Com a Vertex AI Neural Architecture Search, é possível pesquisar arquiteturas neurais ideais em termos de precisão, latência, memória, uma combinação delas ou uma métrica personalizada.
Determinar se a pesquisa de arquitetura neural da Vertex AI é a melhor ferramenta para mim
- A Pesquisa de arquitetura neural da Vertex AI é uma ferramenta de otimização sofisticada usada para encontrar as melhores arquiteturas neurais em termos de precisão com ou sem restrições, como latência, memória ou métrica personalizada. O espaço de pesquisa de possíveis opções de arquitetura neural pode ser tão grande quanto 10^20. Ele é baseado em uma técnica, que gerou com sucesso vários modelos de visão computacional de última geração nos últimos anos, incluindo Nasnet, MNasnet, EfficientNet, NAS-FPN e SpineNet.
- A pesquisa de arquitetura neural não é uma solução em que você pode trazer seus dados e esperar um bom resultado sem experimentação. É uma ferramenta de experimentação.
- A pesquisa de arquitetura neural não se destina ao ajuste de hiperparâmetros, como no ajuste da taxa de aprendizado ou das configurações do otimizador. Ela só se destina a uma pesquisa de arquitetura. Não combine o ajuste de parâmetros com a pesquisa de arquitetura neural.
- A pesquisa de arquitetura não é recomendada com dados de treinamento limitados ou para conjuntos de dados altamente desequilibrados em que algumas classes são muito raras. Se você já estiver usando aumentos pesados no treinamento de referência por causa da falta de dados, a pesquisa de arquitetura neural não é recomendada.
- Primeiro, teste outros métodos e técnicas tradicionais e convencionais de machine learning, como o ajuste de hiperparâmetro. Use a pesquisa de arquitetura neural somente se não vir mais ganho com esses métodos tradicionais.
- É necessário ter uma equipe interna para ajuste de modelos, que tem algumas ideias básicas sobre parâmetros de arquitetura para modificar e testar. Esses parâmetros de arquitetura podem incluir o tamanho do kernel, o número de canais ou conexões entre muitas outras possibilidades. Se você tem um espaço de pesquisa em mente para explorar, a pesquisa de arquitetura neural é altamente valiosa e pode reduzir pelo menos aproximadamente seis meses de tempo de engenharia para explorar um grande espaço de pesquisa: até 10^20 opções de arquitetura.
- A pesquisa de arquitetura neural destina-se a clientes corporativos que podem gastar milhares de dólares em um experimento.
- A pesquisa de arquitetura neural não se limita a casos de uso somente de visão. No momento, são fornecidos apenas espaços de pesquisa pré-criados e baseados em visão, mas os clientes também podem trazer seus próprios espaços de pesquisa e treinadores não visuais.
- A pesquisa de arquitetura neural não usa uma abordagem de supernet (NAS oneshot-NAS ou NAS baseada em compartilhamento de peso), em que você apenas traz seus próprios dados e os usa como um solução. Não é trivial (meses de esforço) personalizar uma supernet. Ao contrário de uma supernet, a pesquisa de arquitetura neural é altamente personalizável para definir espaços de pesquisa personalizados e recompensas. A personalização pode ser feita em aproximadamente um ou dois dias.
- A pesquisa de arquitetura neural está disponível em oito regiões do mundo. Verifique a disponibilidade na sua região.
Leia também a seção a seguir sobre custos esperados, ganhos de resultados e requisitos de cota de GPU antes de usar a pesquisa de arquitetura neural.
Custo esperado, ganhos de resultados e requisitos de cota de GPU
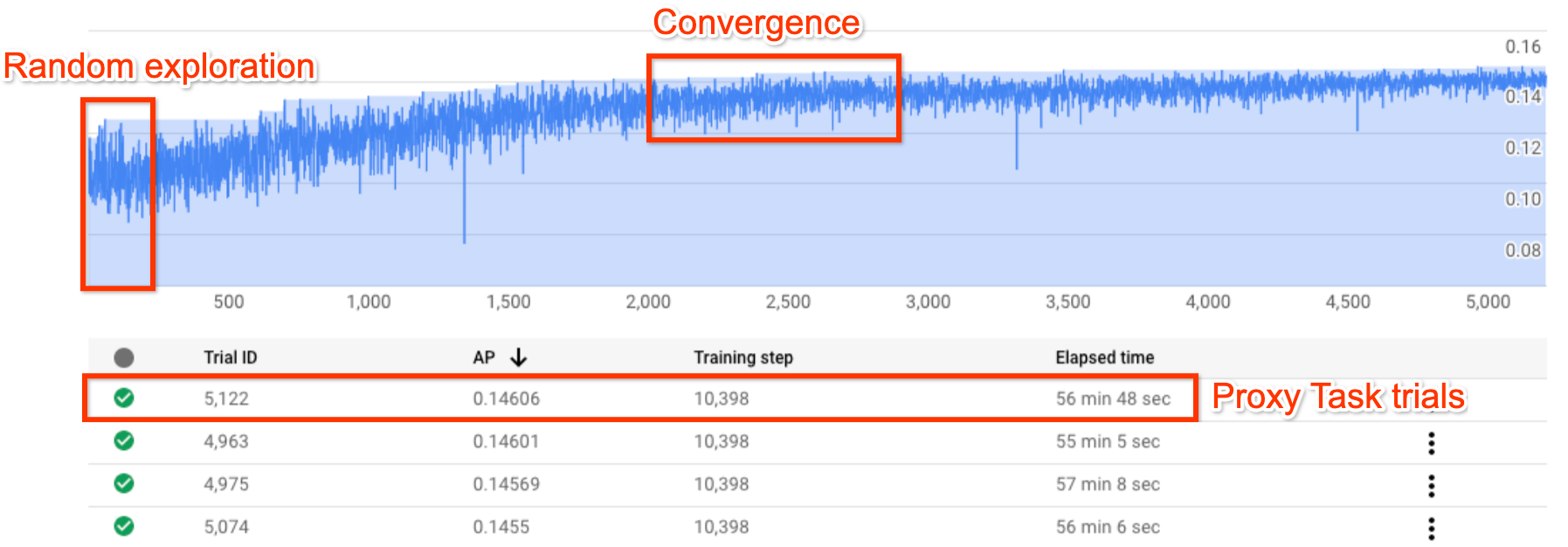
A figura acima mostra uma típica curva de pesquisa de arquitetura neural.
O Y-axis mostra as recompensas da avaliação, e a X-axis mostra o número de avaliações iniciadas.
À medida que o número de testes aumenta, o controlador começa a encontrar modelos melhores. Portanto, a recompensa começa a aumentar e, posteriormente, a variação da recompensa e o crescimento da recompensa começam a diminuir e mostram a convergência. No ponto de convergência, o número de testes pode variar com base no tamanho do espaço de pesquisa, mas está na ordem de aproximadamente 2.000 testes.
Cada teste é projetado para ser uma versão menor do treinamento completo, chamada proxy-task, que é executada por aproximadamente uma ou duas horas em duas GPUs Nvidia V100. O cliente pode interromper a pesquisa manualmente a qualquer momento e encontrar modelos de prêmio mais altos em comparação com a linha de base antes do ponto de convergência.
Talvez seja melhor aguardar até que ocorra o ponto de convergência para escolher os melhores resultados.
Após a pesquisa, a próxima etapa é escolher os 10 principais testes (modelos) e realizar um treinamento completo sobre eles.
(Opcional) Teste o espaço de pesquisa e o treinador MNasNet pré-criados
Neste modo, observe a curva de pesquisa ou alguns testes, aproximadamente 25, e faça um test drive com um espaço de pesquisa e treinador MNasNet pré-criados.

Na figura, a melhor recompensa da fase 1 começa a subir de aproximadamente 0,30 para 1 e 0,37 para 17. Sua execução exata pode parecer um pouco diferente devido à aleatoriedade da amostragem, mas você verá um pequeno aumento na melhor recompensa. Isso ainda é uma simulação e não representa uma prova de conceito ou uma validação de comparativo de mercado pública.
O custo dessa execução é detalhado da seguinte forma:
- Etapa 1:
- Número de tentativas: 25
- Número de GPUs por teste: 2
- Tipo de GPU: TESLA_T4
- Número de CPUs por teste: 1
- Tipo de CPU: n1-highmem-16
- Tempo médio de treinamento de teste único: três horas
- Número de testes paralelos: 6
- Cota de GPU usada: (num-gpus-per-trial * num-parallel-trials) = 12 GPUs. Use a região us-central1 para a avaliação gratuita e hospede os dados de treinamento na mesma região. Não é necessário cota adicional.
- Tempo de execução: (testes totais * tempo de treinamento por teste)/(testes paralelos) = 12 horas
- Horas de GPU: (total de tentativas * tempo de treinamento por teste * num-gpus-por teste) = 150 horas de GPU T4
- Horas de CPU: (total de avaliações * training-time-per-trial * num-cpus-per-trial) = 75 n1-highmem-16 hours
- Custo: aproximadamente US$ 185. É possível interromper o job antes para reduzir o custo. Consulte a página de preços para calcular o preço exato.
Como esta é uma execução de brinquedo, não é necessário executar um treinamento completo do estágio 2 para modelos do estágio 1. Para saber mais sobre a execução do estágio 2, consulte o tutorial 3.
O notebook do MnasNet (em inglês) é usado para essa execução.
Opcional: execução do comprovante de conceito (POC, na sigla em inglês) do espaço de pesquisa e treinador MNasNet pré-criados
Caso você esteja interessado em quase replicar um resultado de MNasnet publicado, use esse modo. De acordo com o documento, o MnasNet alcança uma precisão superior de 75,2% com latência de 78 ms em um smartphone Pixel, o que é 1,8 vez mais rápido que o MobileNetV2 com uma precisão de 0,5% e 2,3 vezes mais rápido do que o NASNet com precisão 1,2% maior. No entanto, este exemplo usa GPUs em vez de TPUs para treinamento e usa cloud-CPU (n1-highmem-8) para avaliar a latência. Com este exemplo, a precisão do primeiro nível 2 esperada no MNasNet é de 75,2% com latência de 50 ms na CPU na nuvem (n1-highmem-8).
O custo dessa execução é detalhado da seguinte forma:
Pesquisa no Estágio 1:
- número de tentativas: 2000
- Número de GPUs por teste: 2
- Tipo de GPU: TESLA_T4
- Tempo médio de treinamento de teste único: três horas
- Número de testes paralelos: 10
- Cota de GPU usada: (num-gpus-per-trial * num-parallel-trials) = 20 GPUs T4. Since this number is above the default quota, create a quota request from your project UI. Para mais informações, consulte setting_up_path.
- Tempo de execução: (testes totais * tempo de treinamento por teste)/(tentativas paralelas)/24 = 25 dias. Observação: o job é encerrado após 14 dias. Após esse período, é possível retomar a tarefa de pesquisa facilmente com um comando por mais 14 dias. Se você tiver uma cota de GPU maior, o ambiente de execução diminuirá proporcionalmente.
- Horas de GPU: (total de tentativas * tempo de treinamento por teste * num-gpus-por teste) = 12.000 horas de GPU T4.
- Custo: US$ 15,000
Treinamento completo do Estágio 2 com os 10 principais modelos:
- número de tentativas: 10
- Número de GPUs por teste: 4
- Tipo de GPU: TESLA_T4
- Tempo médio de treinamento de uma única avaliação: aproximadamente 9 dias
- Número de testes paralelos: 10
- Cota de GPU usada: (num-gpus-per-trial * num-parallel-trials) = 40 GPUs T4. Because this number is above the default quota, create a quota request from your project UI. Para mais informações, consulte setting_up_path. Também é possível executar isso com 20 GPUs T4 executando o job duas vezes com cinco modelos por vez, em vez de todos os 10 em paralelo.
- Tempo de execução: (total de tentativas * treinamento-tempo-por-teste)/(num-parallel-trials)/24 = aproximadamente 9 dias
- Horas de GPU: (testes totais * tempo de treinamento por teste * num-gpus-por teste) = horas de GPU T4 de 8.960.
- Custo: US$ 8.000
Custo total: aproximadamente US$ 23.000. Consulte a página de preços para calcular o preço exato. Observação: este exemplo não é um job de treinamento normal médio. O treinamento completo é executado por aproximadamente nove dias em quatro GPUs TESLA_T4.
O notebook do MnasNet (em inglês) é usado para essa execução.
Como usar seu espaço de pesquisa e instrutores
Fornecemos um custo aproximado para um usuário personalizado médio. Suas necessidades podem variar dependendo da tarefa de treinamento e das GPUs e CPUs usadas. Você precisa de pelo menos 20 cotas de GPUs para uma execução completa, conforme documentado aqui. Observação: o ganho de desempenho depende totalmente de sua tarefa. Só podemos oferecer exemplos como o MNasnet como referência de ganho de desempenho.
O custo dessa execução personalizada hipotética é detalhado da seguinte maneira:
Pesquisa no Estágio 1:
- número de tentativas: 2.000
- Número de GPUs por teste: 2
- Tipo de GPU: TESLA_T4
- Tempo médio de treinamento de teste único: 1h30
- Número de testes paralelos: 10
- Cota de GPU usada: (num-gpus-per-trial * num-parallel-trials) = 20 GPUs T4. Because this number is above the default quota, you need to create a quota request from your project UI. Para mais informações, consulte Solicitar mais cota de dispositivo para o projeto.
- Tempo de execução: (testes totais * tempo de treinamento por teste)/(testes paralelos)/24 = 12,5 dias
- Horas de GPU: (total de tentativas * tempo de treinamento por teste * num-gpus-por teste) = 6.000 horas de GPU T4.
- Custo: aproximadamente US$ 7.400
Treinamento completo do Estágio 2 com os 10 principais modelos:
- número de tentativas: 10
- Número de GPUs por teste: 2
- Tipo de GPU: TESLA_T4
- Tempo médio de treinamento de teste único: aproximadamente 4 dias
- Número de testes paralelos: 10
- Cota de GPU usada: (num-gpus-per-trial * num-parallel-trials) = 20 GPUs T4. **Como esse número está acima da cota padrão, você precisa criar uma solicitação de cota na interface do projeto. Para mais informações, consulte Solicitar uma cota adicional do dispositivo para o projeto. Consulte a mesma documentação para saber quais são as necessidades de cota personalizadas.
- Tempo de execução: (total de tentativas * tempo de treinamento por teste)/(número de tentativas paralelas)/24 = aproximadamente 4 dias
- Horas de GPU: (testes totais * tempo de treinamento por teste * num-gpus-por teste) = horas de GPU T4 de 1.920.
- Custo: aproximadamente US$ 2.400
Para mais informações sobre o custo de design de tarefas de proxy, consulte Design de tarefas de proxy. O custo é semelhante ao treinamento de 12 modelos. (o estágio 2 na figura usa 10 modelos):
- Cota de GPU usada: igual à execução do estágio 2 na figura.
- Custo: (12/10) * estágio-2-cost-for-10-models = aproximadamente US$ 2.880
Custo total: aproximadamente US$ 12.680. Consulte a página de preços para calcular o preço exato.
Esses custos são referentes à pesquisa até o ponto de convergência e até o ganho máximo de desempenho. No entanto, não espere até que a pesquisa converja. Você verá um ganho de desempenho menor com um custo de pesquisa menor se executar o treinamento completo do estágio 2 com o melhor modelo até o momento, se a curva de pesquisa tiver começado a crescer. Por exemplo, no gráfico de pesquisa mostrado anteriormente, não espere até que os 2.000 testes de convergência sejam atingidos. Você pode ter encontrado modelos melhores em 700 ou 1.200 testes e executar o treinamento completo do estágio 2 para eles. Você sempre pode interromper a pesquisa antes para reduzir o custo. Também é possível fazer o treinamento completo do estágio 2 em paralelo durante a execução da pesquisa, mas verifique se você tem cota de GPU para aceitar um job paralelo extra.
Resumo do desempenho e do custo
A tabela a seguir resume alguns pontos de dados com diferentes casos de uso e o desempenho e custo associados.
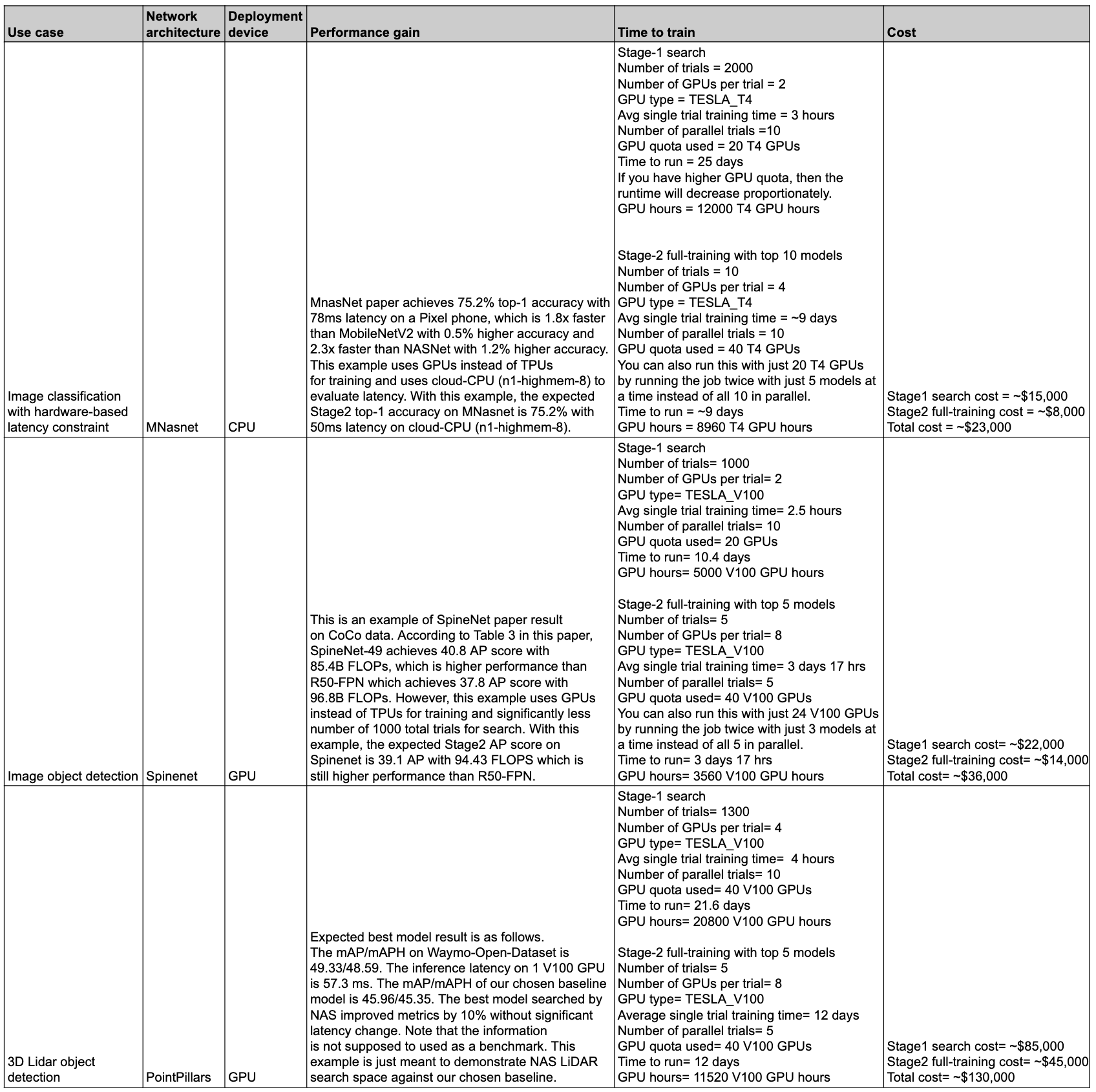
Casos de uso e recursos
Os recursos de pesquisa de arquitetura neural são flexíveis e fáceis de usar. Um usuário iniciante pode usar espaços de pesquisa pré-criados, treinadores pré-criados e notebooks sem nenhuma configuração adicional para começar a explorar o Vertex AI Neural Architecture Search no conjunto de dados. Ao mesmo tempo, um usuário especialista pode usar a pesquisa de arquitetura neural com o treinador personalizado, o espaço de pesquisa personalizado e o dispositivo de inferência personalizado e até mesmo estender a pesquisa de arquitetura para casos de uso que não são visão.
A pesquisa de arquitetura neural oferece treinadores e espaços de pesquisa pré-criados para execução em GPUs para os seguintes casos de uso:
- Treinadores do TensorFlow com resultados baseados em conjuntos de dados públicos publicados em um notebook
- Detecção de objetos de imagem com espaços de pesquisa de ponta a ponta (SpineNet)
- Classificação com espaços de pesquisa de backbone pré-criados (MnasNet)
- Detecção de objetos na nuvem LiDAR 3D Point com espaços de pesquisa pré-criados de ponta a ponta
- Pesquisa com latência e restrição de memória para dispositivos de segmentação
- Os treinadores PyTorch devem ser usados apenas como exemplo de tutorial
- Exemplo de espaço de pesquisa para segmentação de imagens médicas em 3D do PyTorch
- Classificação do MNasNet baseado em PyTorch
- Pesquisa com latência e restrição de memória para dispositivos de segmentação
- Mais espaços de pesquisa pré-criados de última geração do TensorFlow com código.
- Escalonamento de modelos
- Ampliação de dados
O conjunto completo de recursos que a Neural Architecture Search oferece pode ser usado facilmente para arquiteturas personalizadas e casos de uso:
- Uma linguagem de pesquisa de arquitetura neural para definir um espaço de pesquisa personalizado sobre possíveis arquiteturas neurais e integrar esse espaço à pesquisa com código de treinador personalizado.
- Espaços de pesquisa modernos e prontos para usar com código.
- Treinamento predefinido, pronto para usar, com código executado em GPU.
- um serviço gerenciado para pesquisa de arquitetura, incluindo
- ;
- Um controlador de pesquisa de arquitetura neural que analisa o espaço de pesquisa para encontrar a melhor arquitetura.
- Docker/bibliotecas pré-criadas com código para calcular latência/FLOPs/memória em hardware personalizado.
- Tutoriais para ensinar o uso do NAS.
- Um conjunto de ferramentas para projetar tarefas de proxy.
- Orientação e exemplo para treinamento eficiente do PyTorch com a Vertex AI.
- Compatibilidade de biblioteca para relatórios e análises de métricas personalizadas.
- IU do consoleGoogle Cloud para monitorar e gerenciar jobs.
- Notebooks fáceis de usar para iniciar a pesquisa.
- Compatibilidade com bibliotecas para gerenciamento de uso de recursos de GPU/CPU em granularidade por projeto ou por job.
- Nas-client baseado em Python para criar dockers, iniciar jobs de NAS e retomar um job de pesquisa anterior.
- Google Cloud Suporte ao cliente com base na interface do console.
Contexto
A pesquisa de arquitetura neural é uma técnica de automatização do design de redes neurais. Ele gerou vários modelos de visão computacional de última geração nos últimos anos, incluindo:
Esses modelos resultantes estão liderando as três classes principais de problemas de visão computacional: classificação de imagens, detecção de objetos e segmentação.
Com a pesquisa de arquitetura neural, os engenheiros podem otimizar modelos de acurácia, latência e memória no mesmo teste, reduzindo o tempo necessário. implantar modelos. A Neural Architecture Search explora vários tipos diferentes de modelos: o controlador propõe modelos de ML, treina e avalia modelos e itera mais de mil vezes para encontrar as melhores soluções com latência e/ou ou restrição de memória em dispositivos de segmentação. A figura a seguir mostra os principais componentes do framework de pesquisa de arquitetura:
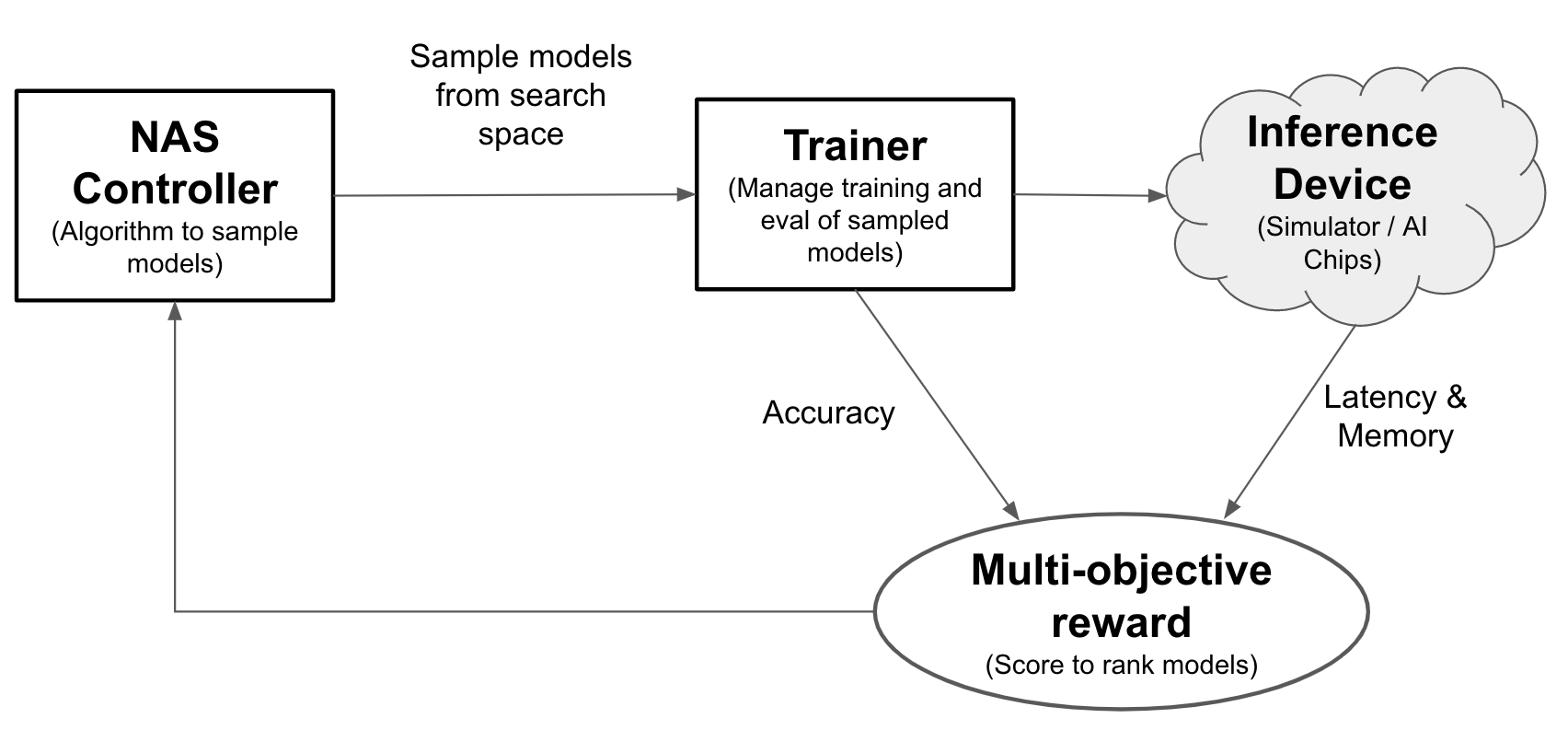
- Modelo: uma arquitetura neural com operações e conexões.
- Espaço de pesquisa: o espaço de modelos possíveis (operações e conexões) que podem ser projetados e otimizados.
- Trainer docker: código do treinador personalizável do usuário para treinar e avaliar um modelo e a precisão do modelo.
- Dispositivo de inferência: um dispositivo de hardware, como CPU/GPU, em que a latência do modelo e o uso da memória são calculados.
- Recompensa: uma combinação de métricas do modelo, como precisão, latência e memória usada para classificar os modelos como melhores ou piores.
- Controlador da pesquisa de arquitetura neural: o algoritmo de orquestração que (a) analisa os modelos do espaço de pesquisa, (b) recebe os prêmios do modelo e (c) fornece o próximo conjunto de modelos -sugestões a serem avaliadas para encontrar os modelos ideais.
Tarefas de configuração de usuários
O Neural Architecture Search oferece um treinador pré-criado integrado a espaços de pesquisa pré-criados que podem ser facilmente usados com notebooks fornecidos, sem nenhuma configuração adicional.
No entanto, a maioria dos usuários precisa usar o treinador personalizado, os espaços de pesquisa personalizados, as métricas personalizadas (memória, latência e tempo de treinamento, por exemplo) e a recompensa personalizada (combinação de itens como precisão e latência). Para isso, você precisa:
- Defina um espaço de pesquisa personalizado usando o idioma da pesquisa de arquitetura neural fornecida.
- Integre a definição de espaço de pesquisa ao código do treinador.
- Adicionar relatórios de métricas personalizadas ao código do treinador.
- Adicione um prêmio personalizado ao código do treinador.
- Crie um contêiner de treinamento e use-o para iniciar jobs de pesquisa de arquitetura neural.
Veja uma ilustração no diagrama abaixo:
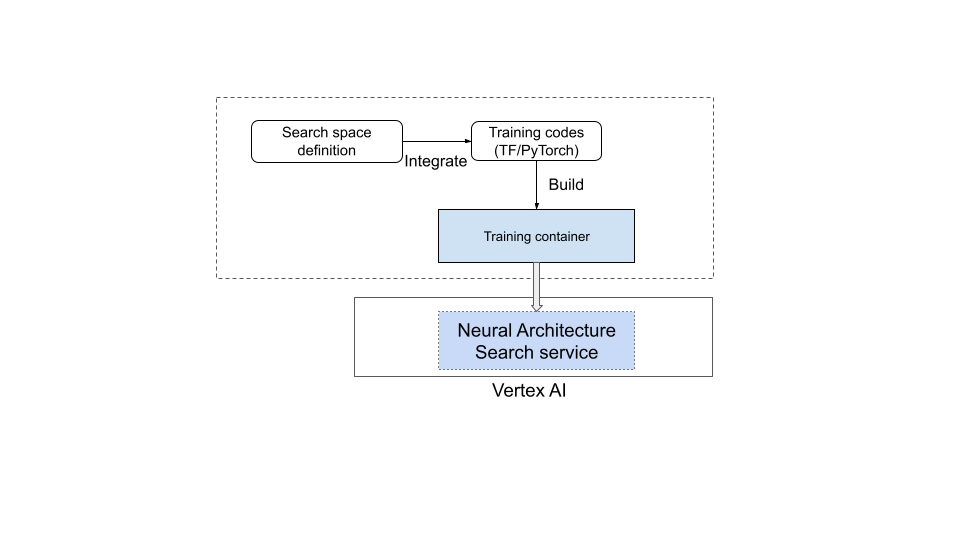
Serviço de pesquisa de arquitetura neural em operação
Depois de configurar o contêiner de treinamento para usar, o serviço de pesquisa de arquitetura neural inicia vários contêineres de treinamento em paralelo em vários dispositivos de GPU. É possível controlar quantos testes serão usados em paralelo para o treinamento e quantos testes serão iniciados. Cada contêiner de treinamento recebe uma arquitetura sugerida do espaço de pesquisa. O contêiner de treinamento cria o modelo sugerido, treina/avalia e informa os prêmios para o serviço de pesquisa de arquitetura neural. À medida que esse processo avança, o serviço de pesquisa de arquitetura neural usa o feedback de recompensa para encontrar arquiteturas de modelo melhores. Após a pesquisa, você terá acesso às métricas informadas para realizar uma análise mais detalhada.

Visão geral da jornada do usuário para a pesquisa de arquitetura neural
As etapas gerais para realizar um experimento de pesquisa de arquitetura neural são as seguintes:
Configurações e definições:
- Identifique o conjunto de dados rotulado e especifique o tipo de tarefa (por exemplo, detecção ou segmentação).
- Personalize o código do treinador:
- Use um espaço de pesquisa pré-criado ou defina um espaço de pesquisa personalizado usando a linguagem de pesquisa de arquitetura neural.
- Integre a definição de espaço de pesquisa ao código do treinador.
- Adicionar relatórios de métricas personalizadas ao código do treinador.
- Adicione um prêmio personalizado ao código do treinador.
- Crie um contêiner de treinador.
- Configure parâmetros de teste de pesquisa para treinamento parcial (tarefa de proxy). O ideal é que o treinamento de pesquisa termine rapidamente (por exemplo, de 30 a 60 minutos) para treinar parcialmente os modelos:
- Períodos mínimos necessários para que amostras de modelos coletem (as épocas mínimas não precisam garantir a convergência de modelos).
- Hiperparâmetros (por exemplo, taxa de aprendizado).
Execute a pesquisa localmente para garantir que o contêiner integrado do espaço de pesquisa seja executado corretamente.
Inicie o job de pesquisa Google Cloud (estágio 1) com cinco testes de teste e verifique se eles atendem às metas de tempo de execução e precisão.
Inicie o job de Google Cloud pesquisa (estágio 1) com mais de mil testes.
Como parte da pesquisa, defina também um intervalo regular para treinar os principais modelos de N (estágio 2):
- Os hiperparâmetros e o algoritmo para pesquisa de hiperparâmetros. O cenário 2 normalmente usa a configuração semelhante à do estágio 1, mas com configurações mais altas para determinados parâmetros, como etapas/períodos de treinamento e número de canais.
- Critérios de parada (o número de períodos).
Analisar as métricas informadas e/ou visualizar arquiteturas para conseguir insights
Um experimento de pesquisa de arquitetura pode ser seguido por um experimento de pesquisa de escalonamento, seguido por um experimento de pesquisa de aumento.
Ordem de leitura da documentação
- (Obrigatório) Configurar o ambiente
- (Obrigatório)Tutoriais
- (Obrigatório apenas para clientes PyTorch)Treinamento eficiente do PyTorch com dados de nuvem
- (Obrigatório)Práticas recomendadas e fluxo de trabalho sugerido
- (Obrigatório)Design de tarefas de proxy
- (Obrigatório apenas para treinadores pré-criados)Como usar espaços de pesquisa pré-criados e um treinador pré-criado
Referências
- Como usar o machine learning para explorar a arquitetura de rede neural (em inglês)
- MnasNet: Toueing Automing the Design of Mobile Machine Models Models (em inglês)
- Eficiente: como melhorar a precisão e a eficiência com o AutoML e o escalonamento de modelos
- NAS-FPN: arquitetura de pirâmide de atributos escalonável de aprendizagem para detecção de objetos
- SpineNet: backbone perfurado em escala de aprendizado para reconhecimento e localização
- RandAugment (em inglês)