Model Vertex AI di-deploy ke instance mesin virtual (VM) miliknya sendiri secara default. Vertex AI menawarkan kemampuan untuk meng-hosting bersama model di VM yang sama, yang memberikan manfaat berikut:
- Berbagi resource di beberapa deployment.
- Penyajian model yang hemat biaya.
- Pemanfaatan memori dan resource komputasi secara lebih optimal.
Panduan ini menjelaskan cara berbagi resource di beberapa deployment di Vertex AI.
Ringkasan
Dukungan hosting bersama model memperkenalkan konsep DeploymentResourcePool, yang mengelompokkan deployment model yang berbagi resource dalam satu VM. Beberapa endpoint dapat di-deploy di VM yang sama dalam DeploymentResourcePool. Setiap endpoint memiliki satu atau beberapa model yang di-deploy. Model yang di-deploy untuk endpoint tertentu dapat dikelompokkan dalam DeploymentResourcePool yang sama atau yang berbeda.
Pada contoh berikut, Anda memiliki empat model dan dua endpoint:
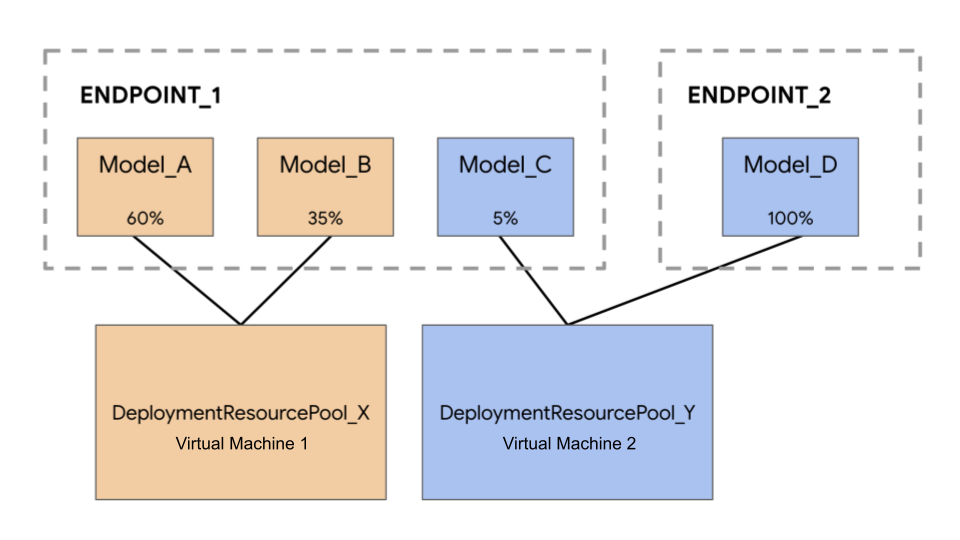
Model_A, Model_B, dan Model_C di-deploy ke Endpoint_1 dengan traffic yang dirutekan ke semua model tersebut. Model_D di-deploy ke Endpoint_2, yang menerima 100% traffic untuk endpoint tersebut.
Alih-alih menetapkan setiap model ke VM yang terpisah, Anda dapat mengelompokkan model dengan salah satu cara berikut:
- Mengelompokkan
Model_AdanModel_Buntuk berbagi satu VM, yang menjadikan keduanya sebagai bagian dariDeploymentResourcePool_X. - Mengelompokkan
Model_CdanModel_D(yang tidak sedang berada di endpoint yang sama) untuk berbagi satu VM, yang menjadikan keduanya sebagai bagian dariDeploymentResourcePool_Y.
Kumpulan resource deployment yang berbeda tidak dapat berbagi satu VM.
Pertimbangan
Tidak ada batas atas terkait jumlah model yang dapat di-deploy ke satu kumpulan resource deployment. Hal ini bergantung pada bentuk VM, ukuran model, dan pola traffic yang dipilih. Jika ada banyak model yang di-deploy tetapi traffic-nya rendah, menetapkan mesin khusus untuk setiap model yang di-deploy akan membuat pemanfaatan sumber daya menjadi tidak efektif, dalam hal ini hosting bersama akan sangat praktis.
Anda dapat men-deploy model ke kumpulan resource deployment yang sama secara serentak. Namun, permintaan deployment serentak dibatasi maksimum 20 setiap saat.
Kumpulan resource deployment yang kosong tidak akan mengurangi kuota resource Anda. Penyediaan resource ke kumpulan resource deployment dimulai saat model pertama di-deploy dan dihentikan saat model terakhir tidak lagi di-deploy.
Model dalam satu kumpulan resource deployment tidak diisolasi satu sama lain dan dapat bersaing untuk mendapatkan CPU dan memori. Performa satu model mungkin lebih buruk jika model lain memproses permintaan inferensi pada saat yang sama.
Batasan
Saat men-deploy model dengan mengaktifkan berbagi resource, batasan berikut berlaku:
- Fitur ini hanya didukung untuk konfigurasi berikut:
- Deployment model TensorFlow yang menggunakan container bawaan untuk TensorFlow
- Deployment model PyTorch yang menggunakan container bawaan untuk PyTorch
- Container bawaan yang dikonfigurasi untuk framework lain tidak didukung.
- Penampung kustom tidak didukung.
- Hanya model yang dilatih khusus dan model yang diimpor yang didukung. Model AutoML tidak didukung.
- Hanya model dengan image container yang sama (termasuk versi framework) dari container bawaan Vertex AI untuk inferensi untuk TensorFlow atau PyTorch yang dapat di-deploy di kumpulan resource deployment yang sama.
- Vertex Explainable AI tidak didukung.
Men-deploy model
Untuk men-deploy model ke DeploymentResourcePool, selesaikan langkah-langkah berikut:
- Buat kumpulan resource deployment jika diperlukan.
- Buat endpoint jika perlu.
- Ambil ID endpoint.
- Deploy model ke endpoint di kumpulan resource deployment.
Membuat kumpulan resource deployment
Jika Anda men-deploy model ke DeploymentResourcePool yang sudah ada, lewati langkah ini:
Gunakan CreateDeploymentResourcePool untuk membuat kumpulan resource.
Cloud Console
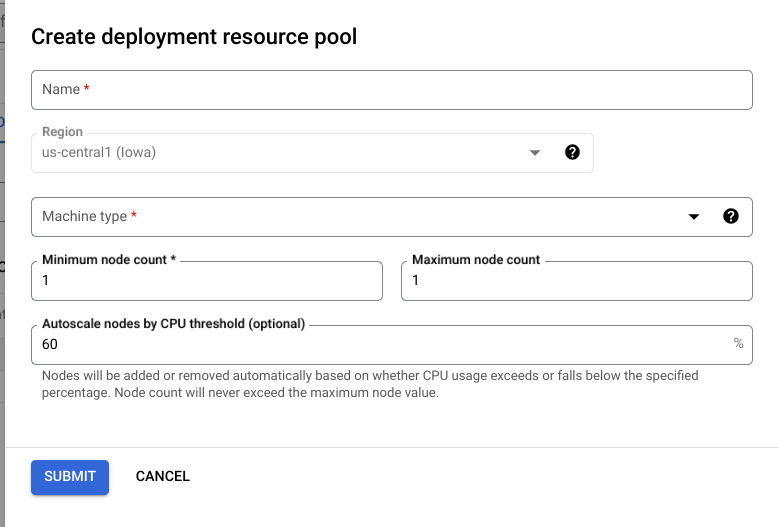
Di konsol Google Cloud , buka halaman Deployment Resource Pools Vertex AI.
Klik Buat, lalu lengkapi formulir (ditampilkan di bawah ini).
REST
Sebelum menggunakan data permintaan mana pun, lakukan penggantian berikut:
- LOCATION_ID: Region tempat Anda menggunakan Vertex AI.
- PROJECT_ID: Project ID Anda.
-
MACHINE_TYPE: Opsional. Resource mesin yang digunakan untuk setiap node deployment ini. Setelan defaultnya adalah
n1-standard-2. Pelajari jenis-jenis mesin lebih lanjut. - ACCELERATOR_TYPE: Jenis akselerator yang akan dipasang ke mesin. Opsional jika ACCELERATOR_COUNT tidak ditentukan atau nol. Tidak direkomendasikan untuk model AutoML atau model yang dilatih secara khusus yang menggunakan image non-GPU. Pelajari lebih lanjut.
- ACCELERATOR_COUNT: Jumlah akselerator untuk setiap replika yang akan digunakan. Opsional. Harus nol atau tidak ditentukan untuk model AutoML atau model yang dilatih secara khusus yang menggunakan image non-GPU.
- MIN_REPLICA_COUNT: Jumlah minimum node untuk deployment ini. Jumlah node dapat ditingkatkan atau diturunkan sesuai kebutuhan beban inferensi, hingga mencapai jumlah maksimum node dan tidak pernah kurang dari jumlah ini. Nilai ini harus lebih besar dari atau sama dengan 1.
- MAX_REPLICA_COUNT: Jumlah maksimum node untuk deployment ini. Jumlah node dapat ditingkatkan atau diturunkan sesuai kebutuhan beban inferensi, hingga mencapai jumlah maksimum node dan tidak pernah kurang dari jumlah ini.
- REQUIRED_REPLICA_COUNT: Opsional. Jumlah node yang diperlukan agar deployment ini ditandai sebagai berhasil. Harus lebih besar dari atau sama dengan 1 dan kurang dari atau sama dengan jumlah minimum node. Jika tidak ditentukan, nilai defaultnya adalah jumlah minimum node.
-
DEPLOYMENT_RESOURCE_POOL_ID: Nama untuk
DeploymentResourcePoolAnda. Panjang maksimum adalah 63 karakter, dan karakter yang valid adalah /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/.
Metode HTTP dan URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/deploymentResourcePools
Meminta isi JSON:
{
"deploymentResourcePool":{
"dedicatedResources":{
"machineSpec":{
"machineType":"MACHINE_TYPE",
"acceleratorType":"ACCELERATOR_TYPE",
"acceleratorCount":"ACCELERATOR_COUNT"
},
"minReplicaCount":MIN_REPLICA_COUNT,
"maxReplicaCount":MAX_REPLICA_COUNT,
"requiredReplicaCount":REQUIRED_REPLICA_COUNT
}
},
"deploymentResourcePoolId":"DEPLOYMENT_RESOURCE_POOL_ID"
}
Untuk mengirim permintaan Anda, perluas salah satu opsi berikut:
Anda akan menerima respons JSON yang mirip dengan berikut ini:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION_ID/deploymentResourcePools/DEPLOYMENT_RESOURCE_POOL_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.CreateDeploymentResourcePoolOperationMetadata",
"genericMetadata": {
"createTime": "2022-06-15T05:48:06.383592Z",
"updateTime": "2022-06-15T05:48:06.383592Z"
}
}
}
Anda dapat melakukan polling untuk status operasi hingga
responsnya menyertakan "done": true.
Python
# Create a deployment resource pool.
deployment_resource_pool = aiplatform.DeploymentResourcePool.create(
deployment_resource_pool_id="DEPLOYMENT_RESOURCE_POOL_ID", # User-specified ID
machine_type="MACHINE_TYPE", # Machine type
min_replica_count=MIN_REPLICA_COUNT, # Minimum number of replicas
max_replica_count=MAX_REPLICA_COUNT, # Maximum number of replicas
)
Ganti kode berikut:
DEPLOYMENT_RESOURCE_POOL_ID: Nama untukDeploymentResourcePoolAnda. Panjang maksimum adalah 63 karakter, dan karakter yang valid adalah /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/.MACHINE_TYPE: Opsional. Resource mesin yang digunakan untuk setiap node deployment ini. Nilai defaultnya adalahn1-standard-2. Pelajari jenis-jenis mesin lebih lanjut.MIN_REPLICA_COUNT: Jumlah minimum node untuk deployment ini. Jumlah node dapat ditingkatkan atau diturunkan sesuai kebutuhan oleh beban inferensi, hingga mencapai jumlah maksimum node dan tidak pernah kurang dari jumlah node ini. Nilai ini harus lebih besar dari atau sama dengan 1.MAX_REPLICA_COUNT: Jumlah maksimum node untuk deployment ini. Jumlah node dapat ditingkatkan atau diturunkan sesuai kebutuhan beban inferensi, hingga jumlah node ini, dan tidak pernah kurang dari jumlah minimum node.
Membuat endpoint
Untuk membuat endpoint, lihat Membuat endpoint publik menggunakan gcloud CLI atau Vertex AI API. Langkah ini sama seperti untuk deployment model tunggal.
Mengambil ID endpoint
Untuk mengambil ID endpoint, lihat Men-deploy model menggunakan gcloud CLI atau Vertex AI API. Langkah ini sama seperti untuk deployment model tunggal.
Men-deploy model di kumpulan resource deployment
Setelah membuat DeploymentResourcePool dan endpoint, Anda sudah dapat men-deploy menggunakan metode API DeployModel. Proses ini mirip dengan deployment model tunggal. Jika ada DeploymentResourcePool, tentukan shared_resources dari DeployModel dengan nama resource DeploymentResourcePool yang Anda deploy.
Cloud Console
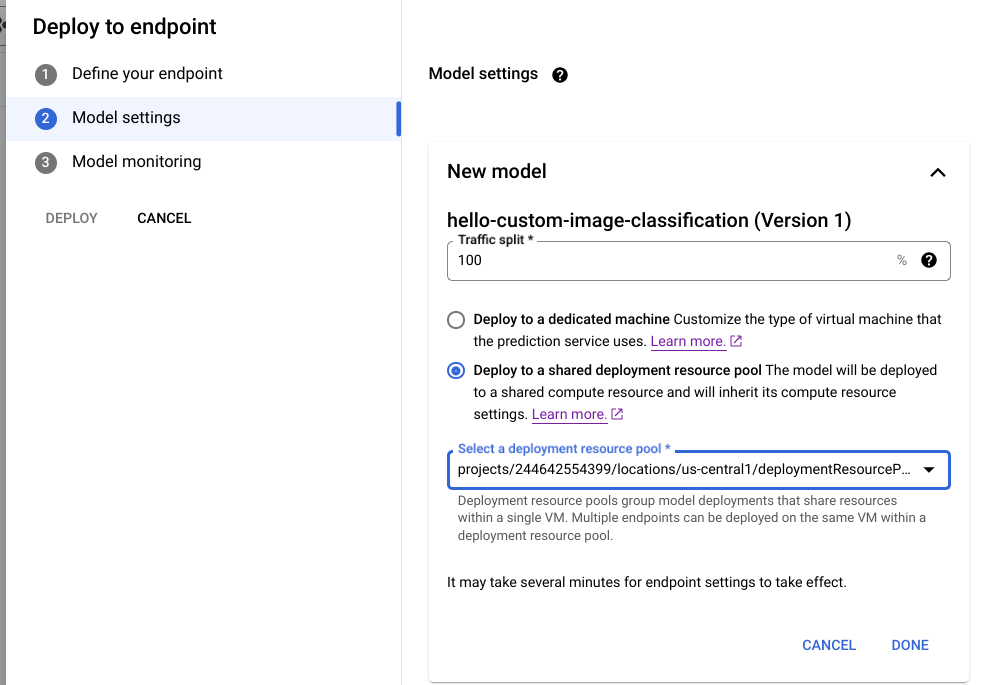
Di konsol Google Cloud , buka halaman Model Registry Vertex AI.
Temukan model Anda, lalu klik Deploy ke endpoint.
Di bagian Pengaturan model (ditampilkan di bawah ini), pilih Deploy ke kumpulan resource deployment bersama.
REST
Sebelum menggunakan data permintaan mana pun, lakukan penggantian berikut:
- LOCATION_ID: Region tempat Anda menggunakan Vertex AI.
- PROJECT: Project ID Anda.
- ENDPOINT_ID: ID untuk endpoint tersebut.
- MODEL_ID: ID untuk model yang akan di-deploy.
-
DEPLOYED_MODEL_NAME: Nama untuk
DeployedModel. Anda juga dapat menggunakan nama tampilanModeluntukDeployedModel. -
DEPLOYMENT_RESOURCE_POOL_ID: Nama untuk
DeploymentResourcePoolAnda. Panjang maksimum adalah 63 karakter, dan karakter yang valid adalah /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/. - TRAFFIC_SPLIT_THIS_MODEL: Persentase traffic prediksi ke endpoint ini yang akan dirutekan ke model yang di-deploy dengan operasi ini. Setelan defaultnya adalah 100. Semua persentase traffic harus berjumlah 100. Pelajari pemisahan traffic lebih lanjut.
- DEPLOYED_MODEL_ID_N: Opsional. Jika model lain di-deploy ke endpoint ini, Anda harus memperbarui persentase pemisahan traffic agar semua persentase berjumlah 100.
- TRAFFIC_SPLIT_MODEL_N: Nilai persentase pemisahan traffic untuk kunci ID model yang di-deploy.
- PROJECT_NUMBER: Nomor project yang dibuat secara otomatis untuk project Anda
Metode HTTP dan URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/endpoints/ENDPOINT_ID:deployModel
Meminta isi JSON:
{
"deployedModel": {
"model": "projects/PROJECT/locations/us-central1/models/MODEL_ID",
"displayName": "DEPLOYED_MODEL_NAME",
"sharedResources":"projects/PROJECT/locations/us-central1/deploymentResourcePools/DEPLOYMENT_RESOURCE_POOL_ID"
},
"trafficSplit": {
"0": TRAFFIC_SPLIT_THIS_MODEL,
"DEPLOYED_MODEL_ID_1": TRAFFIC_SPLIT_MODEL_1,
"DEPLOYED_MODEL_ID_2": TRAFFIC_SPLIT_MODEL_2
},
}
Untuk mengirim permintaan Anda, perluas salah satu opsi berikut:
Anda akan melihat respons JSON seperti berikut:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.DeployModelOperationMetadata",
"genericMetadata": {
"createTime": "2022-06-19T17:53:16.502088Z",
"updateTime": "2022-06-19T17:53:16.502088Z"
}
}
}
Python
# Deploy model in a deployment resource pool.
model = aiplatform.Model("MODEL_ID")
model.deploy(deployment_resource_pool=deployment_resource_pool)
Ganti MODEL_ID dengan ID untuk model yang akan di-deploy.
Ulangi permintaan sebelumnya dengan berbagai model yang memiliki resource bersama yang sama untuk men-deploy beberapa model ke kumpulan resource deployment yang sama.
Mendapatkan inferensi
Anda dapat mengirim permintaan inferensi ke model di DeploymentResourcePool seperti yang Anda lakukan ke model lain yang di-deploy di Vertex AI.