このページでは、予測用の表形式ワークフローを使用して、表形式のデータセットから予測モデルをトレーニングする方法について説明します。
このワークフローで使用されるサービス アカウントについては、表形式ワークフローのサービス アカウントをご覧ください。
予測用の表形式のワークフローを実行するときに、割り当てエラーが発生した場合、割り当ての増加をリクエストすることが必要になる可能性があります。詳細については、表形式のワークフローの割り当てを管理するをご覧ください。
予測用の表形式のワークフローでは、モデルのエクスポートはサポートされていません。
ワークフローの API
このワークフローでは、次の API を使用します。
- Vertex AI
- Dataflow
- Compute Engine
- Cloud Storage
以前のハイパーパラメータ チューニング結果の URI を取得する
予測用の表形式ワークフローをすでに実行している場合は、前回の実行のハイパーパラメータ チューニング結果を使用して、トレーニングの時間とリソースを節約できます。以前のハイパーパラメータ チューニングの結果を確認するには、 Google Cloud コンソールを使用するか、API を使用してプログラムで結果を読み込みます。
Google Cloud コンソール
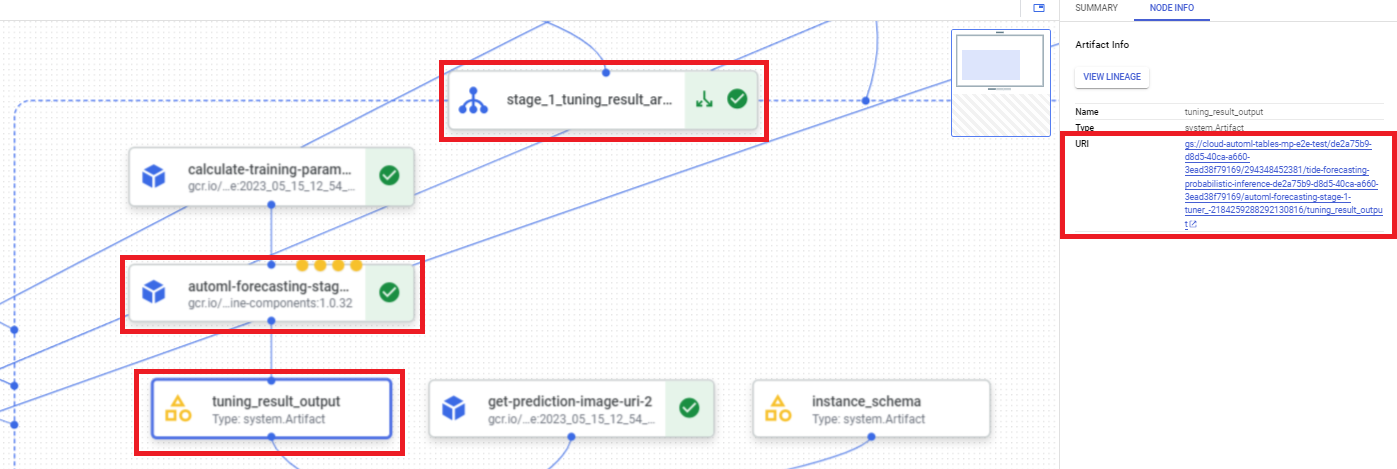
Google Cloud コンソールでハイパーパラメータ チューニングの結果の URI を確認するには、次の操作を行います。
Google Cloud コンソールの [Vertex AI] セクションで、[パイプライン] ページに移動します。
[実行] タブを選択します。
使用するパイプライン実行を選択します。
[Expand Artifacts] を選択します。
コンポーネント exit-handler-1 をクリックします。
コンポーネント stage_1_tuning_result_artifact_uri_empty をクリックします。
コンポーネント automl-forecasting-stage-1-tuner を見つけます。
関連付けられているアーティファクト tuning_result_output をクリックします。
[ノード情報] タブを選択します。
モデルのトレーニング手順で使用する URI をコピーします。
API: Python
次のサンプルコードは、API を使用してハイパーパラメータ チューニングの結果を読み込む方法を示しています。変数 job は、前のモデル トレーニング パイプラインの実行を指しています。
def get_task_detail(
task_details: List[Dict[str, Any]], task_name: str
) -> List[Dict[str, Any]]:
for task_detail in task_details:
if task_detail.task_name == task_name:
return task_detail
pipeline_task_details = job.gca_resource.job_detail.task_details
stage_1_tuner_task = get_task_detail(
pipeline_task_details, "automl-forecasting-stage-1-tuner"
)
stage_1_tuning_result_artifact_uri = (
stage_1_tuner_task.outputs["tuning_result_output"].artifacts[0].uri
)
モデルをトレーニングする
次のサンプルコードは、モデル トレーニング パイプラインの実行方法を示しています。
job = aiplatform.PipelineJob(
...
template_path=template_path,
parameter_values=parameter_values,
...
)
job.run(service_account=SERVICE_ACCOUNT)
job.run() でオプションの service_account パラメータを使用すると、Vertex AI Pipelines サービス アカウントを任意のアカウントに設定できます。
Vertex AI は、モデルのトレーニング用に次のメソッドをサポートしています。
時系列高密度エンコーダ(TiDE)。このモデル トレーニング メソッドを使用するには、次の関数を使用してパイプラインとパラメータ値を定義します。
template_path, parameter_values = automl_forecasting_utils.get_time_series_dense_encoder_forecasting_pipeline_and_parameters(...)Temporal Fusion Transformer(TFT)。このモデル トレーニング メソッドを使用するには、次の関数を使用してパイプラインとパラメータ値を定義します。
template_path, parameter_values = automl_forecasting_utils.get_temporal_fusion_transformer_forecasting_pipeline_and_parameters(...)AutoML(L2L)。このモデル トレーニング メソッドを使用するには、次の関数を使用してパイプラインとパラメータ値を定義します。
template_path, parameter_values = automl_forecasting_utils.get_learn_to_learn_forecasting_pipeline_and_parameters(...)Seq2Seq+。このモデル トレーニング メソッドを使用するには、次の関数を使用してパイプラインとパラメータ値を定義します。
template_path, parameter_values = automl_forecasting_utils.get_sequence_to_sequence_forecasting_pipeline_and_parameters(...)
詳細については、モデルのトレーニング方法をご覧ください。
トレーニング データは、Cloud Storage の CSV ファイルか、BigQuery のテーブルのいずれかです。
以下に示すのは、モデルのトレーニング パラメータの一部です。
| パラメータ名 | 型 | 定義 |
|---|---|---|
optimization_objective |
文字列 | デフォルトでは、Vertex AI は二乗平均平方根誤差(RMSE)を最小化します。予測モデルに対して別の最適化目標が必要な場合は、予測モデルの最適化目標のいずれかのオプションを選択します。分位点損失を最小限に抑える場合は、quantiles の値も指定する必要があります。 |
enable_probabilistic_inference |
ブール値 | true に設定すると、Vertex AI は予測の確率分布をモデル化します。確率的推論により、ノイズの多いデータを処理し、不確実性を定量化することで、モデルの品質を改善できます。quantiles を指定すると、Vertex AI により分布の分位数も返されます。確率的推論は、時系列高密度エンコーダ(TiDE)と AutoML(L2L)のトレーニング方法のみとの互換性があります。確率的推論は、minimize-quantile-loss の最適化目標に対応していません。 |
quantiles |
List[float] | minimize-quantile-loss の最適化目標と確率論的推論に使用する分位数。最大 5 つの一意の数字を 0~1 の範囲(両端を除く)で指定します。 |
time_column |
文字列 | 時間列。詳しくは、データ構造の要件をご覧ください。 |
time_series_identifier_columns |
List[str] | 時系列識別子の列。詳しくは、データ構造の要件をご覧ください。 |
weight_column |
文字列 | (省略可)重み列。詳細については、トレーニング データに重みを追加するをご覧ください。 |
time_series_attribute_columns |
List[str] | (省略可)時系列属性である列の名前。詳細については、特徴タイプと予測時の利用可能性をご覧ください。 |
available_at_forecast_columns |
List[str] | (省略可)予測時に値がわかっている共変量列の名前。詳細については、特徴タイプと予測時の利用可能性をご覧ください。 |
unavailable_at_forecast_columns |
List[str] | (省略可)予測時に値が不明な共変量列の名前。詳細については、特徴タイプと予測時の利用可能性をご覧ください。 |
forecast_horizon |
整数 | (省略可)予測ホライズンでは、推論データの各行のターゲット値について、モデルがどの程度の未来の期間を予測するかを決定します。詳細については、予測ホライズン、コンテキスト ウィンドウ、予測ウィンドウをご覧ください。 |
context_window |
整数 | (省略可)コンテキスト ウィンドウでは、トレーニング時(および予測用)にモデルのルックバック期間を設定します。つまり、各トレーニング データポイントにおいて、コンテキスト ウィンドウの設定によって、モデルが予測パターンをどの程度の期間さかのぼるかが決まります。詳細については、予測ホライズン、コンテキスト ウィンドウ、予測ウィンドウをご覧ください。 |
window_max_count |
Integer | (省略可)Vertex AI は、ローリング ウィンドウ戦略を使用して、入力データから予測ウィンドウを生成します。デフォルトの戦略は [カウント] です。最大ウィンドウ数のデフォルト値は 100,000,000 です。このパラメータを設定して、ウィンドウの最大数にカスタム値を指定します。詳細については、ローリング ウィンドウ戦略をご覧ください。 |
window_stride_length |
Integer | (省略可)Vertex AI は、ローリング ウィンドウ戦略を使用して、入力データから予測ウィンドウを生成します。ストライド戦略を選択するには、このパラメータをストライドの長さに設定します。詳細については、ローリング ウィンドウ戦略をご覧ください。 |
window_predefined_column |
文字列 | (省略可)Vertex AI は、ローリング ウィンドウ戦略を使用して、入力データから予測ウィンドウを生成します。列戦略を選択するには、このパラメータを True 値または False 値を持つ列の名前に設定します。詳細については、ローリング ウィンドウ戦略をご覧ください。 |
holiday_regions |
List[str] | (オプション) 1 つ以上の地域を選択して、休日効果モデリングを有効にできます。トレーニング中に、Vertex AI は time_column の日付と指定された地理的地域に基づいて、モデル内に休日のカテゴリ特徴を作成します。デフォルトでは、休日効果のモデリングは無効になっています。詳しくは、地域の休日をご覧ください。 |
predefined_split_key |
文字列 | (省略可)デフォルトでは、Vertex AI は時系列分割アルゴリズムを使用して、予測データを 3 つのデータ分割に分割します。どのトレーニング データ行をどの分割に使用するかをコントロールするには、データ分割の値を含む列の名前(TRAIN、VALIDATION、TEST)を指定します。詳しくは、予測のためのデータ分割をご覧ください。 |
training_fraction |
Float | (省略可)デフォルトでは、Vertex AI は時系列分割アルゴリズムを使用して、予測データを 3 つのデータ分割に分割します。データの 80% がトレーニング セットに、10% が検証分割に、10% はテスト分割に割り当てられます。このパラメータは、トレーニング セットに割り当てられるデータの割合をカスタマイズする場合に設定します。詳細については、予測のためのデータ分割をご覧ください。 |
validation_fraction |
Float | (省略可)デフォルトでは、Vertex AI は時系列分割アルゴリズムを使用して、予測データを 3 つのデータ分割に分割します。データの 80% がトレーニング セットに、10% が検証分割に、10% はテスト分割に割り当てられます。このパラメータは、検証セットに割り当てられるデータの割合をカスタマイズする場合に設定します。詳細については、予測のためのデータ分割をご覧ください。 |
test_fraction |
Float | (省略可)デフォルトでは、Vertex AI は時系列分割アルゴリズムを使用して、予測データを 3 つのデータ分割に分割します。データの 80% がトレーニング セットに、10% が検証分割に、10% はテスト分割に割り当てられます。このパラメータは、テストセットに割り当てられるデータの割合をカスタマイズする場合に設定します。詳細については、予測のためのデータ分割をご覧ください。 |
data_source_csv_filenames |
文字列 | Cloud Storage に保存されている CSV の URI。 |
data_source_bigquery_table_path |
文字列 | BigQuery テーブルの URI。 |
dataflow_service_account |
文字列 | (省略可)Dataflow ジョブを実行するカスタム サービス アカウント。プライベート IP と特定の VPC サブネットを使用するように Dataflow ジョブを構成できます。このパラメータは、デフォルトの Dataflow ワーカー サービス アカウントのオーバーライドとして機能します。 |
run_evaluation |
ブール値 | True に設定すると、Vertex AI はテスト分割でアンサンブル モデルを評価します。 |
evaluated_examples_bigquery_path |
文字列 | モデル評価中に使用される BigQuery データセットのパス。このデータセットは、予測サンプルの格納先として機能します。run_evaluation が True に設定されている場合、パラメータの値は bq://[PROJECT].[DATASET] の形式にする必要があります。 |
変換
自動解決または型解決の辞書マッピングを特徴列に提供できます。サポートされているタイプは、auto、numeric、categorical、text、timestamp です。
| パラメータ名 | 型 | 定義 |
|---|---|---|
transformations |
Dict[str, List[str]] | 自動解決または型解決の辞書マッピング |
次のコードは、transformations パラメータを入力するためのヘルパー関数を示しています。また、この関数を使用して、features 変数で定義された列のセットに自動変換を適用する方法も示しています。
def generate_transformation(
auto_column_names: Optional[List[str]]=None,
numeric_column_names: Optional[List[str]]=None,
categorical_column_names: Optional[List[str]]=None,
text_column_names: Optional[List[str]]=None,
timestamp_column_names: Optional[List[str]]=None,
) -> List[Dict[str, Any]]:
if auto_column_names is None:
auto_column_names = []
if numeric_column_names is None:
numeric_column_names = []
if categorical_column_names is None:
categorical_column_names = []
if text_column_names is None:
text_column_names = []
if timestamp_column_names is None:
timestamp_column_names = []
return {
"auto": auto_column_names,
"numeric": numeric_column_names,
"categorical": categorical_column_names,
"text": text_column_names,
"timestamp": timestamp_column_names,
}
transformations = generate_transformation(auto_column_names=features)
変換の詳細については、データ型と変換をご覧ください。
ワークフローのカスタマイズ オプション
パイプラインの定義時に渡される引数値を定義することで、予測の表形式ワークフローをカスタマイズできます。ワークフローは次の方法でカスタマイズできます。
- ハードウェアを構成する
- アーキテクチャ検索をスキップする
ハードウェアを構成する
次のモデル トレーニング パラメータを使用すると、トレーニング用のマシンタイプとマシン数を構成できます。このオプションは、大規模なデータセットがあり、それに応じてマシンのハードウェアを最適化したい場合に適しています。
| パラメータ名 | 型 | 定義 |
|---|---|---|
stage_1_tuner_worker_pool_specs_override |
Dict[String, Any] | (省略可)トレーニング用のマシンタイプとマシン数のカスタム構成。このパラメータは、パイプラインの automl-forecasting-stage-1-tuner コンポーネントを構成します。 |
次のコードは、TensorFlow チーフノードに n1-standard-8 マシンタイプを設定し、TensorFlow エバリュエータ ノードに n1-standard-4 マシンタイプを設定する方法を示しています。
worker_pool_specs_override = [
{"machine_spec": {"machine_type": "n1-standard-8"}}, # override for TF chief node
{}, # override for TF worker node, since it's not used, leave it empty
{}, # override for TF ps node, since it's not used, leave it empty
{
"machine_spec": {
"machine_type": "n1-standard-4" # override for TF evaluator node
}
}
]
アーキテクチャ検索をスキップする
次のモデル トレーニング パラメータを使用すると、アーキテクチャ検索なしでパイプラインを実行し、前回のパイプライン実行からのハイパーパラメータのセットを指定できます。
| パラメータ名 | 型 | 定義 |
|---|---|---|
stage_1_tuning_result_artifact_uri |
文字列 | (省略可)前回のパイプライン実行のハイパーパラメータ チューニング結果の URI。 |
次のステップ
- 予測モデルのバッチ予測について確認する。
- モデル トレーニングの料金について確認する。