Vertex AI Neural Architecture Search のテストを開始する前に、以下のセクションに従って環境を設定します。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
-
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
After initializing the gcloud CLI, update it and install the required components:
gcloud components update gcloud components install beta
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
-
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
After initializing the gcloud CLI, update it and install the required components:
gcloud components update gcloud components install beta
- すべての Neural Architecture Search ユーザーに Vertex AI ユーザーロール(
roles/aiplatform.user)を付与する場合は、プロジェクト管理者にお問い合わせください。 - Docker をインストールします。
Ubuntu や Debian などの Linux ベースのオペレーティングシステムを使用している場合は、ユーザー名を
dockerグループに追加して、sudoを使わずに Docker を実行できるようにします。sudo usermod -a -G docker ${USER}dockerグループにユーザー名を追加した後に、システムの再起動が必要となる場合があります。 - Docker を開きます。Docker が稼働中であることを確認するには、次の Docker コマンドを実行します。このコマンドにより、現在の時刻と日付が返されることを確認します。
docker run busybox date
- Docker 認証ヘルパーとして
gcloudを使用します。gcloud auth configure-docker
-
(省略可)GPU をローカルで使用してコンテナを実行する場合は、
nvidia-dockerをインストールします。
Cloud Storage バケットを設定する
このセクションでは、新しいバケットの作成方法を説明します。既存のバケットを使用することもできますが、AI Platform ジョブを実行するリージョンと同じリージョンにある必要があります。また、Neural Architecture Search を実行するプロジェクトに含まれていない場合は、Neural Architecture Search サービス アカウントにアクセス権を明示的に付与する必要があります。
-
新しいバケットに名前を指定します。名前は Cloud Storage のすべてのバケット全体で重複しないようにする必要があります。
BUCKET_NAME="YOUR_BUCKET_NAME"
たとえば、プロジェクト名に
-vertexai-nasを追加したものを使います。PROJECT_ID="YOUR_PROJECT_ID" BUCKET_NAME=${PROJECT_ID}-vertexai-nas
-
作成したバケット名を確認します。
echo $BUCKET_NAME
-
バケットのリージョンを選択して、
REGION環境変数を設定します。Neural Architecture Search ジョブを実行するリージョンと同じリージョンを使用してください。
たとえば、次のコードは
REGIONを作成し、us-central1に設定します。REGION=us-central1
-
新しいバケットを作成します。
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
プロジェクトの追加デバイス割り当てをリクエストする
チュートリアルで使用する CPU マシンは約 5 台で、追加の割り当ては必要ありません。チュートリアルを実行したら、Neural Architecture Search ジョブを実行します。
Neural Architecture Search ジョブは、モデルのバッチを並行してトレーニングします。各トレーニング済みモデルは 1 つのトライアルに対応しています。検索ジョブに必要な CPU と GPU の量を見積もる方法については、number-of-parallel-trials の設定のセクションをご覧ください。たとえば、各トライアルで 2 T4 GPU を使用し、number-of-parallel-trials を 20 に設定した場合、検索ジョブには合計 40 T4 GPU の割り当てが必要です。さらに、各トライアルで highmem-16 CPU を使用している場合は、トライアルごとに 16 個の CPU ユニットが必要です。つまり、20 回の並列トライアルの場合は 320 CPU ユニットです。ただし、少なくとも 10 回の並列トライアルの割り当て(または 20 個の GPU の割り当て)が必要です。GPU のデフォルトの初期割り当ては、リージョンと GPU タイプによって異なり、通常は、Tesla_T4 の場合は 0、6、12、Tesla_V100 の場合は 0 または 6 になります。CPU のデフォルトの初期割り当てはリージョンによって異なり、通常は 20、450、または 2,200 です。
省略可: 複数の検索ジョブを並行して実行する場合は、割り当て要件をスケーリングします。割り当てをリクエストしても、すぐには課金されません。ジョブを実行すると課金されます。
十分な割り当てがなく、割り当てを超えるリソースを必要とするジョブを起動しようとすると、ジョブは起動せず、次のようなエラーが表示されます。
Exception: Starting job failed: {'code': 429, 'message': 'The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd', 'status': 'RESOURCE_EXHAUSTED', 'details': [{'@type': 'type.googleapis.com/google.rpc.DebugInfo', 'detail': '[ORIGINAL ERROR] generic::resource_exhausted: com.google.cloud.ai.platform.common.errors.AiPlatformException: code=RESOURCE_EXHAUSTED, message=The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd, cause=null [google.rpc.error_details_ext] { code: 8 message: "The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd" }'}]}
同じプロジェクトの複数のジョブが同時に開始され、そのすべてに対して割り当てが不十分な場合、いずれかのジョブがキュー待機状態のままになり、トレーニングが開始されないことがあります。この場合、キューに入れられたジョブをキャンセルし、割り当ての増加をリクエストするか、または前のジョブが完了するまで待機します。
[割り当て] ページからデバイスの追加割り当てをリクエストできます。フィルタを適用して、編集する割り当てを見つけることができます。
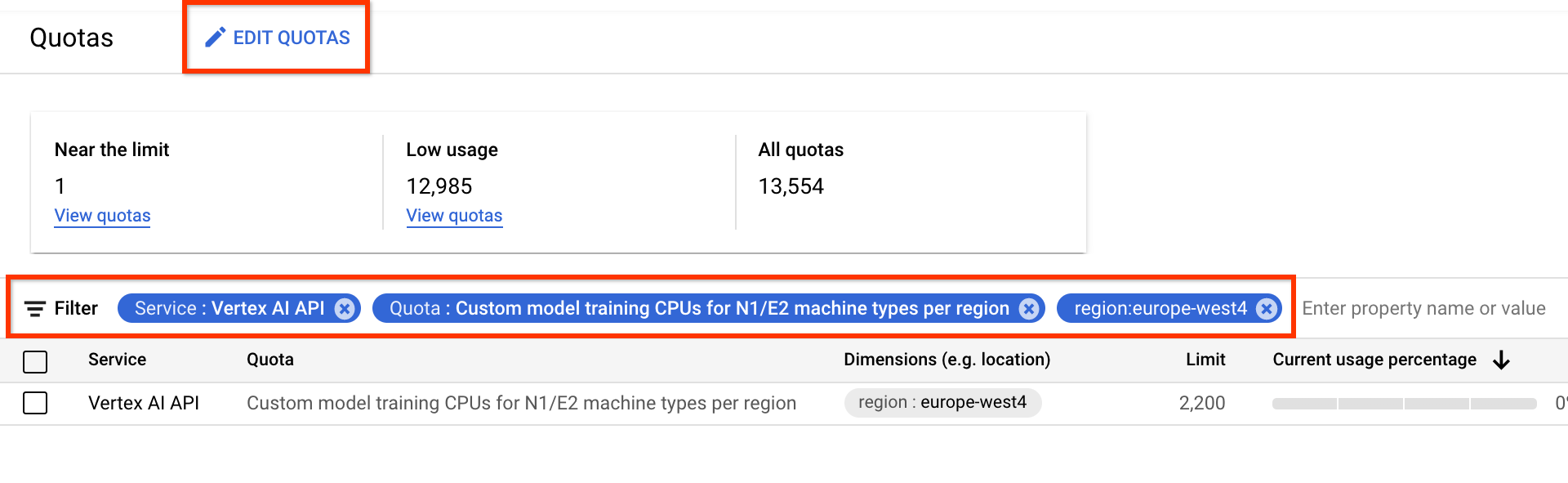
- [サービス] で [Vertex AI API] を選択します。
- [リージョン] で、フィルタリングするリージョンを選択します。
- [割り当て] で、接頭辞が「Custom model training」のアクセラレータ名を選択します。
- V100 GPU の場合、値は Custom model training Nvidia V100 GPUs per region になります。
- CPU の場合、値は Custom model training CPUs for N1/E2 machine types per region になります。CPU の数は、CPU の単位を表します。8 個の
highmem-16CPU が必要な場合は、割り当てリクエストを 8 × 16 = 128 CPU 単位で作成します。[リージョン] に目的の値を入力します。
割り当てリクエストを作成すると、Case number を受け取り、リクエストのステータスについてフォローアップ メールを送信します。GPU 割り当ての承認には、約 2~5 営業日かかることがあります。一般に、約 20~30 の GPU の割り当てを取得するのに要する時間は約 2~3 日で、約 100 GPU の承認には 5 営業日ほどかかります。CPU 割り当ての承認には、最大で 2 営業日かかることがあります。ただし、あるリージョンで GPU タイプが著しく不足している場合は、少量の割り当ての要求でさえも保証されません。この場合、別のリージョンまたは別の GPU タイプを選択するように求められることがあります。一般に、T4 GPU は V100 よりも簡単です。T4 GPU は実経過時間が長くなりますが、費用対効果に優れています。
詳細については、割り当て上限の引き上げをリクエストするをご覧ください。
プロジェクトの Artifact Registry を設定する
Docker イメージを push するプロジェクトとリージョンに Artifact Registry を設定する必要があります。
プロジェクトの [Artifact Registry] ページに移動します。まだ有効にしていない場合は、まずプロジェクトに対して Artifact Registry API を有効にします。
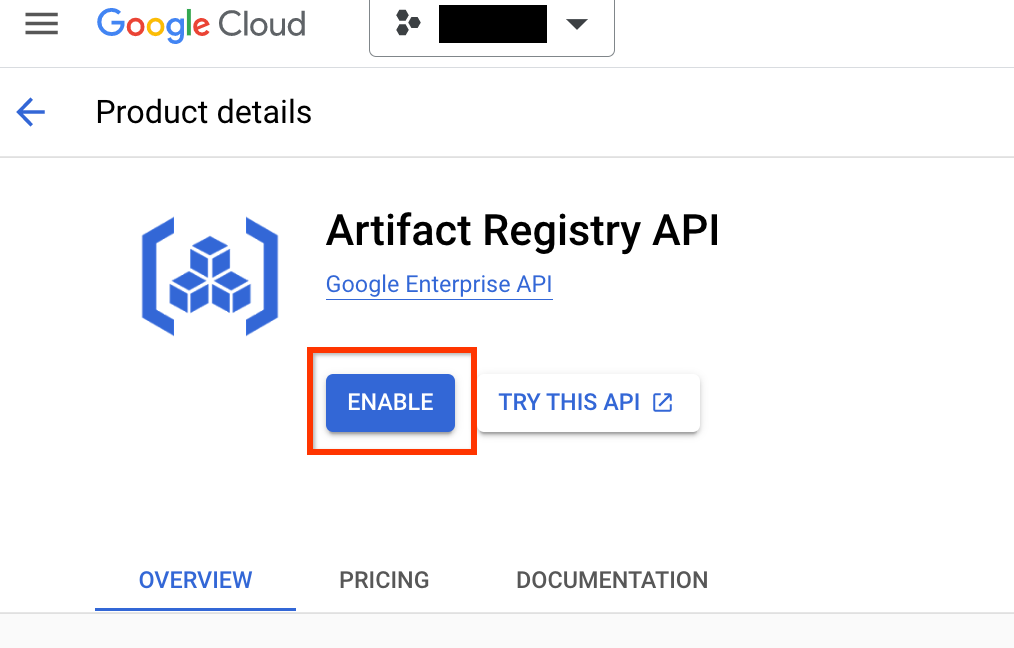
有効にしたら、[リポジトリを作成] をクリックして、新しいリポジトリの作成を開始します。
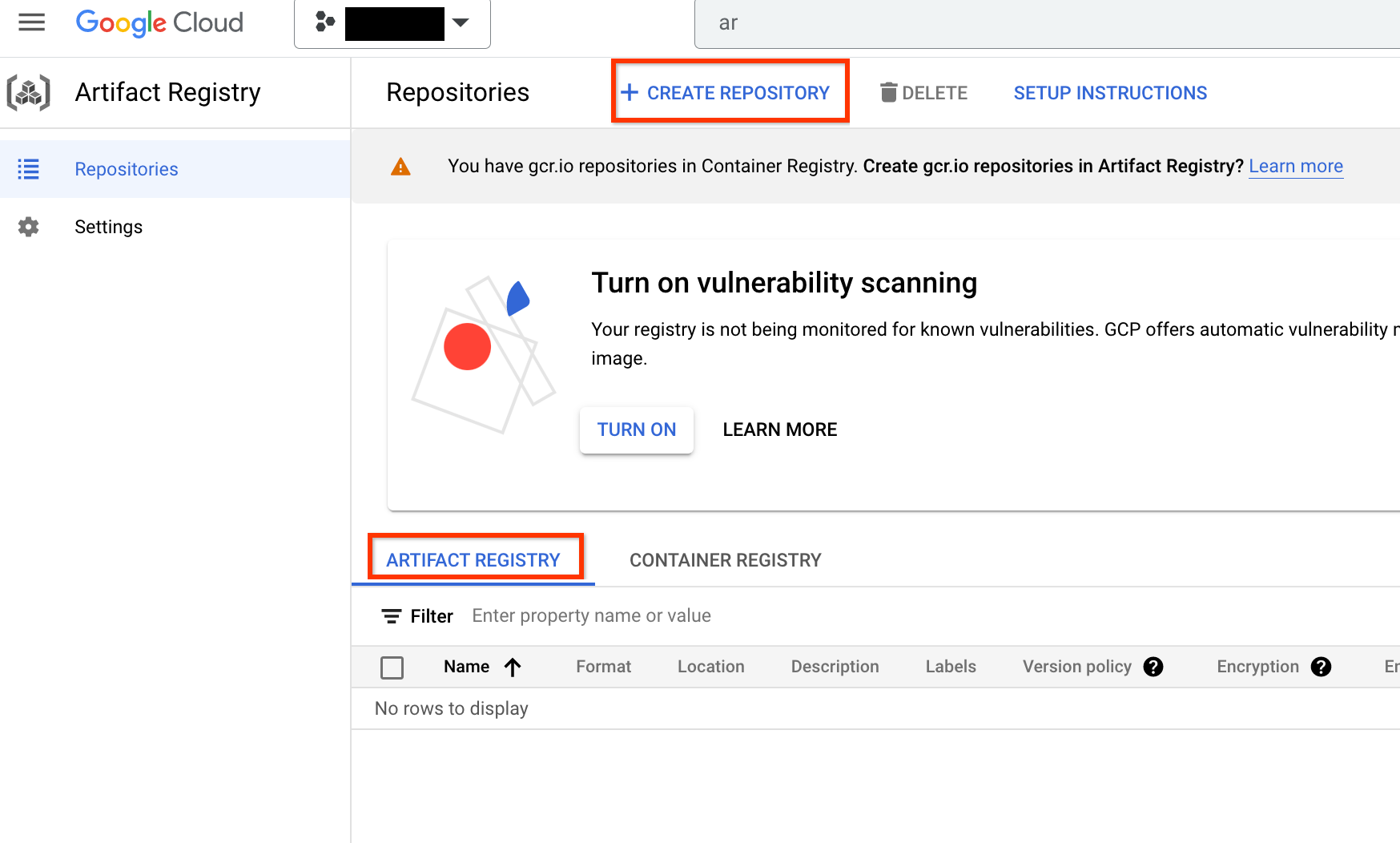
名前として nas、フォーマットとして Docker、Region としてロケーション タイプを選択します。[リージョン] で、ジョブを実行するロケーションを選択し、[作成] をクリックします。
これで、以下のように、必要な Docker リポジトリが作成されるはずです。
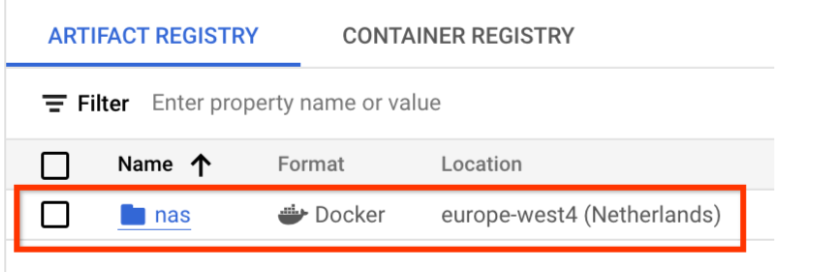
このリポジトリに Docker を push するための認証も設定する必要があります。この手順は、以下のローカル環境の設定セクションに含まれています。
ローカル環境を設定する
以下の手順は、ローカル環境の Bash シェルまたは Vertex AI Workbench ユーザー管理のノートブック インスタンスで行うことができます。
基本的な環境変数を設定します。
gcloud config set project PROJECT_ID gcloud auth login gcloud auth application-default loginArtifact Registry に Docker 認証を設定します。
# example: REGION=europe-west4 gcloud auth configure-docker REGION-docker.pkg.dev(省略可)Python 3 仮想環境を構成します。Python 3 の使用をおすすめしますが、必須ではありません。
sudo apt install python3-pip && \ pip3 install virtualenv && \ python3 -m venv --system-site-packages ~/./nas_venv && \ source ~/./nas_venv/bin/activateその他のライブラリをインストールします。
pip install google-cloud-storage==2.6.0 pip install pyglove==0.1.0
サービス アカウントを設定する
NAS ジョブを実行する前に、サービス アカウントを設定する必要があります。以下の手順は、ローカル環境の Bash シェルまたは Vertex AI Workbench ユーザー管理のノートブック インスタンスで行うことができます。
サービス アカウントを作成します。
gcloud iam service-accounts create NAME \ --description=DESCRIPTION \ --display-name=DISPLAY_NAMEサービス アカウントに
aiplatform.userロールとstorage.objectAdminロールを付与します。gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:NAME@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/aiplatform.user gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:NAME@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/storage.objectAdmin
たとえば、次のコマンドは、プロジェクト my-nas-project の下に、aiplatform.user ロールと storage.objectAdmin ロールを持つ my-nas-sa という名前のサービス アカウントを作成します。
gcloud iam service-accounts create my-nas-sa \
--description="Service account for NAS" \
--display-name="NAS service account"
gcloud projects add-iam-policy-binding my-nas-project \
--member=serviceAccount:my-nas-sa@my-nas-project.iam.gserviceaccount.com \
--role=roles/aiplatform.user
gcloud projects add-iam-policy-binding my-nas-project \
--member=serviceAccount:my-nas-sa@my-nas-project.iam.gserviceaccount.com \
--role=roles/storage.objectAdmin
コードをダウンロードする
Neural Architecture Search のテストを開始するには、サンプルの Python コードをダウンロードする必要があります。これには、事前構築されたトレーナー、検索空間の定義、関連するクライアント ライブラリが含まれます。
次の手順でソースコードをダウンロードします。
新しい Shell ターミナルを開きます。
Git clone コマンドを実行します。
git clone https://github.com/google/vertex-ai-nas.git