Per impostazione predefinita, un modello Vertex AI viene sottoposto a deployment nella propria istanza di macchina virtuale (VM). Vertex AI offre la possibilità di co-ospitare modelli sulla stessa VM, il che consente di ottenere i seguenti vantaggi:
- Condivisione delle risorse in più deployment.
- Pubblicazione di modelli conveniente.
- Migliore utilizzo della memoria e delle risorse di calcolo.
Questa guida descrive come condividere le risorse in più deployment su Vertex AI.
Panoramica
Il supporto del co-hosting dei modelli introduce il concetto di DeploymentResourcePool, che raggruppa i deployment dei modelli che condividono le risorse all'interno di una singola VM. È possibile eseguire il deployment di più endpoint sulla stessa VM all'interno di un DeploymentResourcePool. Ogni endpoint ha uno o più modelli di cui è stato eseguito il deployment. I modelli di cui è stato eseguito il deployment per un determinato endpoint possono essere raggruppati nello stesso DeploymentResourcePool o in un altro.
Nel seguente esempio, hai quattro modelli e due endpoint:
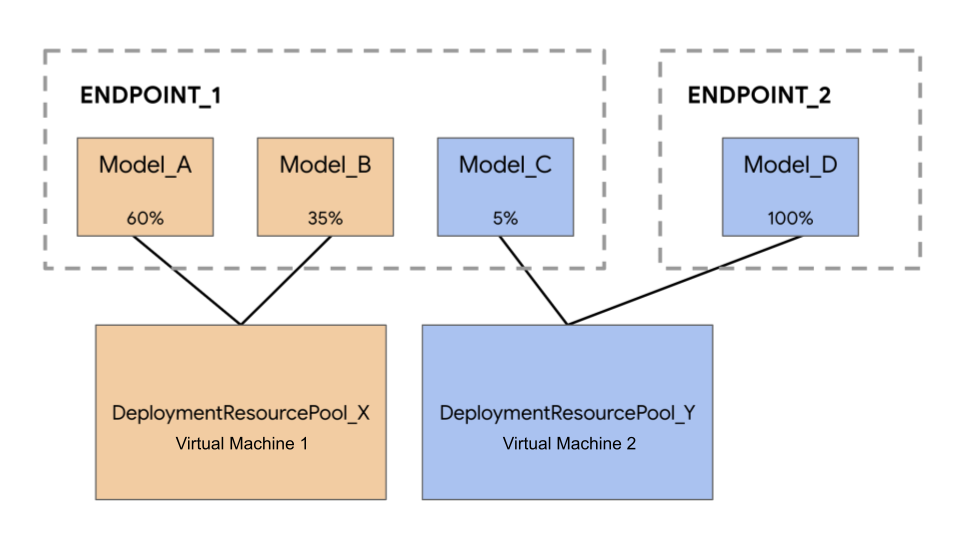
Model_A, Model_B e Model_C vengono implementati in Endpoint_1 con il traffico indirizzato a tutti. Model_D viene implementato in Endpoint_2, che riceve il 100% del traffico per quell'endpoint.
Anziché assegnare ogni modello a una VM separata, puoi raggrupparli in uno dei seguenti modi:
- Raggruppa
Model_AeModel_Bper condividere una VM, che li rende parte diDeploymentResourcePool_X. - Raggruppa
Model_CeModel_D(attualmente non nello stesso endpoint) per condividere una VM, che li rende parte diDeploymentResourcePool_Y.
Pool di risorse di deployment diversi non possono condividere una VM.
Considerazioni
Non esiste un limite superiore al numero di modelli che possono essere sottoposti a deployment in un singolo pool di risorse di deployment. Dipende dalla forma della VM scelta, dalle dimensioni del modello e dai pattern di traffico. Il cohosting è utile quando hai molti modelli di cui è stato eseguito il deployment con traffico scarso, in modo che l'assegnazione di una macchina dedicata a ogni modello di cui è stato eseguito il deployment non utilizzi in modo efficace le risorse.
Puoi eseguire il deployment dei modelli nello stesso pool di risorse di deployment contemporaneamente. Tuttavia, in un determinato momento è possibile inviare al massimo 20 richieste di deployment simultanee.
Un pool di risorse di deployment vuoto non consuma la quota di risorse. Le risorse vengono sottoposte al provisioning in un pool di risorse di deployment quando viene eseguito il deployment del primo modello e vengono rilasciate quando viene annullato il deployment dell'ultimo modello.
I modelli in un singolo pool di risorse di deployment non sono isolati tra loro e possono competere per CPU e memoria. Il rendimento di un modello potrebbe essere peggiore se un altro modello elabora una richiesta di inferenza contemporaneamente.
Limitazioni
Quando esegui il deployment di modelli con la condivisione delle risorse abilitata, esistono le seguenti limitazioni:
- Questa funzionalità è supportata solo per le seguenti configurazioni:
- Deployment di modelli TensorFlow che utilizzano container predefiniti per TensorFlow
- Deployment di modelli PyTorch che utilizzano container predefiniti per PyTorch
- I container predefiniti configurati per altri framework non sono supportati.
- I container personalizzati non sono supportati.
- Sono supportati solo i modelli con addestramento personalizzato e i modelli importati. I modelli AutoML non sono supportati.
- Solo i modelli con la stessa immagine container (inclusa la versione del framework) dei container predefiniti di Vertex AI per l'inferenza per TensorFlow o PyTorch possono essere sottoposti a deployment nello stesso pool di risorse di deployment.
- Vertex Explainable AI non è supportato.
Esegui il deployment di un modello
Per eseguire il deployment di un modello in un DeploymentResourcePool, completa i seguenti passaggi:
- Se necessario, crea un pool di risorse di deployment.
- Se necessario, crea un endpoint.
- Recupera l'ID endpoint.
- Esegui il deployment del modello sull'endpoint nel pool di risorse di deployment.
Crea un pool di risorse di deployment
Se stai eseguendo il deployment di un modello in un DeploymentResourcePool esistente, salta questo passaggio:
Utilizza CreateDeploymentResourcePool per creare un pool di risorse.
Cloud Console
Nella console Google Cloud , vai alla pagina Pool di risorse per il deployment di Vertex AI.
Fai clic su Crea e compila il modulo (mostrato di seguito).

REST
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
- LOCATION_ID: la regione in cui utilizzi Vertex AI.
- PROJECT_ID: il tuo ID progetto
-
MACHINE_TYPE: (Facoltativo). Le risorse macchina utilizzate per ogni nodo di questo
deployment. L'impostazione predefinita è
n1-standard-2. Scopri di più sui tipi di macchina. - ACCELERATOR_TYPE: il tipo di acceleratore da collegare alla macchina. Facoltativo se ACCELERATOR_COUNT non è specificato o è zero. Sconsigliato per modelli AutoML o modelli con addestramento personalizzato che utilizzano immagini non GPU. Scopri di più.
- ACCELERATOR_COUNT: il numero di acceleratori da utilizzare per ogni replica. Facoltativo. Deve essere zero o non specificato per i modelli AutoML o i modelli con addestramento personalizzato che utilizzano immagini non GPU.
- MIN_REPLICA_COUNT: Il numero minimo di nodi per questo deployment. Il conteggio di nodi può essere aumentato o diminuito in base al carico di inferenza, fino al numero massimo di nodi e mai al di sotto di questo numero di nodi. Questo valore deve essere maggiore o uguale a 1.
- MAX_REPLICA_COUNT: il numero massimo di nodi per questo deployment. Il conteggio di nodi può essere aumentato o diminuito in base al carico di inferenza, fino a questo numero di nodi e mai al di sotto del numero minimo di nodi.
- REQUIRED_REPLICA_COUNT: (Facoltativo). Il numero richiesto di nodi per contrassegnare questo deployment come riuscito. Deve essere maggiore o uguale a 1 e minore o uguale al numero minimo di nodi. Se non è specificato, il valore predefinito è il numero minimo di nodi.
-
DEPLOYMENT_RESOURCE_POOL_ID: un nome per il tuo
DeploymentResourcePool. La lunghezza massima è di 63 caratteri e i caratteri validi sono /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/.
Metodo HTTP e URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/deploymentResourcePools
Corpo JSON della richiesta:
{
"deploymentResourcePool":{
"dedicatedResources":{
"machineSpec":{
"machineType":"MACHINE_TYPE",
"acceleratorType":"ACCELERATOR_TYPE",
"acceleratorCount":"ACCELERATOR_COUNT"
},
"minReplicaCount":MIN_REPLICA_COUNT,
"maxReplicaCount":MAX_REPLICA_COUNT,
"requiredReplicaCount":REQUIRED_REPLICA_COUNT
}
},
"deploymentResourcePoolId":"DEPLOYMENT_RESOURCE_POOL_ID"
}
Per inviare la richiesta, espandi una di queste opzioni:
Dovresti ricevere una risposta JSON simile alla seguente:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION_ID/deploymentResourcePools/DEPLOYMENT_RESOURCE_POOL_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.CreateDeploymentResourcePoolOperationMetadata",
"genericMetadata": {
"createTime": "2022-06-15T05:48:06.383592Z",
"updateTime": "2022-06-15T05:48:06.383592Z"
}
}
}
Puoi eseguire il polling dello stato dell'operazione finché
la risposta non include "done": true.
Python
# Create a deployment resource pool.
deployment_resource_pool = aiplatform.DeploymentResourcePool.create(
deployment_resource_pool_id="DEPLOYMENT_RESOURCE_POOL_ID", # User-specified ID
machine_type="MACHINE_TYPE", # Machine type
min_replica_count=MIN_REPLICA_COUNT, # Minimum number of replicas
max_replica_count=MAX_REPLICA_COUNT, # Maximum number of replicas
)
Sostituisci quanto segue:
DEPLOYMENT_RESOURCE_POOL_ID: un nome per il tuoDeploymentResourcePool. La lunghezza massima è di 63 caratteri e i caratteri validi sono /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/.MACHINE_TYPE: (Facoltativo). Le risorse macchina utilizzate per ogni nodo di questo deployment. Il valore predefinito èn1-standard-2. Scopri di più sui tipi di macchina.MIN_REPLICA_COUNT: Il numero minimo di nodi per questo deployment. Il conteggio di nodi può essere aumentato o diminuito in base al carico di inferenza fino al numero massimo di nodi e mai al di sotto di questo numero di nodi. Questo valore deve essere maggiore o uguale a 1.MAX_REPLICA_COUNT: Il numero massimo di nodi per questo deployment. Il conteggio di nodi può essere aumentato o diminuito in base al carico di inferenza fino a questo numero di nodi e mai al di sotto del numero minimo di nodi.
Creazione di un endpoint
Per creare un endpoint, consulta Crea un endpoint pubblico utilizzando l'interfaccia a riga di comando gcloud o l'API Vertex AI. Questo passaggio è uguale a quello per un deployment a modello singolo.
Recupera l'ID endpoint
Per recuperare l'ID endpoint, consulta Esegui il deployment di un modello utilizzando gcloud CLI o l'API Vertex AI. Questo passaggio è uguale a quello per un deployment a modello singolo.
Esegui il deployment del modello in un pool di risorse di deployment
Dopo aver creato un DeploymentResourcePool e un endpoint, puoi eseguire il deployment utilizzando il metodo API DeployModel. Questa procedura è simile a un deployment di un singolo modello. Se è presente un DeploymentResourcePool, specifica shared_resources di DeployModel con il nome della risorsa del DeploymentResourcePool che stai implementando.
Cloud Console
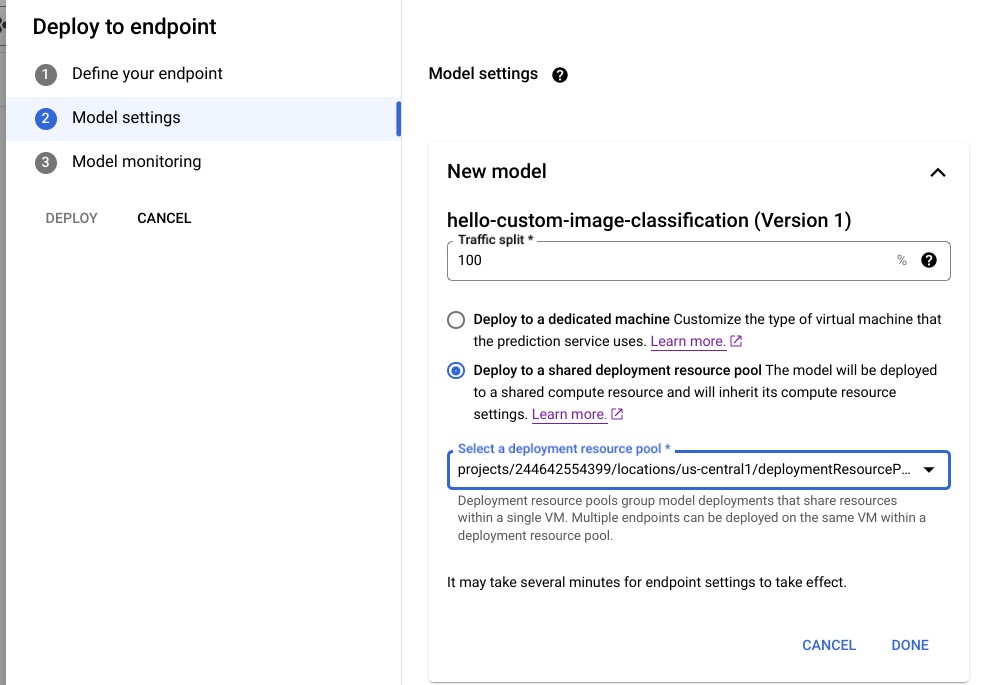
Nella console Google Cloud , vai alla pagina Model Registry di Vertex AI.
Trova il tuo modello e fai clic su Deployment su endpoint.
Nella sezione Impostazioni modello (mostrata di seguito), seleziona Esegui il deployment in un pool di risorse di deployment condiviso.
REST
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
- LOCATION_ID: la regione in cui utilizzi Vertex AI.
- PROJECT: il tuo ID progetto
- ENDPOINT_ID: l'ID dell'endpoint.
- MODEL_ID: L'ID del modello da implementare.
-
DEPLOYED_MODEL_NAME: un nome per
DeployedModel. Puoi utilizzare il nome visualizzato diModelanche perDeployedModel. -
DEPLOYMENT_RESOURCE_POOL_ID: un nome per il tuo
DeploymentResourcePool. La lunghezza massima è di 63 caratteri e i caratteri validi sono /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/. - TRAFFIC_SPLIT_THIS_MODEL: la percentuale di traffico di previsione verso questo endpoint da indirizzare al modello di cui viene eseguito il deployment con questa operazione. Il valore predefinito è 100. La somma di tutte le percentuali di traffico deve essere pari a 100. Scopri di più sulle suddivisioni del traffico.
- DEPLOYED_MODEL_ID_N: (Facoltativo). Se su questo endpoint sono stati implementati altri modelli, devi aggiornare le percentuali di suddivisione del traffico in modo che la somma di tutte le percentuali sia pari a 100.
- TRAFFIC_SPLIT_MODEL_N: Il valore percentuale di suddivisione del traffico per la chiave dell'ID modello di cui è stato eseguito il deployment.
- PROJECT_NUMBER: il numero di progetto generato automaticamente per il tuo progetto
Metodo HTTP e URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/endpoints/ENDPOINT_ID:deployModel
Corpo JSON della richiesta:
{
"deployedModel": {
"model": "projects/PROJECT/locations/us-central1/models/MODEL_ID",
"displayName": "DEPLOYED_MODEL_NAME",
"sharedResources":"projects/PROJECT/locations/us-central1/deploymentResourcePools/DEPLOYMENT_RESOURCE_POOL_ID"
},
"trafficSplit": {
"0": TRAFFIC_SPLIT_THIS_MODEL,
"DEPLOYED_MODEL_ID_1": TRAFFIC_SPLIT_MODEL_1,
"DEPLOYED_MODEL_ID_2": TRAFFIC_SPLIT_MODEL_2
},
}
Per inviare la richiesta, espandi una di queste opzioni:
Dovresti ricevere una risposta JSON simile alla seguente:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.DeployModelOperationMetadata",
"genericMetadata": {
"createTime": "2022-06-19T17:53:16.502088Z",
"updateTime": "2022-06-19T17:53:16.502088Z"
}
}
}
Python
# Deploy model in a deployment resource pool.
model = aiplatform.Model("MODEL_ID")
model.deploy(deployment_resource_pool=deployment_resource_pool)
Sostituisci MODEL_ID con l'ID del modello di cui eseguire il deployment.
Ripeti la richiesta precedente con modelli diversi che hanno le stesse risorse condivise per eseguire il deployment di più modelli nello stesso pool di risorse di deployment.
Ottenere inferenze
Puoi inviare richieste di inferenza a un modello in un DeploymentResourcePool come faresti con qualsiasi altro modello di cui è stato eseguito il deployment su Vertex AI.