この初心者向けガイドでは、Vertex AI でのカスタム トレーニングの概要を説明します。カスタム トレーニングとは、TensorFlow、PyTorch、XGBoost などの ML フレームワークを使用してモデルをトレーニングすることを指します。
学習目標
Vertex AI の経験レベル: 初級
推定所要時間: 15 分
チュートリアルの内容
- カスタム トレーニングにマネージド サービスを使用するメリット。
- トレーニング コードをパッケージ化するためのベスト プラクティス
- トレーニング ジョブの送信方法とモニタリング方法。
マネージド トレーニング サービスを使用する理由
新しい ML の問題に取り組んでいるとします。ノートブックを開き、データをインポートして、テストを実行します。このシナリオでは、選択した ML フレームワークでモデルを作成し、ノートブックのセルを実行してトレーニング ループを実行します。トレーニングが完了したら、モデルの結果を評価して変更を加えた後、トレーニングを再実行します。このワークフローはテストでは便利ですが、ML で本番環境アプリケーションを構築することを考えると、ノートブックのセルを手動で実行することが最も便利な選択肢ではないことに気づくかもしれません。
たとえば、データセットとモデルが大きい場合は、分散トレーニングを試してみることをおすすめします。また、本番環境でモデルのトレーニングが 1 回で済むことはほとんどありません。時間をかけてモデルを再トレーニングすることで、モデルを最新の状態を保ち、価値のある結果を出し続けられるようにします。規模を拡大してテストを自動化したい場合や本番環境のアプリケーション用のモデルを再度トレーニングしたい場合は、マネージド ML トレーニング サービスを利用すると、ワークフローが簡素化されます。
このガイドでは、Vertex AI でのカスタムモデルのトレーニングの概要を説明します。トレーニング サービスはフルマネージドであるため、Vertex AI が自動的にコンピューティング リソースをプロビジョニングし、トレーニング タスクを実行して、トレーニング ジョブが終了するとコンピューティング リソースを確実に削除します。なお、ここでは説明しきれないカスタマイズや機能、サービスとのインターフェース方法もあります。このガイドは、概要の説明を目的としています。詳細については、Vertex AI Training のドキュメントをご覧ください。
カスタム トレーニングの概要
Vertex AI でのカスタムモデルのトレーニングは、次の標準的なワークフローに沿って行います。
トレーニング アプリケーションのコードをパッケージ化する。
カスタム トレーニング ジョブを構成して送信する。
カスタム トレーニング ジョブをモニタリングする。
トレーニング アプリケーション コードのパッケージ化
Vertex AI におけるカスタム トレーニング ジョブの実行には、コンテナを使用します。コンテナとは、アプリケーション コード(この場合はトレーニング コード)を、コードの実行に必要な特定バージョンのライブラリなどの依存関係とともにパッケージ化したものです。コンテナは、依存関係の管理を容易にするだけでなく、ほぼどこでも実行できるため、移植性が高まります。移植性の高いコンポーネントを作成するために、トレーニング コードをパラメータや依存関係とともにコンテナにパッケージ化することは、ML アプリケーションをプロトタイプから本番環境に移行する際の重要なステップです。
トレーニング アプリケーションは、カスタム トレーニング ジョブを起動する前にパッケージ化する必要があります。この場合のトレーニング アプリケーションは、データの読み込み、データの前処理、モデルの定義、トレーニング ループの実行などのタスクを実行する 1 つまたは複数のファイルを指します。Vertex AI トレーニング サービスは、ユーザーが提供したコードを実行するため、トレーニング アプリケーションに含めるステップはすべてユーザーに任されています。
Vertex AI には、TensorFlow、PyTorch、XGBoost、scikit-learn 用のビルド済みコンテナが用意されています。これらのコンテナは定期的に更新され、トレーニング コードで必要になる共通ライブラリが含まれています。ユーザーは、これらのコンテナのいずれかを使用してトレーニング コードを実行するか、トレーニング コードと依存関係がプリインストールされたカスタム コンテナを作成するかを選択できます。
Vertex AI におけるコードのパッケージ化には、次の 3 つの方法があります。
- 1 つの Python ファイルを送信する。
- Python ソース ディストリビューションを作成する。
- カスタム コンテナを使用する。
Python ファイル
この方法は簡単なテストに適しています。この方法は、トレーニング アプリケーションの実行に必要なすべてのコードが 1 つの Python ファイルに含まれており、ビルド済みの Vertex AI トレーニング コンテナのいずれかにアプリケーションの実行に必要なすべてのライブラリが含まれている場合に使用できます。トレーニング アプリケーションを 1 つの Python ファイルとしてパッケージ化する例については、ノートブック チュートリアルのカスタム トレーニングとバッチ予測をご覧ください。
Python ソース ディストリビューション
トレーニング アプリケーションを含む Python ソース ディストリビューションを作成できます。トレーニング コードと依存関係を含むソース ディストリビューションは、Cloud Storage バケットに保存します。トレーニング アプリケーションを Python ソース ディストリビューションとしてパッケージ化する例については、ノートブックのチュートリアル PyTorch 分類モデルのトレーニング、チューニング、デプロイをご覧ください。
カスタム コンテナ
この方法は、アプリケーションをより詳細に制御したい場合や、Python で記述されていないコードを実行したい場合に有用です。この場合、Dockerfile を作成し、カスタム イメージをビルドして Artifact Registry に push する必要があります。トレーニング アプリケーションをコンテナ化する例については、ノートブック チュートリアルの Profiler を使用してモデルのトレーニング パフォーマンスをプロファイリングするをご覧ください。
推奨されるトレーニング アプリケーションの構造
コードを Python ソース ディストリビューションやカスタム コンテナとしてパッケージ化する場合は、次のようにアプリケーションを構築することをおすすめします。
training-application-dir/
....setup.py
....Dockerfile
trainer/
....task.py
....model.py
....utils.py
すべてのトレーニング アプリケーション コードを保存するディレクトリ(この場合は training-application-dir)を作成します。このディレクトリには、Python ソース ディストリビューションを使用している場合は setup.py ファイル、カスタム コンテナを使用している場合は Dockerfile を保存します。
どちらのシナリオでも、この上位ディレクトリにはサブディレクトリ trainer も含まれ、そこには、トレーニングを実行するためのすべてのコードが置かれています。trainer の中では、task.py がアプリケーションへのメインのエントリポイントです。このファイルがモデルのトレーニングを実行します。すべてのコードをこのファイルに含めることもできますが、本番環境のアプリケーションでは、model.py、data.py、utils.py などのファイルが加わる可能性があります。
カスタム トレーニングの実行
Vertex AI のトレーニング ジョブでは、コンピューティング リソースのプロビジョニング、トレーニング アプリケーション コードの実行、トレーニング ジョブ終了後のコンピューティング リソースの削除が自動的に行われます。
より複雑なワークフローを構築するようになると、トレーニング ジョブの構成、送信、モニタリングには Vertex AI SDK for Python を使用することになるでしょう。しかし、カスタム トレーニング ジョブを初めて実行する場合は、Google Cloud コンソールを使用するほうが簡単です。
- Cloud コンソールの [Vertex AI] セクションで [トレーニング] に移動します。[作成] ボタンをクリックすると、新しいトレーニング ジョブを作成できます。
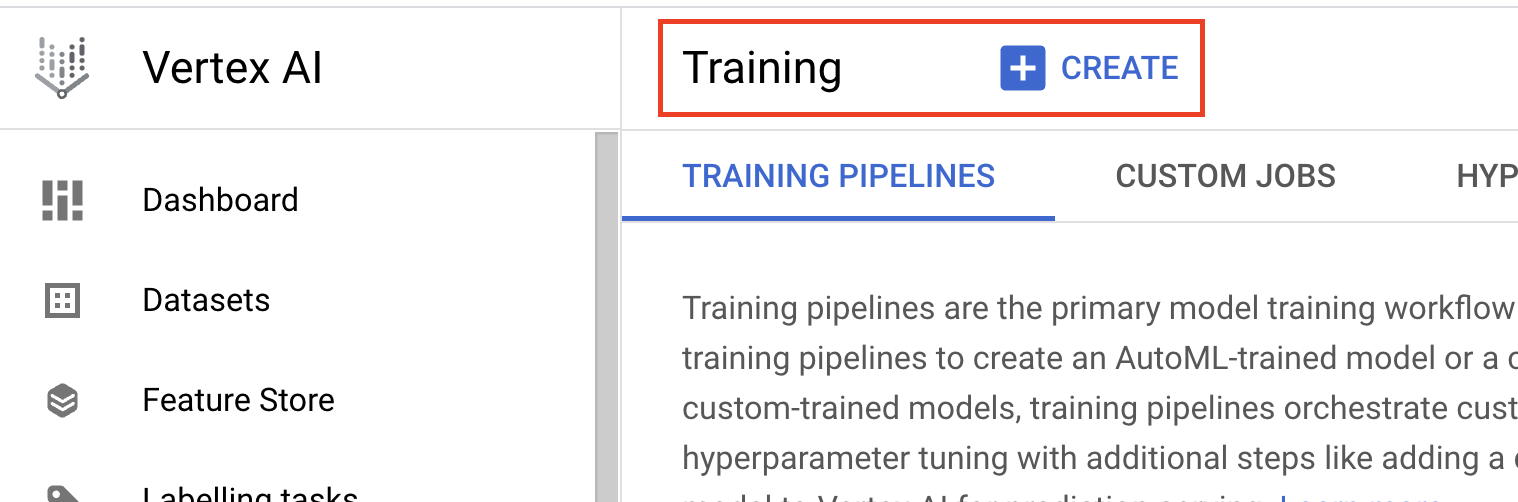
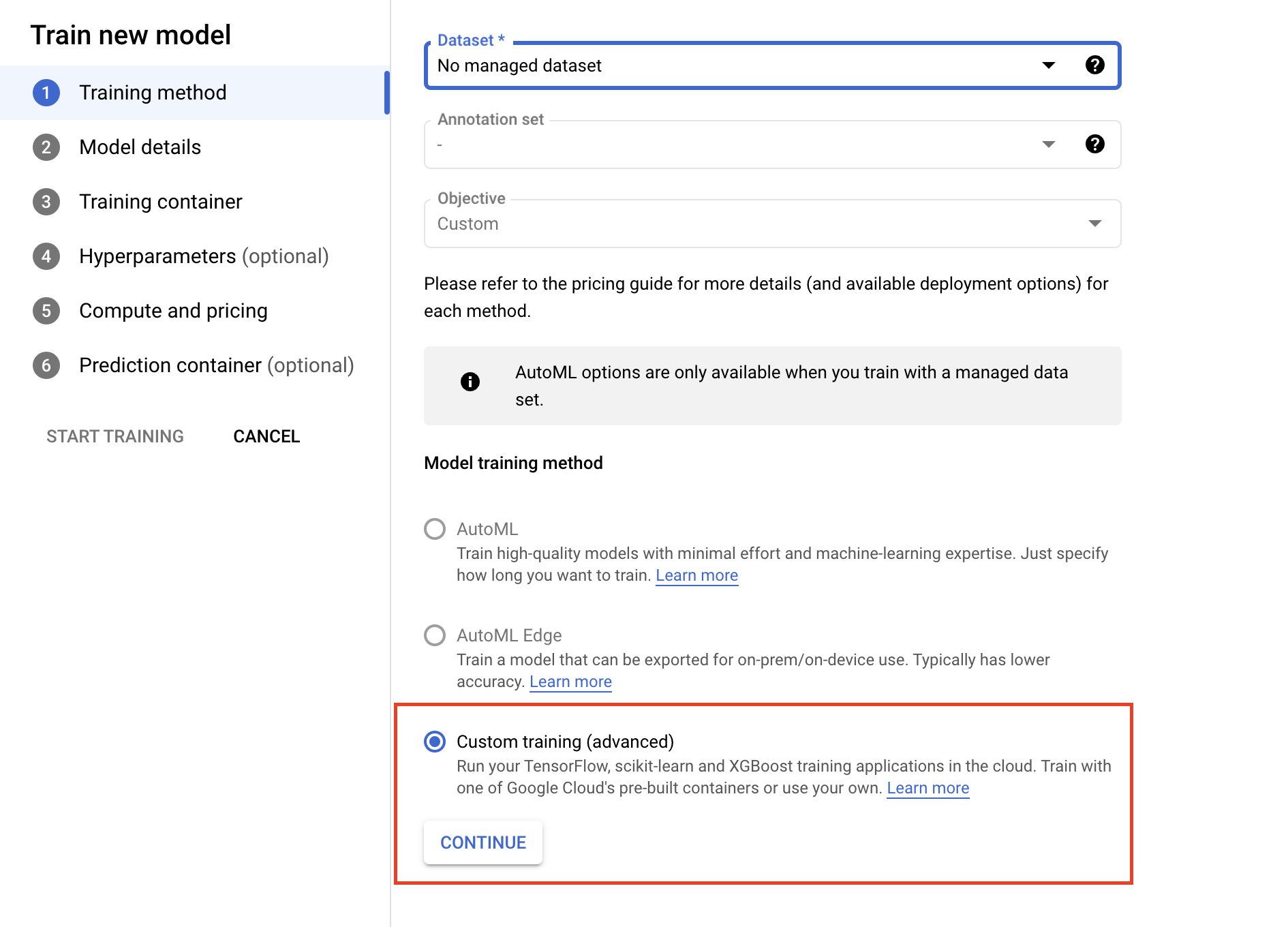
- モデルの [トレーニング方法] で、[カスタム トレーニング(上級者向け)] を選択します。
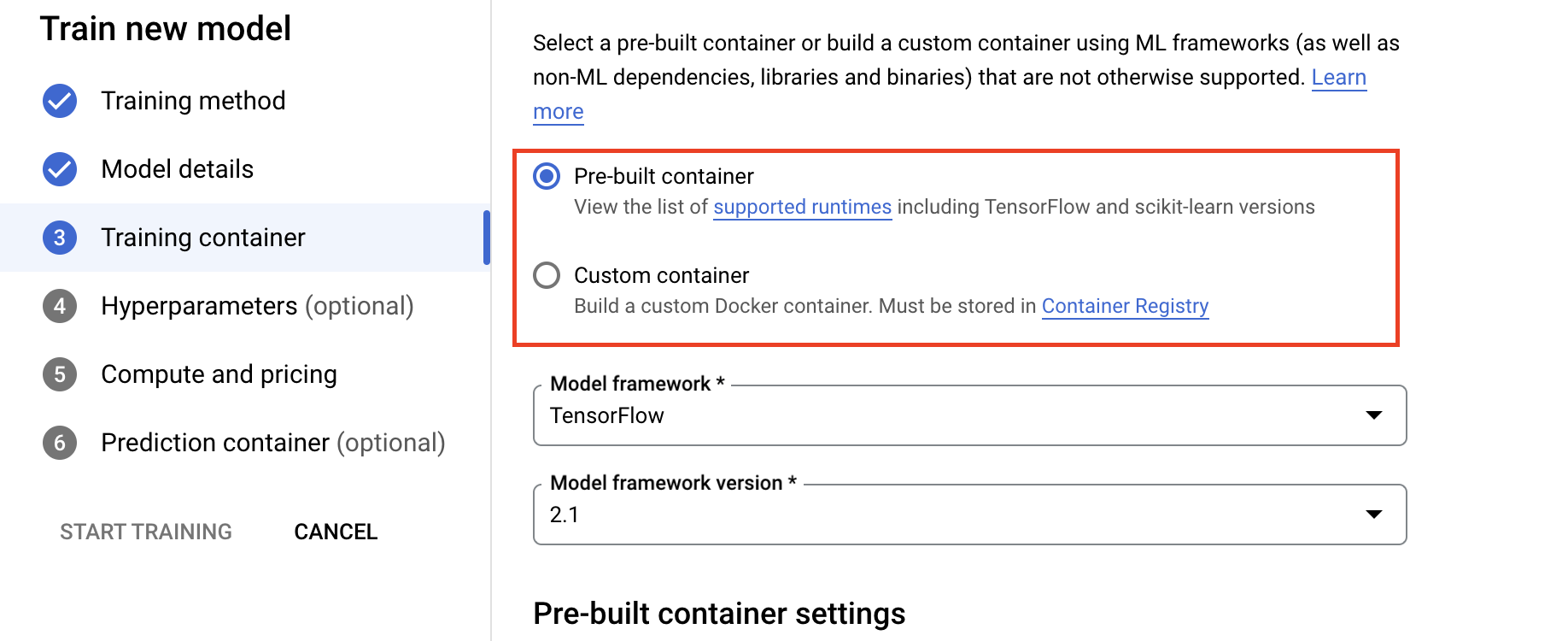
- [トレーニング コンテナ] セクションで、アプリケーションのパッケージ化方法に応じて、[ビルド済みのコンテナ] または [カスタム コンテナ] を選択します。
- [コンピューティングと料金] で、トレーニング ジョブのハードウェアを指定します。単一ノード トレーニングでは、Worker Pool 0 のみを構成する必要があります。分散トレーニングの実行に関心がある場合は、他のワーカープールについて理解する必要があります。詳細については、分散トレーニングをご覧ください。
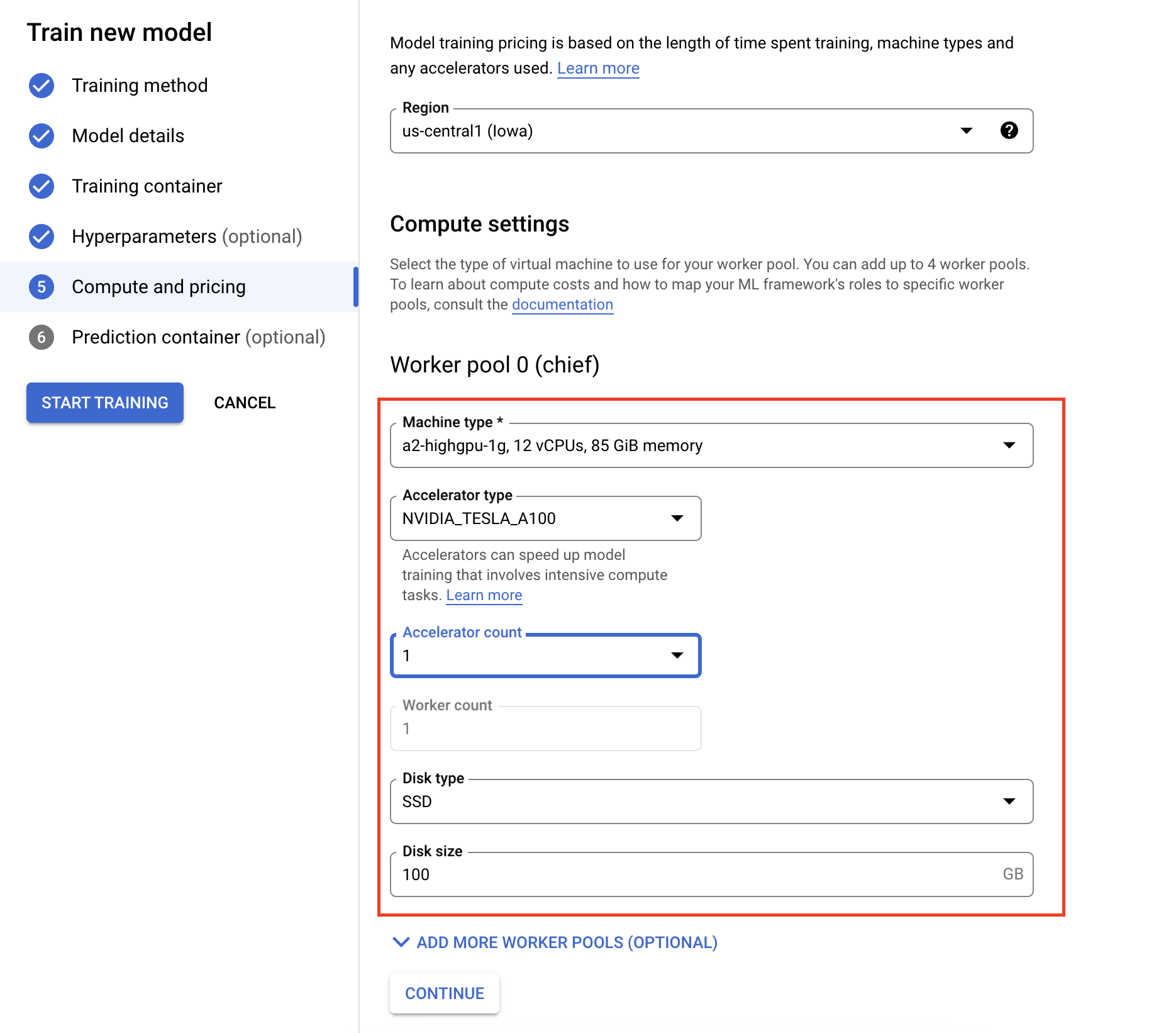
予測コンテナを構成することは任意です。Vertex AI でモデルをトレーニングし、生成された保存済みモデルのアーティファクトにアクセスするだけであれば、この手順は省略できます。生成されたモデルを Vertex AI マネージド予測サービスでホストしてデプロイする場合は、予測コンテナを構成する必要があります。予測コンテナの詳細については、こちらをご覧ください。
トレーニング ジョブのモニタリング
トレーニング ジョブは、Google Cloud コンソールでモニタリングできます。実行されたすべてのジョブの一覧が表示されます。何か問題が発生した場合は、特定のジョブをクリックしてログを調べることができます