簡介
本頁面提供概念的簡短總覽,瞭解 Vertex AI 支援的特徵歸因方法。如需深入的技術討論,請參閱AI 說明白皮書。
全域特徵重要性 (模型特徵歸因) 會顯示各項特徵對模型的影響。這些值是每個特徵的百分比,百分比越高,代表該特徵對模型訓練的影響越大。如要查看模型的全域特徵重要性,請檢查評估指標。
時間序列模型的局部特徵歸因會指出資料中各項特徵對預測結果的影響程度。有了這項資訊,您就能確認模型的行為是否符合預期、找出模型偏誤,以及探索改善模型和訓練資料的方式。要求推論時,系統會根據模型提供適當的預測值。要求說明時,您會收到推論結果和特徵歸因資訊。
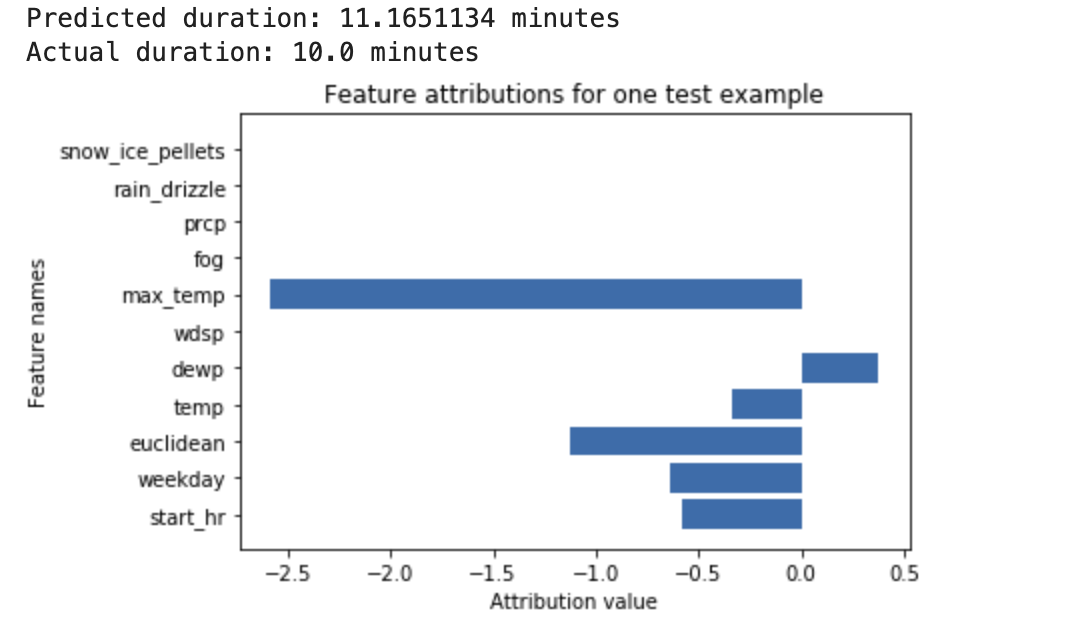
舉例來說,假設您訓練深層類神經網路,根據天氣資料和先前的共乘資料預測騎乘時間長度。如果您只要求從這個模型進行推論,系統會以分鐘為單位,提供預測的單車騎乘時間。如果您要求說明,系統會提供預測的單車行程時間,以及說明要求中每個特徵的歸因分數。相較於您指定的基準值,歸因分數會顯示這項功能對推論值變化的影響程度。選擇對模型有意義的基準,在此案例中為單車騎乘時間中位數。
您可以繪製特徵歸因分數,瞭解哪些特徵對推論結果的影響最大:
優點
檢查特定例項,並彙整訓練資料集中的特徵歸因,有助於深入瞭解模型的運作方式。優點如下:
偵錯模型:特徵歸因可協助偵測資料中的問題,而標準模型評估技術通常會遺漏這些問題。
最佳化模型:您可以找出並移除較不重要的特徵,進而提高模型效率。
概念限制
請注意功能歸因的下列限制:
特徵歸因 (包括 AutoML 的本機特徵重要性) 適用於個別推論。檢查個別推論的特徵歸因可提供實用洞察,但這些洞察可能無法套用至該個別執行個體的整個類別或整個模型。
如要取得 AutoML 模型更具一般性的洞察資料,請參閱模型特徵重要性。如要取得其他模型的更一般化洞察資料,請匯總資料集子集或整個資料集的歸因。
每項歸因只會顯示特徵對特定範例推論的影響程度。單一歸因可能無法反映模型的整體行為。如要瞭解模型在整個資料集上的概略行為,請匯總整個資料集的歸因。
雖然特徵歸因有助於模型偵錯,但無法清楚指出問題是源自模型,還是模型訓練所用的資料。請運用您的判斷力,診斷常見的資料問題,縮小可能原因的範圍。
出處完全取決於模型和用於訓練模型的資料。 說明內容只會揭示模型在資料中發現的模式,無法偵測資料中的任何基礎關係。如果某項特徵的歸因強度高或低,並不代表該特徵與目標之間有或沒有關係。歸因只會顯示模型是否在推論中使用該特徵。
單靠屬性無法判斷模型是否公平、沒有偏見或品質良好。除了歸因之外,請仔細評估訓練資料和評估指標。
如要進一步瞭解限制,請參閱「AI 解釋白皮書」。
改善功能屬性
下列因素對特徵歸因的影響最大:
- 歸因方法會估算 Shapley 值。您可以增加取樣 Shapley 方法的路徑數量,提高近似值的精確度。因此,歸因結果可能會大幅變動。
- 歸因僅表示這項功能對推論值變更的影響程度 (相較於基準值)。請務必選擇有意義的基準,與您向模型提出的問題相關。切換基準線時,歸因值和解讀方式可能會大幅變更。
演算法
Vertex AI 會使用夏普利值提供特徵歸因,這是一種合作賽局理論演算法,可為遊戲中的每位玩家指派特定結果的功勞。套用至機器學習模型時,這表示每個模型特徵都會被視為遊戲中的「玩家」,並根據特定推論的結果分配功勞。對於結構化資料模型,Vertex AI 會使用確切 Shapley 值的近似取樣,稱為「取樣 Shapley」。
如要深入瞭解取樣夏普利值方法的運作方式,請參閱「Bounding the Estimation Error of Sampling-based Shapley Value Approximation」論文。
後續步驟
下列資源提供更多實用教育資料: