此新手指南是 Vertex AI 上自定义训练的简介。自定义训练是指使用 TensorFlow、PyTorch 或 XGBoost 等机器学习框架来训练模型。
学习目标
Vertex AI 体验级别:新手
预计阅读时间:15 分钟
您将学到的内容:
- 使用托管式服务进行自定义训练的优势
- 封装训练代码的最佳做法。
- 如何提交和监控训练作业。
为何使用代管式训练服务?
假设您正在解决一个新的机器学习问题。您可以打开笔记本、导入数据并运行实验。在此场景中,您将使用您选择的机器学习框架创建模型,并执行笔记本单元来运行训练循环。 训练完成后,您需要评估模型的结果,进行更改,然后重新运行训练。此工作流对于实验非常有用,但当您开始考虑使用机器学习构建生产应用时,可能会发现手动执行笔记本单元不是最方便的选项。
例如,如果您的数据集和模型较大,您可能需要尝试分布式训练。此外,在生产环境设置中,模型不太可能只需要训练一次。随着时间的推移,您需要重新训练模型,以确保其保持最新状态并产生有价值的结果。如果您想大规模地自动进行实验或重新训练生产应用的模型,使用代管式机器学习训练服务可简化您的工作流。
本指南介绍如何在 Vertex AI 上训练自定义模型。由于训练服务是全托管式的,因此 Vertex AI 会自动预配计算资源、执行训练任务,并确保在训练作业完成后删除计算资源。请注意,还有其他一些自定义设置、功能以及与此处未涵盖的服务建立连接的方法。本指南仅提供相关概览。如需了解详情,请参阅 Vertex AI Training 文档。
自定义训练概览
在 Vertex AI 上训练自定义模型时需要遵循以下标准工作流:
封装训练应用代码。
配置并提交自定义训练作业。
监控自定义训练作业。
封装训练应用代码
在 Vertex AI 上运行自定义训练作业是通过容器完成的。 容器是您的应用代码(在本例中为训练代码)的封装包,以及依赖项(例如运行代码所需的库特定版本)。除了帮助管理依赖项,容器几乎可以在任何地方运行,从而提高了可移植性。在将机器学习应用从原型迁移到生产环境时,一个非常重要的步骤就是将训练代码及其参数和依赖项打包到容器中以创建可移植的组件。
在启动自定义训练作业之前,您需要打包您的训练应用。本例中的训练应用是指一个或多个文件,这些文件执行加载数据、预处理数据、定义模型和执行训练循环等任务。Vertex AI 训练服务将运行您提供的任何代码,因此您可以完全自行决定要在训练应用中添加哪些步骤。
Vertex AI 为 TensorFlow、PyTorch、XGBoost 和 Scikit-learn 提供了预构建容器。这些容器会定期更新,并在训练代码中包括您可能需要的常用库。您可以选择使用其中一个容器运行训练代码,也可以创建一个预装了训练代码和依赖项的自定义容器。
您可以通过以下三种方式将代码封装到 Vertex AI 上:
- 提交单个 Python 文件。
- 创建 Python 源分发。
- 使用自定义容器。
Python 文件
此选项适用于快速实验。如果执行训练应用所需的所有代码位于一个 Python 文件中,并且其中一个预建的 Vertex AI 训练容器具有运行应用所需的所有库,则可以使用此选项。如需查看将训练应用打包为单个 Python 文件的示例,请参阅笔记本教程自定义训练和批量预测。
Python 源分发
您可以创建 Python 源分发,其中包含您的训练应用。将包含训练代码和依赖项的源分发存储在 Cloud Storage 存储桶中。如需查看将训练应用打包为 Python 源分发的示例,请参阅笔记本教程训练、调整和部署 PyTorch 分类模型。
自定义容器
当您需要更好地控制应用,或者想要运行不是用 Python 编写的代码时,此选项很有用。在这种情况下,您需要编写 Dockerfile、构建自定义映像并将其推送到 Artifact Registry。如需查看将训练应用容器化的示例,请参阅笔记本教程使用 Profiler 分析模型训练性能。
推荐的训练应用结构
如果您选择将代码打包为 Python 源分发或自定义容器,我们建议您按如下方式构建应用:
training-application-dir/
....setup.py
....Dockerfile
trainer/
....task.py
....model.py
....utils.py
创建一个目录,以存储所有训练应用代码(在本例中为 training-application-dir)。如果您使用的是 Python 源分发,则此目录将包含 setup.py 文件;如果您使用的是自定义容器,则包含 Dockerfile。
在这两个场景中,此概要目录还包含子目录 trainer,其中包含用于执行训练的所有代码。在 trainer 中,task.py 是应用的主要入口点。此文件执行模型训练。您可以选择将所有代码放入此文件中,但对于生产应用,您可能还拥有其他文件,例如 model.py、data.py、utils.py 等。
运行自定义训练
Vertex AI 上的训练作业会自动预配计算资源、执行训练应用代码,并确保在训练作业完成后删除计算资源。
构建更复杂的工作流时,您可能需要使用 Python 版 Vertex AI SDK 来配置、提交和监控训练作业。但是,首次运行自定义训练作业时,使用 Google Cloud 控制台会更加方便。
- 导航到 Cloud 控制台的 Vertex AI 部分中的训练。您可以通过点击创建按钮来创建新的训练作业。

- 在训练方法下,选择自定义训练(高级)。
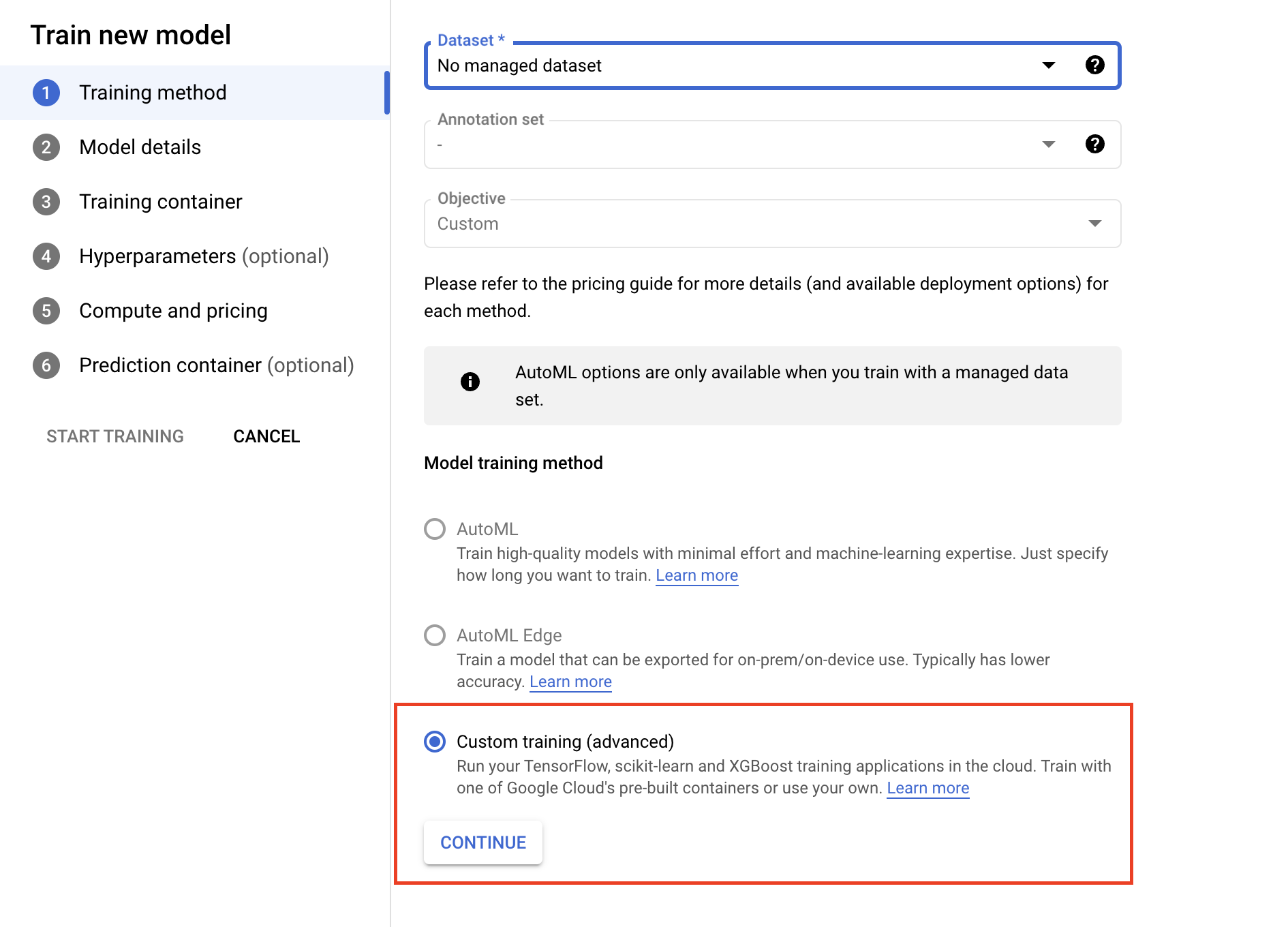
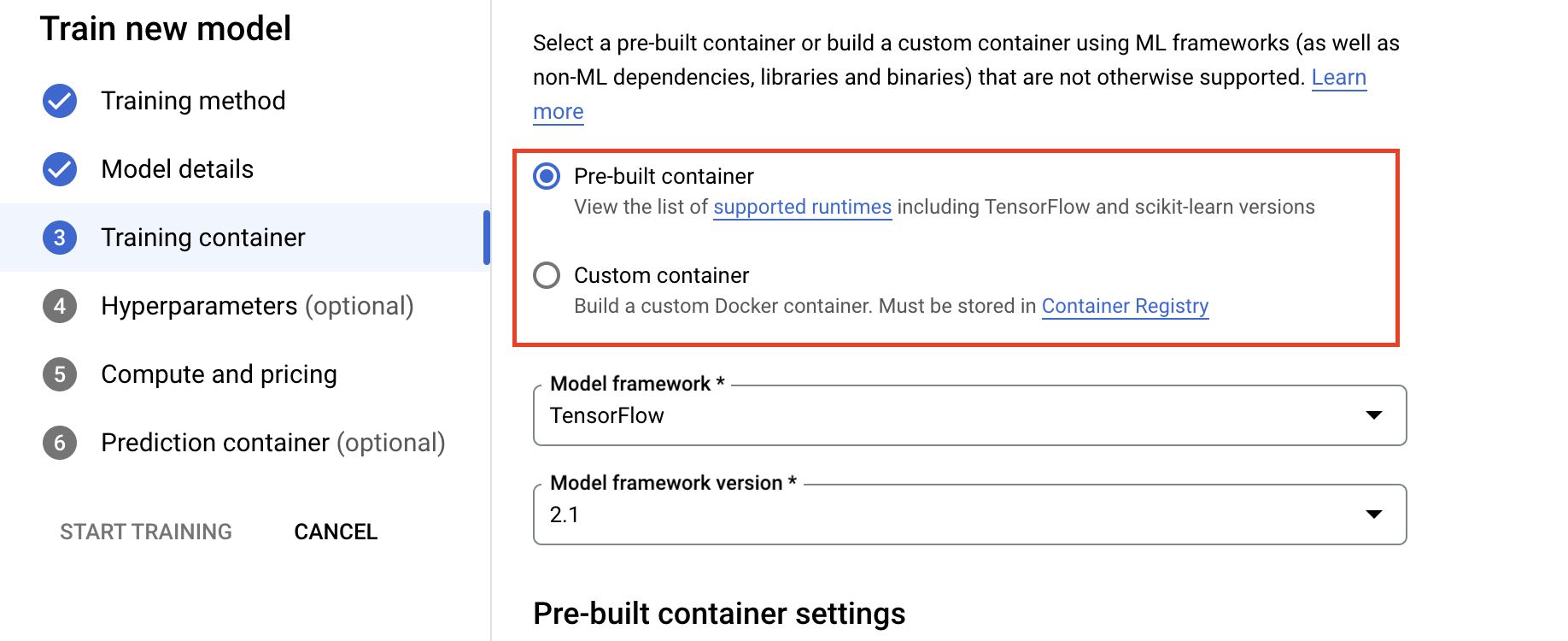
- 在“训练容器”部分下,选择预构建或自定义容器,具体取决于应用的打包方式。
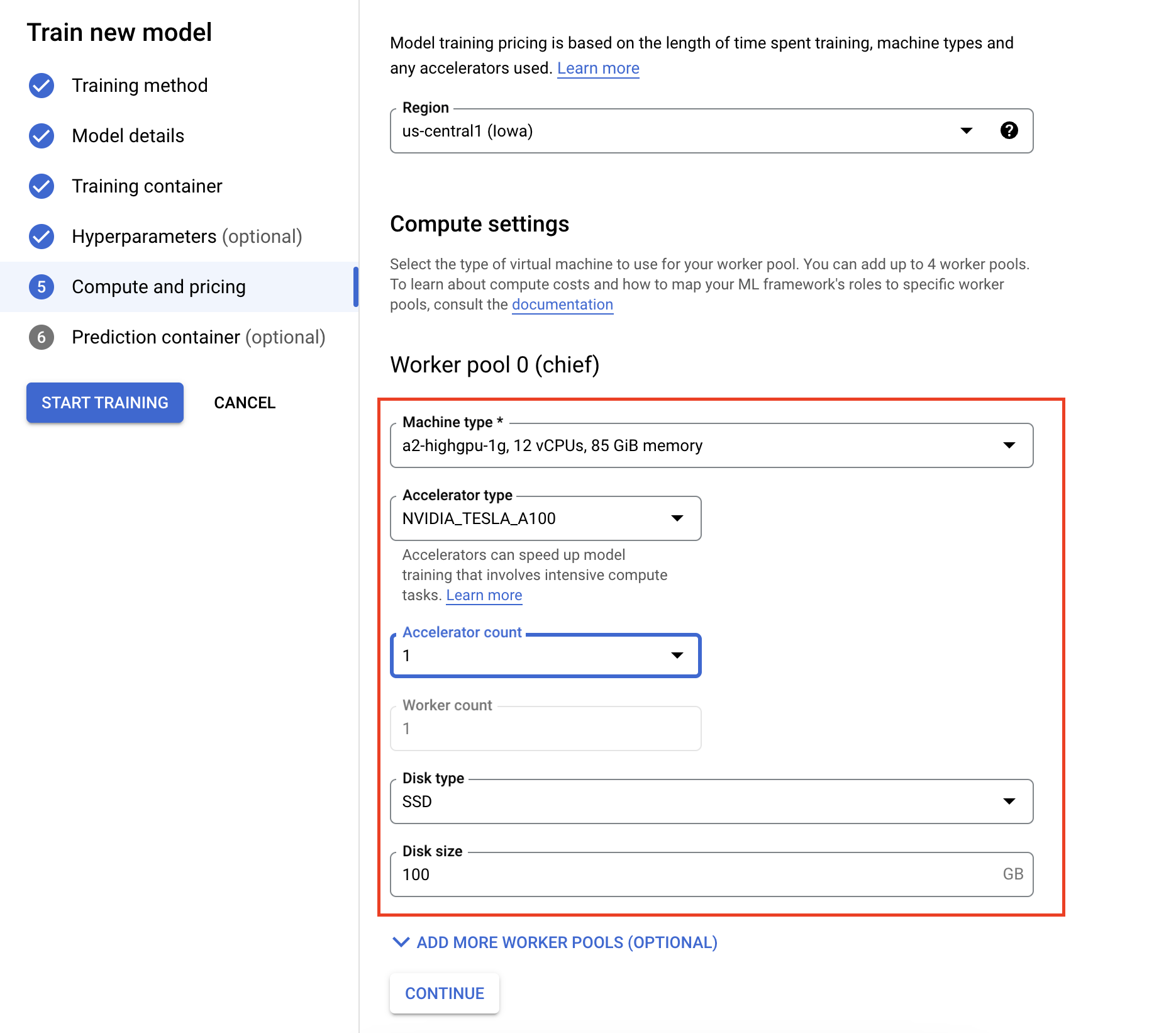
- 在计算和价格下,为训练作业指定硬件。对于单节点训练,您只需配置工作器池 0。如果您有兴趣运行分布式训练,则需要了解其他工作器池,并且可以详细了解分布式训练。
配置预测容器是可选操作。如果您只想在 Vertex AI 上训练模型并访问生成的已保存模型工件,则可以跳过此步骤。如果要在 Vertex AI 代管式预测服务上托管和部署生成的模型,则需要配置预测容器。详细了解预测容器。
监控训练作业
您可以在 Google Cloud 控制台中监控训练作业。您将看到已运行的所有作业的列表。您可以点击特定作业并检查日志(如果出现问题)。
