Questa pagina mostra come addestrare un modello di previsione da un set di dati tabellare con il flusso di lavoro tabellare per la previsione.
Per scoprire di più sui service account utilizzati da questo flusso di lavoro, consulta Service account per i flussi di lavoro tabulari.
Se ricevi un errore di quota durante l'esecuzione del flusso di lavoro tabulare per la previsione, potresti dover richiedere una quota più elevata. Per saperne di più, consulta Gestire le quote per i workflow tabulari.
Il flusso di lavoro tabulare per la previsione non supporta l'esportazione del modello.
API Workflow
Questo flusso di lavoro utilizza le seguenti API:
- Vertex AI
- Dataflow
- Compute Engine
- Cloud Storage
Recupera l'URI del risultato precedente dell'ottimizzazione iperparametri
Se in precedenza hai completato un'esecuzione del flusso di lavoro tabulare per la previsione, puoi utilizzare il risultato dell'ottimizzazione degli iperparametri dell'esecuzione precedente per risparmiare tempo e risorse di addestramento. Trova il risultato precedente dell'ottimizzazione degli iperparametri utilizzando la console Google Cloud o caricandolo in modo programmatico con l'API.
Console Google Cloud
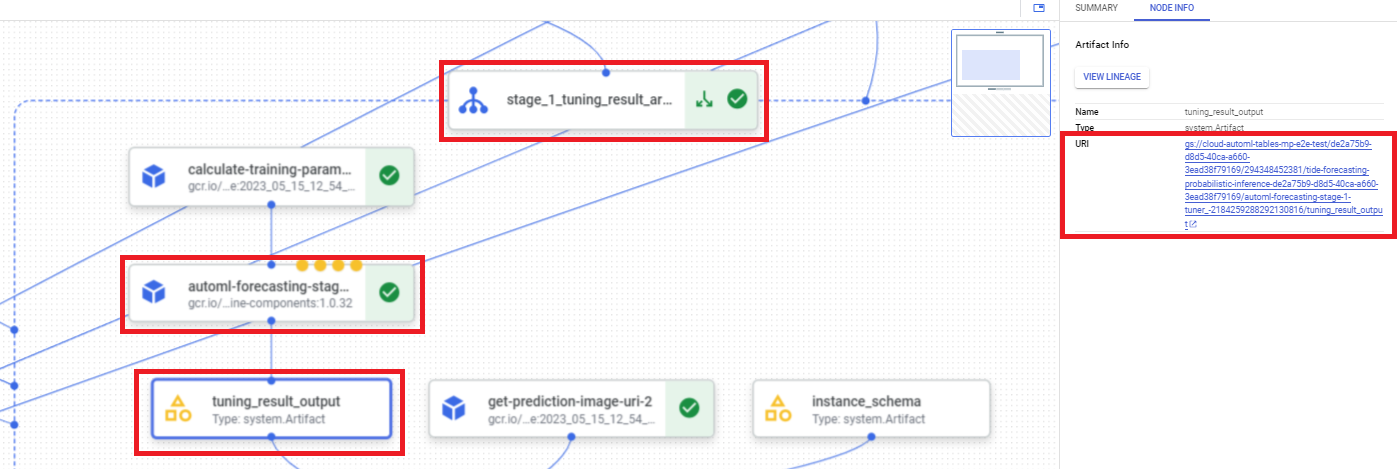
Per trovare l'URI del risultato dell'ottimizzazione degli iperparametri utilizzando la console Google Cloud , segui questi passaggi:
Nella console Google Cloud , nella sezione Vertex AI, vai alla pagina Pipeline.
Seleziona la scheda Esecuzioni.
Seleziona l'esecuzione della pipeline che vuoi utilizzare.
Seleziona Espandi artefatti.
Fai clic sul componente exit-handler-1.
Fai clic sul componente stage_1_tuning_result_artifact_uri_empty.
Trova il componente automl-forecasting-stage-1-tuner.
Fai clic sull'artefatto associato tuning_result_output.
Seleziona la scheda Informazioni nodo.
Copia l'URI da utilizzare nel passaggio Addestra un modello.
API: Python
Il seguente codice campione mostra come caricare il risultato dell'ottimizzazione degli iperparametri utilizzando l'API. La variabile job si riferisce all'esecuzione precedente della pipeline di addestramento del modello.
def get_task_detail(
task_details: List[Dict[str, Any]], task_name: str
) -> List[Dict[str, Any]]:
for task_detail in task_details:
if task_detail.task_name == task_name:
return task_detail
pipeline_task_details = job.gca_resource.job_detail.task_details
stage_1_tuner_task = get_task_detail(
pipeline_task_details, "automl-forecasting-stage-1-tuner"
)
stage_1_tuning_result_artifact_uri = (
stage_1_tuner_task.outputs["tuning_result_output"].artifacts[0].uri
)
Addestra un modello
Il seguente codice campione mostra come eseguire una pipeline di addestramento del modello:
job = aiplatform.PipelineJob(
...
template_path=template_path,
parameter_values=parameter_values,
...
)
job.run(service_account=SERVICE_ACCOUNT)
Il parametro facoltativo service_account in job.run() ti consente di impostare il account di servizio di Vertex AI Pipelines su un account a tua scelta.
Vertex AI supporta i seguenti metodi per l'addestramento del modello:
Time series Dense Encoder (TiDE). Per utilizzare questo metodo di addestramento del modello, definisci la pipeline e i valori dei parametri utilizzando la seguente funzione:
template_path, parameter_values = automl_forecasting_utils.get_time_series_dense_encoder_forecasting_pipeline_and_parameters(...)Trasformatore di fusione temporale (TFT). Per utilizzare questo metodo di addestramento del modello, definisci la pipeline e i valori dei parametri utilizzando la seguente funzione:
template_path, parameter_values = automl_forecasting_utils.get_temporal_fusion_transformer_forecasting_pipeline_and_parameters(...)AutoML (L2L). Per utilizzare questo metodo di addestramento del modello, definisci la pipeline e i valori dei parametri utilizzando la seguente funzione:
template_path, parameter_values = automl_forecasting_utils.get_learn_to_learn_forecasting_pipeline_and_parameters(...)Seq2Seq+. Per utilizzare questo metodo di addestramento del modello, definisci la pipeline e i valori dei parametri utilizzando la seguente funzione:
template_path, parameter_values = automl_forecasting_utils.get_sequence_to_sequence_forecasting_pipeline_and_parameters(...)
Per scoprire di più, consulta Metodi di addestramento dei modelli.
I dati di addestramento possono essere un file CSV in Cloud Storage o una tabella in BigQuery.
Di seguito è riportato un sottoinsieme di parametri di addestramento del modello:
| Nome parametro | Tipo | Definizione |
|---|---|---|
optimization_objective |
Stringa | Per impostazione predefinita, Vertex AI riduce al minimo l'errore quadratico medio (RMSE). Se vuoi un obiettivo di ottimizzazione diverso per il modello di previsione, scegli una delle opzioni in Obiettivi di ottimizzazione per i modelli di previsione. Se scegli di ridurre al minimo la perdita quantile, devi anche specificare un valore per quantiles. |
enable_probabilistic_inference |
Booleano | Se impostato su true, i modelli Vertex AI modellano la distribuzione di probabilità della previsione. L'inferenza probabilistica può migliorare la qualità del modello gestendo i dati rumorosi e quantificando l'incertezza. Se vengono specificati quantiles, Vertex AI restituisce anche i quantili della distribuzione. L'inferenza probabilistica è compatibile solo con i metodi di addestramento Time series Dense Encoder (TiDE) e AutoML (L2L). L'inferenza probabilistica non è compatibile con l'obiettivo di ottimizzazione minimize-quantile-loss. |
quantiles |
List[float] | Quantili da utilizzare per l'minimize-quantile-lossobiettivo di ottimizzazione e l'inferenza probabilistica. Fornisci un elenco di massimo cinque numeri univoci compresi tra 0 e 1, esclusi. |
time_column |
Stringa | La colonna temporale. Per scoprire di più, consulta la sezione Requisiti della struttura dei dati. |
time_series_identifier_columns |
List[str] | Le colonne identificatore serie temporale. Per scoprire di più, consulta la sezione Requisiti della struttura dei dati. |
weight_column |
Stringa | (Facoltativo) La colonna del peso. Per saperne di più, vedi Aggiungere pesi ai dati di addestramento. |
time_series_attribute_columns |
List[str] | (Facoltativo) Il nome o i nomi delle colonne che sono attributi delle serie temporali. Per saperne di più, consulta Tipo di funzionalità e disponibilità al momento della previsione. |
available_at_forecast_columns |
List[str] | (Facoltativo) Il nome o i nomi delle colonne delle covariate il cui valore è noto al momento della previsione. Per saperne di più, consulta Tipo di funzionalità e disponibilità al momento della previsione. |
unavailable_at_forecast_columns |
List[str] | (Facoltativo) Il nome o i nomi delle colonne delle covariate il cui valore è sconosciuto al momento della previsione. Per saperne di più, consulta Tipo di funzionalità e disponibilità al momento della previsione. |
forecast_horizon |
Numero intero | (Facoltativo) L'orizzonte di previsione determina per quanto lontano nel futuro il modello prevede il valore target per ogni riga di dati di inferenza. Per scoprire di più, consulta Orizzonte di previsione, finestra di contesto e finestra di previsione. |
context_window |
Numero intero | (Facoltativo) La finestra contestuale imposta il periodo di tempo che il modello prende in considerazione durante l'addestramento (e per le previsioni). In altre parole, per ogni punto dati di addestramento, la finestra di contesto determina quanto indietro nel tempo il modello cerca pattern predittivi. Per scoprire di più, consulta Orizzonte di previsione, finestra di contesto e finestra di previsione. |
window_max_count |
Numero intero | (Facoltativo) Vertex AI genera finestre di previsione dai dati di input utilizzando una strategia a finestra mobile. La strategia predefinita è Conteggio. Il valore predefinito per il numero massimo di finestre è 100,000,000. Imposta questo parametro per fornire un valore personalizzato per il numero massimo di finestre. Per scoprire di più, vedi Strategie per le finestre temporali continue. |
window_stride_length |
Numero intero | (Facoltativo) Vertex AI genera finestre di previsione dai dati di input utilizzando una strategia a finestra mobile. Per selezionare la strategia Passo, imposta questo parametro sul valore della lunghezza del passo. Per scoprire di più, vedi Strategie per le finestre temporali continue. |
window_predefined_column |
Stringa | (Facoltativo) Vertex AI genera finestre di previsione dai dati di input utilizzando una strategia a finestra mobile. Per selezionare la strategia Colonna, imposta questo parametro sul nome della colonna con valori True o False. Per scoprire di più, vedi Strategie per le finestre temporali continue. |
holiday_regions |
List[str] | (Facoltativo) Puoi selezionare una o più regioni geografiche per attivare la modellazione dell'effetto festività. Durante l'addestramento, Vertex AI crea funzionalità categoriche per le festività all'interno del modello in base alla data di time_column e alle regioni geografiche specificate. Per impostazione predefinita, la modellazione dell'effetto festività è disattivata. Per saperne di più, consulta Regioni delle festività. |
predefined_split_key |
Stringa | (Facoltativo) Per impostazione predefinita, Vertex AI utilizza un algoritmo di suddivisione cronologica per separare i dati di previsione nelle tre suddivisioni di dati. Se vuoi controllare quali righe di dati di addestramento vengono utilizzate per quale suddivisione, fornisci il nome della colonna contenente i valori di suddivisione dei dati (TRAIN, VALIDATION, TEST). Per saperne di più, consulta Suddivisioni dei dati per la previsione. |
training_fraction |
Numero in virgola mobile | (Facoltativo) Per impostazione predefinita, Vertex AI utilizza un algoritmo di suddivisione cronologica per separare i dati di previsione nelle tre suddivisioni di dati. L'80% dei dati viene assegnato al set di addestramento, il 10% alla suddivisione di convalida e il 10% alla suddivisione di test. Imposta questo parametro se vuoi personalizzare la frazione di dati assegnata al set di addestramento. Per scoprire di più, consulta la sezione Divisioni dei dati per le previsioni. |
validation_fraction |
Numero in virgola mobile | (Facoltativo) Per impostazione predefinita, Vertex AI utilizza un algoritmo di suddivisione cronologica per separare i dati di previsione nelle tre suddivisioni di dati. L'80% dei dati viene assegnato al set di addestramento, il 10% alla suddivisione di convalida e il 10% alla suddivisione di test. Imposta questo parametro se vuoi personalizzare la frazione dei dati assegnata al set di convalida. Per scoprire di più, consulta la sezione Divisioni dei dati per le previsioni. |
test_fraction |
Numero in virgola mobile | (Facoltativo) Per impostazione predefinita, Vertex AI utilizza un algoritmo di suddivisione cronologica per separare i dati di previsione nelle tre suddivisioni di dati. L'80% dei dati viene assegnato al set di addestramento, il 10% alla suddivisione di convalida e il 10% alla suddivisione di test. Imposta questo parametro se vuoi personalizzare la frazione dei dati assegnata al set di test. Per scoprire di più, consulta la sezione Divisioni dei dati per le previsioni. |
data_source_csv_filenames |
Stringa | Un URI per un file CSV archiviato in Cloud Storage. |
data_source_bigquery_table_path |
Stringa | Un URI per una tabella BigQuery. |
dataflow_service_account |
Stringa | (Facoltativo) account di servizio personalizzato per eseguire i job Dataflow. Puoi configurare il job Dataflow in modo che utilizzi IP privati e una subnet VPC specifica. Questo parametro funge da override per il account di servizio worker Dataflow predefinito. |
run_evaluation |
Booleano | Se impostato su True, Vertex AI valuta il modello di ensemble sulla suddivisione di test. |
evaluated_examples_bigquery_path |
Stringa | Il percorso del set di dati BigQuery utilizzato durante la valutazione del modello. Il set di dati funge da destinazione per gli esempi previsti. Devi impostare il valore parametro se run_evaluation è impostato su True e deve avere il seguente formato: bq://[PROJECT].[DATASET]. |
Trasformazioni
Puoi fornire una mappatura del dizionario delle risoluzioni automatiche o di tipo alle colonne delle funzionalità. I tipi supportati sono: automatico, numerico, categorico, testo e timestamp.
| Nome parametro | Tipo | Definizione |
|---|---|---|
transformations |
Dict[str, List[str]] | Mappatura del dizionario delle risoluzioni automatiche o di tipo |
Il seguente codice fornisce una funzione helper per compilare il parametro transformations. Mostra anche come utilizzare questa funzione per applicare trasformazioni automatiche
a un insieme di colonne definito da una variabile features.
def generate_transformation(
auto_column_names: Optional[List[str]]=None,
numeric_column_names: Optional[List[str]]=None,
categorical_column_names: Optional[List[str]]=None,
text_column_names: Optional[List[str]]=None,
timestamp_column_names: Optional[List[str]]=None,
) -> List[Dict[str, Any]]:
if auto_column_names is None:
auto_column_names = []
if numeric_column_names is None:
numeric_column_names = []
if categorical_column_names is None:
categorical_column_names = []
if text_column_names is None:
text_column_names = []
if timestamp_column_names is None:
timestamp_column_names = []
return {
"auto": auto_column_names,
"numeric": numeric_column_names,
"categorical": categorical_column_names,
"text": text_column_names,
"timestamp": timestamp_column_names,
}
transformations = generate_transformation(auto_column_names=features)
Per saperne di più sulle trasformazioni, vedi Tipi di dati e trasformazioni.
Opzioni di personalizzazione del flusso di lavoro
Puoi personalizzare il workflow tabulare per la previsione definendo i valori degli argomenti che vengono passati durante la definizione della pipeline. Puoi personalizzare il tuo workflow nei seguenti modi:
- Configura hardware
- Salta ricerca architettura
Configurare l'hardware
Il seguente parametro di addestramento del modello ti consente di configurare i tipi di macchine e il numero di macchine per l'addestramento. Questa opzione è una buona scelta se hai un set di dati di grandi dimensioni e vuoi ottimizzare l'hardware della macchina di conseguenza.
| Nome parametro | Tipo | Definizione |
|---|---|---|
stage_1_tuner_worker_pool_specs_override |
Dict[String, Any] | (Facoltativo) Configurazione personalizzata dei tipi di macchine e del numero di macchine per l'addestramento. Questo parametro configura il componente automl-forecasting-stage-1-tuner della pipeline. |
Il seguente codice mostra come impostare il tipo di macchina n1-standard-8 per il nodo principale TensorFlow e il tipo di macchina n1-standard-4 per il nodo di valutazione TensorFlow:
worker_pool_specs_override = [
{"machine_spec": {"machine_type": "n1-standard-8"}}, # override for TF chief node
{}, # override for TF worker node, since it's not used, leave it empty
{}, # override for TF ps node, since it's not used, leave it empty
{
"machine_spec": {
"machine_type": "n1-standard-4" # override for TF evaluator node
}
}
]
Salta ricerca architettura
Il seguente parametro di addestramento del modello ti consente di eseguire la pipeline senza la ricerca dell'architettura e di fornire un insieme di iperparametri da un'esecuzione precedente della pipeline.
| Nome parametro | Tipo | Definizione |
|---|---|---|
stage_1_tuning_result_artifact_uri |
Stringa | (Facoltativo) URI del risultato dell'ottimizzazione degli iperparametri di un'esecuzione della pipeline precedente. |
Passaggi successivi
- Scopri di più sulle inferenze batch per i modelli di previsione.
- Scopri di più sui prezzi per l'addestramento dei modelli.