本页面介绍了如何使用经过训练的预测模型来创建预测。
若要创建预测,请直接向预测模型发出批量推理请求。指定输入源和用于存储预测结果的输出位置。
“使用 AutoML 进行预测”与端点部署或在线推理不兼容。如需从预测模型请求在线推理,请使用预测表格工作流。
您可以请求带有说明(也称为特征归因)的推理,以了解模型如何得出推理结果。局部特征重要性值可以表示每个特征对推理结果的影响程度。如需查看概念性概览,请参阅用于预测的特征归因。
准备工作
在创建预测之前,请先训练预测模型。如需了解详情,请参阅训练预测模型。
输入数据
批量推理请求的输入数据是模型用来创建预测的数据。您可以采用以下两种格式之一提供输入数据:
- Cloud Storage 中的 CSV 对象
- BigQuery 表
我们建议您为输入数据使用与训练模型时相同的格式。例如,如果您使用 BigQuery 中的数据训练模型,那么最好使用 BigQuery 表作为批量推理的输入。由于 Vertex AI 会将所有 CSV 输入字段视为字符串,因此混用不同的训练和输入数据格式可能会导致错误。
您的数据源中的表格数据必须包含用于训练模型的所有列(按任意顺序)。您可以添加不属于训练数据的列,或者属于训练数据但不用于训练的列。这些额外的列包含在输出中,但不会影响预测结果。
输入数据要求
预测模型的输入必须符合以下要求:
- 时间列中的所有值都必须存在且有效。
- 推理请求中使用的所有列都必须存在于输入数据中。当列为空或不存在时,Vertex AI 会自动填充数据。
- 输入数据和训练数据的数据频率必须一致。如果时序中缺少行,则必须根据适当的领域知识手动插入这些行。
- 系统会将存在重复时间戳的时间序列从推理中移除。如需包含这些时间戳,请移除任何重复的时间戳。
- 为要预测的每个时序提供历史数据。为了获得最准确的预测,数据量应该等于模型训练期间设置的上下文窗口。例如,如果上下文窗口为 14 天,请提供至少 14 天的历史数据。如果您提供较少的数据,Vertex AI 会填充包含空值的数据。
- 预测从时间序列(第一行按时间排序)的第一行开始,目标列中具有 null 值。null 值在时间序列中必须是连续的。例如,如果目标列按时间排序,则您不能将
1、2、null、3、4、null、null之类的用于单个时序。对于 CSV 文件,Vertex AI 将空字符串视为 null;对于 BigQuery,原生支持 null 值。
BigQuery 表
如果您选择 BigQuery 表作为输入,则必须确保:
- BigQuery 数据源表不得大于 100 GB。
- 如果该表属于其他项目,您必须向该项目中的 Vertex AI 服务账号授予
BigQuery Data Editor角色。
CSV 文件
如果您选择 Cloud Storage 中的 CSV 对象作为输入,则必须确保:
- 数据源必须以包含列名称的标题行开头。
- 每个数据源对象不得大于 10 GB。可以包含多个文件,但总大小不得超过 100 GB。
- 如果 Cloud Storage 存储桶位于其他项目中,则您必须将
Storage Object Creator角色授予该项目中的 Vertex AI 服务账号。 - 所有字符串必须用英文双引号 (") 括起来。
输出格式
批量推理请求的输出格式不必与输入格式相同。例如,如果您将 BigQuery 表用作输入,您也可以将预测结果输出到 Cloud Storage 中的 CSV 对象。
向模型发出批量推理请求
如需发出批量推理请求,您可以使用 Google Cloud 控制台或 Vertex AI API。输入数据源可以是存储在 Cloud Storage 存储桶或 BigQuery 表中的 CSV 对象。批量推理任务可能需要一些时间才能完成,具体取决于您提交作为输入的数据量。
Google Cloud 控制台
使用 Google Cloud 控制台请求批量推理。
- 在 Google Cloud 控制台的 Vertex AI 部分中,前往批量推理页面。
- 点击创建以打开新建批量推理窗口。
- 在定义批量推理部分,完成以下步骤:
- 输入批次推理的名称。
- 在模型名称字段中,选择要用于此批量推理的模型的名称。
- 对于版本,选择模型的版本。
- 对于选择来源,选择源输入数据是 Cloud Storage 上的 CSV 文件还是 BigQuery 中的表。
- 对于 CSV 文件,请指定 CSV 输入文件所在的 Cloud Storage 位置。
- 对于 BigQuery 表,请指定表所在的项目 ID、BigQuery 数据集 ID 以及 BigQuery 表或视图 ID。
- 对于批量推理输出,选择 CSV 或 BigQuery。
- 对于 CSV,请指定 Vertex AI 存储输出的 Cloud Storage 存储桶。
- 对于 BigQuery,您可以指定项目 ID 或现有数据集:
- 如需指定项目 ID,请在 Google Cloud 项目 ID 字段中输入项目 ID。Vertex AI 会为您创建新的输出数据集。
- 如需指定现有数据集,请在 Google Cloud 项目 ID 字段中输入其 BigQuery 路径,例如
bq://projectid.datasetid。
- 可选。如果输出目的地是 Cloud Storage 上的 BigQuery 或 JSONL,则除了推理之外,您还可以启用特征归因。为此,请选择为此模型启用特征归因。Cloud Storage 上的 CSV 不支持特征归因。了解详情。
- 可选:适用于批量推理的模型监控分析功能已推出预览版。请参阅将偏差检测配置添加到批量推理作业的前提条件。
- 点击以为此批量推理启用模型监控。
- 选择训练数据源。输入您选择的训练数据源的数据路径或位置。
- 可选:在提醒阈值下,指定触发提醒的阈值。
- 在通知电子邮件地址部分,输入一个或多个以英文逗号分隔的电子邮件地址,以便在模型超出提醒阈值时接收提醒。
- 可选:在通知渠道部分,添加 Cloud Monitoring 渠道,以便在模型超出提醒阈值时接收提醒。您可以选择现有的 Cloud Monitoring 渠道,也可以通过点击管理通知渠道来创建一个新的 Cloud Monitoring 渠道。控制台支持 PagerDuty、Slack 和 Pub/Sub 通知渠道。
- 点击创建。
API:BigQuery
REST
可以使用 batchPredictionJobs.create 方法请求批量推理。
在使用任何请求数据之前,请先进行以下替换:
- LOCATION_ID:存储模型和执行批量推理作业的区域。例如
us-central1。 - PROJECT_ID:您的项目 ID
- BATCH_JOB_NAME:批处理作业的显示名
- MODEL_ID:用于执行推理的模型的 ID
-
INPUT_URI:对 BigQuery 数据源的引用。在此表单中执行以下操作:
bq://bqprojectId.bqDatasetId.bqTableId
-
OUTPUT_URI:对 BigQuery 目标位置(将写入推理结果的位置)的引用。指定项目 ID,并选择性地指定数据集 ID。请使用以下格式:
bq://bqprojectId.bqDatasetId
bq://bqprojectId
- GENERATE_EXPLANATION:默认值为 false。设置为 true 可启用特征归因。如需了解详情,请参阅用于预测的特征归因。
HTTP 方法和网址:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
请求 JSON 正文:
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": "OUTPUT_URI"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
如需发送请求,请选择以下方式之一:
curl
将请求正文保存在名为 request.json 的文件中,然后执行以下命令:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
将请求正文保存在名为 request.json 的文件中,然后执行以下命令:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
您应该收到类似以下内容的 JSON 响应:
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": bq://12345
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
},
"manualBatchTuningParameters": {
"batchSize": 4
},
"outputInfo": {
"bigqueryOutputDataset": "bq://12345.reg_model_2020_10_02_06_04
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Java
在尝试此示例之前,请按照《Vertex AI 快速入门:使用客户端库》中的 Java 设置说明执行操作。 如需了解详情,请参阅 Vertex AI Java API 参考文档。
如需向 Vertex AI 进行身份验证,请设置应用默认凭证。 如需了解详情,请参阅为本地开发环境设置身份验证。
在以下示例中,将 INSTANCES_FORMAT 和 PREDICTIONS_FORMAT 替换为“bigquery”。如需了解如何替换其他占位符,请参阅本部分的“REST 和 CMD LINE”标签页。Python
如需了解如何安装或更新 Vertex AI SDK for Python,请参阅安装 Vertex AI SDK for Python。 如需了解详情,请参阅 Python API 参考文档。
API:Cloud Storage
REST
可以使用 batchPredictionJobs.create 方法请求批量推理。
在使用任何请求数据之前,请先进行以下替换:
- LOCATION_ID:存储模型和执行批量推理作业的区域。例如
us-central1。 - PROJECT_ID:
- BATCH_JOB_NAME:批处理作业的显示名
- MODEL_ID:用于执行推理的模型的 ID
-
URI:包含训练数据的 Cloud Storage 存储桶的路径 (URI)。可以有多个路径。每个 URI 的格式如下:
gs://bucketName/pathToFileName
-
OUTPUT_URI_PREFIX:将写入推理结果的 Cloud Storage 目标路径。Vertex AI 会将批量推理结果写入此路径上带时间戳的子目录中。将此值设置为采用以下格式的字符串:
gs://bucketName/pathToOutputDirectory
- GENERATE_EXPLANATION:默认值为 false。设置为 true 可启用特征归因。此选项仅在输出目的地为 JSONL 时可用。Cloud Storage 上的 CSV 不支持特征归因。如需了解详情,请参阅用于预测的特征归因。
HTTP 方法和网址:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
请求 JSON 正文:
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
URI1,...
]
},
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
如需发送请求,请选择以下方式之一:
curl
将请求正文保存在名为 request.json 的文件中,然后执行以下命令:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
将请求正文保存在名为 request.json 的文件中,然后执行以下命令:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
您应该收到类似以下内容的 JSON 响应:
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
"gs://bp_bucket/reg_mode_test"
]
}
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
}
"outputInfo": {
"gcsOutputDataset": "OUTPUT_URI_PREFIX/prediction-batch_job_1 202005291958-2020-09-30T02:58:44.341643Z"
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Python
如需了解如何安装或更新 Vertex AI SDK for Python,请参阅安装 Vertex AI SDK for Python。 如需了解详情,请参阅 Python API 参考文档。
检索批量推理结果
Vertex AI 会将批量推理的输出发送到您指定的目标位置。此目标位置可以是 BigQuery 或 Cloud Storage。
不支持特征归因的 Cloud Storage 输出。
BigQuery
输出数据集
如果您使用的是 BigQuery,则批量推理的输出会存储在输出数据集中。如果您为 Vertex AI 提供了数据集,则数据集 (BQ_DATASET_NAME) 的名称就是您之前提供的名称。如果您未提供输出数据集,则 Vertex AI 会为您创建一个输出数据集。您可以通过以下步骤找到其名称 (BQ_DATASET_NAME):
- 在 Google Cloud 控制台中,前往 Vertex AI 批量推理页面。
- 选择您创建的推理。
-
输出数据集在导出位置中提供。数据集名称的格式如下:
prediction_MODEL_NAME_TIMESTAMP
输出表
输出数据集包含以下三个输出表中的一个或多个:
-
推理表
此表包含输入数据中请求推理(即其中 TARGET_COLUMN_NAME = null)对应的每一行。例如,如果输入包含目标列的 14 个 null 条目(例如未来 14 天的销售额),则推理请求将返回 14 行,即每天的销售额。如果推理请求超出模型的预测范围,则 Vertex AI 仅会返回该预测范围内的推理结果。
-
错误验证表
此表包含在批量推理之前发生的聚合阶段中出现的每个非严重错误对应的行。每个非严重错误与输入数据中 Vertex AI 无法对其返回预测结果的行相对应。
-
错误表
下表包含批量推理期间出现的每个非严重错误对应的行。每个非严重错误与输入数据中 Vertex AI 无法对其返回预测结果的行相对应。
预测表
表的名称 (BQ_PREDICTIONS_TABLE_NAME) 附加了 `predictions_` 并附加了批量推理作业开始的时间戳,格式为 predictions_TIMESTAMP
如需检索推理表,请执行以下操作:
-
在控制台中,转到 BigQuery 页面。
进入 BigQuery -
请运行以下查询:
SELECT * FROM BQ_DATASET_NAME.BQ_PREDICTIONS_TABLE_NAME
Vertex AI 将推理结果存储在 predicted_TARGET_COLUMN_NAME.value 列中。
如果您使用 Temporal Fusion Transformer (TFT) 训练模型,则可以在 predicted_TARGET_COLUMN_NAME.tft_feature_importance 列中找到 TFT 可解释性输出。
此列进一步细分为以下各项:
context_columns:预测特征,其上下文窗口值用作 TFT 长/短期记忆 (LSTM) 编码器的输入。context_weights:与预测实例的每个context_columns关联的特征重要性权重。horizon_columns:预测特征,其预测范围值用作 TFT 长/短期记忆 (LSTM) 解码器的输入。horizon_weights:与预测实例的每个horizon_columns关联的特征重要性权重。attribute_columns:预测特征(时间不变)。attribute_weights:与每个attribute_columns关联的权重。
如果模型
针对分位数损失进行了优化,并且分位数集包含中位数,则 predicted_TARGET_COLUMN_NAME.value 是中位数的推理值。否则,predicted_TARGET_COLUMN_NAME.value 是集合中最小分位数的推理值。例如,如果分位数集为 [0.1, 0.5, 0.9],则 value 是分位数 0.5 的推理结果。
如果分位数集为 [0.1, 0.9],则 value 是分位数 0.1 的推理结果。
此外,Vertex AI 会将分位数值和推理结果存储在以下列中:
-
predicted_TARGET_COLUMN_NAME.quantile_values:分位数的值,在模型训练期间设置。例如,可以是0.1、0.5和0.9。 -
predicted_TARGET_COLUMN_NAME.quantile_predictions:与分位数值关联的推理值。
如果模型使用概率推理,则 predicted_TARGET_COLUMN_NAME.value 包含优化目标的最小化器。例如,如果优化目标为 minimize-rmse,则 predicted_TARGET_COLUMN_NAME.value 包含平均值。如果优化目标为 minimize-mae,则 predicted_TARGET_COLUMN_NAME.value 包含中位数值。
如果模型将概率推理与分位数结合使用,则 Vertex AI 会将分位数值和推理结果存储在以下列中:
-
predicted_TARGET_COLUMN_NAME.quantile_values:分位数的值,在模型训练期间设置。例如,可以是0.1、0.5和0.9。 -
predicted_TARGET_COLUMN_NAME.quantile_predictions:与分位数值关联的推理值。
如果您启用了特征归因,则可以在推理表中找到它们。如需访问特征 BQ_FEATURE_NAME 的归因,请运行以下查询:
SELECT explanation.attributions[OFFSET(0)].featureAttributions.BQ_FEATURE_NAME FROM BQ_DATASET_NAME.BQ_PREDICTIONS_TABLE_NAME
如需了解详情,请参阅用于预测的特征归因。
错误验证表
该表名称 (BQ_ERRORS_VALIDATION_TABLE_NAME) 由“errors_validation”后面附加批量推理作业开始时的时间戳组成:errors_validation_TIMESTAMP
-
在控制台中,转到 BigQuery 页面。
进入 BigQuery -
请运行以下查询:
SELECT * FROM BQ_DATASET_NAME.BQ_ERRORS_VALIDATION_TABLE_NAME
- errors_TARGET_COLUMN_NAME
错误表
该表名称 (BQ_ERRORS_TABLE_NAME) 由“errors_”后面附加批量推理作业开始时的时间戳组成:errors_TIMESTAMP
-
在控制台中,转到 BigQuery 页面。
进入 BigQuery -
请运行以下查询:
SELECT * FROM BQ_DATASET_NAME.BQ_ERRORS_TABLE_NAME
- errors_TARGET_COLUMN_NAME.code
- errors_TARGET_COLUMN_NAME.message
Cloud Storage
如果您将 Cloud Storage 指定为输出的目标位置,则批量推理请求的结果会以 CSV 对象的形式返回到您指定的存储桶的新文件夹中。文件夹的名称是模型的名称,该名称前面附加了“prediction-”,后面附加了批量推理作业开始时的时间戳。您可以在模型的批量预测标签页中找到 Cloud Storage 文件夹名称。
Cloud Storage 文件夹包含两种对象:-
推理对象
推理对象的名称为“predictions_1.csv”“predictions_2.csv”,以此类推。它们包含一个具有列名称的标题行和一个包含返回的各个预测结果的行。推理值的数量取决于推理输入和预测范围。例如,如果输入包含目标列的 14 个空条目(例如未来 14 天的销售额),则推理请求将返回 14 行,即每天的销售额。如果推理请求超出模型的预测范围,则 Vertex AI 仅会返回该预测范围内的推理结果。
预测值会在名为“predicted_TARGET_COLUMN_NAME”的列中返回。对于分位数预测,输出列包含采用 JSON 格式的分位数推理结果和分位数值。
-
错误对象
错误对象的名称为“errors_1.csv”“errors_2.csv”,以此类推。它们包含一个标题行,还包含输入数据中 Vertex AI 无法针对其返回预测结果(例如,如果不可为 Null 的特征为 Null)的每一行。
注意:如果结果较大,则会拆分为多个对象。
BigQuery 中的特征归因查询示例
示例 1:确定单个推理的归因
请考虑以下问题:
某产品的广告在 11 月 24 日在指定商店增加的预测销售额是多少?
对应的查询如下所示:
SELECT
* EXCEPT(explanation, predicted_sales),
ROUND(predicted_sales.value, 2) AS predicted_sales,
ROUND(
explanation.attributions[OFFSET(0)].featureAttributions.advertisement,
2
) AS attribution_advertisement
FROM
`project.dataset.predictions`
WHERE
product = 'product_0'
AND store = 'store_0'
AND date = '2019-11-24'
示例 2:确定全局特征重要性
请考虑以下问题:
每项功能对预测销售额的总体贡献有多大?
可以通过聚合局部特征重要性归因来手动计算全局特征重要性。对应的查询如下所示:
WITH
/*
* Aggregate from (id, date) level attributions to global feature importance.
*/
attributions_aggregated AS (
SELECT
SUM(ABS(attributions.featureAttributions.date)) AS date,
SUM(ABS(attributions.featureAttributions.advertisement)) AS advertisement,
SUM(ABS(attributions.featureAttributions.holiday)) AS holiday,
SUM(ABS(attributions.featureAttributions.sales)) AS sales,
SUM(ABS(attributions.featureAttributions.store)) AS store,
SUM(ABS(attributions.featureAttributions.product)) AS product,
FROM
project.dataset.predictions,
UNNEST(explanation.attributions) AS attributions
),
/*
* Calculate the normalization constant for global feature importance.
*/
attributions_aggregated_with_total AS (
SELECT
*,
date + advertisement + holiday + sales + store + product AS total
FROM
attributions_aggregated
)
/*
* Calculate the normalized global feature importance.
*/
SELECT
ROUND(date / total, 2) AS date,
ROUND(advertisement / total, 2) AS advertisement,
ROUND(holiday / total, 2) AS holiday,
ROUND(sales / total, 2) AS sales,
ROUND(store / total, 2) AS store,
ROUND(product / total, 2) AS product,
FROM
attributions_aggregated_with_total
BigQuery 中的批量推理输出示例
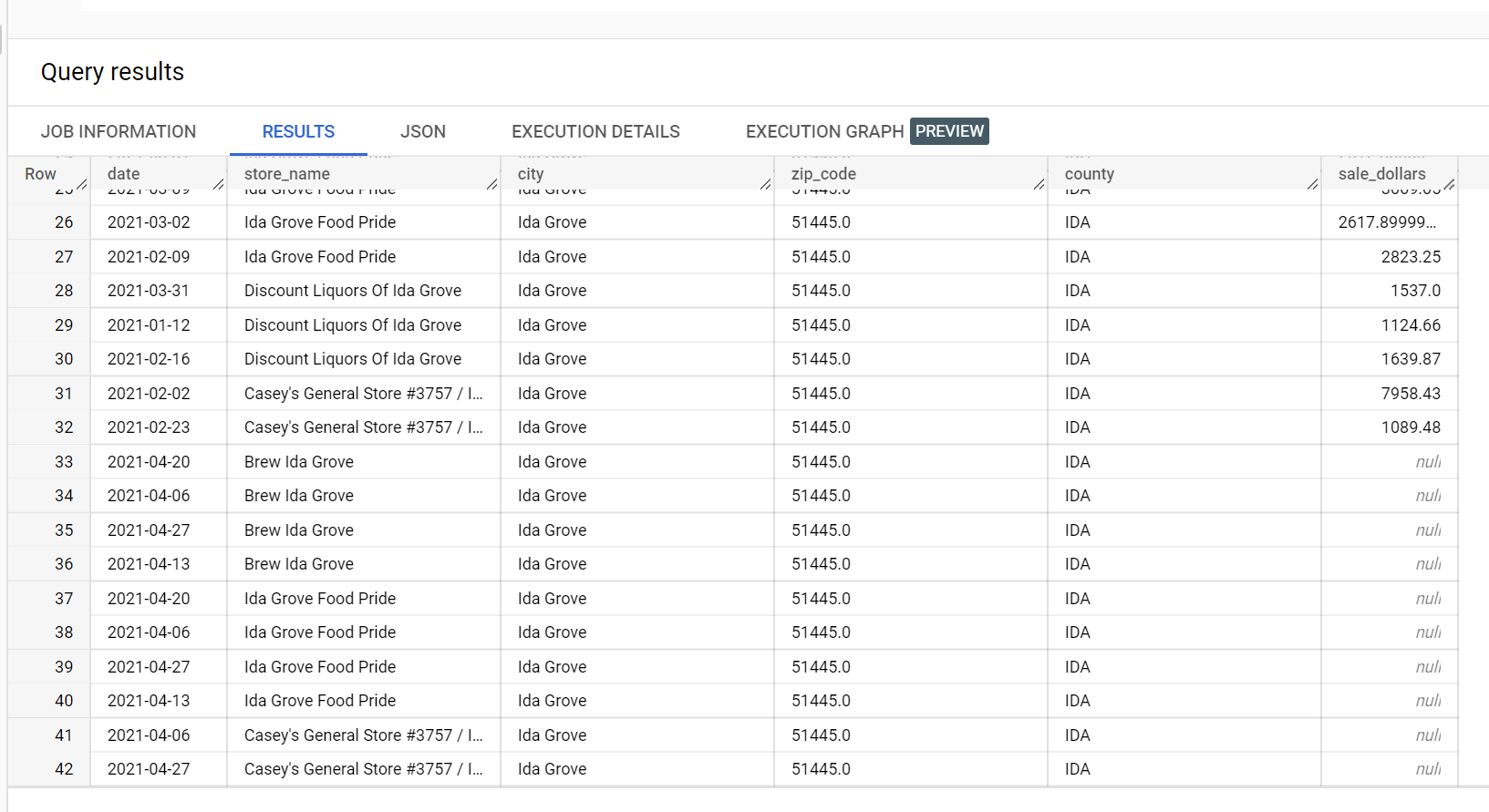
在酒类销售数据集示例中,“Ida Grove”市有四家商店:“Ida Grove Food Pride”“Discount Liquors of Ida Grove”“Casey's General Store #3757”和“Brew Ida Grove”。store_name 为 series identifier,四家商店中的三家请求针对目标列 sale_dollars 进行推理。由于“Discount Liquors of Ida Grove”没有请求预测,因此系统会生成验证错误。
以下是从用于推理的输入数据集中提取的内容:
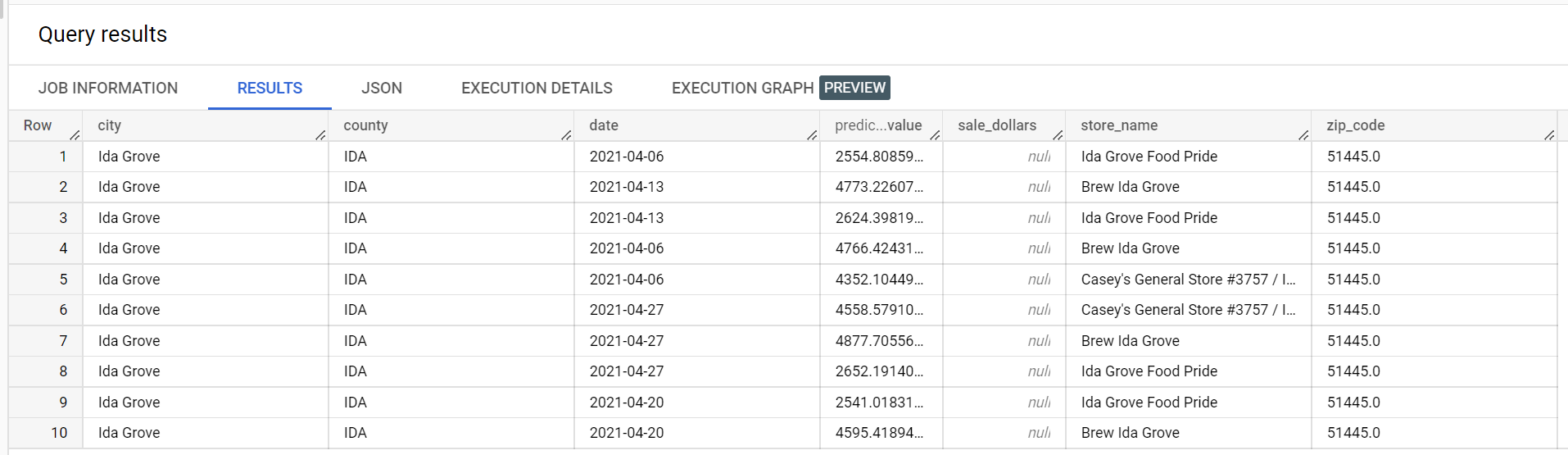
以下是从推理结果中提取的内容:
以下是从验证错误中提取的内容:

针对分位数损失进行优化的模型的批量推理输出示例
以下示例是针对分位数损失进行优化的模型的批量推理输出。在此场景中,预测模型预测了每家商店未来 14 天的销售额。
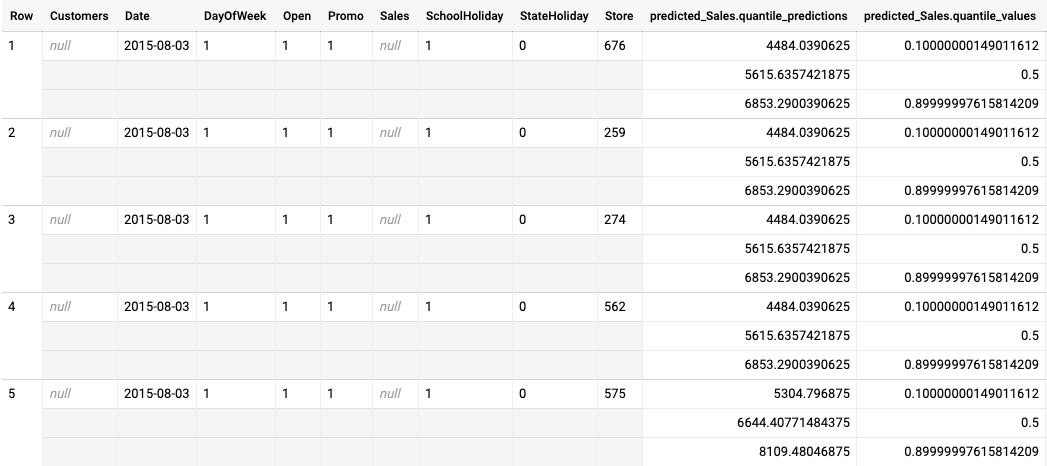
分位数值在 predicted_Sales.quantile_values 列中提供。 在此示例中,模型预测了 0.1、0.5 和 0.9 分位数的值。
推理值在 predicted_Sales.quantile_predictions 列中提供。这是一组销售值,映射到 predicted_Sales.quantile_values 列中的分位数值。在第一行中,我们看到销售价值低于 4484.04 的概率为 10%。销售价值低于 5615.64 的概率为 50%。销售价值低于 6853.29 的概率为 90%。第一行的推理结果(表示为单个值)为 5615.64。