本指南介绍如何使用 Google 的预构建搜索空间和基于 TF-vision 的预构建训练程序代码,为 MnasNet 和 SpineNet 运行 Vertex AI 神经架构搜索作业。如需查看端到端示例,请参阅 MnasNet 分类笔记本和 SpineNet 对象检测笔记本。
为预构建的训练程序准备数据
神经架构搜索预建训练程序要求数据采用 TFRecord 格式,其中包含 tf.train.Example。tf.train.Example 必须包含以下字段:
'image/encoded': tf.FixedLenFeature(tf.string)
'image/height': tf.FixedLenFeature(tf.int64)
'image/width': tf.FixedLenFeature(tf.int64)
# For image classification only.
'image/class/label': tf.FixedLenFeature(tf.int64)
# For object detection only.
'image/object/bbox/xmin': tf.VarLenFeature(tf.float32)
'image/object/bbox/xmax': tf.VarLenFeature(tf.float32)
'image/object/bbox/ymin': tf.VarLenFeature(tf.float32)
'image/object/bbox/ymax': tf.VarLenFeature(tf.float32)
'image/object/class/label': tf.VarLenFeature(tf.int64)
您可以遵循此处的 ImageNet 数据准备说明。
如需转换自定义数据,请使用下载的示例代码和实用程序附带的解析脚本。如需自定义数据解析,请修改 tf_vision/dataloaders/*_input.py 文件。
详细了解 TFRecord 和 tf.train.Example。
定义实验环境变量
在运行实验之前,您需要定义多个环境变量,包括:
- TRAINER_DOCKER_ID:
${USER}_nas_experiment(推荐格式) 实验将使用的训练和验证数据集的 Cloud Storage 位置。例如(用于检测的 CoCo):
gs://cloud-samples-data/ai-platform/built-in/image/coco/train*gs://cloud-samples-data/ai-platform/built-in/image/coco/val*
实验输出的 Cloud Storage 位置。推荐的格式:
gs://${USER}_nas_experiment
REGION:此区域应与实验输出存储桶区域相同。例如:
us-central1。PARAM_OVERRIDE:替换预构建训练程序参数的 .yaml 文件。 神经架构搜索提供了一些可供您使用的默认配置:
PROJECT_ID=PROJECT_ID
TRAINER_DOCKER_ID=TRAINER_DOCKER_ID
LATENCY_CALCULATOR_DOCKER_ID=LATENCY_CALCULATOR_DOCKER_ID
GCS_ROOT_DIR=OUTPUT_DIR
REGION=REGION
PARAM_OVERRIDE=tf_vision/configs/experiments/spinenet_search_gpu.yaml
TRAINING_DATA_PATH=gs://PATH_TO_TRAINING_DATA
VALIDATION_DATA_PATH=gs://PATH_TO_VALIDATION_DATA
您可能需要选择和/或修改符合训练要求的替换文件。请考虑以下事项:
- 您可以将
--accelerator_type设置为从 GPU 或 CPU 中选择。如需使用 CPU 仅运行几个周期以进行快速测试,您可以设置标志--accelerator_type=""并使用配置文件tf_vision/test_files/fast_nas_detection_spinenet_search_for_testing.yaml。 - 周期数
- 训练运行时间
- 超参数(如学习速率)
如需查看控制训练作业的所有参数的列表,请参阅 tf_vision/configs/。以下是关键参数:
task:
train_data:
global_batch_size: 80
validation_data:
global_batch_size: 16
init_checkpoint: null
trainer:
train_steps: 16634
steps_per_loop: 1386
optimizer_config:
learning_rate:
cosine:
initial_learning_rate: 0.16
decay_steps: 16634
type: 'cosine'
warmup:
type: 'linear'
linear:
warmup_learning_rate: 0.0067
warmup_steps: 1386
为神经架构搜索创建 Cloud Storage 存储桶以存储作业输出(即检查点):
gcloud storage buckets create $GCS_ROOT_DIR
构建训练程序容器和延迟时间计算器容器
以下命令将在 Google Cloud 中使用以下 URI 构建训练程序映像:gcr.io/PROJECT_ID/TRAINER_DOCKER_ID将在下一步中用于神经架构搜索作业。
python3 vertex_nas_cli.py build \
--project_id=PROJECT_ID \
--trainer_docker_id=TRAINER_DOCKER_ID \
--latency_calculator_docker_id=LATENCY_CALCULATOR_DOCKER_ID \
--trainer_docker_file=tf_vision/nas_multi_trial.Dockerfile \
--latency_calculator_docker_file=tf_vision/latency_computation_using_saved_model.Dockerfile
如需更改搜索空间和奖励,请在 Python 文件中对其进行更新,然后重新构建 Docker 映像。
在本地测试训练程序
由于在 Google Cloud 服务中启动作业需要几分钟时间,因此在本地测试训练程序 Docker 可能更方便,例如验证 TFRecord 格式。以 spinenet 搜索空间为例,您可以在本地运行搜索作业(模型将随机采样):
# Define the local job output dir.
JOB_DIR="/tmp/iod_${search_space}"
python3 vertex_nas_cli.py search_in_local \
--project_id=PROJECT_ID \
--trainer_docker_id=TRAINER_DOCKER_ID \
--prebuilt_search_space=spinenet \
--use_prebuilt_trainer=True \
--local_output_dir=${JOB_DIR} \
--search_docker_flags \
params_override="tf_vision/test_files/fast_nas_detection_spinenet_search_for_testing.yaml" \
training_data_path=TEST_COCO_TF_RECORD \
validation_data_path=TEST_COCO_TF_RECORD \
model=retinanet
training_data_path 和 validation_data_path 是 TFRecord 的路径。
在 Google Cloud上启动 stage-1 搜索,后跟 stage-2 训练作业
如需查看端到端示例,您应参阅 MnasNet 分类笔记本和 SpineNet 对象检测笔记本。
您可以设置
--max_parallel_nas_trial标志和--max_nas_trial标志进行自定义。神经架构搜索将并行启动max_parallel_nas_trial试验,并在max_nas_trial试验之后完成。如果设置了
--target_device_latency_ms标志,系统会使用由--target_device_type标志指定的加速器启动单独的latency calculator作业。神经架构搜索控制器会通过
--nas_params_str标志为每个实验的新架构候选项提供建议。每次试验都会根据
nas_params_str标志的值构建图并启动训练作业。每个试验还会将其值保存到 json 文件(位于os.path.join(nas_job_dir, str(trial_id), "nas_params_str.json"))。
受延迟时间限制的奖励
MnasNet 分类笔记本展示了一个基于云 CPU 设备的受延迟时间限制的搜索示例。
如需搜索受延迟时间限制的模型,训练程序可以以准确率和延迟时间函数的形式报告奖励。
在共享源代码中,奖励的计算方式如下:
def compute_reward(target_latency, accuracy, inference_latency, weight=0.07):
"""Compute reward from accuracy and latency."""
speed_ratio = target_latency / inference_latency
return accuracy * (speed_ratio**weight)
您可以使用 MnasNet 论文第 3 页上的其他 reward 计算变体。
target_device_type指定 Google Cloud中支持的目标设备类型,例如NVIDIA_TESLA_P100。use_prebuilt_latency_calculator使用预构建的延迟时间计算器tf_vision/latency_computation_using_saved_model.py。target_device_latency_ms指定目标设备延迟时间。
如需了解如何自定义延迟时间计算函数,请参阅 tf_vision/latency_computation_using_saved_model.py。
监控神经架构搜索作业进度
在 Google Cloud 控制台的作业页面上,图表显示 reward vs. trial number,而表显示每次试验的奖励。您可以找到奖励最高的试验。
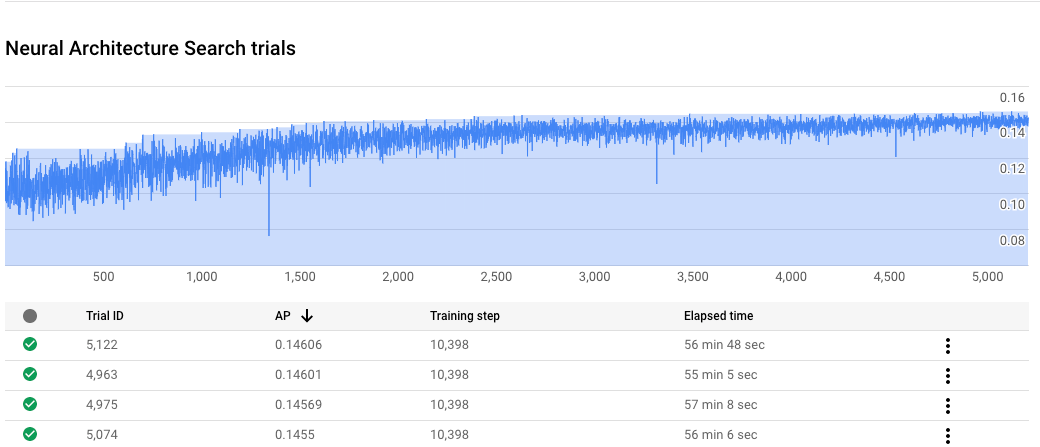
绘制 stage-2 的训练曲线
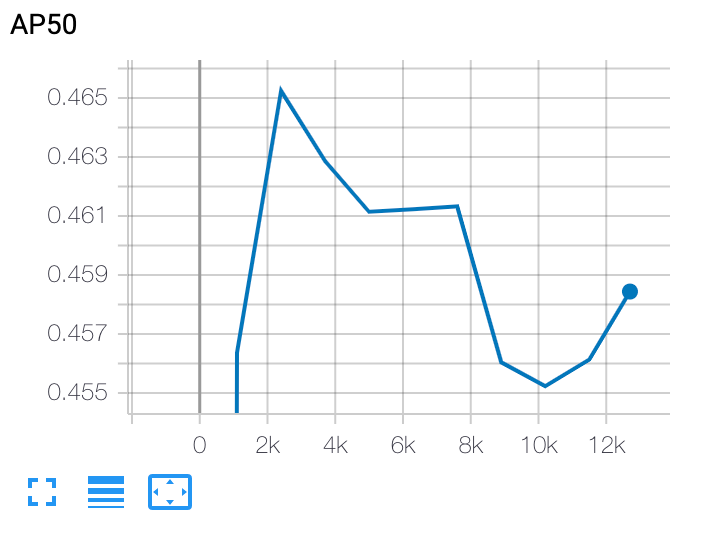
在 stage-2 训练完成后,您可以使用 Cloud Shell 或 Google CloudTensorBoard 将训练曲线指向作业目录来绘制该曲线:
部署选定的模型
如需创建 SavedModel,您可以将 export_saved_model.py 脚本与 params_override=${GCS_ROOT_DIR}/${TRIAL_ID}/params.yaml 搭配使用。