本頁說明如何使用 Tabular Workflow for Forecasting,從表格資料集訓練預測模型。
如要瞭解這個工作流程使用的服務帳戶,請參閱表格工作流程的服務帳戶。
如果在執行「預測」的表格工作流程時收到配額錯誤,可能需要申請提高配額。詳情請參閱「管理表格工作流程的配額」。
表格預測工作流程不支援匯出模型。
Workflow API
這個工作流程會使用下列 API:
- Vertex AI
- Dataflow
- Compute Engine
- Cloud Storage
取得先前超參數調整結果的 URI
如果您先前已完成表格資料預測工作流程,可以使用先前執行的超參數調整結果,節省訓練時間和資源。使用 Google Cloud 控制台或透過 API 以程式輔助方式載入,即可找到先前的超參數調整結果。
Google Cloud 控制台
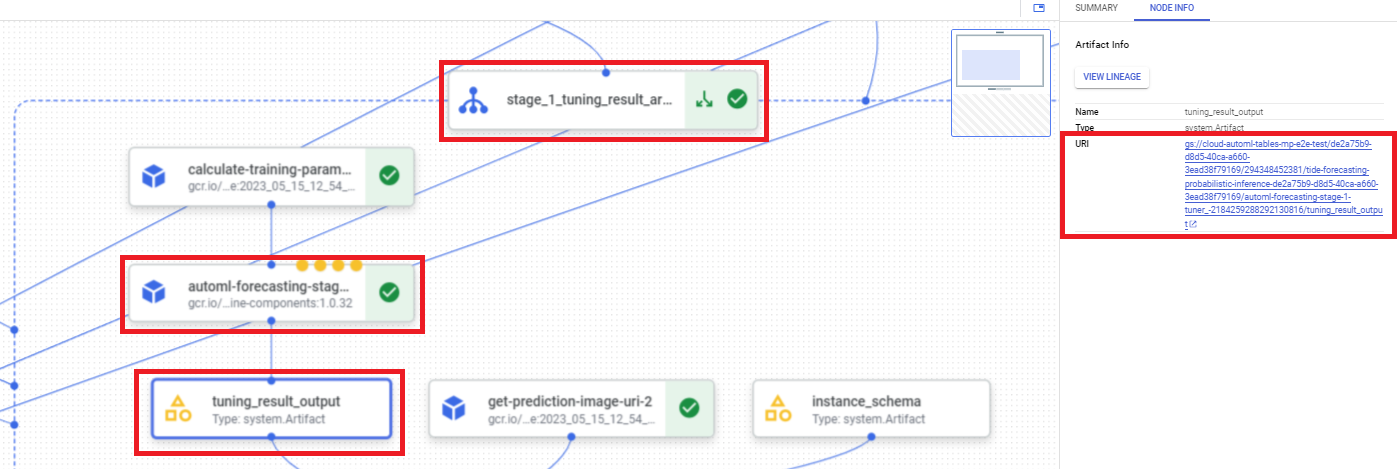
如要使用 Google Cloud 控制台找出超參數調整結果 URI,請按照下列步驟操作:
在 Google Cloud 控制台的 Vertex AI 專區中,前往「Pipelines」頁面。
選取「執行」分頁標籤。
選取要使用的管道執行作業。
選取「Expand Artifacts」(展開構件)。
按一下元件 exit-handler-1。
按一下元件 stage_1_tuning_result_artifact_uri_empty。
找出 automl-forecasting-stage-1-tuner 元件。
按一下相關構件「tuning_result_output」tuning_result_output。
選取「節點資訊」分頁標籤。
API:Python
以下程式碼範例展示如何使用 API 載入超參數調整結果。變數 job 是指先前的模型訓練管道執行作業。
def get_task_detail(
task_details: List[Dict[str, Any]], task_name: str
) -> List[Dict[str, Any]]:
for task_detail in task_details:
if task_detail.task_name == task_name:
return task_detail
pipeline_task_details = job.gca_resource.job_detail.task_details
stage_1_tuner_task = get_task_detail(
pipeline_task_details, "automl-forecasting-stage-1-tuner"
)
stage_1_tuning_result_artifact_uri = (
stage_1_tuner_task.outputs["tuning_result_output"].artifacts[0].uri
)
訓練模型
下列程式碼範例示範如何執行模型訓練管道:
job = aiplatform.PipelineJob(
...
template_path=template_path,
parameter_values=parameter_values,
...
)
job.run(service_account=SERVICE_ACCOUNT)
您可以在 job.run() 中使用選用的 service_account 參數,將 Vertex AI Pipelines 服務帳戶設為您選擇的帳戶。
Vertex AI 支援下列模型訓練方法:
時間序列稠密型編碼器 (TiDE)。如要使用這項模型訓練方法,請使用下列函式定義管道和參數值:
template_path, parameter_values = automl_forecasting_utils.get_time_series_dense_encoder_forecasting_pipeline_and_parameters(...)時間融合轉換器 (TFT)。如要使用這項模型訓練方法,請使用下列函式定義管道和參數值:
template_path, parameter_values = automl_forecasting_utils.get_temporal_fusion_transformer_forecasting_pipeline_and_parameters(...)AutoML (L2L)。如要使用這項模型訓練方法,請使用下列函式定義管道和參數值:
template_path, parameter_values = automl_forecasting_utils.get_learn_to_learn_forecasting_pipeline_and_parameters(...)Seq2Seq+。如要使用這個模型訓練方法,請使用下列函式定義管道和參數值:
template_path, parameter_values = automl_forecasting_utils.get_sequence_to_sequence_forecasting_pipeline_and_parameters(...)
詳情請參閱「模型訓練方法」。
訓練資料可以是 Cloud Storage 中的 CSV 檔案,也可以是 BigQuery 中的資料表。
以下是部分模型訓練參數:
| 參數名稱 | 類型 | 定義 |
|---|---|---|
optimization_objective |
字串 | 根據預設,Vertex AI 會盡量減少均方根誤差 (RMSE)。如要為預測模型設定不同的最佳化目標,請在「預測模型的最佳化目標」中選擇其中一個選項。如果選擇盡量減少分位數損失,也必須指定 quantiles 的值。 |
enable_probabilistic_inference |
布林值 | 如果設為 true,Vertex AI 會模擬預測的機率分布。機率推論可處理有雜訊的資料並量化不確定性,進而提升模型品質。如果指定 quantiles,Vertex AI 也會傳回分布的量化。機率推論僅適用於時間序列密集編碼器 (TiDE) 和 AutoML (L2L) 訓練方法。機率推論與 minimize-quantile-loss 最佳化目標不相容。 |
quantiles |
List[float] | 用於minimize-quantile-loss最佳化目標和機率推論的分位數。請提供最多五個介於 0 和 1 之間的不重複數字 (不含 0 和 1)。 |
time_column |
字串 | 時間欄。詳情請參閱「資料結構規定」。 |
time_series_identifier_columns |
List[str] | 時間序列 ID 欄。詳情請參閱「資料結構規定」。 |
weight_column |
字串 | (選用) 權重欄。詳情請參閱「為訓練資料新增權重」。 |
time_series_attribute_columns |
List[str] | (選用) 時間序列屬性的資料欄名稱。詳情請參閱「預測時的特徵類型和可用性」。 |
available_at_forecast_columns |
List[str] | (選用) 共變數資料欄的名稱,預測時已知這些資料欄的值。詳情請參閱「預測時的特徵類型和可用性」。 |
unavailable_at_forecast_columns |
List[str] | (選用) 共變量資料欄的名稱,預測時的值不明。詳情請參閱「預測時的特徵類型和可用性」。 |
forecast_horizon |
整數 | (選用) 預測期間會決定模型預測推論資料各列目標值的未來時間長度。 詳情請參閱「預測範圍、背景期間和預測期間」。 |
context_window |
整數 | (選用) 背景期間會設定模型在訓練期間 (和預測期間) 的回溯時間。換句話說,對於每個訓練資料點,背景區間會決定模型回溯多遠的時間,以尋找預測模式。詳情請參閱「預測範圍、背景期間和預測期間」。 |
window_max_count |
整數 | (選用) Vertex AI 會使用滾動視窗策略,從輸入資料產生預測視窗。預設策略為「Count」。視窗數上限的預設值為 100,000,000。設定這個參數,即可為視窗數量上限提供自訂值。詳情請參閱「滾動週期策略」。 |
window_stride_length |
整數 | (選用) Vertex AI 會使用滾動視窗策略,從輸入資料產生預測視窗。如要選取「步幅」策略,請將這個參數設為步幅長度的值。詳情請參閱「滾動週期策略」。 |
window_predefined_column |
字串 | (選用) Vertex AI 會使用滾動視窗策略,從輸入資料產生預測視窗。如要選取「Column」策略,請將這個參數設為含有 True 或 False 值的資料欄名稱。詳情請參閱「滾動週期策略」。 |
holiday_regions |
List[str] | (選用) 您可以選取一或多個地理區域,啟用節慶效應模擬功能。訓練期間,Vertex AI 會根據 time_column 中的日期和指定的地理區域,在模型中建立節慶類別特徵。節慶效應模擬功能預設為停用。詳情請參閱「節慶區域」。 |
predefined_split_key |
字串 | (選用) 根據預設,Vertex AI 會使用時間順序分割演算法,將預測資料分成三種資料分割。如要控管哪些訓練資料列用於哪些拆分,請提供包含資料拆分值 (TRAIN、VALIDATION、TEST) 的資料欄名稱。詳情請參閱預測的資料拆分。 |
training_fraction |
浮點值 | (選用) 根據預設,Vertex AI 會使用時間順序分割演算法,將預測資料分成三種資料分割。80% 的資料會指派給訓練集,10% 會指派給驗證分割,10% 則會指派給測試分割。如要自訂指派給訓練集的資料比例,請設定這個參數。詳情請參閱「預測資料分割」。 |
validation_fraction |
浮點值 | (選用) 根據預設,Vertex AI 會使用時間順序分割演算法,將預測資料分成三種資料分割。80% 的資料會指派給訓練集,10% 會指派給驗證分割,10% 則會指派給測試分割。如要自訂指派給驗證集的資料比例,請設定這個參數。詳情請參閱「預測資料分割」。 |
test_fraction |
浮點值 | (選用) 根據預設,Vertex AI 會使用時間順序分割演算法,將預測資料分成三種資料分割。80% 的資料會指派給訓練集,10% 會指派給驗證分割,10% 則會指派給測試分割。如要自訂指派給測試集的資料比例,請設定這個參數。詳情請參閱「預測資料分割」。 |
data_source_csv_filenames |
字串 | 儲存在 Cloud Storage 中的 CSV 檔案 URI。 |
data_source_bigquery_table_path |
字串 | BigQuery 資料表的 URI。 |
dataflow_service_account |
字串 | (選用) 用於執行 Dataflow 工作的自訂服務帳戶。您可以將 Dataflow 工作設定為使用私人 IP 和特定虛擬私有雲子網路。這個參數會覆寫預設的 Dataflow 工作站服務帳戶。 |
run_evaluation |
布林值 | 如果設為 True,Vertex AI 會評估測試集分割資料的集合模型。 |
evaluated_examples_bigquery_path |
字串 | 模型評估期間使用的 BigQuery 資料集路徑。資料集是預測範例的目的地。如果 run_evaluation 設為 True,您就必須設定參數值,且格式必須為 bq://[PROJECT].[DATASET]。 |
轉換
您可以提供自動或類型解析的字典對應,以對應至特徵資料欄。支援的類型包括:自動、數值、類別、文字和時間戳記。
| 參數名稱 | 類型 | 定義 |
|---|---|---|
transformations |
Dict[str, List[str]] | 自動或類型解析度的字典對應 |
下列程式碼提供輔助函式,用於填入 transformations 參數。此外,本範例也說明如何使用這項函式,對 features 變數定義的一組資料欄套用自動轉換。
def generate_transformation(
auto_column_names: Optional[List[str]]=None,
numeric_column_names: Optional[List[str]]=None,
categorical_column_names: Optional[List[str]]=None,
text_column_names: Optional[List[str]]=None,
timestamp_column_names: Optional[List[str]]=None,
) -> List[Dict[str, Any]]:
if auto_column_names is None:
auto_column_names = []
if numeric_column_names is None:
numeric_column_names = []
if categorical_column_names is None:
categorical_column_names = []
if text_column_names is None:
text_column_names = []
if timestamp_column_names is None:
timestamp_column_names = []
return {
"auto": auto_column_names,
"numeric": numeric_column_names,
"categorical": categorical_column_names,
"text": text_column_names,
"timestamp": timestamp_column_names,
}
transformations = generate_transformation(auto_column_names=features)
如要進一步瞭解轉換,請參閱「資料類型和轉換」。
工作流程自訂選項
您可以定義在管道定義期間傳入的引數值,自訂用於預測的表格工作流程。您可以透過下列方式自訂工作流程:
- 設定硬體
- 略過架構搜尋
設定硬體
您可以使用下列模型訓練參數,設定訓練用的機器類型和機器數量。如果您有大型資料集,並想據此最佳化機器硬體,建議選擇這個選項。
| 參數名稱 | 類型 | 定義 |
|---|---|---|
stage_1_tuner_worker_pool_specs_override |
Dict[String, Any] | (選用) 訓練用的機器類型和機器數量自訂設定。這項參數會設定管道的 automl-forecasting-stage-1-tuner 元件。 |
下列程式碼示範如何為 TensorFlow 主要節點設定 n1-standard-8 機器類型,以及為 TensorFlow 評估器節點設定 n1-standard-4 機器類型:
worker_pool_specs_override = [
{"machine_spec": {"machine_type": "n1-standard-8"}}, # override for TF chief node
{}, # override for TF worker node, since it's not used, leave it empty
{}, # override for TF ps node, since it's not used, leave it empty
{
"machine_spec": {
"machine_type": "n1-standard-4" # override for TF evaluator node
}
}
]
略過架構搜尋
您可以透過下列模型訓練參數執行管道,不必進行架構搜尋,而是提供先前管道執行作業的一組超參數。
| 參數名稱 | 類型 | 定義 |
|---|---|---|
stage_1_tuning_result_artifact_uri |
字串 | (選用) 先前管道執行作業的超參數調整結果 URI。 |