Lorsque vous utilisez un ensemble de données pour entraîner un modèle AutoML, les données sont divisées en trois ensembles : une division d'entraînement, une division de validation et une division de test. Lors de la création de répartitions des données, l'objectif principal est de s'assurer que votre ensemble de données de test représente les données de production avec justesse. Ainsi, les métriques d'évaluation fourniront un signal précis sur la manière dont le modèle fonctionne sur les données réelles.
Cette page explique comment Vertex AI utilise les ensembles d'entraînement, de validation et de test de vos données pour entraîner un modèle AutoML et comment contrôler la manière dont vos données sont réparties entre ces trois ensembles. Les algorithmes de répartition des données pour la classification et la régression sont différents des algorithmes de répartition des données pour la prévision.
Répartition des données pour la classification et la régression
Utilisation des répartitions de données
Les répartitions de données sont utilisées dans le processus d'entraînement comme suit:
Essais de modèles
L'ensemble d'entraînement permet d'entraîner des modèles avec différentes combinaisons d'options de prétraitement, d'architecture et d'hyperparamètres. Ces modèles sont évalués sur l'ensemble de validation en ce qui concerne la qualité, ce qui guide l'exploration d'autres combinaisons d'options. L'ensemble de validation permet également de sélectionner le meilleur point de contrôle grâce à une évaluation périodique pendant l'entraînement. Les meilleurs paramètres et architectures déterminés lors de la phase de réglage en parallèle sont utilisés pour entraîner deux modèles d'ensemble, comme décrit ci-dessous.
Évaluation du modèle
Vertex AI entraîne un modèle d'évaluation, en utilisant les ensembles d'entraînement et de validation comme données d'entraînement. Vertex AI génère les métriques d'évaluation de modèle finales sur ce modèle, en utilisant l'ensemble de test. À ce stade du processus, il s'agit de la première fois que l'ensemble de test est utilisé. Cette approche permet de s'assurer que les métriques d'évaluation finales reflètent de manière impartiale les performances du modèle entraîné final en production.
Diffuser le modèle
Un modèle est entraîné avec les ensembles d'entraînement, de validation et de test pour maximiser la quantité de données d'entraînement. Ce modèle est celui que vous utilisez pour demander des prédictions en ligne ou des prédictions par lot.
Répartition par défaut des données
Par défaut, Vertex AI utilise un algorithme de répartition aléatoire pour séparer vos données en trois divisions. Par défaut, Vertex AI sélectionne de manière aléatoire 80 % des lignes de données pour l'ensemble d'entraînement, 10 % pour l'ensemble de validation et 10 % pour l'ensemble de test. Nous recommandons la répartition par défaut pour les ensembles de données comportant les caractéristiques suivantes :
- Constants au fil du temps
- Relativement équilibrés.
- Distribués comme les données utilisées pour les prédictions en production.
Pour utiliser la répartition des données par défaut, acceptez la valeur par défaut dans la console Google Cloud ou laissez le champ division vide pour l'API.
Options de contrôle de répartition des données
Pour contrôler quelles lignes sont sélectionnées pour telle répartition, vous pouvez choisir l'une des approches suivantes :
- Répartition aléatoire : Définissez les pourcentages de répartition et affectez les lignes de données de manière aléatoire.
- Répartition manuelle : sélectionnez des lignes spécifiques à utiliser pour l'entraînement, la validation et les tests dans la colonne de répartition des données.
- Répartition chronologique : répartissez vos données par heure dans la colonne Heure.
Vous ne choisissez qu'une de ces options ; vous faites votre choix lorsque vous entraînez le modèle. Certaines de ces options nécessitent de modifier les données d'entraînement (par exemple, la colonne de répartition des données ou la colonne d'horaire). L'inclusion de données pour les options de répartition des données ne vous oblige pas à les utiliser. Vous pouvez toujours choisir une autre option lorsque vous entraînez votre modèle.
La répartition par défaut n'est pas le meilleur choix dans les cas suivants :
Vous n'entraînez pas de modèle de prévision, mais vos données sont sensibles au facteur temps.
Dans ce cas, vous devez utiliser une répartition chronologique ou une répartition manuelle qui désignera les données les plus récentes comme constituant l'ensemble de données de test.
Vos données de test incluent des données de populations qui ne seront pas représentées en production.
Par exemple, imaginons que vous entraîniez un modèle sur les données d'achat d'un certain nombre de magasins. Vous savez cependant que le modèle sera principalement utilisé pour réaliser des prédictions pour les magasins qui ne figurent pas dans les données d'entraînement. Afin d'être certain que le modèle peut s'appliquer également aux magasins non représentés, vous devez isoler vos ensembles de données par magasin. En d'autres termes, votre ensemble de données de test ne doit concerner que des magasins absents de l'ensemble de données de validation, et celui-ci ne doit inclure que des magasins absents de l'ensemble de données de test.
Vos classes sont déséquilibrées.
Si l'une des classes est largement plus représentée qu'une autre dans vos données d'entraînement, vous devrez peut-être inclure manuellement davantage d'exemples de la classe minoritaire dans vos données de test. Vertex AI n'effectuant pas d'échantillonnage stratifié, les exemples de la classe minoritaire dans l'ensemble de données de test peuvent être en nombre insuffisant, voire inexistants.
Répartition aléatoire
La répartition aléatoire est également appelée "répartition mathématique" ou "répartition en fractions".
Par défaut, les pourcentages de données d'entraînement utilisés pour les ensembles d'entraînement, de validation et de test sont respectivement de 80, 10 et 10. Si vous utilisez la console Google Cloud, vous pouvez remplacer les pourcentages par n'importe quelle valeur correspondant à 100. Si vous utilisez l'API Vertex AI, vous utilisez des fractions dont le total doit être égal à 1,0.
Pour modifier les pourcentages (fractions), utilisez l'objet FractionSplit pour définir vos fractions.
Au cours du processus de répartition, les lignes sont sélectionnées de façon aléatoire, mais déterministe. Si vous n'êtes pas satisfait de la composition des segments de données générés, vous devez effectuer un fractionnement manuel ou modifier les données d'entraînement. L'entraînement d'un nouveau modèle avec les mêmes données d'entraînement produit la même répartition des données.
Répartition manuelle
La répartition manuelle est également appelée "répartition prédéfinie".
Une colonne de répartition des données vous permet de sélectionner des lignes spécifiques à utiliser pour l'entraînement, la validation et les tests. Lorsque vous créez vos données d'entraînement, vous ajoutez une colonne pouvant contenir l'une des valeurs suivantes (sensibles à la casse) :
TRAINVALIDATETESTUNASSIGNED
Les valeurs de cette colonne doivent correspondre à l'une des deux combinaisons suivantes :
- Tous les ensembles
TRAIN,VALIDATEetTEST - Seuls les ensembles
TESTetUNASSIGNED
Chaque ligne doit contenir une valeur pour cette colonne et ne peut être la chaîne vide.
Par exemple, si tous les ensembles sont spécifiés :
"TRAIN","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "TRAIN","Roger","Rogers","123-45-6789" "VALIDATE","Sarah","Smith","333-33-3333"
Si seul l'ensemble de données de test est spécifié :
"UNASSIGNED","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "UNASSIGNED","Roger","Rogers","123-45-6789" "UNASSIGNED","Sarah","Smith","333-33-3333"
La colonne de répartition des données peut avoir n'importe quel nom de colonne valide. Son type de transformation peut être catégoriel, text ou auto.
Si la valeur de la colonne de répartition des données est UNASSIGNED, Vertex AI attribue automatiquement cette ligne à l'ensemble de données d'entraînement ou de validation.
Désignez une colonne comme colonne de répartition des données lors de l'entraînement du modèle.
Répartition chronologique
La répartition chronologique est également appelée "répartition par horodatage".
Si vos données dépendent de l'heure, vous pouvez désigner une colonne comme colonne d'horaire. Vertex AI utilise la colonne Heure pour répartir vos données. Les lignes les plus anciennes sont utilisées pour l'entraînement, les lignes suivantes pour la validation et les lignes les plus récentes pour les tests.
Vertex AI traite chaque ligne comme un exemple d'entraînement indépendant et réparti de manière identique. La définition de la colonne Heure n'a aucune incidence. La colonne Heure n'est utilisée que pour diviser l'ensemble de données.
Si vous spécifiez une colonne Heure, vous devez inclure une valeur pour la colonne Heure pour chaque ligne de l'ensemble de données. Assurez-vous que la colonne Heure contient suffisamment de valeurs distinctes afin que les ensembles de données de validation et de test ne soient pas vides. En règle générale, vous devez indiquer au moins 20 valeurs distinctes.
Les données de la colonne Heure doivent être conformes à l'un des formats acceptés par la transformation d'horodatages. Toutefois, la colonne Heure peut utiliser n'importe quelle transformation compatible, car la transformation ne concerne que l'utilisation de cette colonne dans l'entraînement. les transformations n'affectent pas la répartition des données.
Vous pouvez également spécifier les pourcentages des données d'entraînement à attribuer à chaque ensemble.
Désignez une colonne en tant que colonne Heure lors de l'entraînement du modèle.
Répartition des données pour la prévision
Par défaut, Vertex AI utilise un algorithme de répartition chronologique pour séparer vos données de prévision en trois divisions. Nous vous recommandons d'utiliser la répartition par défaut. Toutefois, si vous souhaitez contrôler les lignes de données d'entraînement utilisées pour chaque division, utilisez une répartition manuelle.
Utilisation des répartitions de données
Les répartitions de données sont utilisées dans le processus d'entraînement comme suit:
Essais de modèles
L'ensemble d'entraînement permet d'entraîner des modèles avec différentes combinaisons d'options de prétraitement, d'architecture et d'hyperparamètres. Ces modèles sont évalués sur l'ensemble de validation en ce qui concerne la qualité, ce qui guide l'exploration d'autres combinaisons d'options. L'ensemble de validation permet également de sélectionner le meilleur point de contrôle grâce à une évaluation périodique pendant l'entraînement. Les meilleurs paramètres et architectures déterminés lors de la phase de réglage en parallèle sont utilisés pour entraîner deux modèles d'ensemble, comme décrit ci-dessous.
Évaluation du modèle
Vertex AI entraîne un modèle d'évaluation, en utilisant les ensembles d'entraînement et de validation comme données d'entraînement. Vertex AI génère les métriques d'évaluation de modèle finales sur ce modèle, en utilisant l'ensemble de test. À ce stade du processus, il s'agit de la première fois que l'ensemble de test est utilisé. Cette approche permet de s'assurer que les métriques d'évaluation finales reflètent de manière impartiale les performances du modèle entraîné final en production.
Diffuser le modèle
Un modèle est entraîné avec l'ensemble d'entraînement et de validation. Il est validé (pour sélectionner le meilleur point de contrôle) à l'aide de l'ensemble de test. L'ensemble de test n'est jamais entraîné dans le sens où la perte est calculée à partir de celui-ci. Ce modèle est celui que vous utilisez pour demander des prédictions.
Répartition par défaut
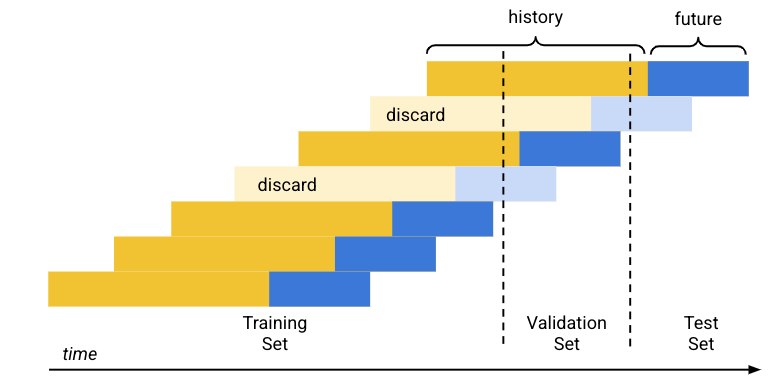
La répartition des données par défaut (chronologique) fonctionne comme suit :
- Les données d'entraînement sont triées par date.
- À l'aide des pourcentages prédéterminés par ensemble de données (80/10/10), la période couverte par les données d'entraînement est divisée en trois blocs, un pour chaque ensemble d'entraînement.
- Des lignes vides sont ajoutées au début de chaque série temporelle pour permettre au modèle d'apprendre à partir des lignes qui ne disposent pas d'un historique suffisant (fenêtre de contexte). Le nombre de lignes ajoutées correspond à la taille de la fenêtre de contexte définie au moment de l'entraînement.
En utilisant la taille d'horizon de prévision définie au moment de l'entraînement, chaque ligne dont les données futures (horizon de prévision) correspond complètement à l'un des ensembles de données est utilisée pour cet ensemble. (Les lignes dont l'horizon de prévision se trouve à cheval sur deux ensembles sont supprimées pour éviter toute fuite de données.)
Répartition manuelle
Une colonne de répartition des données vous permet de sélectionner des lignes spécifiques à utiliser pour l'entraînement, la validation et les tests. Lorsque vous créez vos données d'entraînement, vous ajoutez une colonne pouvant contenir l'une des valeurs suivantes (sensibles à la casse) :
TRAINVALIDATETEST
Chaque ligne doit contenir une valeur pour cette colonne et ne peut être la chaîne vide.
Exemple :
"TRAIN","sku_id_1","2020-09-21","10" "TEST","sku_id_1","2020-09-22","23" "TRAIN","sku_id_2","2020-09-22","3" "VALIDATE","sku_id_2","2020-09-23","45"
La colonne de répartition des données peut avoir n'importe quel nom de colonne valide. Son type de transformation peut être catégoriel, text ou auto.
Désignez une colonne comme colonne de répartition des données lors de l'entraînement du modèle.
Veillez à éviter les fuites de données entre vos séries temporelles.