Ce guide du débutant est une introduction à l'entraînement personnalisé sur Vertex AI. L'entraînement personnalisé consiste à entraîner un modèle à l'aide d'un framework de ML tel que TensorFlow, PyTorch ou XGBoost.
Objectifs de la formation
Niveau d'expérience sur Vertex AI : débutant
Durée de lecture estimée : 15 minutes
Objectifs du tutoriel :
- Avantages de l'utilisation d'un service géré pour l'entraînement personnalisé.
- Bonnes pratiques pour empaqueter le code d'entraînement.
- Comment envoyer et surveiller un job d'entraînement.
Pourquoi utiliser un service d'entraînement géré ?
Imaginez que vous travaillez sur un nouveau problème de ML. Vous allez ouvrir un notebook, importer vos données et effectuer des tests. Dans ce scénario, vous allez créer un modèle avec le framework de ML de votre choix et exécuter des cellules de notebook pour exécuter une boucle d'entraînement. Une fois l'entraînement terminé, vous allez évaluer les résultats du modèle, apporter des modifications, puis relancer l'entraînement. Ce workflow est utile à des fins d'expérimentation, mais à mesure que vous commencerez à concevoir des applications de production avec le ML, vous constaterez peut-être que l'exécution manuelle des cellules de votre notebook n'est pas l'option la plus pratique.
Par exemple, si votre ensemble de données et votre modèle sont volumineux, il est possible que vous souhaitiez tester l'entraînement distribué. De plus, dans un environnement de production, il est peu probable que vous n'ayez besoin d'entraîner votre modèle qu'une seule fois. Au fil du temps, vous réentraînerez votre modèle pour vous assurer qu'il reste pertinent et continue à produire de bons résultats. Lorsque vous souhaitez automatiser les tests à grande échelle ou réentraîner des modèles pour une application de production, l'utilisation d'un service d'entraînement ML géré va simplifier vos workflows.
Ce guide constitue une introduction à I'entraînement de modèles personnalisés sur Vertex AI. Comme le service d'entraînement est entièrement géré, Vertex AI provisionne automatiquement les ressources de calcul, effectue le job d'entraînement et assure la suppression des ressources de calcul une fois le job d'entraînement terminé. Notez qu'il existe d'autres personnalisations, fonctionnalités et méthodes d'interface avec le service qui ne sont pas abordées ici. L'objectif de ce guide est de fournir une vue d'ensemble. Pour en savoir plus, consultez la documentation sur Vertex AI Training.
Présentation de l'entraînement personnalisé
L'entraînement de modèles personnalisés sur Vertex AI suit ce workflow standard :
Empaqueter le code de votre application d'entraînement.
Configurer et envoyer un job d'entraînement personnalisé.
Surveiller le job d'entraînement personnalisé.
Empaqueter le code de l'application d'entraînement
L'exécution d'un job d'entraînement personnalisé sur Vertex AI s'effectue à l'aide de conteneurs. Les conteneurs sont des packages de votre code d'application, dans ce cas votre code d'entraînement, associés à des dépendances, telles que des versions de bibliothèques spécifiques requises pour exécuter votre code. En plus de faciliter la gestion des dépendances, les conteneurs peuvent s'exécuter pratiquement n'importe où, permettant ainsi d'améliorer la portabilité. L'empaquetage de votre code d'entraînement dans un conteneur avec ses paramètres et ses dépendances pour créer un composant portable est une étape importante lors du passage de vos applications de ML du prototype à la production.
Avant de pouvoir lancer un job d'entraînement personnalisé, vous devez empaqueter votre application d'entraînement. L'application d'entraînement fait dans ce cas référence à un ou plusieurs fichiers, qui effectuent des tâches telles que le chargement de données, le prétraitement de données, la définition d'un modèle et l'exécution d'une boucle d'entraînement. Le service d'entraînement Vertex AI exécute le code que vous lui fournissez. C'est donc à vous de décider des étapes à inclure dans votre application d'entraînement.
Vertex AI fournit des conteneurs prédéfinis pour TensorFlow, PyTorch, XGBoost et Scikit-learn. Ces conteneurs sont mis à jour régulièrement et incluent des bibliothèques courantes dont vous pourriez avoir besoin dans votre code d'entraînement. Vous pouvez choisir d'exécuter votre code d'entraînement avec l'un de ces conteneurs, ou créer un conteneur personnalisé dans lequel votre code d'entraînement et vos dépendances sont préinstallés.
Trois options s'offrent à vous pour empaqueter votre code sur Vertex AI :
- Envoyer un seul fichier Python.
- Créer une distribution source Python.
- Utiliser des conteneurs personnalisés.
Fichier Python
Cette option est appropriée pour effectuer des tests rapides. Vous pouvez utiliser cette option si tout le code nécessaire à l'exécution de votre application d'entraînement se trouve dans un fichier Python et que l'un des conteneurs d'entraînement Vertex AI prédéfinis dispose de toutes les bibliothèques nécessaires à l'exécution de votre application. Pour obtenir un exemple d'empaquetage de votre application d'entraînement sous la forme d'un seul fichier Python, consultez le tutoriel du notebook Entraînement personnalisé et prédiction par lot.
Distribution source Python
Vous pouvez créer une distribution source Python contenant l'application d'entraînement. Vous allez stocker votre distribution source avec le code d'entraînement et les dépendances dans un bucket Cloud Storage. Pour obtenir un exemple d'empaquetage de votre application d'entraînement en tant que distribution source Python, consultez le tutoriel de notebook Entraîner, régler et déployer un modèle de classification PyTorch.
Conteneur personnalisé
Cette option est utile lorsque vous souhaitez avoir davantage de contrôle sur votre application, ou si vous souhaitez exécuter du code non écrit en Python. Dans ce cas, vous allez devoir écrire un Dockerfile, créer votre image personnalisée et la transférer vers Artifact Registry. Pour obtenir un exemple de conteneurisation de votre application d'entraînement, consultez le tutoriel de notebook Profiler les performances d'entraînement des modèles à l'aide de Profiler.
Structure d'application d'entraînement recommandée
Si vous choisissez d'empaqueter votre code en tant que distribution source Python ou en tant que conteneur personnalisé, nous vous recommandons de structurer votre application comme suit :
training-application-dir/
....setup.py
....Dockerfile
trainer/
....task.py
....model.py
....utils.py
Créez un répertoire pour stocker l'ensemble du code de votre application d'entraînement, dans ce cas, training-application-dir. Ce répertoire contient un fichier setup.py si vous utilisez une distribution source Python ou un Dockerfile si vous utilisez un conteneur personnalisé.
Dans les deux scénarios, ce répertoire de haut niveau contient également un sous-répertoire trainer, qui contient tout le code permettant d'exécuter l'entraînement. Dans trainer, task.py est le point d'entrée principal de votre application. Ce fichier exécute l'entraînement du modèle. Vous pouvez choisir de placer tout votre code dans ce fichier, mais pour les applications de production, vous aurez probablement d'autres fichiers (par exemple model.py, data.py, utils.py).
Exécuter un entraînement personnalisé
Les jobs d'entraînement sur Vertex AI provisionnent automatiquement des ressources de calcul, exécutent le code de l'application d'entraînement et garantissent la suppression des ressources de calcul une fois le job d'entraînement terminé.
À mesure que vous élaborez des workflows plus complexes, il est probable que vous utilisiez le SDK Vertex AI pour Python pour configurer, envoyer et surveiller vos jobs d'entraînement. Cependant, la première fois que vous exécutez un job d'entraînement personnalisé, il peut être plus facile d'utiliser la console Google Cloud.
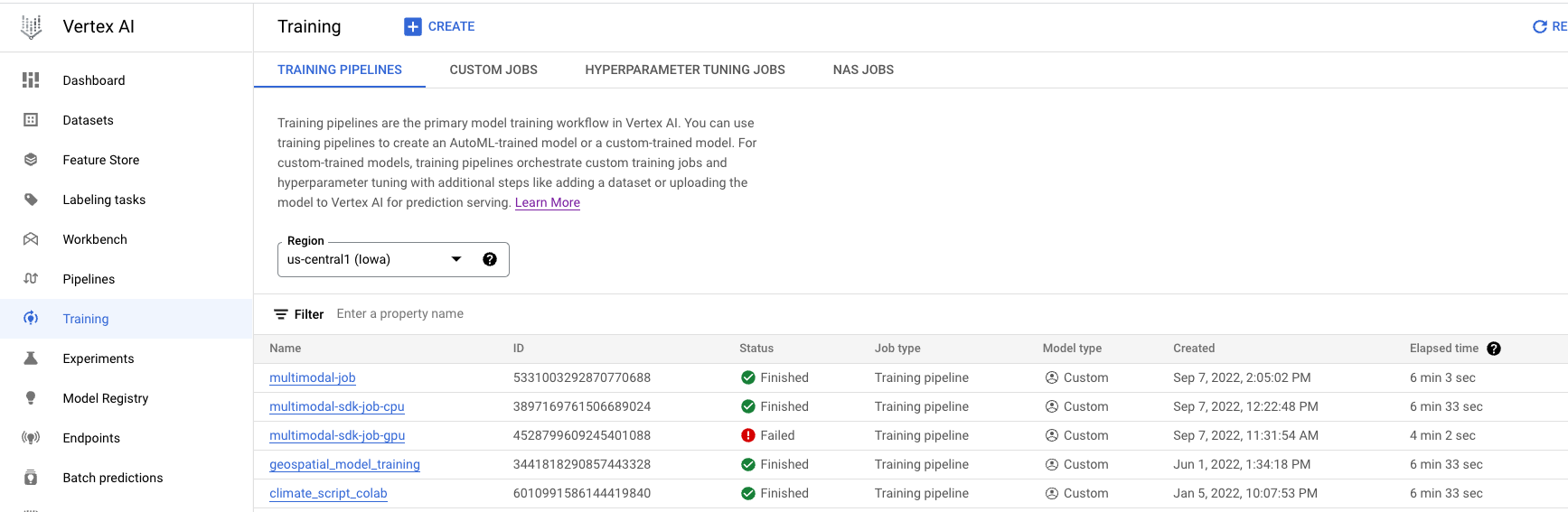
- Accédez à la page Entraînement dans la section "Vertex AI" de la console Cloud. Vous pouvez créer un nouveau job d'entraînement en cliquant sur le bouton CRÉER.
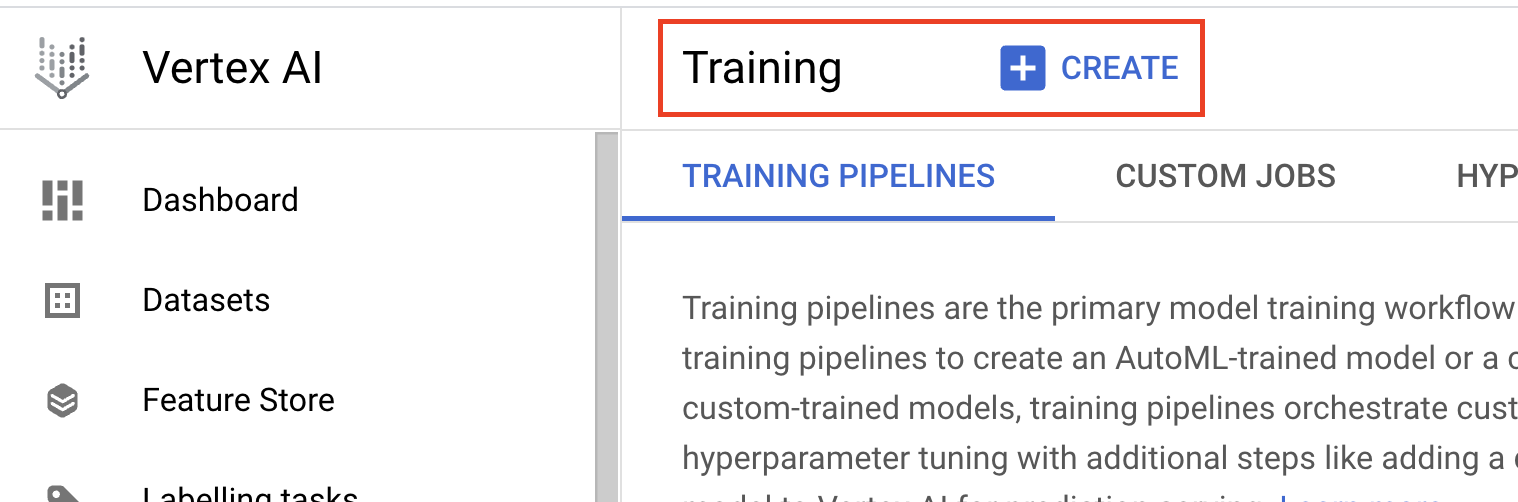
- Sous Méthode d'entraînement, sélectionnez Entraînement personnalisé (avancé).
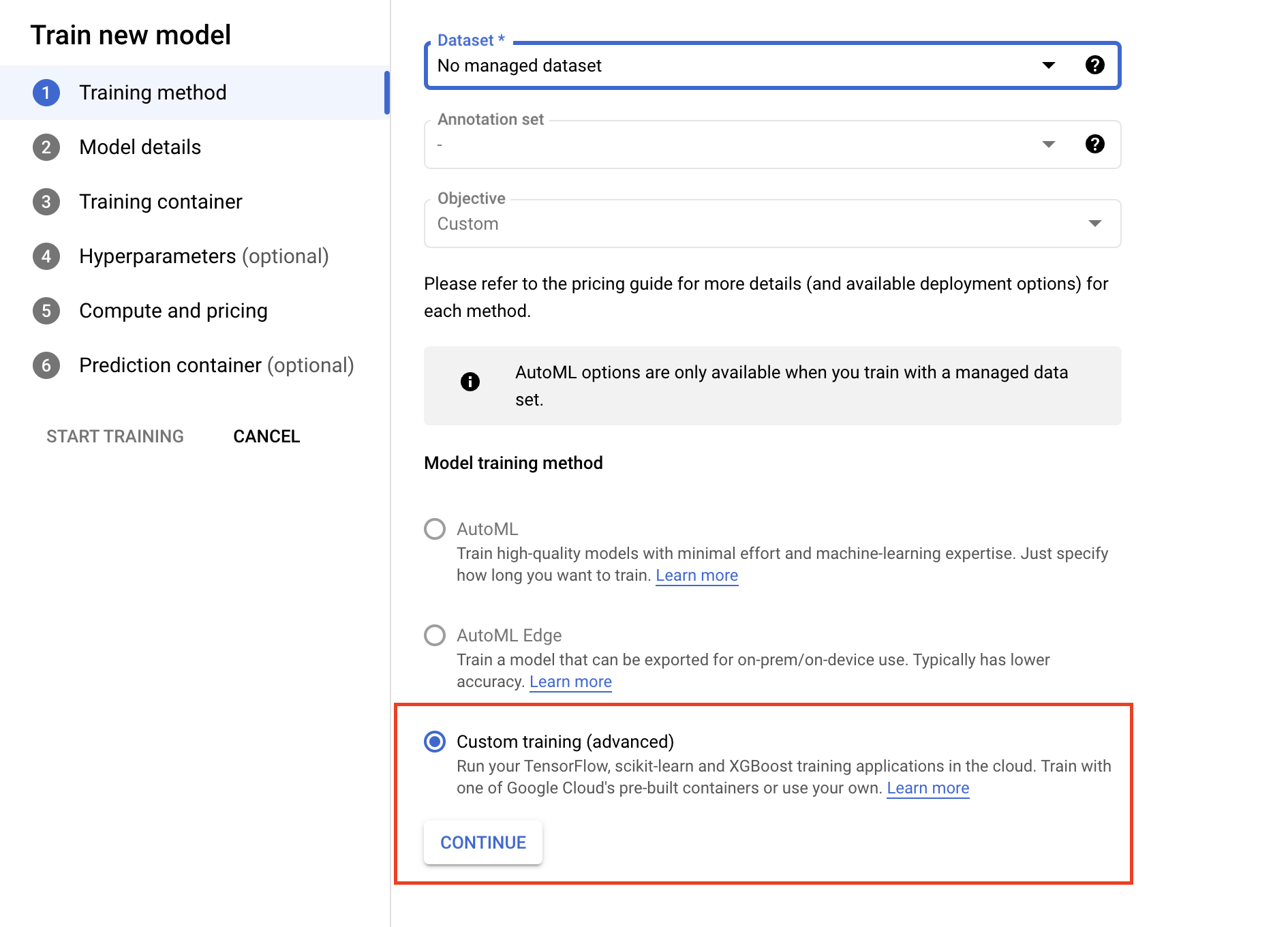
- Dans la section "Conteneur d'entraînement", sélectionnez un conteneur prédéfini ou personnalisé suivant la façon dont vous avez empaqueté votre application.
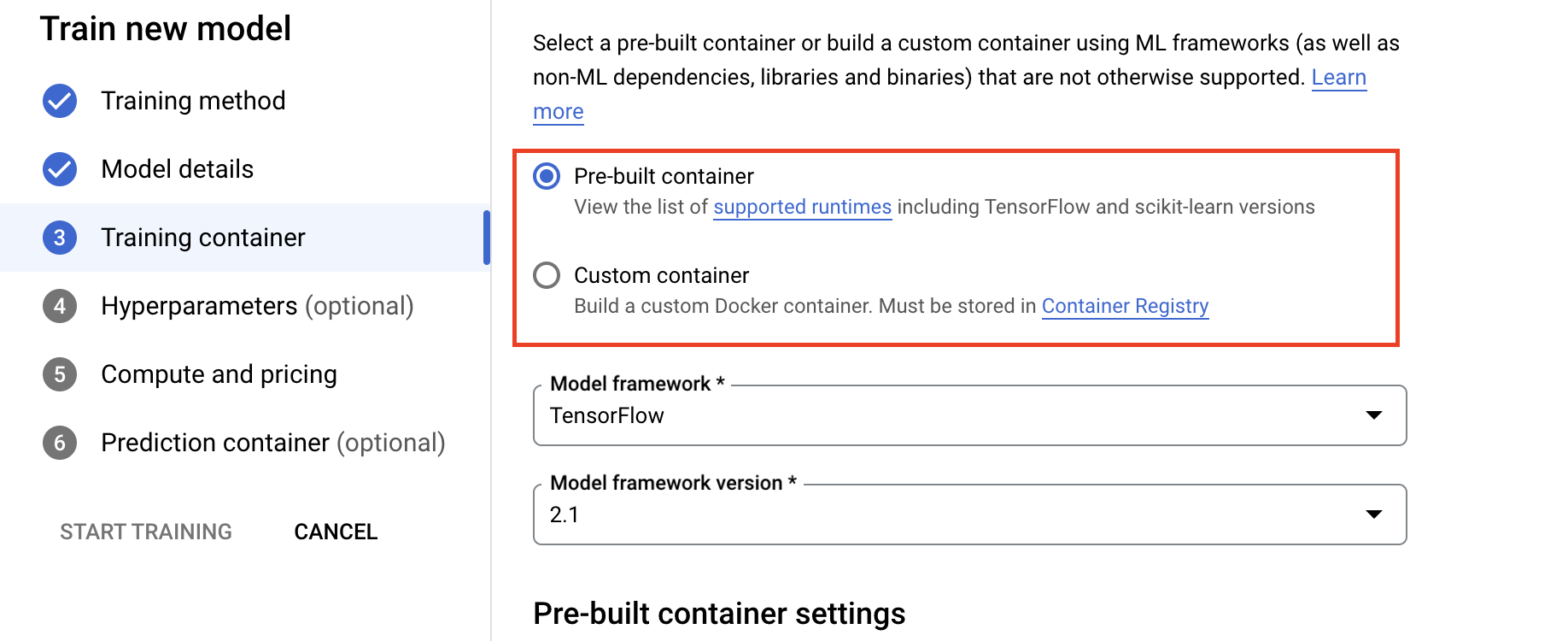
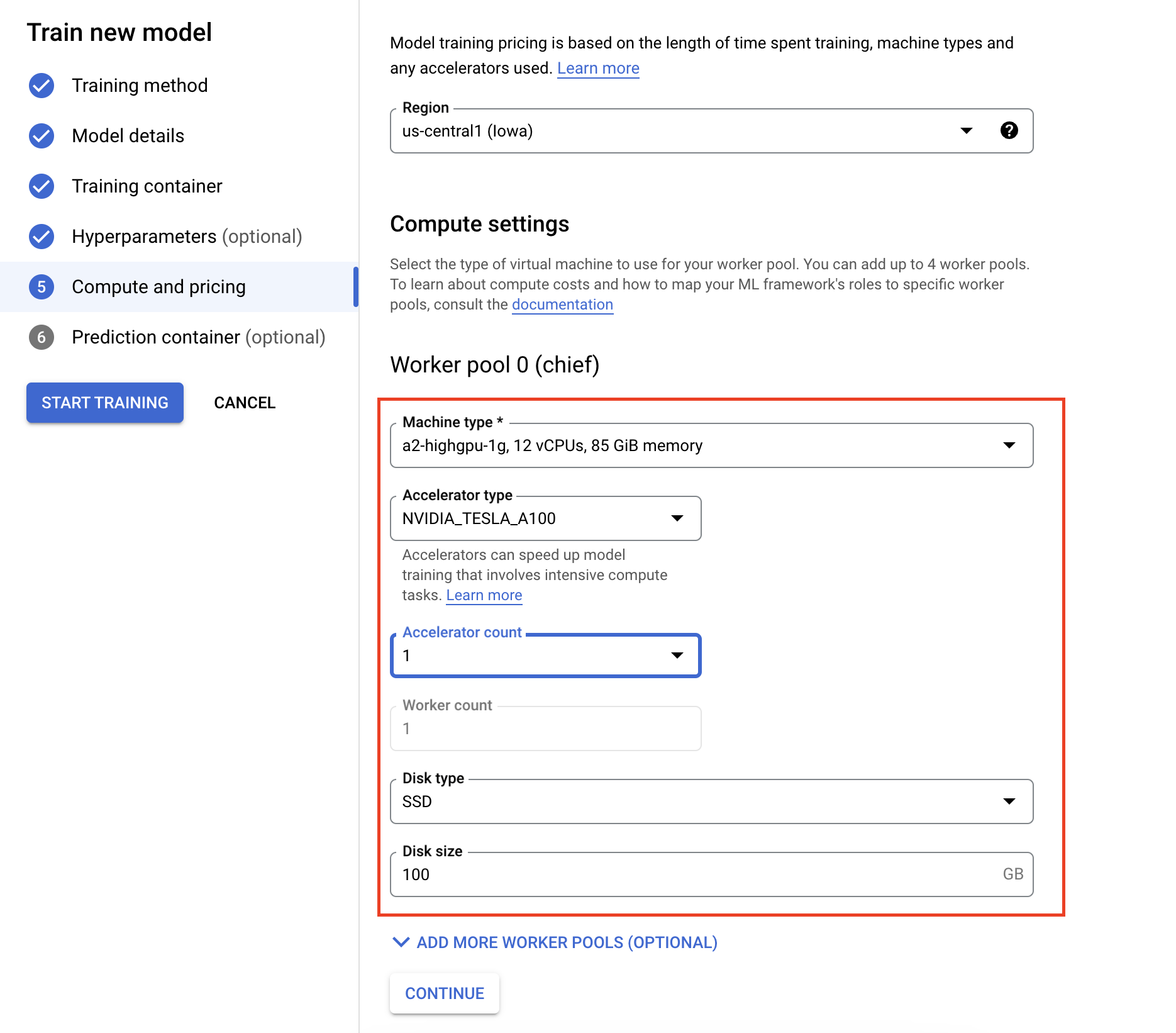
- Sous Options de calcul et tarifs, spécifiez le matériel pour le job d'entraînement. Pour l'entraînement à nœud unique, il vous suffit de configurer le pool de nœuds de calcul 0. Si vous souhaitez exécuter un entraînement distribué, vous devez comprendre les autres pools de nœuds de calcul. Vous pouvez en apprendre plus dans la section entraînement distribué.
La configuration du conteneur de prédiction est facultative. Si vous souhaitez uniquement entraîner un modèle sur Vertex AI et accéder aux artefacts de modèle enregistrés obtenus, vous pouvez ignorer cette étape. Si vous souhaitez héberger et déployer le modèle obtenu sur le service de prédiction géré Vertex AI, vous aurez besoin de configurer un conteneur de prédiction. En savoir plus sur les conteneurs de prédiction.
Surveiller les jobs d'entraînement
Vous pouvez surveiller votre job d'entraînement dans la console Google Cloud. Vous y trouverez la liste de tous les jobs qui ont été exécutés. Vous pouvez cliquer sur un job particulier et examiner les journaux en cas de problème.