Dengan Vertex AI Neural Architecture Search, Anda dapat menelusuri arsitektur neural yang optimal dalam hal akurasi, latensi, memori, kombinasi dari semuanya, atau metrik kustom.
Menentukan apakah Vertex AI Neural Architecture Search adalah alat terbaik bagi saya
- Vertex AI Neural Architecture Search adalah alat pengoptimalan kelas atas yang digunakan untuk menemukan arsitektur neural terbaik dalam hal akurasi dengan atau tanpa batasan seperti latensi, memori, atau metrik kustom. Ruang penelusuran dari kemungkinan pilihan arsitektur neural dapat sebesar 10^20. Pengembangan ini didasarkan pada sebuah teknik yang telah berhasil menghasilkan beberapa model computer vision yang canggih dalam beberapa tahun terakhir, termasuk Nasnet dan MNasnet, EffecientNet, NAS-FPN, dan SpineNet.
- Penelusuran Arsitektur Neural bukan solusi yang memungkinkan Anda menghadirkan data dan mengharapkan hasil yang baik tanpa eksperimen. Alat ini adalah alat eksperimen.
- Penelusuran Arsitektur Neural tidak digunakan untuk penyesuaian hyperparameter, misalnya untuk menyesuaikan setelan kecepatan pembelajaran atau pengoptimal. Data ini hanya dimaksudkan untuk penelusuran arsitektur. Anda tidak boleh menggabungkan penyesuaian hyper-parameter dengan Penelusuran Arsitektur Neural.
- Penelusuran Arsitektur Neural tidak direkomendasikan dengan data pelatihan terbatas atau untuk set data yang sangat tidak seimbang di mana beberapa kelasnya sangat langka. Jika Anda sudah menggunakan sangat banyak augmentasi untuk pelatihan dasar pengukuran karena kurangnya data, Penelusuran Arsitektur Neural tidak direkomendasikan.
- Anda harus terlebih dahulu mencoba metode dan teknik machine learning tradisional dan konvensional lainnya seperti penyesuaian hyperparameter. Sebaiknya gunakan Penelusuran Arsitektur Neural hanya jika Anda tidak melihat adanya manfaat menggunakan metode tradisional tersebut.
- Anda harus memiliki tim internal untuk penyesuaian model, yang memiliki beberapa ide dasar tentang parameter arsitektur yang dapat dimodifikasi dan dicoba. Parameter arsitektur ini dapat mencakup ukuran kernel, jumlah saluran, atau koneksi di antara berbagai kemungkinan lainnya. Jika Anda mempertimbangkan ruang penelusuran untuk dijelajahi, Penelusuran Arsitektur Neural sangat berharga dan dapat mengurangi setidaknya sekitar enam bulan waktu engineer dalam menjelajahi ruang penelusuran yang besar: hingga 10^20 pilihan arsitektur.
- Neural Architecture Search ditujukan bagi pelanggan perusahaan yang dapat menghabiskan beberapa ribu dolar untuk eksperimen.
- Penelusuran Arsitektur Neural tidak terbatas pada kasus penggunaan khusus penglihatan. Saat ini, hanya ruang penelusuran bawaan berbasis vision dan pelatih bawaan yang disediakan, tetapi pelanggan juga dapat membawa ruang penelusuran dan pelatih non-visi mereka sendiri.
- Penelusuran Arsitektur Neural tidak menggunakan pendekatan supernet (oneshot-NAS atau NAS berbasis pembagian berat) yang memungkinkan Anda membawa data sendiri, dan menggunakannya sebagai solusi. Menyesuaikan supernet tidaklah mudah (berbulan-bulan upaya). Tidak seperti supernet, Neural Architecture Search sangat mudah disesuaikan untuk menentukan ruang penelusuran kustom dan reward. Penyesuaian dapat dilakukan dalam waktu sekitar satu hingga dua hari.
- Penelusuran Arsitektur Neural didukung di 8 wilayah di seluruh dunia. Periksa ketersediaan di wilayah Anda.
Anda juga harus membaca bagian berikut tentang perkiraan biaya, peningkatan hasil, dan persyaratan kuota GPU sebelum menggunakan Penelusuran Arsitektur Neural.
Biaya yang diharapkan, peningkatan hasil, dan persyaratan kuota GPU
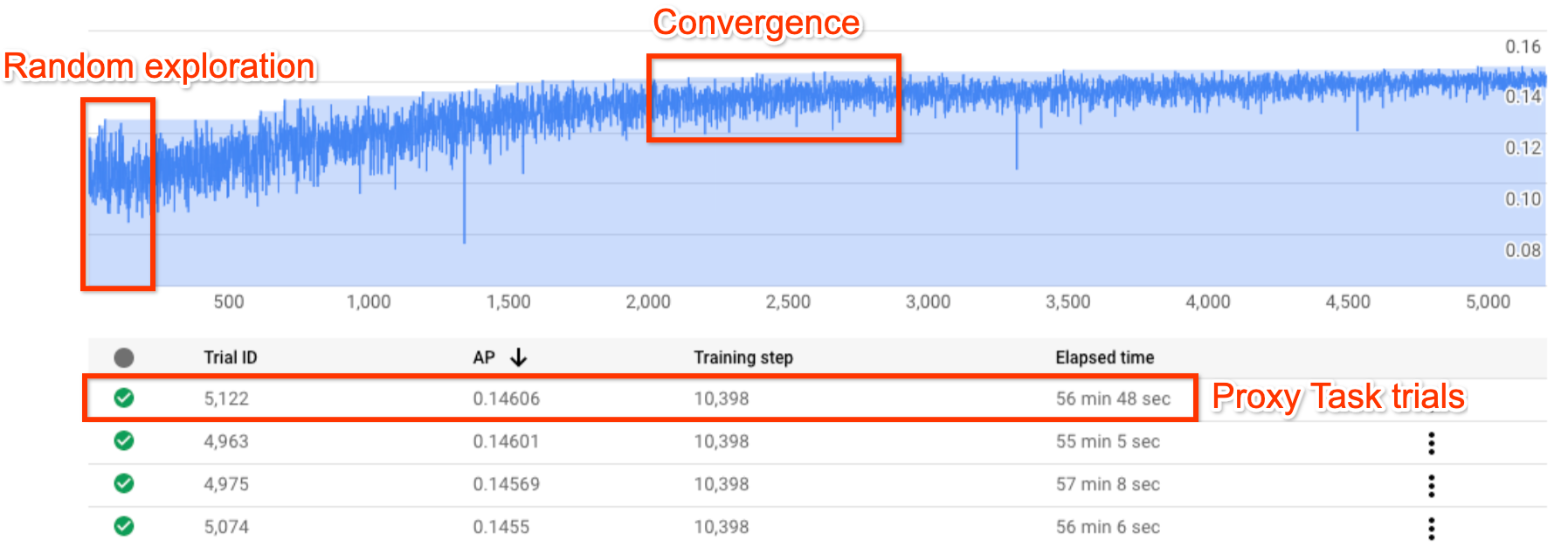
Gambar ini menunjukkan kurva Penelusuran Arsitektur Neural standar.
Y-axis menunjukkan reward uji coba, dan
X-axis menunjukkan jumlah uji coba yang diluncurkan.
Saat jumlah uji coba meningkat, pengontrol mulai menemukan model
yang lebih baik. Oleh karena itu, reward mulai meningkat, lalu varians reward dan pertumbuhan reward mulai menurun dan menunjukkan konvergensi. Pada titik konvergensi, jumlah uji coba dapat bervariasi berdasarkan ukuran ruang penelusuran, tetapi dalam urutan sekitar 2000 uji coba.
Setiap uji coba dirancang untuk menjadi versi pelatihan penuh yang lebih kecil yang disebut proxy-task, yang berjalan selama sekitar satu hingga dua jam pada dua GPU Nvidia V100. Pelanggan dapat menghentikan penelusuran secara manual kapan saja dan mungkin menemukan model reward yang lebih tinggi dibandingkan dengan dasar pengukuran mereka sebelum titik konvergensi terjadi.
Mungkin lebih baik menunggu sampai titik konvergensi terjadi untuk memilih hasil yang lebih baik.
Setelah pencarian, tahap selanjutnya adalah memilih 10 uji coba (model) teratas dan menjalankan pelatihan penuh pada uji coba tersebut.
(Opsional) Uji coba ruang penelusuran dan trainer MNasNet bawaan
Dalam mode ini, amati kurva penelusuran atau beberapa uji coba, sekitar 25 kali, dan lakukan uji coba dengan ruang penelusuran dan trainer MNasNet bawaan.
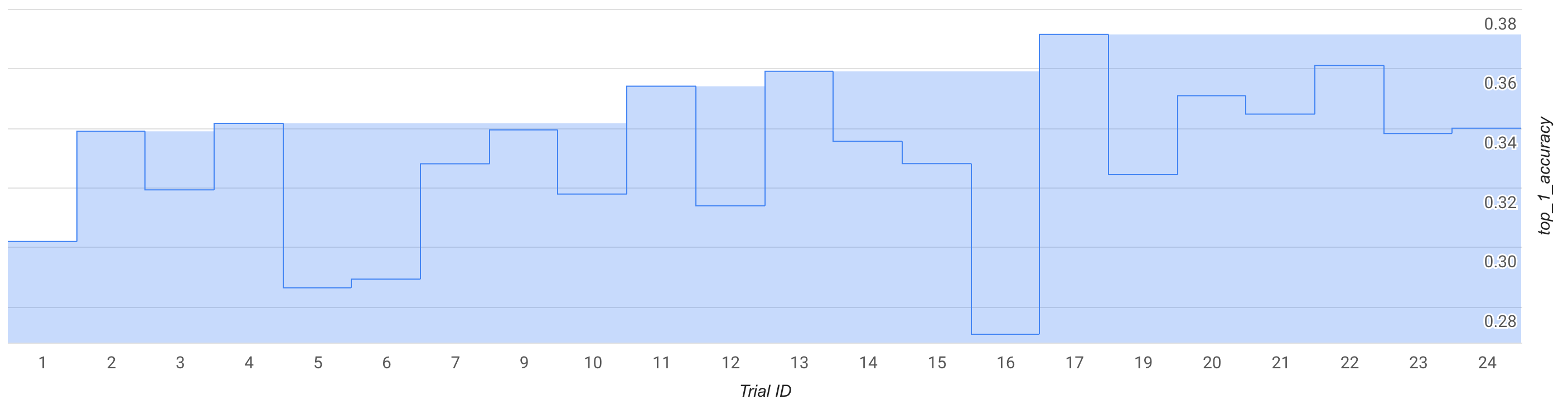
Pada gambar, reward tahap 1 terbaik mulai naik dari ~0,30 pada uji coba ke-1 menjadi ~0,37 pada uji coba ke-17. Mekanisme yang tepat mungkin terlihat sedikit berbeda karena pengambilan sampel keacakan, tetapi Anda akan melihat sedikit peningkatan dalam reward terbaik. Perhatikan bahwa tindakan ini masih berupa toy run dan tidak merepresentasikan bukti konsep atau validasi benchmark publik.
Biaya untuk operasi ini dijelaskan sebagai berikut:
- Tahap-1:
- Jumlah percobaan: 25
- Jumlah GPU per uji coba: 2
- Jenis GPU: TESLA_T4
- Jumlah CPU per uji coba: 1
- Jenis CPU: n1-highmem-16
- Rata-rata waktu pelatihan uji coba tunggal: 3 jam
- Jumlah uji coba paralel: 6
- Kuota GPU yang digunakan: (num-gpus-per-trial * num-Parallel-trials) = 12 GPU. Gunakan region us-central1 untuk uji coba dan data pelatihan host di region yang sama. Tidak perlu kuota tambahan.
- Waktu untuk dijalankan: (total-uji coba * waktu-pelatihan-per-uji coba)/(num-paralel-uji coba) = 12 jam
- Jam GPU: (total-uji coba * waktu pelatihan-per-uji coba * num-gpus-per-uji coba) = 150 T4 jam GPU
- Jam CPU: (total-percobaan * waktu pelatihan-per-uji coba * num-cpus-per-uji coba) = 75 n1-highmem-16 jam
- Biaya: Sekitar $185 Anda dapat menghentikan pekerjaan lebih awal untuk mengurangi biaya. Lihat halaman harga untuk menghitung harga pasti.
Karena ini adalah toy run, Anda tidak perlu menjalankan pelatihan tahap-2 penuh untuk model dari tahap-1. Untuk mempelajari lebih lanjut cara menjalankan tahap-2, lihat tutorial 3.
Notebook MnasNet digunakan untuk proses ini.
(Opsional) Menjalankan bukti konsep (POC) dari ruang penelusuran dan trainer MNasNet bawaan
Jika ingin mereplikasi hasil MNasnet yang dipublikasikan hampir sama, Anda dapat menggunakan mode ini. Menurut makalah tersebut, MnasNet mencapai akurasi top-1 75.2% dengan latensi 78 md pada ponsel Pixel, yang 1,8x lebih cepat daripada MobileNetV2 dengan akurasi 0,5% lebih tinggi dan 2,3x lebih cepat dari NASNet dengan akurasi 1,2% lebih tinggi. Namun, contoh ini menggunakan GPU, bukan TPU, untuk pelatihan dan menggunakan cloud-CPU (n1-highmem-8) untuk mengevaluasi latensi. Dengan contoh ini, akurasi top-1 Stage2 yang diharapkan di MNasNet adalah 75,2% dengan latensi 50 md di cloud-CPU (n1-highmem-8).
Biaya untuk operasi ini dijelaskan sebagai berikut:
Penelusuran tahap-1:
- Jumlah percobaan:2000
- Jumlah GPU per uji coba: 2
- Jenis GPU: TESLA_T4
- Rata-rata waktu pelatihan uji coba tunggal: 3 jam
- Jumlah uji coba paralel: 10
- Kuota GPU yang digunakan: (num-gpus-per-trial * num-Parallel-trials) = 20 T4 GPU. Karena jumlah ini di atas kuota default, buat permintaan kuota dari UI project Anda. Untuk informasi selengkapnya, lihat setting_up_path.
- Waktu untuk dijalankan: (total-uji coba * waktu-pelatihan-per-uji coba)/(num-paralel-uji coba)/24 = 25 hari. Catatan: Lowongan akan berakhir setelah 14 hari. Setelah itu, Anda dapat melanjutkan tugas penelusuran dengan mudah menggunakan satu perintah selama 14 hari berikutnya. Jika Anda memiliki kuota GPU yang lebih tinggi, runtime akan berkurang secara proporsional.
- Jam GPU: (total-uji coba * waktu pelatihan-per-uji coba * num-gpus-per-uji coba) = 12000 T4 jam GPU.
- Biaya: ~$15,000
Tahap-2 pelatihan penuh dengan 10 model teratas:
- Jumlah percobaan: 10
- Jumlah GPU per uji coba: 4
- Jenis GPU: TESLA_T4
- Rata-rata waktu pelatihan uji coba tunggal: ~9 hari
- Jumlah uji coba paralel: 10
- Kuota GPU yang digunakan: (num-gpus-per-trial * num-paralel-trials) = 40 T4 GPU. Karena jumlah ini di atas kuota default, buat permintaan kuota dari UI project Anda. Untuk informasi selengkapnya, lihat setting_up_path. Anda juga dapat menjalankan ini dengan 20 GPU T4 dengan menjalankan tugas dua kali dengan lima model sekaligus, bukan 10 model secara paralel.
- Waktu untuk dijalankan: (total-uji coba * waktu-pelatihan-per-uji coba)/(num-paralel-uji coba)/24 = ~9 hari
- Jam GPU: (total-uji coba * waktu pelatihan-per-uji coba * num-gpus-per-uji coba) = 8960 T4 jam GPU.
- Biaya: ~$8,000
Biaya total: Sekitar $23000. Lihat halaman harga untuk menghitung harga pasti. Catatan: Contoh ini bukan tugas pelatihan reguler pada umumnya. Pelatihan lengkap berlangsung selama sekitar sembilan hari pada empat GPU TESLA_T4.
Notebook MnasNet digunakan untuk proses ini.
Menggunakan ruang penelusuran dan trainer Anda
Kami memberikan perkiraan biaya untuk rata-rata pengguna kustom. Kebutuhan Anda dapat bervariasi, bergantung pada tugas pelatihan Anda, serta GPU dan CPU yang digunakan. Anda memerlukan setidaknya 20 kuota GPU untuk menjalankan operasi menyeluruh seperti yang didokumentasikan di sini. Catatan: Peningkatan performa sepenuhnya bergantung pada tugas Anda. Kami hanya dapat menyediakan contoh seperti MNasnet sebagai contoh referensi untuk peningkatan performa.
Biaya untuk hipotesis untuk operasi kustom ini dijelaskan sebagai berikut:
Penelusuran tahap-1:
- Jumlah percobaan: 2000
- Jumlah GPU per uji coba: 2
- Jenis GPU: TESLA_T4
- Rata-rata waktu pelatihan uji coba tunggal: 1,5 jam
- Jumlah uji coba paralel: 10
- Kuota GPU yang digunakan: (num-gpus-per-trial * num-Parallel-trials) = 20 T4 GPU. Karena jumlah ini di atas kuota default, Anda perlu membuat permintaan kuota dari UI project Anda. Untuk informasi lebih lanjut, lihat Meminta kuota perangkat tambahan untuk project.
- Waktu untuk dijalankan: (total-uji coba * waktu-pelatihan-per-uji coba)/(num-paralel-uji coba)/24 = 12,5 hari
- Jam GPU: (total-uji coba * waktu pelatihan-per-uji coba * num-gpus-per-uji coba) = 6000 T4 jam GPU.
- Biaya: sekitar $7400
Tahap-2 pelatihan penuh dengan 10 model teratas:
- Jumlah percobaan: 10
- Jumlah GPU per uji coba: 2
- Jenis GPU: TESLA_T4
- Rata-rata waktu pelatihan uji coba tunggal: sekitar 4 hari
- Jumlah uji coba paralel: 10
- Kuota GPU yang digunakan: (num-gpus-per-trial * num-Parallel-trials) = 20 T4 GPU. **Karena jumlah ini di atas kuota default, Anda perlu membuat permintaan kuota dari UI project Anda. Untuk mengetahui informasi selengkapnya, lihat Meminta kuota perangkat tambahan untuk project. Lihat dokumentasi yang sama untuk kebutuhan kuota kustom.
- Waktu untuk dijalankan: (total-uji coba * waktu-pelatihan-per-uji coba)/(num-paralel-uji coba)/24 = sekitar 4 hari
- Jam GPU: (total-uji coba * waktu pelatihan-per-uji coba * num-gpus-per-uji coba) = 1920 T4 jam GPU.
- Biaya: sekitar $2400
Untuk informasi selengkapnya tentang biaya desain tugas proxy, lihat Desain tugas proxyBiayanya mirip dengan melatih 12 model (tahap-2 pada gambar menggunakan 10 model):
- Kuota GPU yang digunakan: Sama seperti langkah tahap-2 dalam gambar.
- Biaya: (12/10) * tahap-2-biaya-untuk-10-model = ~$2880
Total biaya: sekitar $12680 Lihat halaman harga untuk menghitung harga pasti.
Biaya penelusuran tahap-1 ini ditujukan untuk penelusuran hingga titik konvergensi tercapai dan untuk peningkatan performa maksimum. Namun, jangan tunggu hingga penelusuran digabungkan. Anda akan dapat melihat sejumlah kecil peningkatan performa dengan biaya penelusuran yang lebih kecil dengan menjalankan pelatihan penuh tahap-2 menggunakan model terbaik jika kurva reward penelusuran sudah mulai berkembang. Misalnya, untuk plot penelusuran yang ditampilkan sebelumnya, jangan menunggu hingga 2000 uji coba untuk konvergensi tercapai. Anda mungkin telah menemukan model yang lebih baik dengan jumlah uji coba 700 atau 1200 dan dapat menjalankan pelatihan penuh tahap-2 untuk model tersebut. Anda selalu dapat menghentikan penelusuran lebih awal untuk mengurangi biaya. Anda juga dapat melakukan pelatihan penuh tahap-2 secara paralel saat penelusuran sedang berjalan, tetapi pastikan Anda memiliki kuota GPU untuk mendukung tugas paralel tambahan.
Ringkasan performa dan biaya
Tabel berikut merangkum beberapa titik data dengan kasus penggunaan yang berbeda serta performa dan biaya terkait.
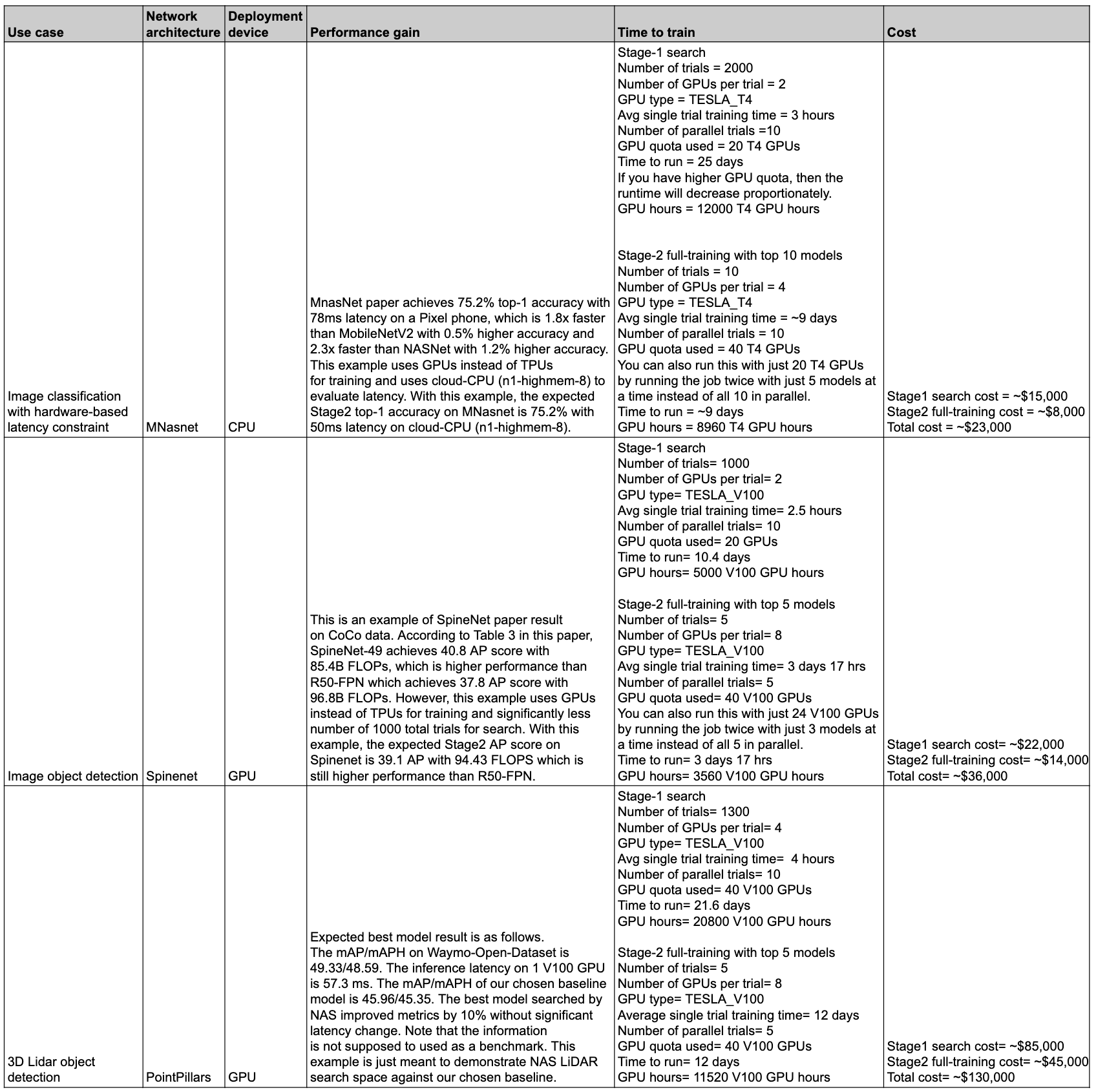
Kasus penggunaan dan fitur
Fitur Penelusuran Arsitektur Neural fleksibel dan mudah digunakan. Pengguna baru dapat menggunakan ruang penelusuran bawaan, pelatih bawaan, dan notebook tanpa penyiapan lebih lanjut untuk mulai menjelajahi Vertex AI Neural Architecture Search untuk set data mereka. Pada saat yang sama, pengguna ahli dapat menggunakan Penelusuran Arsitektur Neural dengan pelatih khusus, ruang penelusuran khusus, dan perangkat inferensi khusus, serta bahkan memperluas penelusuran arsitektur untuk kasus penggunaan non-visi.
Penelusuran Arsitektur Neural menawarkan pelatih dan ruang penelusuran bawaan untuk dijalankan di GPU pada kasus penggunaan berikut:
- Pelatih Tensorflow dengan hasil berbasis set data publik yang dipublikasikan di notebook
- Deteksi Objek Gambar dengan ruang penelusuran menyeluruh (SpineNet)
- Klasifikasi dengan ruang penelusuran backbone bawaan (MnasNet)
- Deteksi Objek Cloud Titik 3D LiDAR dengan ruang penelusuran menyeluruh yang telah dibangun sebelumnya
- Penelusuran dengan keterbatasan memori dan latensi untuk menargetkan perangkat
- Pelatih PyTorch hanya digunakan sebagai contoh tutorial
- Contoh ruang penelusuran segmentasi gambar medis PyTorch 3D
- Klasifikasi MNasNet berbasis PyTorch
- Penelusuran dengan keterbatasan memori dan latensi untuk menargetkan perangkat
- Ruang penelusuran canggih berbasis Tensorflow tambahan dengan kode
- Penskalaan Model
- Augmentasi data (data augmentation)
Kumpulan fitur lengkap yang ditawarkan Penelusuran Arsitektur Neural dapat digunakan dengan mudah untuk arsitektur yang disesuaikan dan juga kasus penggunaan:
- Bahasa Penelusuran Arsitektur Neural untuk menentukan ruang penelusuran kustom pada arsitektur neural yang memungkinkan dan mengintegrasikan ruang penelusuran ini dengan kode pelatih kustom.
- Ruang penelusuran canggih bawaan yang siap digunakan dengan kode.
- Trainer bawaan siap pakai, dengan kode, yang berjalan di GPU.
- Layanan Terkelola untuk penelusuran arsitektur, termasuk
- Pengontrol Penelusuran Arsitektur Neural yang mengambil sampel ruang penelusuran untuk menemukan arsitektur terbaik.
- Docker/library bawaan, dengan kode, untuk menghitung latensi/FLOP/Memori pada hardware kustom.
- Tutorial untuk mengajarkan penggunaan NAS.
- Serangkaian alat untuk mendesain tugas proxy.
- Panduan dan contoh untuk pelatihan PyTorch yang efisien dengan Vertex AI.
- Dukungan library untuk pelaporan dan analisis metrik kustom.
- UI konsolGoogle Cloud untuk memantau dan mengelola tugas.
- Notebook yang mudah digunakan untuk memulai pencarian.
- Dukungan library untuk pengelolaan penggunaan resource GPU/CPU aktif per project atau per tingkat perincian tugas.
- Klien Nas berbasis Python untuk membuat Docker, meluncurkan tugas NAS, dan melanjutkan tugas penelusuran sebelumnya.
- Dukungan pelanggan berbasis UI konsolGoogle Cloud .
Latar belakang
Penelusuran Arsitektur Neural adalah teknik untuk mengotomatiskan desain jaringan neural. Teknologi ini telah berhasil menghasilkan beberapa model computer vision yang canggih dalam beberapa tahun terakhir, termasuk:
Model yang dihasilkan ini menjadi yang terdepan dalam 3 kelas utama masalah penglihatan komputer: klasifikasi gambar, deteksi objek, dan segmentasi.
Dengan Neural Architecture Search, engineer dapat mengoptimalkan model untuk akurasi, latensi, dan memori dalam uji coba yang sama, sehingga mengurangi waktu yang dibutuhkan untuk men-deploy model. Penelusuran Arsitektur Neural mempelajari berbagai jenis model: pengontrol mengusulkan model ML, lalu melatih dan mengevaluasi model serta melakukan iterasi lebih dari 1.000 kali untuk menemukan solusi terbaik dengan latensi dan/atau keterbatasan memori pada perangkat yang ditargetkan. Gambar berikut menunjukkan komponen utama framework penelusuran arsitektur:
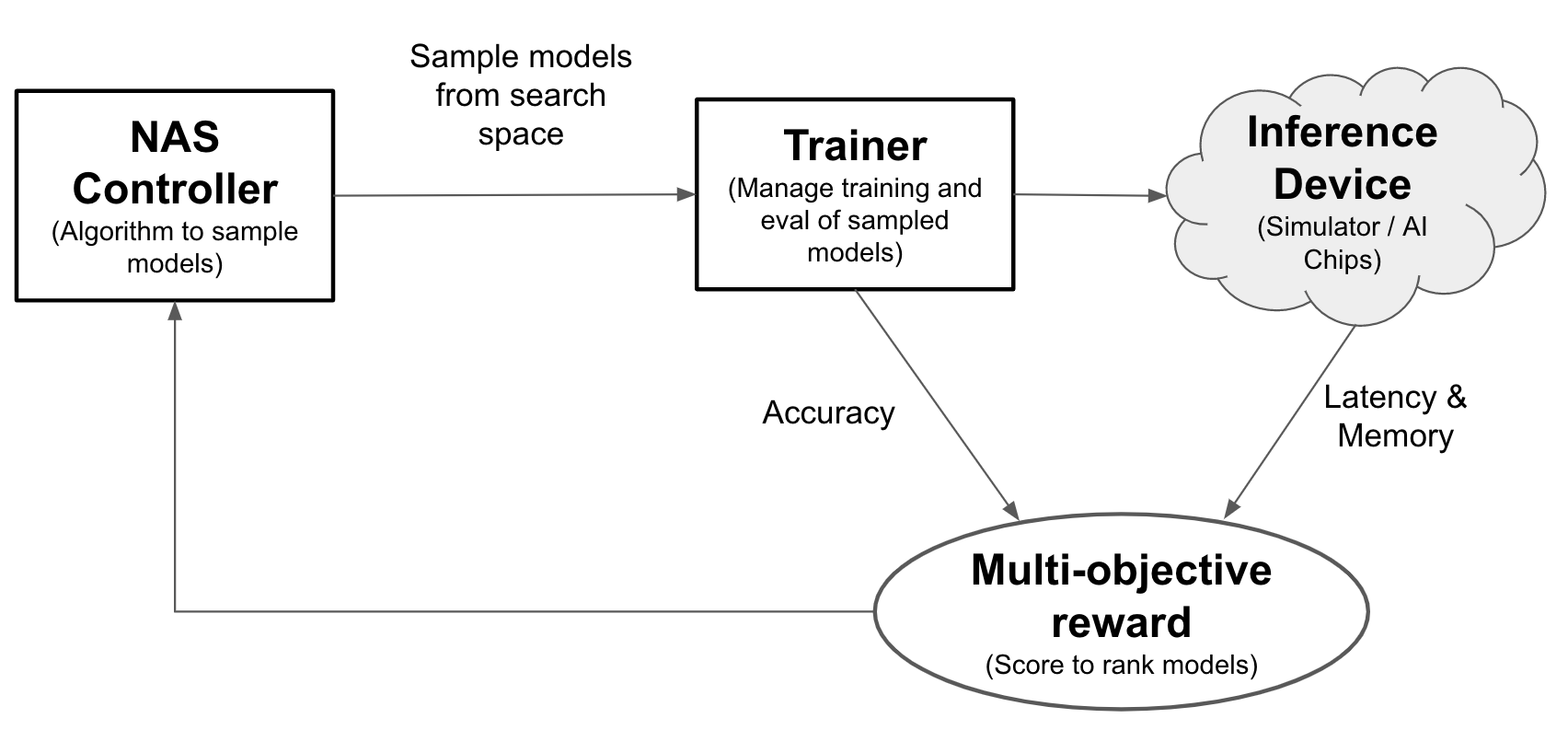
- Model: Arsitektur neural dengan operasi dan koneksi.
- Ruang penelusuran: Ruang berisi kemungkinan model (operasi dan koneksi) yang dapat dirancang dan dioptimalkan.
- Docker pelatih: Kode pelatih yang dapat disesuaikan untuk melatih dan mengevaluasi model serta menghitung akurasi model.
- Perangkat inferensi: Perangkat hardware seperti CPU/GPU yang menghitung latensi model dan penggunaan memori.
- Reward: Kombinasi metrik model seperti akurasi, latensi, dan memori yang digunakan untuk menentukan peringkat model sebagai lebih baik atau lebih buruk.
- Pengontrol Penelusuran Arsitektur Neural: Algoritma orkestrasi yang (a) mengambil sampel model dari ruang penelusuran, (b) menerima reward model, dan (c) menyediakan serangkaian saran model untuk dievaluasi untuk menemukan model yang paling optimal.
Tugas penyiapan pengguna
Penelusuran Arsitektur Neural menawarkan trainer bawaan yang terintegrasi dengan ruang penelusuran bawaan yang dapat mudah digunakan dengan notebook yang disediakan tanpa penyiapan lebih lanjut.
Namun, sebagian besar pengguna perlu menggunakan pelatih kustom, ruang penelusuran kustom, metrik kustom (misalnya, memori, latensi, dan waktu pelatihan), serta reward kustom (kombinasi dari beberapa hal seperti akurasi dan latensi). Untuk melakukannya, Anda harus:
- Tentukan ruang penelusuran kustom menggunakan bahasa Penelusuran Arsitektur Neural yang disediakan.
- Integrasikan definisi ruang penelusuran ke dalam kode trainer.
- Tambahkan pelaporan metrik kustom ke kode pelatih.
- Tambahkan reward kustom ke kode pelatih.
- Membangun container pelatihan dan menggunakannya untuk memulai tugas Penelusuran Arsitektur Neural.
Diagram berikut menggambarkan hal ini:
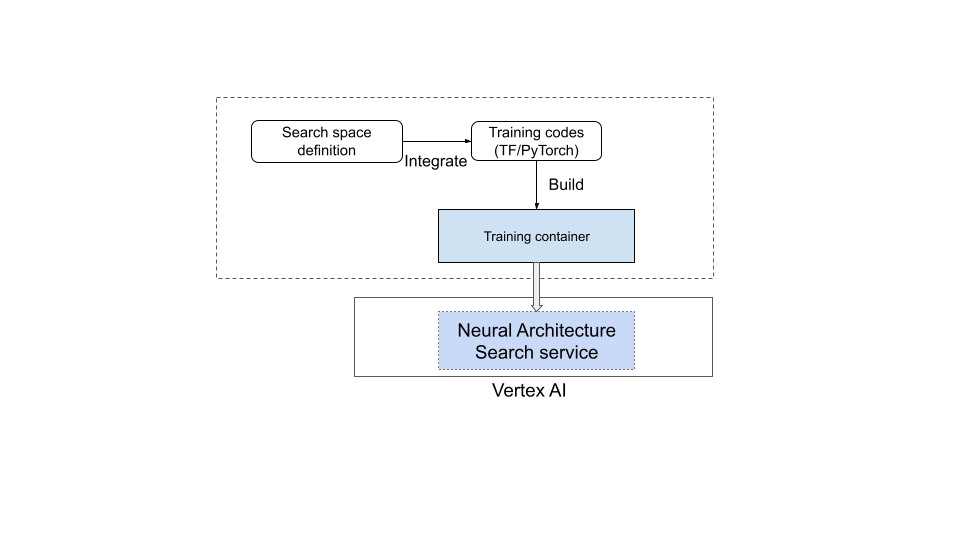
Layanan Penelusuran Neural Architecture sedang beroperasi
Setelah Anda menyiapkan container pelatihan yang akan digunakan, layanan Penelusuran Arsitektur Neural akan meluncurkan beberapa container pelatihan secara paralel di beberapa perangkat GPU. Anda dapat mengontrol jumlah uji coba yang akan digunakan secara paralel untuk pelatihan dan jumlah total uji coba yang akan diluncurkan. Setiap container pelatihan disediakan arsitektur yang disarankan dari ruang penelusuran. Container pelatihan mem-build model yang disarankan, melakukan pelatihan/mengevaluasi, lalu melaporkan reward kembali ke layanan Penelusuran Arsitektur Neural. Seiring dengan berlangsungnya proses ini, layanan Penelusuran Arsitektur Neural menggunakan masukan reward untuk menemukan arsitektur model yang terus menjadi semakin baik. Setelah penelusuran, Anda memiliki akses ke metrik yang dilaporkan untuk analisis lebih lanjut.
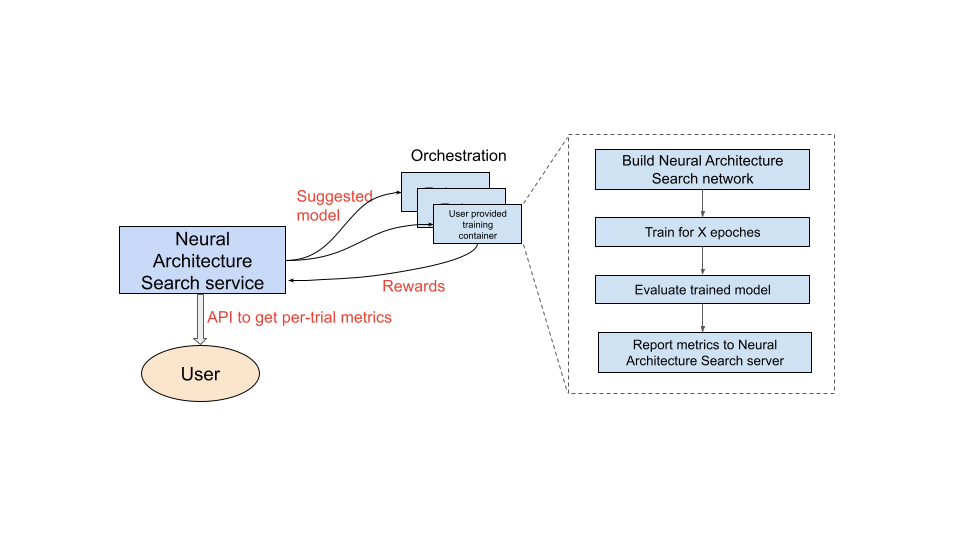
Ringkasan perjalanan pengguna untuk Penelusuran Arsitektur Neural
Langkah-langkah tingkat tinggi untuk melakukan eksperimen Penelusuran Arsitektur Neural adalah sebagai berikut:
Penyiapan dan definisi:
- Identifikasi set data berlabel dan tentukan jenis tugas (misalnya, deteksi atau segmentasi).
- Sesuaikan kode pelatih:
- Gunakan ruang penelusuran bawaan atau tentukan ruang penelusuran khusus menggunakan bahasa Penelusuran Arsitektur Neural.
- Integrasikan definisi ruang penelusuran ke dalam kode trainer.
- Tambahkan pelaporan metrik kustom ke kode pelatih.
- Tambahkan reward kustom ke kode pelatih.
- Buat container pelatih.
- Menyiapkan parameter uji coba penelusuran untuk pelatihan parsial (tugas proxy). Idealnya, pelatihan penelusuran harus selesai dengan cepat (misalnya, 30-60 menit) untuk melatih sebagian model:
- Epoch minimum yang diperlukan agar model yang diambil sampelnya dapat mengumpulkan reward (epoch minimum tidak diperlukan untuk memastikan konvergensi model).
- Hyperparameter (misalnya, kecepatan pembelajaran).
Jalankan penelusuran secara lokal untuk memastikan container terintegrasi ruang penelusuran dapat berjalan dengan benar.
Mulai Google Cloud tugas penelusuran (tahap-1) dengan lima uji coba pengujian dan pastikan uji coba penelusuran memenuhi target runtime dan akurasi.
Mulai tugas Google Cloud penelusuran (tahap-1) dengan uji coba +1k.
Sebagai bagian dari penelusuran, tetapkan juga interval reguler untuk melatih model N teratas (tahap-2):
- Hyperparameter dan algoritma untuk penelusuran hyperparameter. tahap-2 biasanya menggunakan konfigurasi yang mirip seperti tahap-1, tetapi dengan setelan yang lebih tinggi untuk parameter tertentu, seperti langkah/epoch pelatihan, dan jumlah saluran.
- Kriteria hentikan (jumlah epoch).
Lakukan analisis metrik yang dilaporkan dan/atau visualisasikan arsitektur untuk mendapatkan insight.
Eksperimen penelusuran arsitektur dapat ditindaklanjuti dengan eksperimen penskalaan-penelusuran, yang dilanjutkan dengan eksperimen penelusuran augmentasi.
Urutan pembacaan dokumentasi
- (Wajib) Menyiapkan lingkungan Anda
- (Wajib) Tutorial
- (Hanya diperlukan oleh pelanggan PyTorch) Pelatihan PyTorch yang efisien dengan data cloud
- (Wajib) Praktik terbaik dan alur kerja yang disarankan
- (Wajib) Desain tugas proxy
- (Hanya diperlukan saat menggunakan pelatih bawaan) Cara menggunakan ruang penelusuran bawaan dan trainer bawaan
Referensi
- Menggunakan Machine Learning untuk Mempelajari Arsitektur Jaringan Neural
- MnasNet: Menuju Otomatisasi Desain Model Mobile Machine Learning
- EfisienNet: Meningkatkan Akurasi dan Efisiensi melalui AutoML dan Penskalaan Model
- NAS-FPN: Mempelajari Arsitektur Piramida Fitur Skalabel untuk Deteksi Objek
- SpineNet: Mempelajari Scale-permuted Backbone untuk Pengenalan dan Pelokalan
- RandAugment