Os fluxos de trabalho tabulares são um conjunto de pipelines integrados, totalmente geridos e escaláveis para ML completo com dados tabulares. Tiram partido da tecnologia da Google para o desenvolvimento de modelos e oferecem-lhe opções de personalização para se adaptarem às suas necessidades.
Vantagens
- Totalmente gerido: não tem de se preocupar com atualizações, dependências e conflitos.
- Fácil de dimensionar: não precisa de reestruturar a infraestrutura à medida que as cargas de trabalho ou os conjuntos de dados crescem.
- Otimizado para o desempenho: o hardware certo é configurado automaticamente para os requisitos do fluxo de trabalho.
- Profundamente integrado: a compatibilidade com produtos no conjunto MLOps do Vertex AI, como o Vertex AI Pipelines e o Vertex AI Experiments, permite-lhe executar muitas experiências num curto período de tempo.
Descrição Geral Técnica
Cada fluxo de trabalho é uma instância gerida do Vertex AI Pipelines.
O Vertex AI Pipelines é um serviço sem servidor que executa pipelines Kubeflow. Pode usar pipelines para automatizar e monitorizar as suas tarefas de aprendizagem automática e preparação de dados. Cada passo num pipeline executa parte do fluxo de trabalho do pipeline. Por exemplo, um pipeline pode incluir passos para dividir dados, transformar tipos de dados e preparar um modelo. Uma vez que os passos são instâncias de componentes do pipeline, têm entradas, saídas e uma imagem de contentor. As entradas dos passos podem ser definidas a partir das entradas do pipeline ou podem depender da saída de outros passos neste pipeline. Estas dependências definem o fluxo de trabalho do pipeline como um gráfico acíclico orientado.
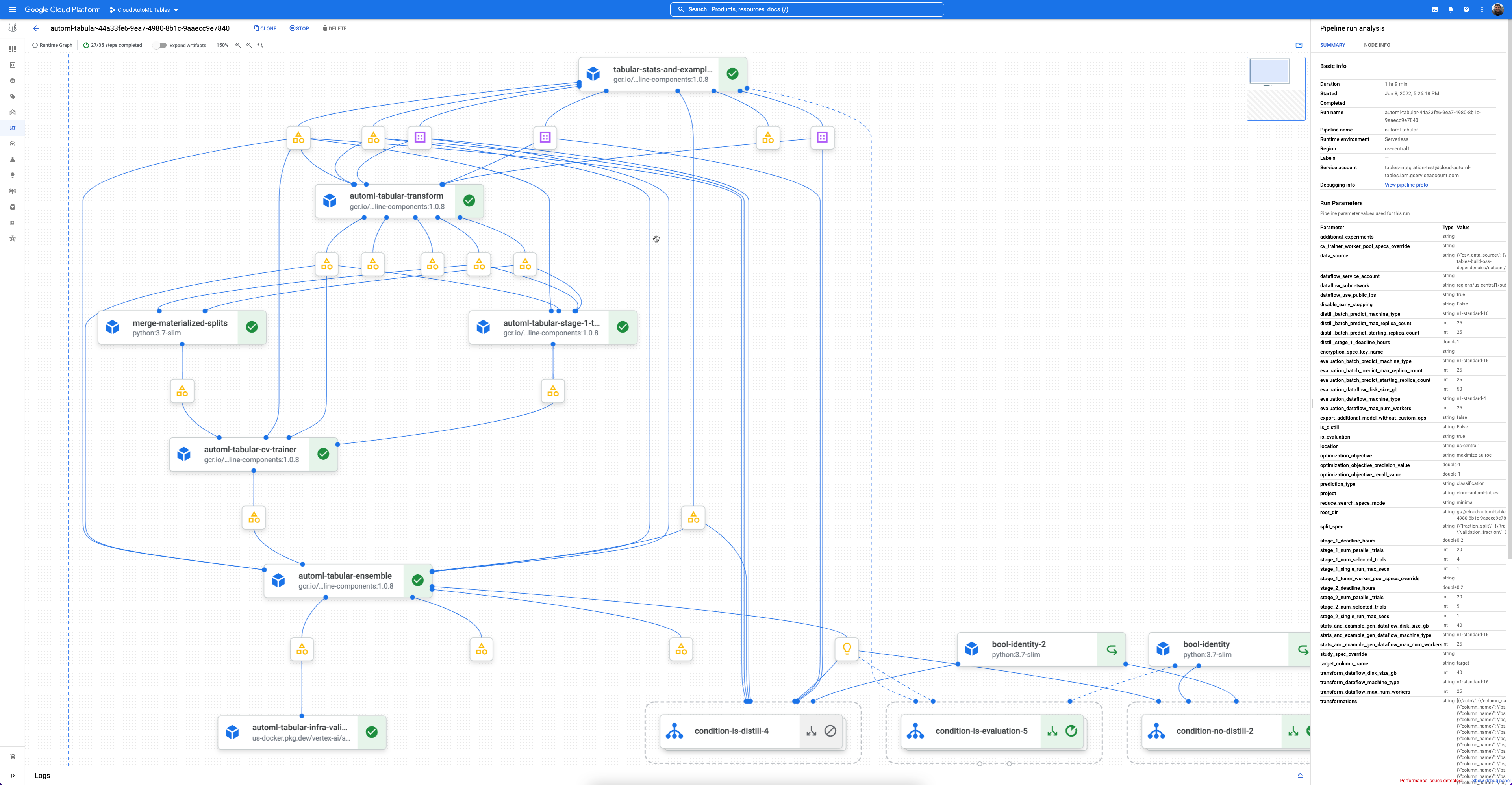
Começar
Na maioria dos casos, defina e execute o pipeline através do Google Cloud SDK de componentes de pipeline. O seguinte exemplo de código ilustra este processo. Tenha em atenção que a implementação real do código pode ser diferente.
// Define the pipeline and the parameters
template_path, parameter_values = tabular_utils.get_default_pipeline_and_parameters(
…
optimization_objective=optimization_objective,
data_source=data_source,
target_column_name=target_column_name
…)
// Run the pipeline
job = pipeline_jobs.PipelineJob(..., template_path=template_path, parameter_values=parameter_values)
job.run(...)
Para obter exemplos de colabs e blocos de notas, contacte o seu representante de vendas ou preencha um formulário de pedido.
Controlo de versões e manutenção
Os fluxos de trabalho tabulares têm um sistema de controlo de versões eficaz que permite atualizações e melhorias contínuas sem alterações significativas às suas aplicações.
Cada fluxo de trabalho é lançado e atualizado como parte do Google Cloud SDK de componentes de pipeline. As atualizações e as modificações a qualquer fluxo de trabalho são lançadas como novas versões desse fluxo de trabalho. As versões anteriores de todos os fluxos de trabalho estão sempre disponíveis através das versões mais antigas do SDK. Se a versão do SDK estiver fixada, a versão do fluxo de trabalho também está fixada.
Fluxos de trabalho disponíveis
O Vertex AI oferece os seguintes fluxos de trabalho tabulares:
| Nome | Tipo | Disponibilidade |
|---|---|---|
| Feature Transform Engine | Engenharia de funcionalidades | Pré-visualização pública |
| AutoML ponto a ponto | Classificação e regressão | Disponível de forma geral |
| TabNet | Classificação e regressão | Pré-visualização pública |
| Wide & Deep | Classificação e regressão | Pré-visualização pública |
| Previsão | Previsão | Pré-visualização pública |
Para informações adicionais e exemplos de blocos de notas, contacte o seu representante de vendas ou preencha um formulário de pedido.
Feature Transform Engine
O Feature Transform Engine realiza a seleção e as transformações de funcionalidades. Se a seleção de funcionalidades estiver ativada, o Feature Transform Engine cria um conjunto classificado de funcionalidades importantes. Se as transformações de funcionalidades estiverem ativadas, o Feature Transform Engine processa as funcionalidades para garantir que a entrada para a preparação e a publicação do modelo é consistente. O Feature Transform Engine pode ser usado de forma autónoma ou em conjunto com qualquer um dos fluxos de trabalho de preparação tabular. É compatível com frameworks TensorFlow e não TensorFlow.
Para mais informações, consulte o artigo Engenharia de funcionalidades.
Fluxos de trabalho tabulares para classificação e regressão
Fluxo de trabalho tabular para o AutoML integral
O fluxo de trabalho tabular para o AutoML completo é um pipeline do AutoML completo para tarefas de classificação e regressão. É semelhante à API AutoML, mas permite-lhe escolher o que controlar e o que automatizar. Em vez de ter controlos para todo o pipeline, tem controlos para cada passo no pipeline. Estes controlos do pipeline incluem:
- Divisão de dados
- Engenharia de funcionalidades
- Pesquisa de arquitetura
- Preparação de modelos
- Agregação de modelos
- Destilação de modelos
Vantagens
- Suporta grandes conjuntos de dados com vários TB e até 1000 colunas.
- Permite melhorar a estabilidade e reduzir o tempo de preparação, limitando o espaço de pesquisa de tipos de arquitetura ou ignorando a pesquisa de arquitetura.
- Permite melhorar a velocidade de preparação selecionando manualmente o hardware usado para a preparação e a pesquisa de arquitetura.
- Permite reduzir o tamanho do modelo e melhorar a latência com a destilação ou alterando o tamanho do conjunto.
- Cada componente do AutoML pode ser inspecionado numa interface de gráfico de pipelines avançada que lhe permite ver as tabelas de dados transformadas, as arquiteturas de modelos avaliadas e muitos mais detalhes.
- Cada componente do AutoML tem uma flexibilidade e uma transparência alargadas, como a capacidade de personalizar parâmetros, hardware, ver o estado do processo, registos e muito mais.
Entrada-saída
- Usa uma tabela do BigQuery ou um ficheiro CSV do Cloud Storage como entrada.
- Produz um modelo do Vertex AI como resultado.
- As saídas intermédias incluem estatísticas e divisões do conjunto de dados.
Para mais informações, consulte o artigo Fluxo de trabalho tabular para o AutoML integral.
Fluxo de trabalho tabular para a TabNet
O fluxo de trabalho tabular para o TabNet é um pipeline que pode usar para formar modelos de classificação ou regressão. A TabNet usa a atenção sequencial para escolher as funcionalidades a partir das quais raciocinar em cada etapa de decisão. Isto promove a interpretabilidade e a aprendizagem mais eficiente, uma vez que a capacidade de aprendizagem é usada para as funcionalidades mais relevantes.
Vantagens
- Seleciona automaticamente o espaço de pesquisa de hiperparâmetros adequado com base no tamanho do conjunto de dados, no tipo de inferência e no orçamento de preparação.
- Integrado com o Vertex AI. O modelo preparado é um modelo do Vertex AI. Pode executar inferências em lote ou implementar o modelo para inferências online imediatamente.
- Oferece interpretabilidade inerente do modelo. Pode obter informações sobre as funcionalidades que a TabNet usou para tomar a sua decisão.
- Suporta a preparação de GPUs.
Entrada-saída
Usa uma tabela do BigQuery ou um ficheiro CSV do Cloud Storage como entrada e fornece um modelo do Vertex AI como saída.
Para mais informações, consulte o Fluxo de trabalho tabular para a TabNet.
Fluxo de trabalho tabular para modelos amplos e profundos
O fluxo de trabalho tabular para o modelo amplo e profundo é um pipeline que pode usar para formar modelos de classificação ou regressão. A arquitetura Wide & Deep forma em conjunto modelos lineares amplos e redes neurais profundas. Combina as vantagens da memorização e da generalização. Em algumas experiências online, os resultados mostraram que o modelo Wide & Deep aumentou significativamente as aquisições de aplicações da Google Store em comparação com os modelos apenas amplos e apenas profundos.
Vantagens
- Integrado com o Vertex AI. O modelo preparado é um modelo do Vertex AI. Pode executar inferências em lote ou implementar o modelo para inferências online imediatamente.
Entrada-saída
Usa uma tabela do BigQuery ou um ficheiro CSV do Cloud Storage como entrada e fornece um modelo do Vertex AI como saída.
Para mais informações, consulte o artigo Fluxo de trabalho tabular para dados amplos e detalhados.
Fluxos de trabalho tabulares para previsões
Fluxo de trabalho tabular para previsões
O fluxo de trabalho tabular para previsões é o pipeline completo para tarefas de previsão. É semelhante à API AutoML, mas permite-lhe escolher o que controlar e o que automatizar. Em vez de ter controlos para todo o pipeline, tem controlos para cada passo no pipeline. Estes controlos do pipeline incluem:
- Divisão de dados
- Engenharia de funcionalidades
- Pesquisa de arquitetura
- Preparação de modelos
- Agregação de modelos
Vantagens
- Suporta grandes conjuntos de dados com um tamanho máximo de 1 TB e até 200 colunas.
- Permite melhorar a estabilidade e reduzir o tempo de preparação, limitando o espaço de pesquisa de tipos de arquitetura ou ignorando a pesquisa de arquitetura.
- Permite melhorar a velocidade de treino selecionando manualmente o hardware usado para o treino e a pesquisa de arquitetura.
- Permite reduzir o tamanho do modelo e melhorar a latência alterando o tamanho do conjunto.
- Cada componente pode ser inspecionado numa interface de gráfico de pipelines avançada que lhe permite ver as tabelas de dados transformadas, as arquiteturas de modelos avaliadas e muitos mais detalhes.
- Cada componente recebe flexibilidade e transparência alargadas, como a capacidade de personalizar parâmetros, hardware, ver o estado do processo, registos e muito mais.
Entrada-saída
- Usa uma tabela do BigQuery ou um ficheiro CSV do Cloud Storage como entrada.
- Produz um modelo do Vertex AI como resultado.
- As saídas intermédias incluem estatísticas e divisões do conjunto de dados.
Para mais informações, consulte o artigo Fluxo de trabalho tabular para previsões.
O que se segue?
- Saiba mais sobre o fluxo de trabalho tabular para o AutoML integral.
- Saiba mais sobre o fluxo de trabalho tabular para a TabNet.
- Saiba mais sobre o fluxo de trabalho tabular para aprendizagem ampla e avançada.
- Saiba mais sobre o fluxo de trabalho tabular para previsão.
- Saiba mais sobre a engenharia de funcionalidades.
- Saiba mais sobre os preços dos fluxos de trabalho tabulares.