Par défaut, un modèle Vertex AI est déployé sur sa propre instance de machine virtuelle (VM). Vertex AI offre la possibilité de co-héberger des modèles sur la même VM, ce qui offre les avantages suivants :
- Partage des ressources entre plusieurs déploiements
- Mise en service de modèles à coûts réduits
- Utilisation améliorée de la mémoire et des ressources de calcul
Ce guide explique comment partager des ressources entre plusieurs déploiements sur Vertex AI.
Présentation
La gestion du co-hébergement de modèles introduit le concept de DeploymentResourcePool, qui regroupe au sein d'une VM unique les déploiements de modèles partageant des ressources. Plusieurs points de terminaison peuvent être déployés sur la même VM au sein d'un DeploymentResourcePool. Chaque point de terminaison possède un ou plusieurs modèles déployés. Les modèles déployés pour un point de terminaison donné peuvent être regroupés dans le même DeploymentResourcePool ou dans des regroupements différents.
Dans l'exemple suivant, vous avez quatre modèles et deux points de terminaison :
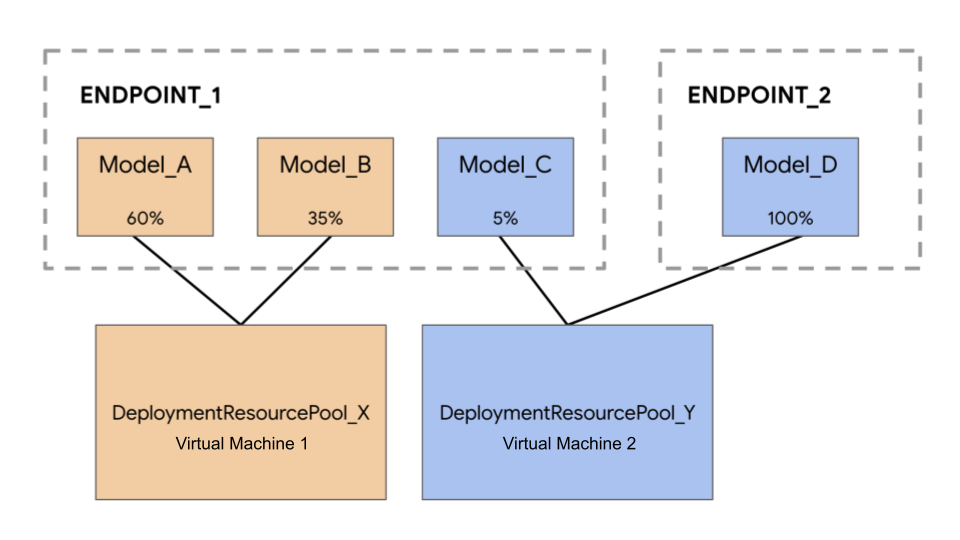
Model_A, Model_B et Model_C sont déployés sur Endpoint_1, et le trafic est acheminé vers l'ensemble. Model_D est déployé sur Endpoint_2, qui reçoit 100% du trafic pour ce point de terminaison.
Au lieu d'attribuer chaque modèle à une VM distincte, vous pouvez les regrouper de l'une des manières suivantes :
- Regroupez
Model_AetModel_Bpour qu'ils partagent une VM, ce qui les inclut alors dansDeploymentResourcePool_X. - Regroupez
Model_CetModel_D(actuellement sur des points de terminaison différents) pour qu'ils partagent une VM, ce qui les inclut alors dansDeploymentResourcePool_Y.
Des pools de ressources de déploiement différents ne peuvent pas partager une VM.
Remarques
Il n'y a pas de limite supérieure au nombre de modèles pouvant être déployés dans un même pool de ressources de déploiement. Cela dépend de la forme de VM choisie, de la taille des modèles et des modèles de trafic. Le co-hébergement fonctionne bien lorsque vous avez de nombreux modèles déployés avec un trafic épars, de sorte que l'attribution d'une machine dédiée à chaque modèle déployé ne représente pas une utilisation efficace des ressources.
Vous pouvez déployer des modèles simultanément sur le même pool de ressources de déploiement. Toutefois, le nombre de requêtes de déploiement simultanées est limité à tout moment à 20.
Un pool de ressources de déploiement vide ne consomme pas votre quota de ressources. Les ressources sont provisionnées dans un pool de ressources de déploiement au déploiement du premier modèle, et elles sont libérées à l'annulation du déploiement du dernier modèle.
Les modèles d'un même pool de ressources de déploiement ne sont pas isolés les uns des autres et peuvent être en concurrence pour le processeur et la mémoire. Les performances d'un modèle peuvent être moins bonnes si un autre modèle traite une requête d'inférence en même temps.
Limites
Les limites suivantes s'appliquent lors du déploiement de modèles pour lesquels le partage des ressources est activé :
- Cette fonctionnalité est uniquement compatible avec les configurations suivantes :
- Déploiements de modèles TensorFlow utilisant des conteneurs prédéfinis pour TensorFlow
- Déploiements de modèles PyTorch utilisant des conteneurs prédéfinis pour PyTorch
- Les conteneurs prédéfinis configurés pour d'autres frameworks ne sont pas acceptés.
- Les conteneurs personnalisés ne sont pas acceptés.
- Seuls les modèles entraînés personnalisés et les modèles importés sont acceptés. Les modèles AutoML ne sont pas acceptés.
- Seuls les modèles ayant la même image de conteneur (y compris la version de framework) des conteneurs Vertex AI prédéfinis pour l'inférence pour TensorFlow ou PyTorch peuvent être déployés dans le même pool de ressources de déploiement.
- Vertex Explainable AI n'est pas compatible.
Déployer un modèle
Pour déployer un modèle dans un DeploymentResourcePool, procédez comme suit :
- Créez un pool de ressources de déploiement si nécessaire.
- Créez un point de terminaison si nécessaire.
- Récupérez l'ID du point de terminaison.
- Déployez le modèle sur le point de terminaison dans le pool de ressources de déploiement.
Créer un pool de ressources de déploiement
Si vous déployez un modèle dans un DeploymentResourcePool existant, ignorez cette étape :
Utilisez CreateDeploymentResourcePool pour créer un pool de ressources.
Cloud Console
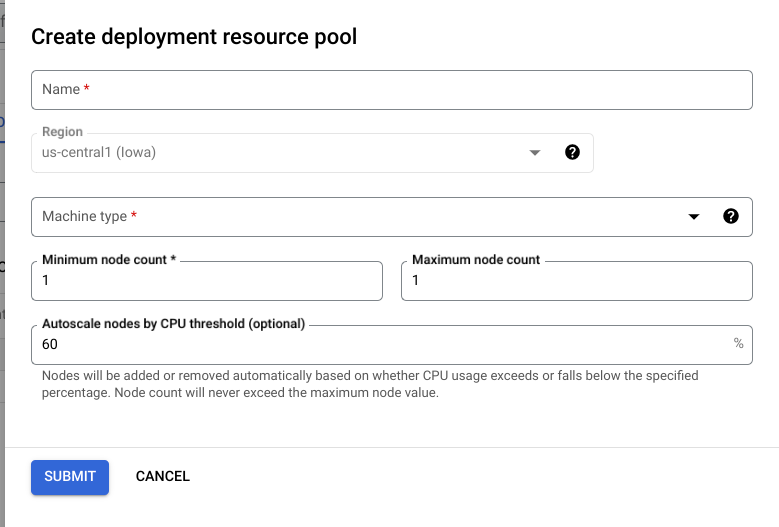
Dans la console Google Cloud , accédez à la page Pools de ressources de déploiement de Vertex AI.
Cliquez sur Créer et remplissez le formulaire (affiché ci-dessous).
REST
Avant d'utiliser les données de requête, effectuez les remplacements suivants :
- LOCATION_ID : région dans laquelle vous utilisez Vertex AI.
- PROJECT_ID : l'ID de votre projet.
-
MACHINE_TYPE : facultatif. Ressources machine utilisées pour chaque nœud de ce déploiement. Le paramètre par défaut est
n1-standard-2. En savoir plus sur les types de machines. - ACCELERATOR_TYPE : type d'accélérateur à associer à la machine. Facultatif si ACCELERATOR_COUNT n'est pas spécifié ou est égal à zéro. Il n'est pas recommandé pour les modèles AutoML ni les modèles personnalisés qui utilisent des images non GPU. En savoir plus
- ACCELERATOR_COUNT : nombre d'accélérateurs pour chaque instance dupliquée à utiliser. Facultatif. Doit être égal à zéro ou non spécifié pour les modèles AutoML ou les modèles personnalisés qui utilisent des images non GPU.
- MIN_REPLICA_COUNT : nombre minimal de nœuds pour ce déploiement. Le nombre de nœuds peut être augmenté ou réduit selon les besoins de la charge d'inférence, dans la limite du nombre maximal de nœuds et sans jamais être inférieur à ce nombre minimal de nœuds. Cette valeur doit être supérieure ou égale à 1.
- MAX_REPLICA_COUNT : nombre maximal de nœuds pour ce déploiement. Le nombre de nœuds peut être augmenté ou réduit selon les besoins de la charge d'inférence, dans la limite de ce nombre de nœuds et jamais moins que le nombre minimal de nœuds.
- REQUIRED_REPLICA_COUNT : facultatif. nombre de nœuds requis pour que ce déploiement soit marqué comme réussi. Doit être supérieur ou égal à 1 et inférieur ou égal au nombre minimal de nœuds. Si aucune valeur n'est spécifiée, la valeur par défaut est le nombre minimal de nœuds.
-
DEPLOYMENT_RESOURCE_POOL_ID : nom de votre
DeploymentResourcePool. La longueur maximale est de 63 caractères, et les caractères valides sont /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/.
Méthode HTTP et URL :
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/deploymentResourcePools
Corps JSON de la requête :
{
"deploymentResourcePool":{
"dedicatedResources":{
"machineSpec":{
"machineType":"MACHINE_TYPE",
"acceleratorType":"ACCELERATOR_TYPE",
"acceleratorCount":"ACCELERATOR_COUNT"
},
"minReplicaCount":MIN_REPLICA_COUNT,
"maxReplicaCount":MAX_REPLICA_COUNT,
"requiredReplicaCount":REQUIRED_REPLICA_COUNT
}
},
"deploymentResourcePoolId":"DEPLOYMENT_RESOURCE_POOL_ID"
}
Pour envoyer votre requête, développez l'une des options suivantes :
Vous devriez recevoir une réponse JSON de ce type :
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION_ID/deploymentResourcePools/DEPLOYMENT_RESOURCE_POOL_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.CreateDeploymentResourcePoolOperationMetadata",
"genericMetadata": {
"createTime": "2022-06-15T05:48:06.383592Z",
"updateTime": "2022-06-15T05:48:06.383592Z"
}
}
}
Vous pouvez interroger l'état de l'opération jusqu'à ce que la réponse indique "done": true.
Python
# Create a deployment resource pool.
deployment_resource_pool = aiplatform.DeploymentResourcePool.create(
deployment_resource_pool_id="DEPLOYMENT_RESOURCE_POOL_ID", # User-specified ID
machine_type="MACHINE_TYPE", # Machine type
min_replica_count=MIN_REPLICA_COUNT, # Minimum number of replicas
max_replica_count=MAX_REPLICA_COUNT, # Maximum number of replicas
)
Remplacez les éléments suivants :
DEPLOYMENT_RESOURCE_POOL_ID: nom de votreDeploymentResourcePool. La longueur maximale est de 63 caractères, et les caractères valides sont /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/.MACHINE_TYPE: facultatif. Ressources machine utilisées pour chaque nœud de ce déploiement. La valeur par défaut estn1-standard-2. En savoir plus sur les types de machines.MIN_REPLICA_COUNT: nombre minimal de nœuds pour ce déploiement. Le nombre de nœuds peut être augmenté ou réduit selon les besoins de la charge d'inférence, dans la limite du nombre maximal de nœuds et jamais moins que ce nombre de nœuds. Cette valeur doit être supérieure ou égale à 1.MAX_REPLICA_COUNT: nombre maximal de nœuds pour ce déploiement. Le nombre de nœuds peut être augmenté ou réduit selon les besoins de la charge d'inférence, dans la limite de ce nombre de nœuds et jamais moins que le nombre minimal de nœuds.
Créer un point de terminaison
Pour créer un point de terminaison, consultez Créer un point de terminaison public à l'aide de la gcloud CLI ou de l'API Vertex AI. Cette étape est identique au déploiement d'un modèle unique.
Récupérer l'ID du point de terminaison
Pour récupérer l'ID du point de terminaison, consultez Déployer un modèle à l'aide de la gcloud CLI ou de l'API Vertex AI. Cette étape est identique au déploiement d'un modèle unique.
Déployer le modèle dans un pool de ressources de déploiement
Après avoir créé un DeploymentResourcePool et un point de terminaison, vous êtes prêt à effectuer un déploiement à l'aide de la méthode API DeployModel. Ce processus est semblable au déploiement d'un modèle unique. S'il existe un DeploymentResourcePool, spécifiez shared_resources sur DeployModel avec le nom de ressource du DeploymentResourcePool que vous déployez.
Cloud Console
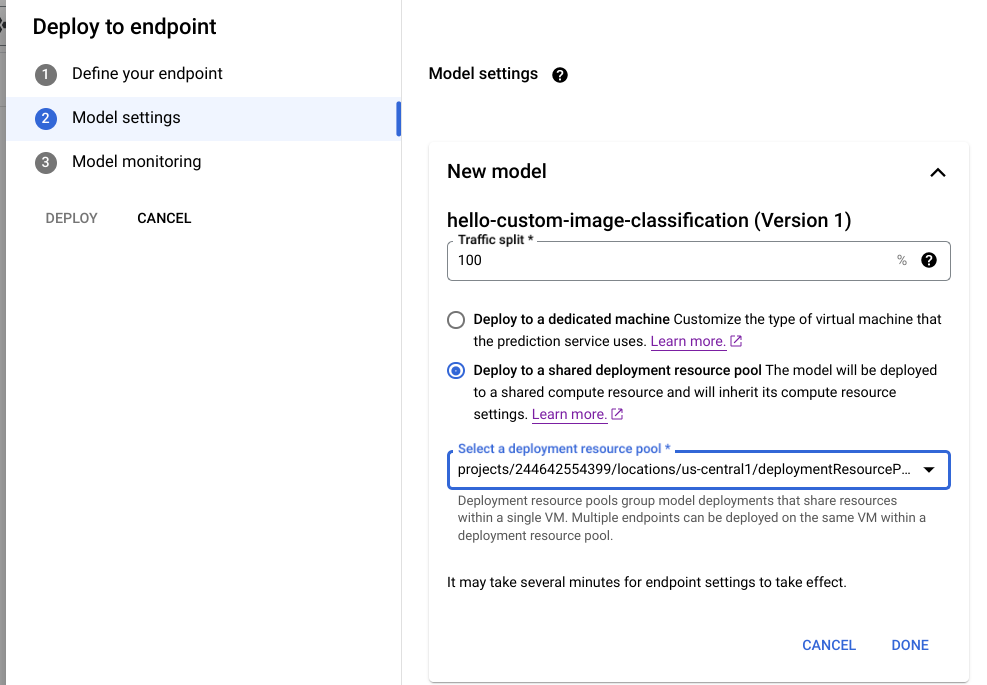
Dans la console Google Cloud , accédez à la page Vertex AI Model Registry.
Recherchez votre modèle, puis cliquez sur Déployer sur un point de terminaison.
Sous Paramètres du modèle (voir ci-dessous), sélectionnez Déployer dans un pool de ressources de déploiement partagé.
REST
Avant d'utiliser les données de requête, effectuez les remplacements suivants :
- LOCATION_ID : région dans laquelle vous utilisez Vertex AI.
- PROJECT : ID de votre projet.
- ENDPOINT_ID : ID du point de terminaison.
- MODEL_ID : ID du modèle à déployer.
-
DEPLOYED_MODEL_NAME : nom de l'élément
DeployedModel. Vous pouvez également utiliser le nom à afficher duModelpour leDeployedModel. -
DEPLOYMENT_RESOURCE_POOL_ID : nom de votre
DeploymentResourcePool. La longueur maximale est de 63 caractères, et les caractères valides sont /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/. - TRAFFIC_SPLIT_THIS_MODEL : pourcentage du trafic de prédiction vers ce point de terminaison à acheminer vers le modèle déployé avec cette opération. La valeur par défaut est 100. La somme des pourcentages de trafic doit être égale à 100. En savoir plus sur la répartition du trafic
- DEPLOYED_MODEL_ID_N : facultatif. Si d'autres modèles sont déployés sur ce point de terminaison, vous devez modifier les pourcentages de répartition du trafic pour que le total des pourcentages soit égal à 100.
- TRAFFIC_SPLIT_MODEL_N : valeur en pourcentage de la répartition du trafic pour la clé de l'ID de modèle déployé.
- PROJECT_NUMBER : numéro de projet généré automatiquement pour votre projet.
Méthode HTTP et URL :
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/endpoints/ENDPOINT_ID:deployModel
Corps JSON de la requête :
{
"deployedModel": {
"model": "projects/PROJECT/locations/us-central1/models/MODEL_ID",
"displayName": "DEPLOYED_MODEL_NAME",
"sharedResources":"projects/PROJECT/locations/us-central1/deploymentResourcePools/DEPLOYMENT_RESOURCE_POOL_ID"
},
"trafficSplit": {
"0": TRAFFIC_SPLIT_THIS_MODEL,
"DEPLOYED_MODEL_ID_1": TRAFFIC_SPLIT_MODEL_1,
"DEPLOYED_MODEL_ID_2": TRAFFIC_SPLIT_MODEL_2
},
}
Pour envoyer votre requête, développez l'une des options suivantes :
Vous devriez recevoir une réponse JSON de ce type :
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.DeployModelOperationMetadata",
"genericMetadata": {
"createTime": "2022-06-19T17:53:16.502088Z",
"updateTime": "2022-06-19T17:53:16.502088Z"
}
}
}
Python
# Deploy model in a deployment resource pool.
model = aiplatform.Model("MODEL_ID")
model.deploy(deployment_resource_pool=deployment_resource_pool)
Remplacez MODEL_ID par l'ID du modèle à déployer.
Répétez la requête ci-dessus avec différents modèles ayant les mêmes ressources partagées pour déployer plusieurs modèles dans le même pool de ressources de déploiement.
Obtenir des inférences
Vous pouvez envoyer des requêtes d'inférence à un modèle d'un DeploymentResourcePool de la même façon que pour tout autre modèle déployé sur Vertex AI.