使用数据集训练 AutoML 模型时,Vertex AI 会将数据划分为三个分块:训练分块、验证分块和测试分块。创建数据分块的主要目标是确保您的测试集准确地表示生产数据。这样可确保评估指标能够准确表示模型在使用真实数据时的表现。
本页面介绍了 Vertex AI 如何使用数据的训练集、验证集和测试集来训练 AutoML 模型。本文还介绍了如何控制这三个数据集的拆分方式。用于分类和回归的数据分块算法与用于预测的数据分块算法不同。
用于分类和回归的数据分块
如何使用数据分块
在训练过程中,会使用数据分块,如下所示:
模型试验
训练集用于使用不同的预处理、架构和超参数选项组合来训练模型。Vertex AI 会在验证集上评估这些模型的质量,这有助于探索其他选项组合。在训练期间,验证集还用于从定期评估中选择最佳检查点。Vertex AI 使用在并行调整阶段确定的最佳参数和架构来训练两个集成学习模型,如下所述。
模型评估
Vertex AI 会将训练和验证集用作训练数据来训练评估模型。Vertex AI 会使用测试集在此模型上生成最终模型评估指标。这是首次在过程中使用测试集。该方法可确保最终评估指标能公正地反映最终训练出的模型在生产环境中的表现。
应用模型
Vertex AI 会使用训练集、验证集和测试集来训练模型,以最大限度地提高训练数据量。使用此模型请求在线预测或批量预测。
默认数据拆分
默认情况下,Vertex AI 使用随机拆分算法将数据拆分为三个数据分块。Vertex AI 随机选择 80% 的数据行分配给训练集、10% 分配给验证集、10% 分配给测试集。建议对以下数据集使用默认拆分:
- 随时间变化不变。
- 相对平衡。
- 与用于生产环境中预测的数据类似进行分布。
如需使用默认数据拆分,请在 Google Cloud 控制台中接受默认值,或者将 API 的 split 字段留空。
控制数据拆分的选项
您可使用下列方法之一来控制为哪个数据集选择哪些行:
您只能选择以上选项之一;您需要在训练模型时进行选择。 其中一些选项需要更改训练数据(例如数据拆分列或时间列)。为数据拆分选项添加数据不要求您必须使用这些选项;在训练模型时,您仍然可以选择其他选项。
在以下情况下,默认分配不是最佳选择:
您未训练预测模型,但您的数据具有时间敏感性。
测试数据包括生产环境中不会出现的群体的数据。
例如,假设您使用来自多个商店的消费数据来训练模型。但是,您知道该模型主要用于对训练数据中没有的商店进行预测。为了确保模型能够泛化到未显示的商店,应按商店划分数据集。也就是说,您的测试集应仅包含与验证集不同的商店,而验证集应仅包含与训练集不同的商店。
分类不平衡。
如果您的训练数据中某个类的数据明显多于另一个类,则您可能需要在测试数据中向少数类手动添加更多样本。Vertex AI 不执行分层采样,因此测试集可能包含很少甚至零个少数类的样本。
随机拆分
随机拆分也称为“数学拆分”或“分数拆分”。
默认情况下,用于训练集、验证集和测试集的训练数据的百分比分别为 80、10 和 10。如果您使用的是 Google Cloud 控制台,则可以将百分比更改为总和为 100 的任何值。如果您使用的是 Vertex AI API,则使用总和为 1.0 的分数。
如需更改百分比(分数),您可以使用 FractionSplit 对象来定义分数。
Vertex AI 会随机(但具有确定性)地选择数据拆分的行。如果您对生成的数据拆分的构成不满意,请使用手动拆分或更改训练数据。使用相同的训练数据训练新模型将产生相同的数据分块。
手动拆分
手动拆分也称为“预定义拆分”。
您可以使用数据拆分列来选择要用于训练、验证和测试的特定行。创建训练数据时,添加一个可包含以下某个值(区分大小写)的列:
TRAINVALIDATETESTUNASSIGNED
此列中的值必须是以下两种组合之一:
- 全部为
TRAIN、VALIDATE和TEST - 只有
TEST和UNASSIGNED
每一行都必须具有该列的值;不能为空字符串。
例如,指定了所有集的情形:
"TRAIN","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "TRAIN","Roger","Rogers","123-45-6789" "VALIDATE","Sarah","Smith","333-33-3333"
仅指定了测试集的情形:
"UNASSIGNED","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "UNASSIGNED","Roger","Rogers","123-45-6789" "UNASSIGNED","Sarah","Smith","333-33-3333"
数据拆分列可以具有任何有效的列名称;其转换类型可以是“分类”、“文本”或“自动”。
如果数据拆分列的值为 UNASSIGNED,则 Vertex AI 会自动将相应行分配给训练集或验证集。
在模型训练期间将一列指定为数据拆分列。
按时间顺序拆分
按时间顺序拆分也称为“时间戳拆分”。
如果您的数据会随时间变化,则可以指定一个列作为时间列。Vertex AI 使用时间列来拆分数据,最早的行用于训练,次早的行用于验证,最新的行用于测试。
Vertex AI 将每一行视为一个独立同分布的训练样本;设置时间列不会更改此情况。时间列仅用于拆分数据集。
如果您指定时间列,则必须为数据集中的每一行添加一个时间列值。请确保时间列具有足够多的非重复值,从而使验证和测试集不为空。通常,至少应包含 20 个非重复值。
时间列中的数据必须符合时间戳转换支持的某种格式。但是,时间列可以包含任何受支持的转换,因为转换仅影响该列在训练中的使用方式;转换不会影响数据拆分。
您还可以指定分配给每组的训练数据百分比。
在模型训练期间,指定一个列作为时间列。
用于预测的数据分块
默认情况下,Vertex AI 使用按时间顺序拆分算法将预测数据拆分为三个数据分块。我们建议您使用默认拆分。但是,如果要控制将哪些训练数据行用于哪个分块,请使用手动拆分。
如何使用数据分块
在训练过程中,会使用数据分块,如下所示:
模型试验
训练集用于使用不同的预处理、架构和超参数选项组合来训练模型。Vertex AI 会在验证集上评估这些模型的质量,这有助于探索其他选项组合。在训练期间,验证集还用于从定期评估中选择最佳检查点。Vertex AI 使用在并行调整阶段确定的最佳参数和架构来训练两个集成学习模型,如下所述。
模型评估
Vertex AI 会将训练和验证集用作训练数据来训练评估模型。Vertex AI 会使用测试集在此模型上生成最终模型评估指标。这是首次在过程中使用测试集。该方法可确保最终评估指标能公正地反映最终训练出的模型在生产环境中的表现。
应用模型
Vertex AI 会使用训练集和验证集来训练模型。使用测试集验证模型(以选择最佳检查点)。测试集从未训练过,因为损失是根据它计算的。您可以使用此模型获取推理结果。
默认拆分
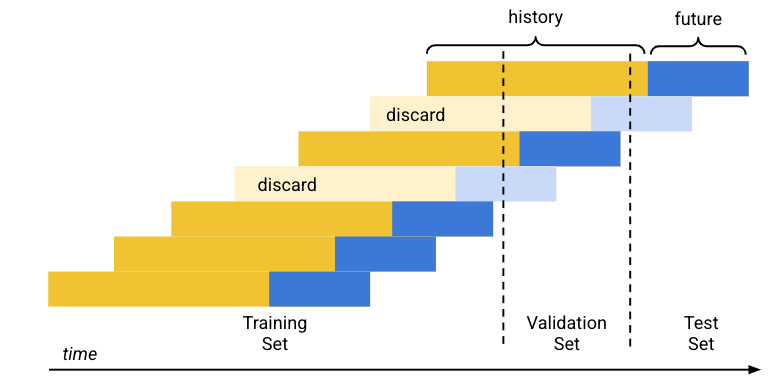
默认(时间顺序)数据拆分的工作原理如下:
- Vertex AI 会按日期对训练数据进行排序。
- 根据预先设定的数据集百分比 (80/10/10),Vertex AI 会将训练数据覆盖的时间段分为三段,每个训练集对应一个时间段。
- Vertex AI 会在每个时序的开头添加空白行,以使模型能够从没有足够历史记录的行(上下文窗口)进行学习。添加的行数是训练时设置的上下文窗口大小。
根据在训练时设置的预测范围大小,Vertex AI 会将未来数据(预测范围)完全落入某一个数据集的每一行用于该数据集。(Vertex AI 会舍弃预测范围横跨两个数据集的行,以避免数据泄露。)
手动拆分
您可以使用数据拆分列来选择要用于训练、验证和测试的特定行。创建训练数据时,添加一个可包含以下某个值(区分大小写)的列:
TRAINVALIDATETEST
每一行都必须具有该列的值;不能为空字符串。
例如:
"TRAIN","sku_id_1","2020-09-21","10" "TEST","sku_id_1","2020-09-22","23" "TRAIN","sku_id_2","2020-09-22","3" "VALIDATE","sku_id_2","2020-09-23","45"
数据拆分列可以具有任何有效的列名称;其转换类型可以是“分类”、“文本”或“自动”。
在模型训练期间将一列指定为数据拆分列。
请务必谨慎,以避免时序之间出现数据泄露。