NVIDIA Triton en Vertex AI
Vertex AI admite la implementación de modelos en el servidor de inferencia de Triton que se ejecutan en un contenedor personalizado publicado por NVIDIA GPU Cloud (NGC): Imagen de servidor de inferencia de Triton de NVIDIA. Las imágenes de Triton de NVIDIA tienen todos los paquetes y las configuraciones necesarios que cumplen con los requisitos de Vertex AI para las imágenes personalizadas de contenedor de entrega. La imagen contiene el servidor de inferencia de Triton compatible con los modelos de TensorFlow, PyTorch, TensorRT, ONNX y OpenVINO. La imagen también incluye el backend de FIL (Biblioteca de inferencia de bosque) que admite la ejecución de frameworks de AA, como XGBoost, LightGBM y Scikit-Learn.
Triton carga los modelos y expone los extremos de REST de administración de modelo, inferencia y estado que usan protocolos de inferencia estándar. Mientras se implementa un modelo en Vertex AI, Triton reconoce los entornos de Vertex AI y adopta el protocolo de Vertex AI Inference para las verificaciones de estado y solicitudes de inferencia.
En la siguiente lista, se describen las funciones clave y los casos prácticos del servidor de inferencia de Triton de NVIDIA:
- Compatibilidad con varios frameworks de aprendizaje automático y aprendizaje profundo: Triton admite la implementación de varios modelos y una combinación de frameworks y formatos de modelo: backends de FIL, TensorFlow (modelo guardado y GraphDef), PyTorch (TorchScript), TensorRT, ONNX y OpenVINO para admitir frameworks como XGBoost, LightGBM, scikit-learn y cualquier formato de modelo personalizado de Python o C++.
- Ejecución simultánea de varios modelos: Triton permite que varios modelos, varias instancias del mismo modelo o ambos se ejecuten de forma simultánea en el mismo recurso de procesamiento con cero o más GPU.
- Ensamble de modelos (encadenamiento o canalización): el ensamble de Triton admite casos prácticos en los que varios modelos se componen como una canalización (o un DAG, grafo acíclico dirigido) con tensores de entrada y salida conectados entre ellos. Además, con un backend de Python de Triton, puedes incluir cualquier lógica de flujo de procesamiento previo, procesamiento posterior o control que se defina por secuencias de comandos de lógicas empresariales (BLS).
- Ejecución en backends de GPU y CPU: Triton admite inferencia para modelos implementados en nodos con CPU y GPU.
- Agrupación en lotes dinámica de solicitudes de inferencia: En los modelos que admiten el procesamiento por lotes, Triton tiene algoritmos integrados de programación y procesamiento por lotes. Estos algoritmos combinan de forma dinámica las solicitudes de inferencia individuales en lotes en el lado del servidor para mejorar la capacidad de procesamiento de la inferencia y aumentar el uso de la GPU.
Para obtener más información sobre el servidor de inferencia de Triton de NVIDIA, consulta la documentación de Triton.
Imágenes de contenedor de Triton de NVIDIA disponibles
En la siguiente tabla, se muestra lo siguiente:Imágenes de Triton Docker disponibles en el catálogo de NVIDIA NGC. Elige una imagen según el framework del modelo, el backend y el tamaño de la imagen de contenedor que uses.
xx y yy hacen referencia a versiones principales y secundarias de Triton, en ese orden.
| Imagen de Triton de NVIDIA | Compatibilidad |
|---|---|
xx.yy-py3 |
Contenedor completo compatible con los modelos de TensorFlow, PyTorch, TensorRT, ONNX y OpenVINO |
xx.yy-pyt-python-py3 |
Solo backends de PyTorch y Python |
xx.yy-tf2-python-py3 |
Solo backends de TensorFlow 2.x y Python |
xx.yy-py3-min |
Personaliza el contenedor de Triton según sea necesario |
Comenzar: Entrega inferencias con Triton de NVIDIA
En la siguiente figura, se muestra la arquitectura de alto nivel de Triton en Vertex AI Inference:
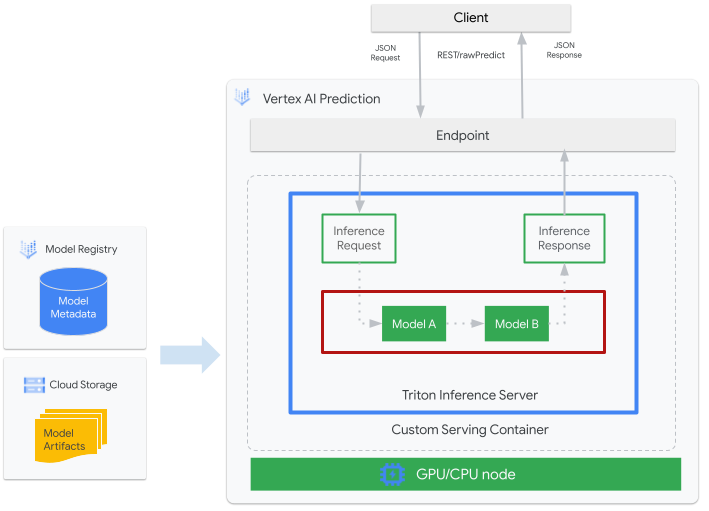
- Un modelo de AA que entrega Triton se registra con Vertex AI Model Registry. Los metadatos del modelo hacen referencia a la ubicación de los artefactos del modelo en Cloud Storage, el contenedor de entrega personalizado y su configuración.
- El modelo de Vertex AI Model Registry se implementa en un extremo de inferencia de Vertex AI que ejecuta el servidor de inferencia de Triton como un contenedor personalizado en los nodos de procesamiento con CPU y GPU.
- Las solicitudes de inferencia llegan al servidor de inferencia de Triton a través de un extremo de inferencia de Vertex AI y se enrutan al programador adecuado.
- El backend realiza inferencias mediante las entradas proporcionadas en las solicitudes por lotes y muestra una respuesta.
- Triton proporciona extremos de estado de funcionamiento y preparación, que permiten la integración de Triton en entornos de implementación, como Vertex AI.
En este instructivo, se muestra cómo usar un contenedor personalizado que ejecuta el servidor de inferencia de Triton de NVIDIA para implementar un modelo de aprendizaje automático (AA) en Vertex AI, que entrega inferencias en línea. Implementas un contenedor que ejecuta Triton para entregar inferencias de un modelo de detección de objetos de TensorFlow Hub que se entrenó previamente en el conjunto de datos COCO 2017. Luego, puedes usar Vertex AI para detectar objetos en una imagen.
Para ejecutar este instructivo en formato de notebook, haz lo siguiente:
Abrir en Colab | Abrir en Colab Enterprise | Ver en GitHub | Abrir en Vertex AI Workbench |Antes de comenzar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API and Artifact Registry API APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API and Artifact Registry API APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
-
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init - Sigue la documentación de Artifact Registry para instalar Docker.
- LOCATION_ID: la región de tu repositorio de Artifact Registry, como se especifica en una sección anterior
- PROJECT_ID: Es el ID de tu proyecto deGoogle Cloud.
Para ejecutar la imagen de contenedor de forma local, ejecuta el siguiente comando en la shell:
docker run -t -d -p 8000:8000 --rm \ --name=local_object_detector \ -e AIP_MODE=True \ LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference \ --model-repository MODEL_ARTIFACTS_REPOSITORY \ --strict-model-config=falseReemplaza lo siguiente, tal como lo hiciste en la sección anterior:
- LOCATION_ID: La región de tu repositorio de Artifact Registry, como se especifica en una sección anterior
- PROJECT_ID: Es el ID de tu Google Cloud. project
- MODEL_ARTIFACTS_REPOSITORY: La ruta de acceso de Cloud Storage donde se encuentran los artefactos del modelo
Este comando ejecuta un contenedor en modo desconectado, asignando el puerto
8000del contenedor al puerto8000del entorno local. La imagen de Triton de NGC configura Triton para usar el puerto8000.Para enviar una verificación de estado al servidor del contenedor, ejecuta el siguiente comando en tu shell:
curl -s -o /dev/null -w "%{http_code}" http://localhost:8000/v2/health/readySi se ejecuta de forma correcta, el servidor muestra el código de estado como
200.Ejecuta el siguiente comando para enviar una solicitud de inferencia al servidor del contenedor con la carga útil generada anteriormente y obtener respuestas de inferencia:
curl -X POST \ -H "Content-Type: application/json" \ -d @instances.json \ localhost:8000/v2/models/object_detector/infer | jq -c '.outputs[] | select(.name == "detection_classes")'Esta solicitud usa una de las imágenes de prueba que se incluyen en el ejemplo de detección de objetos de TensorFlow.
Si se ejecuta de forma correcta, el servidor mostrará la siguiente inferencia:
{"name":"detection_classes","datatype":"FP32","shape":[1,300],"data":[38,1,...,44]}Para detener el contenedor, ejecuta el siguiente comando en la shell:
docker stop local_object_detectorSi deseas permitir que tu instalación local de Docker se envíe a Artifact Registry en la región que seleccionaste, ejecuta el siguiente comando en tu shell:
gcloud auth configure-docker LOCATION_ID-docker.pkg.dev- Reemplaza LOCATION_ID por la región en la que creaste tu repositorio en una sección anterior.
Para enviar la imagen de contenedor que acabas de compilar a Artifact Registry, ejecuta el siguiente comando en tu shell:
docker push LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inferenceReemplaza lo siguiente, tal como lo hiciste en la sección anterior:
- LOCATION_ID: La región de tu repositorio de Artifact Registry, como se especifica en una sección anterior
- PROJECT_ID: Es el ID de tu proyecto deGoogle Cloud.
- LOCATION_ID: la región en la que usas Vertex AI.
- PROJECT_ID: Es el ID de tu proyecto deGoogle Cloud.
-
DEPLOYED_MODEL_NAME: Un nombre para
DeployedModelTambién puedes usar el nombre comercial deModelparaDeployedModel. - LOCATION_ID: la región en la que usas Vertex AI.
- ENDPOINT_NAME: el nombre visible para el extremo.
- LOCATION_ID: la región en la que usas Vertex AI.
- ENDPOINT_NAME: el nombre visible para el extremo.
-
DEPLOYED_MODEL_NAME: Un nombre para
DeployedModelTambién puedes usar el nombre comercial deModelparaDeployedModel. -
MACHINE_TYPE: Opcional Los recursos de máquina que se usan para cada nodo de esta implementación. Su configuración predeterminada es
n1-standard-2. Obtén más información sobre los tipos de máquinas. - MIN_REPLICA_COUNT: La cantidad mínima de nodos para esta implementación. El recuento de nodos se puede aumentar o disminuir según lo requiera la carga de inferencia, hasta la cantidad máxima de nodos y nunca menos que esta cantidad.
- MAX_REPLICA_COUNT: La cantidad máxima de nodos para esta implementación. El recuento de nodos se puede aumentar o disminuir según lo requiera la carga de inferencia, hasta esta cantidad de nodos y nunca menos que la cantidad mínima de nodos.
ACCELERATOR_COUNT: La cantidad de aceleradores que se deben conectar a cada máquina que ejecuta el trabajo. Por lo general, es 1. Si no se especifica, el valor predeterminado es 1.
ACCELERATOR_TYPE: Administra la configuración del acelerador para la entrega de GPU. Cuando se implementa un modelo con tipos de máquina de Compute Engine, también se puede seleccionar un acelerador de GPU y se debe especificar el tipo. Las opciones son
nvidia-tesla-a100,nvidia-tesla-p100,nvidia-tesla-p4,nvidia-tesla-t4ynvidia-tesla-v100.- LOCATION_ID: la región en la que usas Vertex AI.
- ENDPOINT_NAME: el nombre visible para el extremo.
Para anular la implementación del modelo en el extremo y borrarlo, ejecuta el siguiente comando en tu shell:
ENDPOINT_ID=$(gcloud ai endpoints list \ --region=LOCATION_ID \ --filter=display_name=ENDPOINT_NAME \ --format="value(name)") DEPLOYED_MODEL_ID=$(gcloud ai endpoints describe $ENDPOINT_ID \ --region=LOCATION_ID \ --format="value(deployedModels.id)") gcloud ai endpoints undeploy-model $ENDPOINT_ID \ --region=LOCATION_ID \ --deployed-model-id=$DEPLOYED_MODEL_ID gcloud ai endpoints delete $ENDPOINT_ID \ --region=LOCATION_ID \ --quietReemplaza LOCATION_ID por la región en la que creaste tu modelo en una sección anterior.
Para borrar tu modelo, ejecuta el siguiente comando en tu shell:
MODEL_ID=$(gcloud ai models list \ --region=LOCATION_ID \ --filter=display_name=DEPLOYED_MODEL_NAME \ --format="value(name)") gcloud ai models delete $MODEL_ID \ --region=LOCATION_ID \ --quietReemplaza LOCATION_ID por la región en la que creaste tu modelo en una sección anterior.
Para borrar tu repositorio de Artifact Registry y la imagen del contenedor que contiene, ejecuta el siguiente comando en tu shell:
gcloud artifacts repositories delete getting-started-nvidia-triton \ --location=LOCATION_ID \ --quietReemplaza LOCATION_ID por la región en la que creaste tu repositorio de Artifact Registry en una sección anterior.
- El contenedor personalizado de Triton no es compatible con Vertex Explainable AI o Vertex AI Model Monitoring.
- Para obtener más información sobre los patrones de implementación con el servidor de inferencia de Triton de NVIDIA en Vertex AI, consulta los instructivos de Jupyter Notebook de NVIDIA Triton.
Durante este instructivo, te recomendamos que uses Cloud Shell para interactuar con Google Cloud. Si quieres usar un shell de Bash diferente en lugar de Cloud Shell, realiza la siguiente configuración adicional:
Compila y envía la imagen del contenedor
Para usar un contenedor personalizado, debes especificar una imagen de contenedor de Docker que cumpla con los requisitos de contenedores personalizados. En esta sección, se describe cómo crear la imagen del contenedor y enviarla a Artifact Registry.
Descarga artefactos de modelo
Los artefactos de modelo son archivos que crea el entrenamiento de AA que puedes usar para entregar inferencias. Contienen, como mínimo, la estructura y los pesos de tu modelo de AA entrenado. El formato de los artefactos del modelo depende del marco de trabajo de AA que uses para el entrenamiento.
Para este instructivo, en lugar de entrenar un modelo desde cero, descarga el modelo de detección de objetos de TensorFlow Hub que se entrenó en el conjunto de datos COCO 2017.
Triton espera que el repositorio de modelos se organice en la siguiente estructura para entregar el formato de TensorFlow SavedModel:
└── model-repository-path
└── model_name
├── config.pbtxt
└── 1
└── model.savedmodel
└── <saved-model-files>
El archivo config.pbtxt describe la configuración del modelo. De forma predeterminada, se debe proporcionar el archivo de configuración del modelo que contiene la configuración necesaria. Sin embargo, si Triton se inicia con la opción --strict-model-config=false, en algunos casos, la configuración del modelo se puede generar de forma automática mediante Triton y no debe proporcionarse de forma explícita.
En particular, los modelos de SavedModel de TensorFlow, TensorRT y ONNX no requieren un archivo de configuración del modelo, ya que Triton puede derivar toda la configuración necesaria de forma automática. Todos los demás tipos de modelos deben proporcionar un archivo de configuración del modelo.
# Download and organize model artifacts according to the Triton model repository spec
mkdir -p models/object_detector/1/model.savedmodel/
curl -L "https://tfhub.dev/tensorflow/faster_rcnn/resnet101_v1_640x640/1?tf-hub-format=compressed" | \
tar -zxvC ./models/object_detector/1/model.savedmodel/
ls -ltr ./models/object_detector/1/model.savedmodel/
Después de descargar el modelo de forma local, el repositorio de modelos se organizará de la siguiente manera:
./models
└── object_detector
└── 1
└── model.savedmodel
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
Copia los artefactos de modelo a un bucket de Cloud Storage
Los artefactos del modelo descargado, incluido el archivo de configuración del modelo, se envían a un bucket de Cloud Storage que especifica MODEL_ARTIFACTS_REPOSITORY, que se puede usar cuando creas el recurso del modelo de Vertex AI.
gcloud storage cp ./models/object_detector MODEL_ARTIFACTS_REPOSITORY/ --recursive
Crea un repositorio de Artifact Registry
Crea un repositorio de Artifact Registry para almacenar la imagen de contenedor que crearás en la próxima sección.
Habilita el servicio de la API de Artifact Registry para tu proyecto.
gcloud services enable artifactregistry.googleapis.com
Ejecuta el siguiente comando en la shell para crear un repositorio de Artifact Registry:
gcloud artifacts repositories create getting-started-nvidia-triton \
--repository-format=docker \
--location=LOCATION_ID \
--description="NVIDIA Triton Docker repository"
Reemplaza LOCATION_ID por la región en la que Artifact Registry almacena la imagen de contenedor. Más adelante, debes crear un recurso de modelo de Vertex AI en un extremo de ubicación que coincida con esta región, por lo que debes elegir una región en la que Vertex AI tenga un extremo de ubicación, como us-central1.
Después de completar la operación, el comando imprime el siguiente resultado:
Created repository [getting-started-nvidia-triton].
Compila la imagen del contenedor
NVIDIA proporciona imágenes de Docker para compilar una imagen de contenedor que ejecuta Triton y se alinea con los requisitos de contenedor personalizados de Vertex AI para la entrega. Puedes extraer la imagen mediante docker y etiquetar la ruta de acceso de Artifact Registry a la que se enviará la imagen.
NGC_TRITON_IMAGE_URI="nvcr.io/nvidia/tritonserver:22.01-py3"
docker pull $NGC_TRITON_IMAGE_URI
docker tag $NGC_TRITON_IMAGE_URI LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference
Reemplaza lo siguiente:
El comando puede ejecutarse durante varios minutos.
Prepara el archivo de carga útil para probar las solicitudes de inferencia
Para enviar una solicitud de inferencia al servidor del contenedor, prepara la carga útil con un archivo de imagen de muestra que use Python. Ejecuta la siguiente secuencia de comandos Python para generar el archivo de carga útil:
import json
import requests
# install required packages before running
# pip install pillow numpy --upgrade
from PIL import Image
import numpy as np
# method to generate payload from image url
def generate_payload(image_url):
# download image from url and resize
image_inputs = Image.open(requests.get(image_url, stream=True).raw)
image_inputs = image_inputs.resize((200, 200))
# convert image to numpy array
image_tensor = np.asarray(image_inputs)
# derive image shape
image_shape = [1] + list(image_tensor.shape)
# create payload request
payload = {
"id": "0",
"inputs": [
{
"name": "input_tensor",
"shape": image_shape,
"datatype": "UINT8",
"parameters": {},
"data": image_tensor.tolist(),
}
],
}
# save payload as json file
payload_file = "instances.json"
with open(payload_file, "w") as f:
json.dump(payload, f)
print(f"Payload generated at {payload_file}")
return payload_file
if __name__ == '__main__':
image_url = "https://github.com/tensorflow/models/raw/master/research/object_detection/test_images/image2.jpg"
payload_file = generate_payload(image_url)
La secuencia de comandos de Python genera una carga útil y, luego, imprime la siguiente respuesta:
Payload generated at instances.json
Ejecuta el contenedor de forma local (opcional)
Antes de enviar tu imagen de contenedor a Artifact Registry para usarla con Vertex AI, puedes ejecutarla como un contenedor en tu entorno local para verificar que el servidor funcione como se espera:
{kind=link}
Envía la imagen del contenedor a Artifact Registry
Configurar Docker para acceder a Artifact Registry Luego, envía tu imagen de contenedor a tu repositorio de Artifact Registry.
Implementa el modelo
En esta sección, crearás un modelo y un extremo, y, luego, implementarás el modelo en el extremo.
Crear un modelo
Para crear un recurso Model que use un contenedor personalizado que ejecute Triton, usa el comando gcloud ai models upload.
Antes de crear tu modelo, lee Configuración de contenedores personalizados para saber si necesitas especificar los campos opcionales sharedMemorySizeMb, startupProbe y healthProbe para tu contenedor.
gcloud ai models upload \
--region=LOCATION_ID \
--display-name=DEPLOYED_MODEL_NAME \
--container-image-uri=LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference \
--artifact-uri=MODEL_ARTIFACTS_REPOSITORY \
--container-args='--strict-model-config=false'
El argumento --container-args='--strict-model-config=false' permite que Triton genere la configuración del modelo de forma automática.
Crear un extremo
Debes implementar el modelo en un extremo antes de que pueda usarse para entregar inferencias en línea. Si implementas un modelo en un extremo existente, puedes omitir este paso. En el siguiente ejemplo, se usa el comando gcloud ai endpoints create:
gcloud ai endpoints create \
--region=LOCATION_ID \
--display-name=ENDPOINT_NAME
Reemplaza lo siguiente:
La herramienta de la CLI de Google Cloud puede tardar unos segundos en crear el extremo.
Implementa el modelo en el extremo
Una vez que el extremo esté listo, implementa el modelo en el extremo. Cuando implementas un modelo en un extremo, el servicio asocia los recursos físicos con el modelo que ejecuta Triton para entregar inferencias en línea.
En el siguiente ejemplo, se usa el comando gcloud ai endpoints deploy-model para implementar Model en un endpoint que ejecute Triton en GPU a fin de acelerar la entrega de inferencias y sin dividir el tráfico entre varios recursos de DeployedModel:
ENDPOINT_ID=$(gcloud ai endpoints list \ --region=LOCATION_ID\ --filter=display_name=ENDPOINT_NAME\ --format="value(name)") MODEL_ID=$(gcloud ai models list \ --region=LOCATION_ID\ --filter=display_name=DEPLOYED_MODEL_NAME\ --format="value(name)") gcloud ai endpoints deploy-model $ENDPOINT_ID \ --region=LOCATION_ID\ --model=$MODEL_ID \ --display-name=DEPLOYED_MODEL_NAME\ --machine-type=MACHINE_TYPE\ --min-replica-count=MIN_REPLICA_COUNT\ --max-replica-count=MAX_REPLICA_COUNT\ --accelerator=count=ACCELERATOR_COUNT,type=ACCELERATOR_TYPE\ --traffic-split=0=100
Reemplaza lo siguiente:
Google Cloud CLI puede tardar unos segundos en implementar el modelo en el extremo. Cuando el modelo se implementa de forma correcta, este comando imprime el siguiente resultado:
Deployed a model to the endpoint xxxxx. Id of the deployed model: xxxxx.
Obtén inferencias en línea del modelo implementado
Para invocar el modelo a través del extremo de Vertex AI Inference, formatea la solicitud de inferencia con un objeto JSON de solicitud de inferencia estándar
o un objeto JSON de solicitud de inferencia con una extensión binaria
y envía una solicitud al extremo rawPredict de REST de Vertex AI.
En el siguiente ejemplo, se usa el comando gcloud ai endpoints raw-predict:
ENDPOINT_ID=$(gcloud ai endpoints list \
--region=LOCATION_ID \
--filter=display_name=ENDPOINT_NAME \
--format="value(name)")
gcloud ai endpoints raw-predict $ENDPOINT_ID \
--region=LOCATION_ID \
--http-headers=Content-Type=application/json \
--request=@instances.json
Reemplaza lo siguiente:
El extremo muestra la siguiente respuesta para una solicitud válida:
{
"id": "0",
"model_name": "object_detector",
"model_version": "1",
"outputs": [{
"name": "detection_anchor_indices",
"datatype": "FP32",
"shape": [1, 300],
"data": [2.0, 1.0, 0.0, 3.0, 26.0, 11.0, 6.0, 92.0, 76.0, 17.0, 58.0, ...]
}]
}
Limpia
Para evitar incurrir en más cargos de Vertex AI y cargos de Artifact Registry, borra los Google Cloud recursos que creaste durante este instructivo: