O Vertex AI oferece duas opções para projetar valores futuros através do seu modelo de previsão preparado: inferências online e inferências em lote.
Uma inferência online é um pedido síncrono. Use inferências online quando fizer pedidos em resposta à entrada da aplicação ou noutras situações em que precisa de inferência atempada.
Um pedido de inferência em lote é um pedido assíncrono. Use a inferência em lote quando não precisar de uma resposta imediata e quiser processar dados acumulados usando um único pedido.
Esta página mostra como projetar valores futuros usando inferências em lote. Para saber como projetar valores usando inferências online, consulte o artigo Obtenha inferências online para um modelo de previsão.
Pode pedir inferências em lote diretamente a partir do recurso do modelo.
Pode pedir uma inferência com explicações (também denominadas atribuições de funcionalidades) para ver como o modelo chegou a uma inferência. Os valores de importância das funcionalidades locais indicam a contribuição de cada funcionalidade para o resultado da inferência. Para uma vista geral conceptual, consulte o artigo Atribuições de funcionalidades para a previsão.
Para saber mais sobre os preços das inferências em lote, consulte o artigo Preços dos fluxos de trabalho tabulares.
Antes de começar
Antes de fazer um pedido de inferência em lote, primeiro forme um modelo.
Dados de entrada
Os dados de entrada para pedidos de inferência em lote são os dados que o seu modelo usa para criar previsões. Pode fornecer dados de entrada num de dois formatos:
- Objetos CSV no Cloud Storage
- Tabelas do BigQuery
Recomendamos que use o mesmo formato para os dados de entrada que usou para formar o modelo. Por exemplo, se tiver preparado o modelo com dados no BigQuery, é melhor usar uma tabela do BigQuery como entrada para a inferência em lote. Uma vez que o Vertex AI trata todos os campos de entrada CSV como strings, a mistura de formatos de dados de entrada e de preparação pode causar erros.
A sua origem de dados tem de conter dados tabulares que incluam todas as colunas, por qualquer ordem, que foram usadas para preparar o modelo. Pode incluir colunas que não estavam nos dados de preparação ou que estavam nos dados de preparação, mas foram excluídas da utilização para preparação. Estas colunas adicionais estão incluídas na saída, mas não afetam os resultados de previsões.
Requisitos de dados de entrada
A entrada para modelos de previsão tem de cumprir os seguintes requisitos:
- Todos os valores na coluna de tempo têm de estar presentes e ser válidos.
- Todas as colunas usadas no seu pedido de inferência têm de estar presentes nos dados de entrada. Quando as colunas estão vazias ou não existem, o Vertex AI preenche os dados automaticamente.
- A frequência dos dados de entrada e dos dados de preparação tem de corresponder. Se existirem linhas em falta na série cronológica, tem de as inserir manualmente de acordo com os conhecimentos do domínio adequados.
- As séries cronológicas com indicações de tempo duplicadas são removidas das inferências. Para as incluir, remova as indicações de tempo duplicadas.
- Disponibilize dados do histórico para cada série cronológica a prever. Para ter previsões mais precisas, a quantidade de dados deve ser igual à janela de contexto, que é definida durante a preparação do modelo. Por exemplo, se o período de contexto for de 14 dias, forneça, pelo menos, 14 dias de dados do histórico. Se fornecer menos dados, o Vertex AI preenche os dados com valores vazios.
- A previsão começa na primeira linha de uma série cronológica (ordenada por tempo)
com um valor nulo na coluna de destino. O valor nulo tem de ser contínuo
na série cronológica. Por exemplo, se a coluna de destino estiver ordenada por tempo, não pode ter algo como
1,2,null,3,4,null,nullpara uma única série cronológica. Para ficheiros CSV, o Vertex AI trata uma string vazia como nula e, para o BigQuery, os valores nulos são suportados nativamente.
tabela do BigQuery
Se escolher uma tabela do BigQuery como entrada, tem de garantir o seguinte:
- As tabelas de origem de dados do BigQuery não podem ter mais de 100 GB.
- Se a tabela estiver num projeto diferente, tem de conceder a função
BigQuery Data Editorà conta de serviço do Vertex AI nesse projeto.
Ficheiro CSV
Se escolher um objeto CSV no Cloud Storage como entrada, tem de garantir o seguinte:
- A origem de dados tem de começar com uma linha de cabeçalho com os nomes das colunas.
- Cada objeto de origem de dados não pode ter mais de 10 GB. Pode incluir vários ficheiros, até um máximo de 100 GB.
- Se o contentor do Cloud Storage estiver num projeto diferente, tem de conceder a função
Storage Object Creatorà conta de serviço do Vertex AI nesse projeto. - Tem de colocar todas as strings entre aspas duplas (").
Formato de saída
O formato de saída do seu pedido de inferência em lote não tem de ser igual ao formato de entrada. Por exemplo, se usar uma tabela do BigQuery como entrada, pode gerar resultados de previsão num objeto CSV no Cloud Storage.
Faça um pedido de inferência em lote ao seu modelo
Para fazer pedidos de inferência em lote, pode usar a Google Cloud consola ou a API Vertex AI. A origem de dados de entrada pode ser objetos CSV armazenados num contentor do Cloud Storage ou tabelas do BigQuery. Consoante a quantidade de dados que enviar como entrada, uma tarefa de inferência em lote pode demorar algum tempo a ser concluída.
Google Cloud consola
Use a Google Cloud consola para pedir uma inferência em lote.
- Na Google Cloud consola, na secção Vertex AI, aceda à página Inferências em lote.
- Clique em Criar para abrir a janela Nova inferência em lote.
- Para Definir a inferência em lote, conclua os seguintes passos:
- Introduza um nome para a inferência em lote.
- Para Nome do modelo, selecione o nome do modelo a usar para esta inferência em lote.
- Para Versão, selecione a versão do modelo.
- Em Selecionar origem, selecione se os dados de entrada de origem são um ficheiro CSV no Cloud Storage ou uma tabela no BigQuery.
- Para ficheiros CSV, especifique a localização do Google Cloud Storage onde se encontra o ficheiro de entrada CSV.
- Para tabelas do BigQuery, especifique o ID do projeto onde a tabela está localizada, o ID do conjunto de dados do BigQuery e o ID da tabela ou da vista do BigQuery.
- Para Resultado da inferência em lote, selecione CSV ou BigQuery.
- Para CSV, especifique o contentor do Cloud Storage onde o Vertex AI armazena o resultado.
- Para o BigQuery, pode especificar um ID do projeto ou um conjunto de dados existente:
- Para especificar o ID do projeto, introduza-o no campo ID do projeto do Google Cloud. O Vertex AI cria um novo conjunto de dados de saída para si.
- Para especificar um conjunto de dados existente, introduza o respetivo caminho do BigQuery
no campo ID do projeto do Google Cloud, como
bq://projectid.datasetid.
- Opcional. Se o destino de saída for o BigQuery ou o JSONL no Cloud Storage, pode ativar as atribuições de funcionalidades, além das inferências. Para o fazer, selecione Ativar atribuições de funcionalidades para este modelo. As atribuições de funcionalidades não são suportadas para CSV no armazenamento na nuvem. Saiba mais.
- Opcional: a monitorização de modelos
para inferências em lote está disponível na pré-visualização. Consulte os
Pré-requisitos
para adicionar a configuração de deteção de desvios à sua tarefa de inferência em lote.
- Clique para ativar/desativar a opção Ativar monitorização do modelo para esta inferência em lote.
- Selecione uma origem de dados de preparação. Introduza o caminho ou a localização dos dados para a origem de dados de preparação que selecionou.
- Opcional: em Limites de alerta, especifique os limites nos quais os alertas devem ser acionados.
- Para Emails de notificação, introduza um ou mais endereços de email separados por vírgulas para receber alertas quando um modelo exceder um limite de alerta.
- Opcional: para Canais de notificação, adicione canais do Cloud Monitoring para receber alertas quando um modelo exceder um limite de alerta. Pode selecionar canais do Cloud Monitoring existentes ou criar um novo clicando em Gerir canais de notificação. A consola suporta canais de notificação do PagerDuty, Slack e Pub/Sub.
- Clique em Criar.
API : BigQuery
REST
Use o método batchPredictionJobs.create para pedir uma inferência em lote.
Antes de usar qualquer um dos dados do pedido, faça as seguintes substituições:
- LOCATION_ID: região onde o modelo é armazenado e a tarefa de inferência em lote é executada. Por exemplo,
us-central1. - PROJECT_ID: o seu ID do projeto
- BATCH_JOB_NAME: nome a apresentar para a tarefa em lote
- MODEL_ID: o ID do modelo a usar para fazer inferências
-
INPUT_URI: Referência à origem de dados do BigQuery. No formulário:
bq://bqprojectId.bqDatasetId.bqTableId
-
OUTPUT_URI: referência ao destino do BigQuery (onde as inferências são escritas). Especifique o ID do projeto e, opcionalmente,
um ID do conjunto de dados existente. Use o seguinte formulário:
bq://bqprojectId.bqDatasetId
bq://bqprojectId
- GENERATE_EXPLANATION: o valor predefinido é false. Defina como true para ativar as atribuições de funcionalidades. Para saber mais, consulte o artigo Atribuições de funcionalidades para previsões.
Método HTTP e URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
Corpo JSON do pedido:
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": "OUTPUT_URI"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
Para enviar o seu pedido, escolha uma destas opções:
curl
Guarde o corpo do pedido num ficheiro com o nome request.json,
e execute o seguinte comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
Guarde o corpo do pedido num ficheiro com o nome request.json,
e execute o seguinte comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
Deve receber uma resposta JSON semelhante à seguinte:
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": bq://12345
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
},
"manualBatchTuningParameters": {
"batchSize": 4
},
"outputInfo": {
"bigqueryOutputDataset": "bq://12345.reg_model_2020_10_02_06_04
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Java
Antes de experimentar este exemplo, siga as Javainstruções de configuração no início rápido do Vertex AI com bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API Java Vertex AI.
Para se autenticar no Vertex AI, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
No exemplo seguinte, substitua INSTANCES_FORMAT e PREDICTIONS_FORMAT por "bigquery". Para saber como substituir os outros marcadores de posição, consulte o separador "REST & CMD LINE" desta secção.Python
Para saber como instalar ou atualizar o SDK Vertex AI para Python, consulte o artigo Instale o SDK Vertex AI para Python. Para mais informações, consulte a Python documentação de referência da API.
API : Cloud Storage
REST
Use o método batchPredictionJobs.create para pedir uma inferência em lote.
Antes de usar qualquer um dos dados do pedido, faça as seguintes substituições:
- LOCATION_ID: região onde o modelo é armazenado e a tarefa de inferência em lote é executada. Por exemplo,
us-central1. - PROJECT_ID:
- BATCH_JOB_NAME: nome a apresentar para a tarefa em lote
- MODEL_ID: o ID do modelo a usar para fazer inferências
-
URI: caminhos (URIs) para os contentores do Cloud Storage que contêm os dados de preparação.
Pode haver mais do que um. Cada URI tem o formato:
gs://bucketName/pathToFileName
-
OUTPUT_URI_PREFIX: caminho para um destino do Cloud Storage onde as inferências vão ser escritas. O Vertex AI escreve inferências em lote num subdiretório com indicação de data/hora
deste caminho. Defina este valor como uma string com o seguinte formato:
gs://bucketName/pathToOutputDirectory
- GENERATE_EXPLANATION: o valor predefinido é false. Defina como true para ativar as atribuições de funcionalidades. Esta opção só está disponível se o destino de saída for JSONL. As atribuições de funcionalidades não são suportadas para CSV no armazenamento na nuvem. Para saber mais, consulte o artigo Atribuições de funcionalidades para previsões.
Método HTTP e URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
Corpo JSON do pedido:
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
URI1,...
]
},
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
Para enviar o seu pedido, escolha uma destas opções:
curl
Guarde o corpo do pedido num ficheiro com o nome request.json,
e execute o seguinte comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
Guarde o corpo do pedido num ficheiro com o nome request.json,
e execute o seguinte comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
Deve receber uma resposta JSON semelhante à seguinte:
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
"gs://bp_bucket/reg_mode_test"
]
}
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
}
"outputInfo": {
"gcsOutputDataset": "OUTPUT_URI_PREFIX/prediction-batch_job_1 202005291958-2020-09-30T02:58:44.341643Z"
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Python
Para saber como instalar ou atualizar o SDK Vertex AI para Python, consulte o artigo Instale o SDK Vertex AI para Python. Para mais informações, consulte a Python documentação de referência da API.
Obtenha resultados da inferência em lote
O Vertex AI envia o resultado das inferências em lote para o destino que especificou, que pode ser o BigQuery ou o Cloud Storage.
A saída do Cloud Storage para atribuições de funcionalidades não é suportada.
BigQuery
Conjunto de dados de saída
Se estiver a usar o BigQuery, o resultado da inferência em lote é armazenado num conjunto de dados de saída. Se tiver fornecido um conjunto de dados ao Vertex AI, o nome do conjunto de dados (BQ_DATASET_NAME) é o nome que forneceu anteriormente. Se não forneceu um conjunto de dados de saída, o Vertex AI criou um para si. Pode encontrar o nome do dispositivo (BQ_DATASET_NAME) através dos seguintes passos:
- Na Google Cloud consola, aceda à página Inferências em lote do Vertex AI.
- Selecione a inferência que criou.
-
O conjunto de dados de saída é fornecido em Localização de exportação. O nome do conjunto de dados é
formatado da seguinte forma:
prediction_MODEL_NAME_TIMESTAMP
Tabelas de resultados
O conjunto de dados de saída contém uma ou mais das seguintes três tabelas de saída:
-
Tabela de inferência
Esta tabela contém uma linha para cada linha nos seus dados de entrada em que foi pedida uma inferência (ou seja, em que TARGET_COLUMN_NAME = null). Por exemplo, se a sua entrada incluiu 14 entradas nulas para a coluna de destino (como as vendas para os próximos 14 dias), o seu pedido de inferência devolve 14 linhas, o número de vendas para cada dia. Se o seu pedido de previsão exceder o horizonte de previsão do modelo, o Vertex AI devolve apenas previsões até ao horizonte de previsão.
-
Tabela de validação de erros
Esta tabela contém uma linha para cada erro não crítico encontrado durante a fase de agregação que ocorre antes da inferência em lote. Cada erro não crítico corresponde a uma linha nos dados de entrada para a qual o Vertex AI não conseguiu devolver uma previsão.
-
Tabela de erros
Esta tabela contém uma linha para cada erro não crítico encontrado durante a inferência em lote. Cada erro não crítico corresponde a uma linha nos dados de entrada para a qual o Vertex AI não conseguiu devolver uma previsão.
Tabela de previsões
O nome da tabela (BQ_PREDICTIONS_TABLE_NAME) é formado pela
adição de `predictions_` com a data/hora em que a tarefa de inferência em lote
foi iniciada: predictions_TIMESTAMP
Para obter a tabela de inferências:
-
Na consola, aceda à página do BigQuery.
Aceda ao BigQuery -
Execute a seguinte consulta:
SELECT * FROM BQ_DATASET_NAME.BQ_PREDICTIONS_TABLE_NAME
O Vertex AI armazena inferências na coluna predicted_TARGET_COLUMN_NAME.value.
Se formou um modelo
com o Temporal Fusion Transformer (TFT), pode encontrar o resultado da interpretabilidade do TFT na coluna
predicted_TARGET_COLUMN_NAME.tft_feature_importance.
Esta coluna está ainda dividida no seguinte:
context_columns: funcionalidades de previsão cujos valores da janela de contexto servem como entradas para o codificador de memória a curto/longo prazo (LSTM) do TFT.context_weights: os pesos de importância das funcionalidades associados a cada um doscontext_columnspara a instância prevista.horizon_columns: funcionalidades de previsão cujos valores do horizonte de previsão servem de entradas para o descodificador de memória a curto/longo prazo (LSTM) da TFT.horizon_weights: os pesos de importância das funcionalidades associados a cada um doshorizon_columnspara a instância prevista.attribute_columns: funcionalidades de previsão que são invariantes no tempo.attribute_weights: os pesos associados a cada um dosattribute_columns.
Se o seu modelo estiver
otimizado para a perda de quantis e o seu conjunto de quantis incluir a mediana,
predicted_TARGET_COLUMN_NAME.value é o valor de inferência na
mediana. Caso contrário, predicted_TARGET_COLUMN_NAME.value é o valor de inferência no quantil mais baixo do conjunto. Por exemplo, se o seu conjunto de quantis for [0.1, 0.5, 0.9], value é a inferência para o quantil 0.5.
Se o seu conjunto de quantis for [0.1, 0.9], value é a inferência para o quantil 0.1.
Além disso, o Vertex AI armazena valores de quantis e inferências nas seguintes colunas:
-
predicted_TARGET_COLUMN_NAME.quantile_values: os valores dos quantis, que são definidos durante a preparação do modelo. Por exemplo, podem ser0.1,0.5e0.9. -
predicted_TARGET_COLUMN_NAME.quantile_predictions: os valores de inferência associados aos valores dos quantis.
Se o seu modelo usar inferência probabilística,
predicted_TARGET_COLUMN_NAME.value contém o minimizador do
objetivo de otimização. Por exemplo, se o objetivo de otimização for minimize-rmse,
predicted_TARGET_COLUMN_NAME.value contém o valor médio. Se for minimize-mae, predicted_TARGET_COLUMN_NAME.value contém o valor mediano.
Se o seu modelo usar inferência probabilística com quantis, o Vertex AI armazena valores e inferências de quantis nas seguintes colunas:
-
predicted_TARGET_COLUMN_NAME.quantile_values: os valores dos quantis, que são definidos durante a preparação do modelo. Por exemplo, podem ser0.1,0.5e0.9. -
predicted_TARGET_COLUMN_NAME.quantile_predictions: os valores de inferência associados aos valores dos quantis.
Se ativou as atribuições de funcionalidades, também as pode encontrar na tabela de inferência. Para aceder às atribuições de uma funcionalidade BQ_FEATURE_NAME, execute a seguinte consulta:
SELECT explanation.attributions[OFFSET(0)].featureAttributions.BQ_FEATURE_NAME FROM BQ_DATASET_NAME.BQ_PREDICTIONS_TABLE_NAME
Para saber mais, consulte o artigo Atribuições de funcionalidades para previsões.
Tabela de validação de erros
O nome da tabela (BQ_ERRORS_VALIDATION_TABLE_NAME)
é formado anexando `errors_validation` com a data/hora em que a tarefa de inferência em lote foi iniciada: errors_validation_TIMESTAMP
-
Na consola, aceda à página do BigQuery.
Aceda ao BigQuery -
Execute a seguinte consulta:
SELECT * FROM BQ_DATASET_NAME.BQ_ERRORS_VALIDATION_TABLE_NAME
- errors_TARGET_COLUMN_NAME
Tabela de erros
O nome da tabela (BQ_ERRORS_TABLE_NAME) é formado ao
anexar `errors_` com a data/hora em que a tarefa de inferência em lote
foi iniciada: errors_TIMESTAMP
-
Na consola, aceda à página do BigQuery.
Aceda ao BigQuery -
Execute a seguinte consulta:
SELECT * FROM BQ_DATASET_NAME.BQ_ERRORS_TABLE_NAME
- errors_TARGET_COLUMN_NAME.code
- errors_TARGET_COLUMN_NAME.message
Cloud Storage
Se especificou o armazenamento na nuvem como destino de saída, os resultados do seu pedido de inferência em lote são devolvidos como objetos CSV numa nova pasta no contentor que especificou. O nome da pasta é o nome do seu modelo, com o prefixo "prediction-" e o sufixo da data/hora em que a tarefa de inferência em lote foi iniciada. Pode encontrar o nome da pasta do Cloud Storage no separador Previsões em lote do seu modelo.
A pasta do Cloud Storage contém dois tipos de objetos:-
Objetos de inferência
Os objetos de inferência têm os nomes `predictions_1.csv`, `predictions_2.csv` e assim sucessivamente. Contêm uma linha de cabeçalho com os nomes das colunas e uma linha para cada previsão devolvida. O número de valores de inferência depende da entrada de inferência e do horizonte de previsão. Por exemplo, se a sua entrada incluiu 14 entradas nulas para a coluna de destino (como as vendas para os próximos 14 dias), o seu pedido de inferência devolve 14 linhas, o número de vendas para cada dia. Se o seu pedido de previsão exceder o horizonte de previsão do modelo, o Vertex AI devolve apenas previsões até ao horizonte de previsão.
Os valores de previsão são devolvidos numa coluna denominada `predicted_TARGET_COLUMN_NAME`. Para previsões de quantis, a coluna de saída contém as inferências de quantis e os valores de quantis no formato JSON.
-
Objetos de erro
Os objetos de erro têm os nomes `errors_1.csv`, `errors_2.csv` e assim sucessivamente. Contêm uma linha de cabeçalho e uma linha para cada linha nos seus dados de entrada para os quais o Vertex AI não conseguiu devolver uma previsão (por exemplo, se uma funcionalidade não anulável fosse nula).
Nota: se os resultados forem grandes, são divididos em vários objetos.
Exemplos de consultas de atribuição de funcionalidades no BigQuery
Exemplo 1: determine as atribuições para uma única inferência
Considere a seguinte questão:
Quanto é que um anúncio de um produto aumentou as vendas previstas a 24 de novembro numa determinada loja?
A consulta correspondente é a seguinte:
SELECT
* EXCEPT(explanation, predicted_sales),
ROUND(predicted_sales.value, 2) AS predicted_sales,
ROUND(
explanation.attributions[OFFSET(0)].featureAttributions.advertisement,
2
) AS attribution_advertisement
FROM
`project.dataset.predictions`
WHERE
product = 'product_0'
AND store = 'store_0'
AND date = '2019-11-24'
Exemplo 2: determine a importância das funcionalidades globais
Considere a seguinte questão:
Qual foi o contributo de cada funcionalidade para as vendas previstas em geral?
Pode calcular manualmente a importância das funcionalidades globais agregando as atribuições de importância das funcionalidades locais. A consulta correspondente é a seguinte:
WITH
/*
* Aggregate from (id, date) level attributions to global feature importance.
*/
attributions_aggregated AS (
SELECT
SUM(ABS(attributions.featureAttributions.date)) AS date,
SUM(ABS(attributions.featureAttributions.advertisement)) AS advertisement,
SUM(ABS(attributions.featureAttributions.holiday)) AS holiday,
SUM(ABS(attributions.featureAttributions.sales)) AS sales,
SUM(ABS(attributions.featureAttributions.store)) AS store,
SUM(ABS(attributions.featureAttributions.product)) AS product,
FROM
project.dataset.predictions,
UNNEST(explanation.attributions) AS attributions
),
/*
* Calculate the normalization constant for global feature importance.
*/
attributions_aggregated_with_total AS (
SELECT
*,
date + advertisement + holiday + sales + store + product AS total
FROM
attributions_aggregated
)
/*
* Calculate the normalized global feature importance.
*/
SELECT
ROUND(date / total, 2) AS date,
ROUND(advertisement / total, 2) AS advertisement,
ROUND(holiday / total, 2) AS holiday,
ROUND(sales / total, 2) AS sales,
ROUND(store / total, 2) AS store,
ROUND(product / total, 2) AS product,
FROM
attributions_aggregated_with_total
Exemplo de resultado da inferência em lote no BigQuery
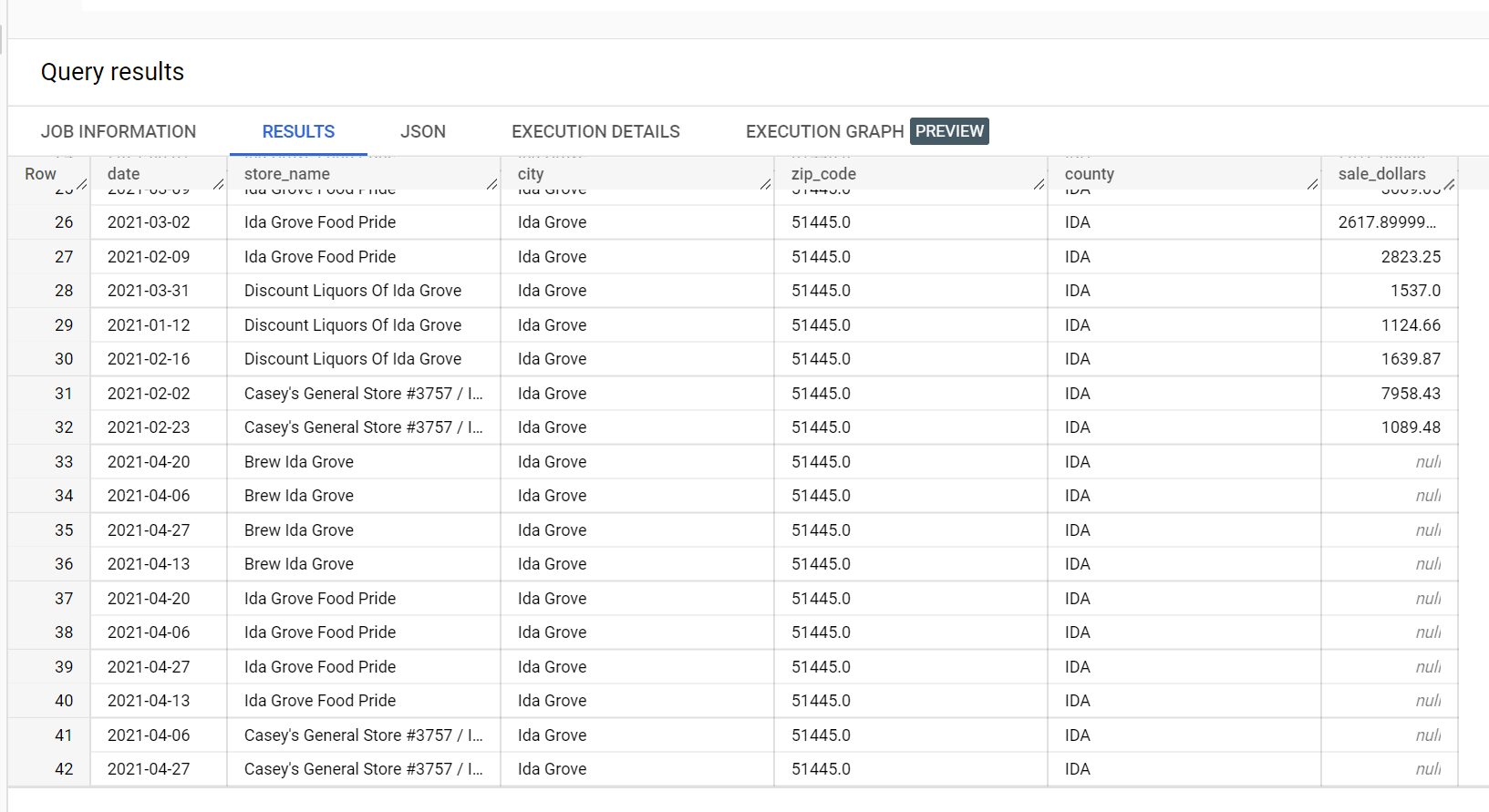
Num conjunto de dados de exemplo de vendas de bebidas alcoólicas, existem quatro lojas na cidade de "Ida Grove": "Ida Grove Food Pride", "Discount Liquors of Ida Grove", "Casey's General Store #3757" e "Brew Ida Grove". store_name é o
series identifier e três das quatro lojas pedem inferências para a coluna de destino sale_dollars. É gerado um erro de validação porque não foi pedida nenhuma previsão para "Discount Liquors of Ida Grove".
Segue-se uma extração do conjunto de dados de entrada usado para inferência:
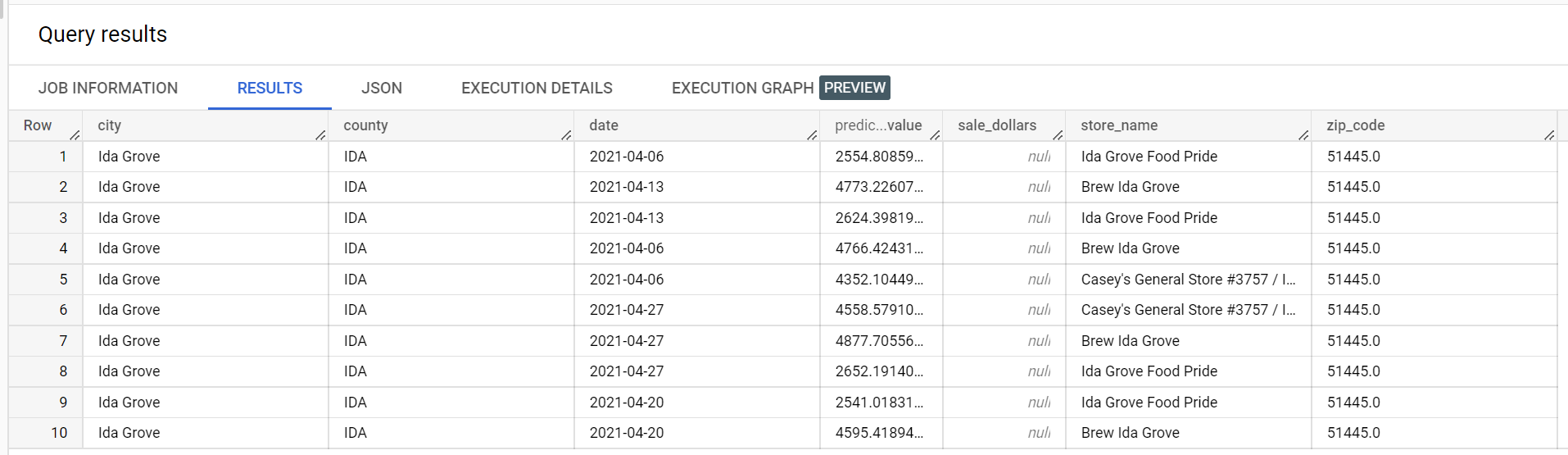
Segue-se um extrato dos resultados da inferência:
Segue-se um extrato dos erros de validação:

Exemplo de saída de inferência em lote para um modelo otimizado de perda de quantil
O exemplo seguinte é a saída da inferência em lote para um modelo otimizado para a função de perda quantílica. Neste cenário, o modelo de previsão previu as vendas para os próximos 14 dias para cada loja.
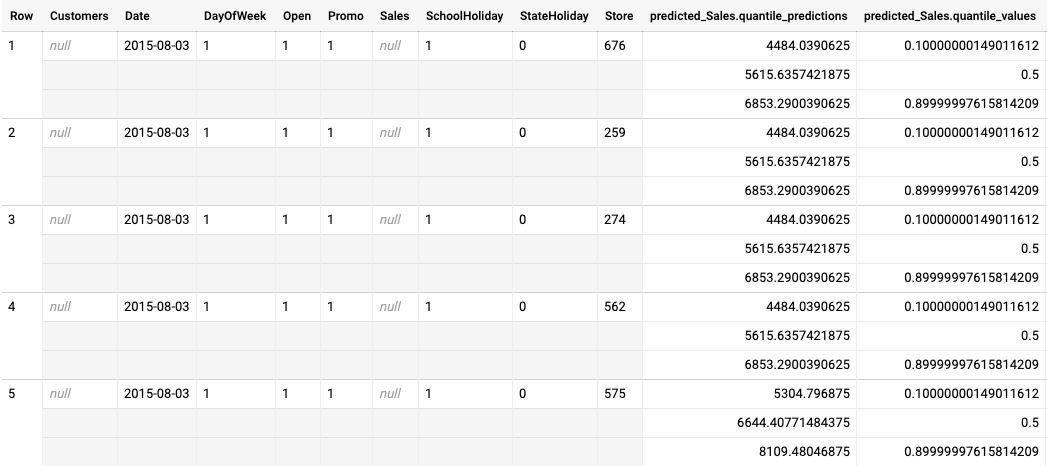
Os valores dos quantis são indicados na coluna predicted_Sales.quantile_values. Neste exemplo, o modelo previu valores nos quantis 0.1, 0.5 e 0.9.
Os valores de inferência são fornecidos na coluna predicted_Sales.quantile_predictions.
Esta é uma matriz de valores de vendas, que é mapeada para os valores dos quantis na coluna predicted_Sales.quantile_values. Na primeira linha, vemos que a probabilidade de o valor de vendas ser inferior a 4484.04 é de 10%. A probabilidade de o valor de vendas ser inferior a 5615.64 é de 50%. A probabilidade de o valor de vendas ser inferior a
6853.29 é de 90%. A inferência para a primeira linha, representada como um único valor, é
5615.64.
O que se segue?
- Saiba mais acerca dos preços das inferências em lote.