Vertex AI には、トレーニング済みの予測モデルを使用して将来の値を予測するために、オンライン予測とバッチ予測の 2 つのオプションがあります。
オンライン予測は同期リクエストです。アプリケーションの入力に応じてリクエストを送信する場合、またはタイムリーな推定が必要となる状況でリクエストを送信する場合は、オンライン予測を使用します。
バッチ予測リクエストは非同期リクエストです。即時のレスポンスが必要なく、累積されたデータを 1 回のリクエストで処理する場合は、バッチ予測を使用します。
このページでは、バッチ予測を使用して将来の値を予測する方法について説明します。オンライン予測を使用して値を予測する方法については、予測モデルのオンライン予測を取得するをご覧ください。
バッチ予測はモデルリソースから直接リクエストできます。
説明(特徴アトリビューション)付きの予測をリクエストして、モデルがどのように予測を達成したかを確認できます。ローカル特徴量の重要度の値は、各特徴量が予測結果に及ぼした影響の度合いを示します。コンセプトの概要については、予測の特徴アトリビューションをご覧ください。
バッチ予測の料金については、Tabular Workflows の料金をご覧ください。
始める前に
バッチ予測リクエストを行うには、まずモデルをトレーニングする必要があります。
入力データ
バッチ予測リクエストの入力データは、モデルが予測の作成に使用するデータです。入力データは、次の 2 つの形式のいずれかで指定できます。
- Cloud Storage の CSV オブジェクト
- BigQuery テーブル
入力データにも、モデルのトレーニングに使用した形式を使用することをおすすめします。たとえば、BigQuery のデータを使用してモデルをトレーニングした場合は、BigQuery テーブルをバッチ予測の入力として使用することをおすすめします。Vertex AI は、すべての CSV 入力フィールドを文字列として扱うため、トレーニング データ形式と入力データ形式を混在させると、エラーが発生することがあります。
データソースには、モデルのトレーニングに使用したすべての列が含まれている必要があります。ただし、順序は問いません。トレーニング データに含まれなかった列や、トレーニング データに含まれているがトレーニングへの使用からは除外された列を含めることができます。これらの追加の列は出力に含まれますが、予測結果には影響しません。
入力データの要件
予測モデルの入力は、次の要件を満たす必要があります。
- 時間列の値はすべて指定され、かつ有効な値である必要があります。
- 入力データとトレーニング データのデータ頻度は一致している必要があります。時系列で行が欠落している場合は、正しいドメイン知識に従って行を手動で挿入する必要があります。
- タイムスタンプが重複する時系列は予測から削除されます。それらを含めるには、重複するタイムスタンプをすべて削除してください。
- 予測する各時系列の履歴データを提供します。予測の精度を最大限に高めるには、データの量が、モデルのトレーニングで設定されたコンテキスト ウィンドウと一致している必要があります。たとえば、コンテキスト ウィンドウが 14 日の場合、少なくとも 14 日分の履歴データを提供します。提供されるデータが少ない場合、Vertex AI では空の値でパディングされます。
- 予測は、ターゲット列内の null 値を持つ時系列(時間順)の最初の行から始まります。null 値は時系列内で連続している必要があります。たとえば、ターゲット列が時間順に並んでいる場合、1 つの時系列を
1、2、null、3、4、null、nullのように指定することはできません。CSV ファイルの場合、Vertex AI は空の文字列を null として扱います。BigQuery は null 値をネイティブでサポートしています。
BigQuery テーブル
入力として BigQuery テーブルを選択する場合は、次のことを確認する必要があります。
- BigQuery のデータソース テーブルは、100 GB 以下でなければなりません。
- テーブルが別のプロジェクトにある場合は、そのプロジェクトの Vertex AI サービス アカウントに
BigQuery Data Editorロールを付与する必要があります。
CSV ファイル
Cloud Storage の入力として CSV オブジェクトを選択する場合は、次のことを確認する必要があります。
- データソースの先頭は、列名を含むヘッダー行にする必要があります。
- 各データソース オブジェクトは 10 GB 以下でなければなりません。最大サイズの 100 GB に達するまで、複数のファイルを含められます。
- Cloud Storage バケットが別のプロジェクトにある場合は、そのプロジェクトの Vertex AI サービス アカウントに
Storage Object Creatorロールを付与する必要があります。 - すべての文字列は二重引用符(")で囲む必要があります。
出力形式
バッチ予測の出力形式は、入力に使用した形式と同じにする必要はありません。たとえば、BigQuery テーブルを入力として使用した場合は、Cloud Storage の CSV オブジェクトに予測結果を出力できます。
モデルにバッチ予測リクエストを行う
バッチ予測リクエストを行うには、Google Cloud コンソールまたは Vertex AI API を使用します。入力データソースは、Cloud Storage バケットまたは BigQuery テーブルに格納された CSV オブジェクトです。入力として送信したデータの量によっては、バッチ予測タスクが完了するまでに時間がかかることがあります。
Google Cloud コンソール
Google Cloud コンソールを使用してバッチ予測をリクエストします。
- Google Cloud コンソールの [Vertex AI] セクションで、[バッチ予測] ページに移動します。
- [作成] をクリックして、[新しいバッチ予測] ウィンドウを開きます。
- [バッチ予測の定義] で、次の手順を完了します。
- バッチ予測の名前を入力します。
- [モデル名] で、このバッチ予測に使用するモデルの名前を選択します。
- [バージョン] で、モデルのバージョンを選択します。
- [ソースを選択] で、ソース入力データとして Cloud Storage 上の CSV ファイルと、BigQuery のテーブルのどちらを使用するかを選択します。
- CSV ファイルの場合は、CSV 入力ファイルのある Cloud Storage のロケーションを指定します。
- BigQuery テーブルの場合、テーブルが存在するプロジェクト ID、BigQuery データセット ID、BigQuery テーブルまたはビュー ID を指定します。
- [バッチ予測の出力] で、[CSV] または [BigQuery] を選択します。
- CSV の場合は、Vertex AI が出力を保存する Cloud Storage バケットを指定します。
- BigQuery の場合は、プロジェクト ID または既存のデータセットを指定します。
- プロジェクト ID を指定するには、[Google Cloud プロジェクト ID] フィールドにプロジェクト ID を入力します。Vertex AI により、新しい出力データセットが作成されます。
- 既存のデータセットを指定するには、[Google Cloud プロジェクト ID] フィールドに BigQuery パス(
bq://projectid.datasetidなど)を入力します。
- (省略可)出力先が Cloud Storage 上の BigQuery または JSONL の場合は、予測に加えて特徴アトリビューションを有効にできます。これを行うには、[このモデルの特徴アトリビューションを有効にする] を選択します。特徴アトリビューションは、Cloud Storage の CSV ではサポートされていません。詳細については、こちらをご覧ください。
- (省略可)バッチ予測の Model Monitoring 分析はプレビュー版として提供されています。スキュー検出構成をバッチ予測ジョブに追加する方法については、前提条件をご覧ください。
- [このバッチ予測のモデルのモニタリングを有効にする] をクリックしてオンにします。
- トレーニング データソースを選択します。選択したトレーニング データソースのデータパスまたは場所を入力します。
- (省略可)[アラートのしきい値] で、アラートをトリガーするしきい値を指定します。
- [通知メール] に、モデルがアラートのしきい値を超えたときにアラートを受け取るメールアドレスを、カンマ区切り形式で 1 つ以上入力します。
- 省略可: 通知チャネルの場合、モデルがアラートのしきい値を超えたときにアラートを受け取るには、Cloud Monitoring チャネルを追加します。[通知チャンネルを管理] をクリックして、既存の Cloud Monitoring チャネルを選択するか、新しい Cloud Monitoring チャネルを作成できます。コンソールでは、PagerDuty、Slack、Pub/Sub 通知チャネルがサポートされています。
- [作成] をクリックします。
API: BigQuery
REST
バッチ予測をリクエストするには、batchPredictionJobs.create メソッドを使用します。
リクエストのデータを使用する前に、次のように置き換えます。
- LOCATION_ID: モデルを保存し、バッチ予測ジョブを実行するリージョン。例:
us-central1 - PROJECT_ID: 実際のプロジェクト ID
- BATCH_JOB_NAME: バッチジョブの表示名
- MODEL_ID: 予測に使用するモデルの ID
-
INPUT_URI: BigQuery データソースへの参照。フォームで次の操作を行います。
bq://bqprojectId.bqDatasetId.bqTableId
-
OUTPUT_URI: BigQuery の宛先への参照(予測が作成される場所)。プロジェクト ID と、必要に応じて既存のデータセット ID を指定します。次の形式を使用します。
bq://bqprojectId.bqDatasetId
bq://bqprojectId
- GENERATE_EXPLANATION: デフォルト値は false です。特徴アトリビューションを有効にするには、true に設定します。詳細については、予測のための特徴アトリビューションをご覧ください。
HTTP メソッドと URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
リクエストの本文(JSON):
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": "OUTPUT_URI"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
リクエストを送信するには、次のいずれかのオプションを選択します。
curl
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
次のような JSON レスポンスが返されます。
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": bq://12345
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
},
"manualBatchTuningParameters": {
"batchSize": 4
},
"outputInfo": {
"bigqueryOutputDataset": "bq://12345.reg_model_2020_10_02_06_04
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Java
このサンプルを試す前に、Vertex AI クイックスタート: クライアント ライブラリの使用にある Java の設定手順を完了してください。詳細については、Vertex AI Java API のリファレンス ドキュメントをご覧ください。
Vertex AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
次のサンプルでは、INSTANCES_FORMAT と PREDICTIONS_FORMAT を「bigquery」に置き換えます。他のプレースホルダを置き換える方法については、このセクションの「REST とコマンドライン」タブをご覧ください。Vertex AI SDK for Python
Vertex AI SDK for Python のインストールまたは更新の方法については、Vertex AI SDK for Python をインストールするをご覧ください。 詳細については、Vertex AI SDK for Python API のリファレンス ドキュメントをご覧ください。
API: Cloud Storage
REST
バッチ予測をリクエストするには、batchPredictionJobs.create メソッドを使用します。
リクエストのデータを使用する前に、次のように置き換えます。
- LOCATION_ID: モデルを保存し、バッチ予測ジョブを実行するリージョン。例:
us-central1 - PROJECT_ID: 実際のプロジェクト ID
- BATCH_JOB_NAME: バッチジョブの表示名
- MODEL_ID: 予測に使用するモデルの ID
-
URI: トレーニング データを含む Cloud Storage バケットへのパス(URI)。複数指定することも可能です。各 URI の形式は次のとおりです。
gs://bucketName/pathToFileName
-
OUTPUT_URI_PREFIX: 予測が作成される Cloud Storage の宛先のパス。Vertex AI は、このパスのタイムスタンプ付きのサブディレクトリにバッチ予測を書き込みます。この値は、次の形式の文字列に設定します。
gs://bucketName/pathToOutputDirectory
- GENERATE_EXPLANATION: デフォルト値は false です。特徴アトリビューションを有効にするには、true に設定します。このオプションは、出力先が JSONL の場合にのみ使用できます。特徴アトリビューションは、Cloud Storage の CSV ではサポートされていません。詳細については、予測のための特徴アトリビューションをご覧ください。
HTTP メソッドと URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
リクエストの本文(JSON):
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
URI1,...
]
},
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
リクエストを送信するには、次のいずれかのオプションを選択します。
curl
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
次のような JSON レスポンスが返されます。
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
"gs://bp_bucket/reg_mode_test"
]
}
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
}
"outputInfo": {
"gcsOutputDataset": "OUTPUT_URI_PREFIX/prediction-batch_job_1 202005291958-2020-09-30T02:58:44.341643Z"
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Vertex AI SDK for Python
Vertex AI SDK for Python のインストールまたは更新の方法については、Vertex AI SDK for Python をインストールするをご覧ください。 詳細については、Vertex AI SDK for Python API のリファレンス ドキュメントをご覧ください。
バッチ予測の結果を取得する
Vertex AI は、バッチ予測の出力を指定の宛先(BigQuery または Cloud Storage)に送信します。
現在、特徴アトリビューションの Cloud Storage 出力はサポートされていません。
BigQuery
出力データセット
BigQuery を使用している場合、バッチ予測の出力は出力データセットに保存されます。Vertex AI にデータセットを提供した場合、データセットの名前(BQ_DATASET_NAME)は前に指定した名前です。出力データセットを指定しなかった場合は、Vertex AI によって作成されます。名前(BQ_DATASET_NAME)を確認する手順は次のとおりです。
- Google Cloud コンソールで、[Vertex AI] の [バッチ予測] ページに移動します。
- 作成した予測を選択します。
-
出力データセットは [エクスポート ロケーション] に表示されます。データセット名は
prediction_MODEL_NAME_TIMESTAMPのような形式です。
出力テーブル
出力データセットには、次の 3 つの出力テーブルのうち 1 つ以上が含まれます。
-
予測テーブル
このテーブルには、入力データの中で、予測がリクエストされたすべての行(すなわち、TARGET_COLUMN_NAME = null の行)について、対応する行が含まれています。たとえば、入力のターゲット列に 14 個の null エントリ(次の 14 日間の売上など)が含まれている場合、予測リクエストはそれぞれの日についての売上の数値として 14 行を返します。予測リクエストがモデルの予測ホライズンを超過した場合、Vertex AI は予測ホライズンまでの予測のみを返します。
-
エラー検証のテーブル
このテーブルには、バッチ予測の前に行われる集計フェーズ中に発生した、重大でないエラーのそれぞれについて、1 つの行が含まれています。それぞれの重大でないエラーは、入力データの中で、Vertex AI が予測を返せなかった各行に対応しています。
-
エラーテーブル
このテーブルには、バッチ予測中に発生した重大でないエラーの行が含まれています。それぞれの重大でないエラーは、入力データの中で、Vertex AI が予測を返せなかった各行に対応しています。
予測テーブル
テーブルの名前(BQ_PREDICTIONS_TABLE_NAME)は、「predictions_」にバッチ予測ジョブの開始時のタイムスタンプが追加された形式(predictions_TIMESTAMP)になっています。
予測テーブルを取得するには:
-
コンソールで、[BigQuery] ページに移動します。
[BigQuery] に移動 - 次のクエリを実行します。
SELECT * FROM BQ_DATASET_NAME.BQ_PREDICTIONS_TABLE_NAME
Vertex AI は、予測を predicted_TARGET_COLUMN_NAME.value 列に保存します。
Temporal Fusion Transformer(TFT)を使用してモデルをトレーニングした場合、TFT の解釈可能性の出力は predicted_TARGET_COLUMN_NAME.tft_feature_importance 列で確認できます。
この列はさらに次の項目に分かれています。
context_columns: コンテキスト ウィンドウの値が TFT の長・短期記憶(LSTM)エンコーダへの入力として機能する予測特徴。context_weights: 予測インスタンスの各context_columnsに関連付けられた特徴の重要度の重み。horizon_columns: 予測ホライズンの値が TFT の長・短期記憶(LSTM)デコーダへの入力として機能する予測特徴。horizon_weights: 予測インスタンスの各horizon_columnsに関連付けられた特徴の重要度の重み。attribute_columns: 時間不変である予測特徴。attribute_weights: 各attribute_columnsに関連付けられた重み。
モデルが分位点損失に最適化されており、分位点の値のセットに中央値が含まれている場合、predicted_TARGET_COLUMN_NAME.value は中央値の予測値です。それ以外の場合、predicted_TARGET_COLUMN_NAME.value はセット内の最小分位の予測値です。たとえば、分位のセットが [0.1, 0.5, 0.9] の場合、value は分位 0.5 の予測です。分位のセットが [0.1, 0.9] の場合、value は分位 0.1 の予測です。
さらに、Vertex AI では、分位値と予測を次の列に保存します。
-
predicted_TARGET_COLUMN_NAME.quantile_values: モデルのトレーニング中に設定される分位の値。たとえば、0.1、0.5、0.9などです。 predicted_TARGET_COLUMN_NAME.quantile_predictions: 分位値に関連付けられた予測値。
モデルで確率的推論を使用する場合、predicted_TARGET_COLUMN_NAME.value には最適化目標の最小化値が含まれます。たとえば、最適化目標が minimize-rmse の場合、predicted_TARGET_COLUMN_NAME.value には平均値が含まれます。minimize-mae の場合、predicted_TARGET_COLUMN_NAME.value には中央値が含まれます。
モデルで分位数を使用した確率論的推論を使用する場合、Vertex AI は次の列に分位値と予測を保存します。
-
predicted_TARGET_COLUMN_NAME.quantile_values: モデルのトレーニング中に設定される分位の値。たとえば、0.1、0.5、0.9などです。 predicted_TARGET_COLUMN_NAME.quantile_predictions: 分位値に関連付けられた予測値。
特徴アトリビューションを有効にしていれば、予測テーブルでも確認できます。特徴 BQ_FEATURE_NAME のアトリビューションにアクセスするには、次のクエリを実行します。
SELECT explanation.attributions[OFFSET(0)].featureAttributions.BQ_FEATURE_NAME FROM BQ_DATASET_NAME.BQ_PREDICTIONS_TABLE_NAME
詳細については、予測の特徴アトリビューションをご覧ください。
エラー検証のテーブル
テーブルの名前(BQ_ERRORS_VALIDATION_TABLE_NAME)は、「predictions_」にバッチ予測ジョブの開始時のタイムスタンプが追加された形式(errors_validation_TIMESTAMP)になっています。
-
コンソールで、[BigQuery] ページに移動します。
[BigQuery] に移動 -
次のクエリを実行します。
SELECT * FROM BQ_DATASET_NAME.BQ_ERRORS_VALIDATION_TABLE_NAME
- errors_TARGET_COLUMN_NAME
エラーテーブル
テーブルの名前(BQ_ERRORS_TABLE_NAME)は、「errors_」にバッチ予測ジョブの開始時のタイムスタンプが追加された形式(errors_TIMESTAMP)になっています。
-
コンソールで、[BigQuery] ページに移動します。
[BigQuery] に移動 -
次のクエリを実行します。
SELECT * FROM BQ_DATASET_NAME.BQ_ERRORS_TABLE_NAME
- errors_TARGET_COLUMN_NAME.code
- errors_TARGET_COLUMN_NAME.message
Cloud Storage
Cloud Storage を出力先に指定した場合、バッチ予測リクエストの結果は、指定したバケット内の新しいフォルダに CSV オブジェクトとして返されます。フォルダの名前は、モデル名の先頭に「prediction-」が追加され、バッチ予測ジョブの開始時のタイムスタンプが末尾に付加された形式です。Cloud Storage フォルダ名は、モデルの [バッチ予測] タブで確認できます。
Cloud Storage フォルダには、次の 2 種類のオブジェクトが含まれます。-
予測オブジェクト
予測オブジェクトには、「predictions_1.csv」、「predictions_2.csv」の順に名前が付けられます。このオブジェクトには、列名が含まれるヘッダー行に加えて、返されたすべての予測の行が含まれています。予測値の数は、予測入力と予測ホライズンによって異なります。たとえば、入力のターゲット列に 14 個の null エントリ(次の 14 日間の売上など)が含まれている場合、予測リクエストはそれぞれの日についての売上の数値として 14 行を返します。予測リクエストがモデルの予測ホライズンを超過した場合、Vertex AI は予測ホライズンまでの予測のみを返します。
予測値は「predicted_TARGET_COLUMN_NAME」という名前の列に返されます。分位予測の場合、出力列には JSON 形式の分位予測と分位値が含まれます。
-
エラー オブジェクト
エラー オブジェクトには、「errors_1.csv」、「errors_2.csv」の順に名前が付けられます。このオブジェクトには、ヘッダー行に加えて、入力データの中で Vertex AI が予測を返せなかった各行(null 値を許容しない特徴が null であった場合など)に対応する行が含まれます。
注: 結果が大きい場合は、複数のオブジェクトに分割されます。
BigQuery の特徴アトリビューション クエリの例
例 1: 単一予測のアトリビューションを決定する
次の質問について考えてみましょう。
特定の商品の広告により、11 月 24 日の特定の店舗での売り上げがどのくらい増えると予測できるか。
対応するクエリは次のとおりです。
SELECT
* EXCEPT(explanation, predicted_sales),
ROUND(predicted_sales.value, 2) AS predicted_sales,
ROUND(
explanation.attributions[OFFSET(0)].featureAttributions.advertisement,
2
) AS attribution_advertisement
FROM
`project.dataset.predictions`
WHERE
product = 'product_0'
AND store = 'store_0'
AND date = '2019-11-24'
例 2: グローバル特徴の重要度を決定する
次の質問について考えてみましょう。
それぞれの特徴が全体の売上予測にどの程度影響を及ぼしているか。
ローカル特徴の重要度のアトリビューションを集計することで、グローバル特徴の重要度を手動で計算できます。対応するクエリは次のとおりです。
WITH
/*
* Aggregate from (id, date) level attributions to global feature importance.
*/
attributions_aggregated AS (
SELECT
SUM(ABS(attributions.featureAttributions.date)) AS date,
SUM(ABS(attributions.featureAttributions.advertisement)) AS advertisement,
SUM(ABS(attributions.featureAttributions.holiday)) AS holiday,
SUM(ABS(attributions.featureAttributions.sales)) AS sales,
SUM(ABS(attributions.featureAttributions.store)) AS store,
SUM(ABS(attributions.featureAttributions.product)) AS product,
FROM
project.dataset.predictions,
UNNEST(explanation.attributions) AS attributions
),
/*
* Calculate the normalization constant for global feature importance.
*/
attributions_aggregated_with_total AS (
SELECT
*,
date + advertisement + holiday + sales + store + product AS total
FROM
attributions_aggregated
)
/*
* Calculate the normalized global feature importance.
*/
SELECT
ROUND(date / total, 2) AS date,
ROUND(advertisement / total, 2) AS advertisement,
ROUND(holiday / total, 2) AS holiday,
ROUND(sales / total, 2) AS sales,
ROUND(store / total, 2) AS store,
ROUND(product / total, 2) AS product,
FROM
attributions_aggregated_with_total
BigQuery のバッチ予測の出力例
酒類販売のデータセットの例では、「Ida Grove」市に「Ida Grove Food Pride」、「Discount Liquors of Ida Grove」、「Casey's General Store #3757」、「Brew Ida Grove」の 4 つの店舗があります。store_name は series identifier で、4 つのうち 3 つの店舗がターゲット列 sale_dollars の予測をリクエストします。「Discount Liquors of Ida Grove」に対して予測がリクエストされたわけではないため、検証エラーが生成されます。
以下に示すのは、予測に使用された入力データセットからの抜粋です。
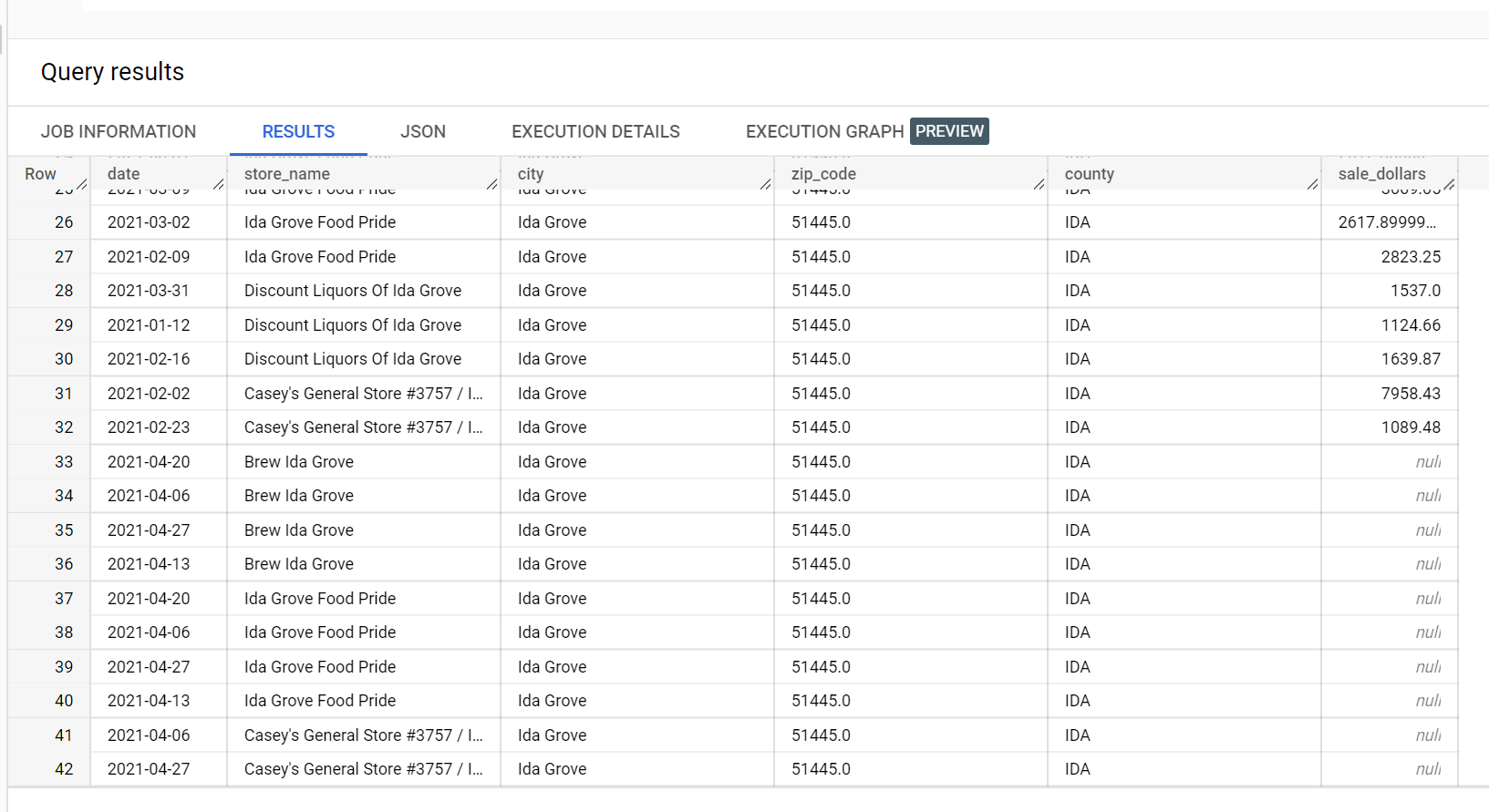
予測結果の抜粋を以下に示します。
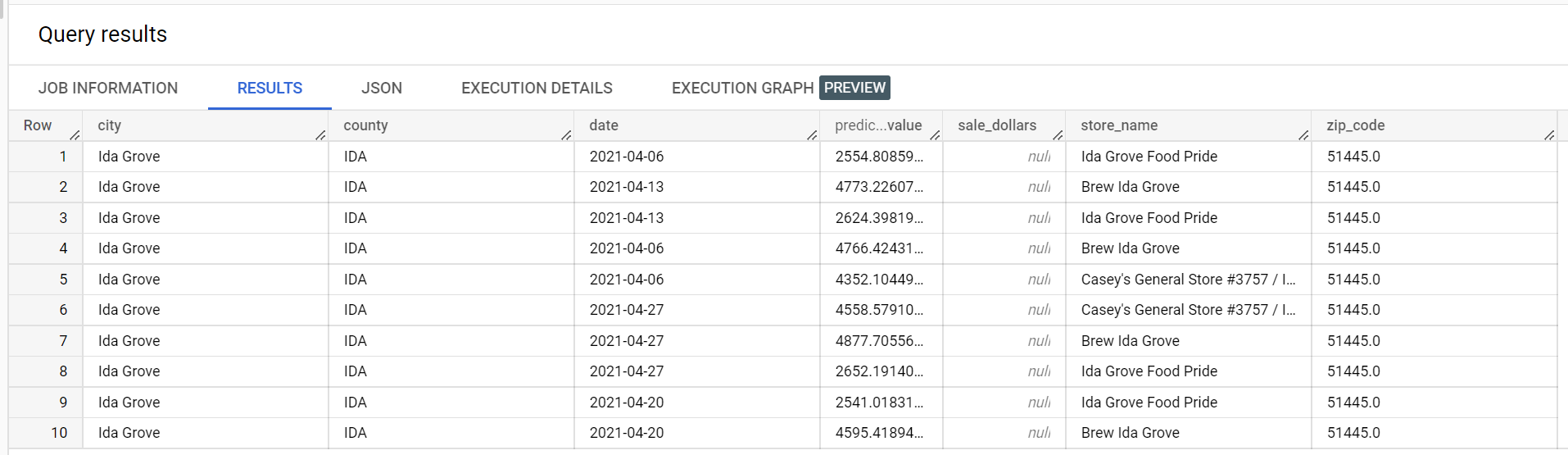
次に示すのは、検証エラーを抜粋したものです。

分位点損失最適化モデルのバッチ予測の出力例
次の例は、分位点損失最適化モデルのバッチ予測の出力です。このシナリオでは、予測モデルが、各店舗の今後 14 日間の売上を予測しています。
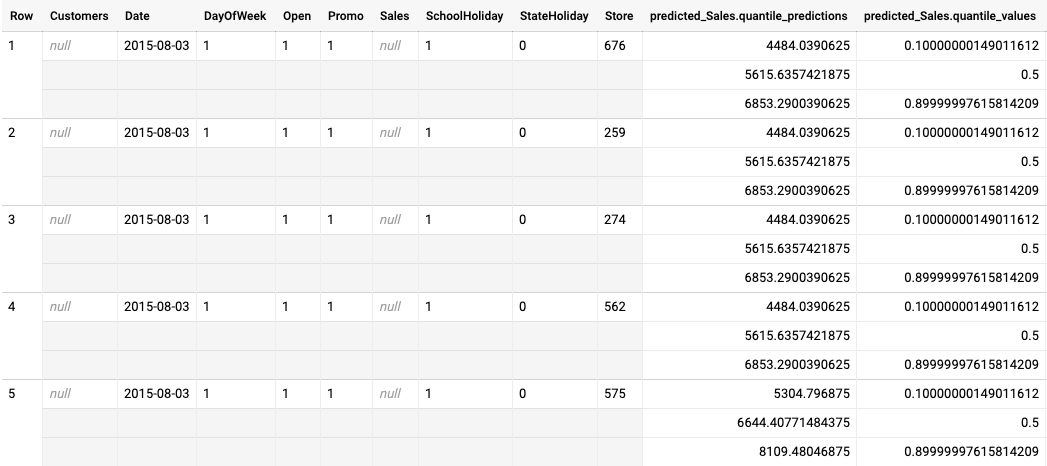
分位の値は predicted_Sales.quantile_values 列で指定されています。この例では、モデルが 0.1、0.5、0.9 の分位で値を予測しました。
予測値は predicted_Sales.quantile_predictions 列に示されています。これは売上値の配列で、predicted_Sales.quantile_values 列の分位値にマッピングされます。最初の行から、販売額が 4484.04 より低い確率が 10% であることがわかります。販売額が 5615.64 より低い確率は 50% です。販売額が 6853.29 より低い確率は 90% です。最初の行の予測は 1 つの値で表され、5615.64 です。
次のステップ
- バッチ予測の料金について学習する。