller_dir'>/SEARCH_CONTROLLER_STATE.json
此命令会显示所有代理任务评估的摘要以及搜索控制器作业的当前状态、作业名称和每个评估的链接:
{
"proxy_tasks_map": {
"mnasnet_proxy_training_data_pct_25": {
"proxy_task_stats": {
"training_steps": [
1249,
2499,
...,
18749
],
"accuracy_correlation_over_step": [
-0.06666666666666667,
-0.6,
...,
0.7857142857142856
],
"accuracy_correlation_p_value_over_step": [
0.8618005952380953,
0.016666115520282188,
...,
0.005505952380952381
],
"median_accuracy_over_step": [
0.011478611268103123,
0.04956454783678055,
...,
0.32932570576667786
],
"median_training_time_hrs_over_step": [
0.11611097933475001,
0.22913257125276987,
...,
1.6682701704073444
],
"latency_correlation": 0.9555555555555554,
"latency_correlation_p_value": 5.5114638447971785e-06,
"stopping_state": "Met desired correlation",
"posted_stop_trials_message": true,
"final_training_time_in_hours": 1.6675102778428197,
"final_training_steps": 18512
},
"proxy_task_name": "mnasnet_proxy_training_data_pct_25",
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/4173661476642357248",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/4173661476642357248/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/8785347495069745152",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/8785347495069745152/cpu?project=my-project"
},
...,
"mnasnet_proxy_training_data_pct_95": {
"proxy_task_stats": {
"training_steps": [
1249,
...,
18749
],
"accuracy_correlation_over_step": [
-0.3333333333333333,
...,
0.7857142857142856,
-5.0
],
"accuracy_correlation_p_value_over_step": [
0.21637345679012346,
...,
0.005505952380952381,
-5.0
],
"median_accuracy_over_step": [
0.01120645459741354,
...,
0.38238024711608887,
-1.0
],
"median_training_time_hrs_over_step": [
0.11385884770307843,
...,
1.5466042930547819,
-1.0
],
"latency_correlation": 0.9555555555555554,
"latency_correlation_p_value": 5.5114638447971785e-06,
"stopping_state": "Met desired correlation",
"posted_stop_trials_message": true,
"final_training_time_in_hours": 1.533235285929564,
"final_training_steps": 17108
},
"proxy_task_name": "mnasnet_proxy_training_data_pct_95",
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2341822328209408000",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2341822328209408000/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/7575005095213924352",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/7575005095213924352/cpu?project=my-project"
}
},
"best_proxy_task_name": "mnasnet_proxy_training_data_pct_75"
}
proxy_tasks_map 存储每个代理任务评估的输出,best_proxy_task_name 记录搜索的最佳代理任务。每个代理任务条目都包含额外的数据,例如 proxy_task_stats,用于记录训练步骤的准确率相关性进度、p 值、中位数准确率以及中位数训练时间。它还会记录与延迟时间相关的相关性(如果适用),并记录停止此作业的原因(例如超出训练时间限制)以及作业在哪个训练步骤停止。您还可以采用曲线图形式查看这些统计信息,方法是通过运行以下命令将 search_controller_dir 的内容复制到本地文件夹:
gcloud storage cp gs://<path to 'search_controller_dir'>/* /your/local/dir
并检查曲线图。例如,下面的曲线图显示了最佳代理任务的准确率相关性与训练时间:
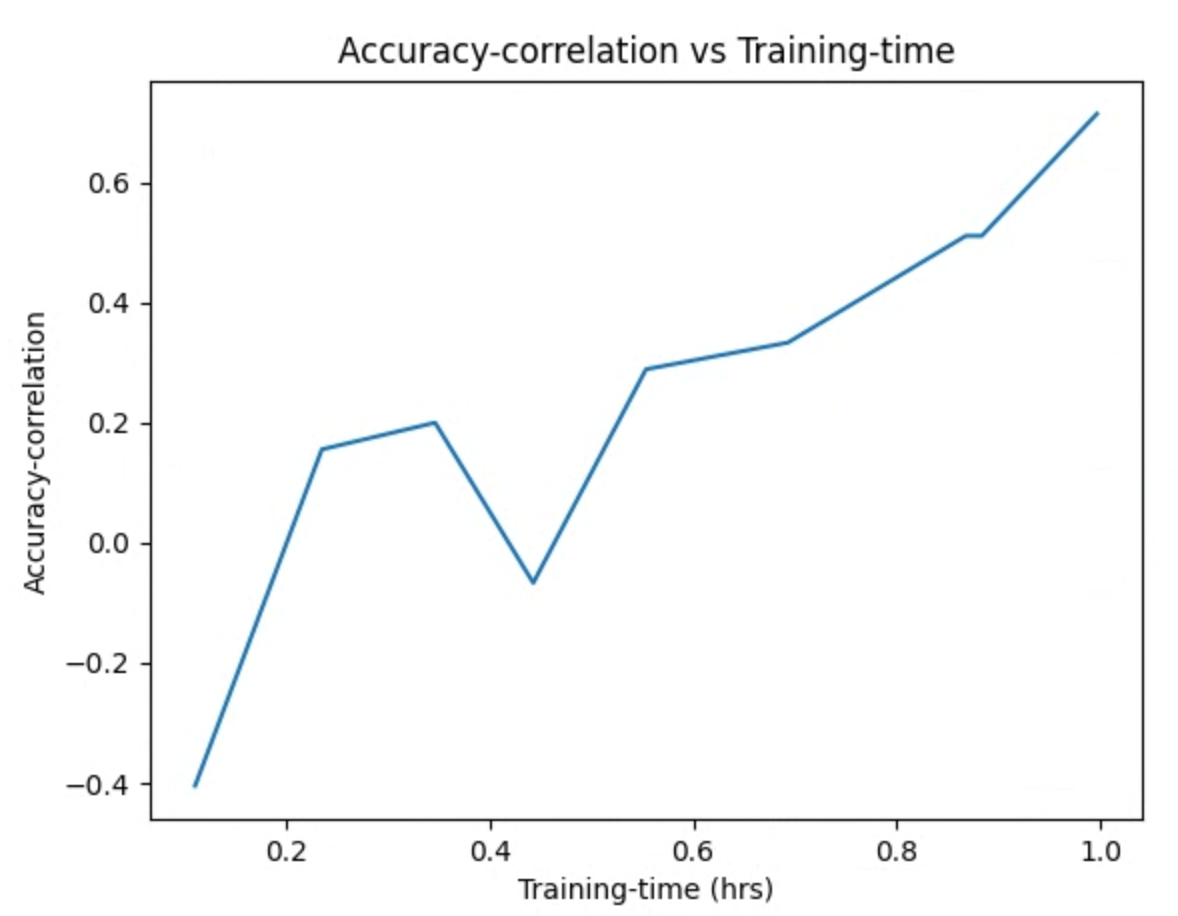
您的搜索已完成,并且您已找到最佳代理任务配置,您必须执行以下操作:
- 将训练步骤数设置为胜出代理任务的
final_training_steps。 - 将余弦衰减步骤设置为与
final_training_steps相同,使得结束时学习速率接近于零。 - [可选] 在训练结束时执行一个验证分数评估,从而节省多个评估费用。
使用本地延迟时间设备进行代理任务搜索
如需使用本地延迟时间设备进行代理任务搜索,请运行 search_proxy_task 命令,但不包括延迟时间 Docker 和延迟时间 Docker 标志,因为您不希望在 Google Cloud上启动延迟时间 Docker。接下来,使用教程 4 中所述的 run_latency_calculator_local 命令启动本地延迟时间计算器作业。不传递 --search_job_id 标志,而是传递 --controller_job_id 标志和运行 search_proxy_task 命令后获得的数字代理任务搜索作业 ID。
恢复代理任务搜索控制器作业
在以下情况下,您需要恢复代理任务搜索控制器作业:
- 父级代理任务搜索控制器作业终止(罕见情况)。
- 您意外取消代理任务搜索控制器作业。
- 您希望稍后扩展代理任务搜索空间(即使在许多天后)。
首先,如果子级 NASNAS 迭代作业(“NAS”标签页)已在运行,请不要将其取消。然后,如需恢复父级代理任务搜索控制器作业,请像之前一样运行 search_proxy_task 命令,但这次传递 --previous_proxy_task_search_dir 标志,并将其设置为上一个代理任务搜索控制器作业的输出目录。恢复的代理任务搜索控制器作业会从目录加载其之前的状态,并继续像之前一样运行。
最终检查
针对代理任务的两个最终检查包括奖励范围以及保存数据以供搜索后分析使用。
奖励范围
报告给控制器的奖励应在 [1e-3, 10] 范围内。如果不是这种情况,您可以人为地扩缩该奖励以实现此目标。
保存数据以便进行搜索后分析
您的代理任务代码应将任何其他指标和数据保存到 Cloud Storage 位置,这可能有助于您之后分析搜索空间。神经架构搜索平台只支持最多 5 个浮点 other_metrics 记录。任何其他指标都应保存到 Cloud Storage 位置,以供日后分析。