Este documento oferece uma vista geral do pipeline e dos componentes do AutoML ponto a ponto. Para saber como preparar um modelo com o AutoML completo, consulte o artigo Prepare um modelo com o AutoML completo.
O fluxo de trabalho tabular para o AutoML completo é um pipeline do AutoML completo para tarefas de classificação e regressão. É semelhante à API AutoML, mas permite-lhe escolher o que controlar e o que automatizar. Em vez de ter controlos para todo o pipeline, tem controlos para cada passo no pipeline. Estes controlos do pipeline incluem:
- Divisão de dados
- Engenharia de funcionalidades
- Pesquisa de arquitetura
- Preparação de modelos
- Agregação de modelos
- Destilação de modelos
Vantagens
Seguem-se algumas das vantagens do fluxo de trabalho tabular para o AutoML integral :
- Suporta grandes conjuntos de dados com vários TB e até 1000 colunas.
- Permite melhorar a estabilidade e reduzir o tempo de preparação, limitando o espaço de pesquisa de tipos de arquitetura ou ignorando a pesquisa de arquitetura.
- Permite melhorar a velocidade de preparação selecionando manualmente o hardware usado para a preparação e a pesquisa de arquitetura.
- Permite reduzir o tamanho do modelo e melhorar a latência com a destilação ou alterando o tamanho do conjunto.
- Cada componente do AutoML pode ser inspecionado numa interface de gráfico de pipelines avançada que lhe permite ver as tabelas de dados transformadas, as arquiteturas de modelos avaliadas e muitos mais detalhes.
- Cada componente do AutoML tem uma flexibilidade e uma transparência alargadas, como a capacidade de personalizar parâmetros, hardware, ver o estado do processo, registos e muito mais.
AutoML ponto a ponto no Vertex AI Pipelines
O fluxo de trabalho tabular para o AutoML ponto a ponto é uma instância gerida do Vertex AI Pipelines.
O Vertex AI Pipelines é um serviço sem servidor que executa pipelines Kubeflow. Pode usar pipelines para automatizar e monitorizar as suas tarefas de aprendizagem automática e preparação de dados. Cada passo num pipeline executa parte do fluxo de trabalho do pipeline. Por exemplo, um pipeline pode incluir passos para dividir dados, transformar tipos de dados e preparar um modelo. Uma vez que os passos são instâncias de componentes do pipeline, têm entradas, saídas e uma imagem de contentor. As entradas dos passos podem ser definidas a partir das entradas do pipeline ou podem depender da saída de outros passos neste pipeline. Estas dependências definem o fluxo de trabalho do pipeline como um gráfico acíclico orientado.
Vista geral do pipeline e dos componentes
O diagrama seguinte mostra o pipeline de modelagem para o fluxo de trabalho tabular para o AutoML integral :

Os componentes do pipeline são:
- feature-transform-engine: realiza a engenharia de funcionalidades. Consulte o Feature Transform Engine para ver detalhes.
- split-materialized-data:
divida os dados materializados num conjunto de preparação, num conjunto de avaliação e num conjunto de teste.
Entrada:
- Dados materializados
materialized_data.
Saída:
- Divisão de preparação materializada:
materialized_train_split. - Divisão de avaliação materializada
materialized_eval_split. - Conjunto de teste materializado
materialized_test_split.
- Dados materializados
- merge-materialized-splits: une a divisão de avaliação materializada e a divisão de preparação materializada.
automl-tabular-stage-1-tuner: executa a pesquisa da arquitetura do modelo e ajusta os hiperparâmetros.
- Uma arquitetura é definida por um conjunto de hiperparâmetros.
- Os hiperparâmetros incluem o tipo de modelo e os parâmetros do modelo.
- Os tipos de modelos considerados são redes neurais e árvores de decisão com reforço.
- O sistema prepara um modelo para cada arquitetura considerada.
automl-tabular-cv-trainer: valida arquiteturas de forma cruzada através da preparação de modelos em diferentes dobras dos dados de entrada.
- As arquiteturas consideradas são as que dão os melhores resultados no passo anterior.
- O sistema seleciona aproximadamente dez das melhores arquiteturas. O número preciso é definido pelo orçamento de formação.
automl-tabular-ensemble: reúne as melhores arquiteturas para produzir um modelo final.
- O diagrama seguinte ilustra a validação cruzada de K-fold com bagging:
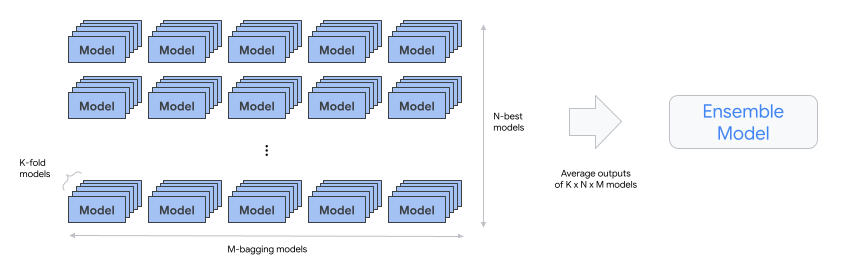
condition-is-distill: opcional. Cria uma versão mais pequena do modelo de conjunto.
- Um modelo mais pequeno reduz a latência e o custo da inferência.
automl-tabular-infra-validator: valida se o modelo preparado é um modelo válido.
model-upload: carrega o modelo.
condition-is-evaluation: opcional. Usa o conjunto de testes para calcular as métricas de avaliação.