本页面简要介绍了 Vertex AI Model Monitoring。
监控概览
借助 Vertex AI Model Monitoring,您可以根据需要或按固定时间表运行监控作业,以跟踪表格模型的质量。如果您设置了提醒,Vertex AI Model Monitoring 会在指标超出指定阈值时通知您。
例如,假设您有一个用于预测客户生命周期价值的模型。随着客户习惯的变化,预测客户支出的因素也会发生变化。因此,您之前用于训练模型的特征和特征值可能不适用于现在进行预测。数据中的这种偏差称为偏移。
Vertex AI Model Monitoring 可以跟踪偏差超过指定阈值的情况并向您发出提醒。您随后可以重新评估或重新训练模型,以确保模型的行为符合预期。
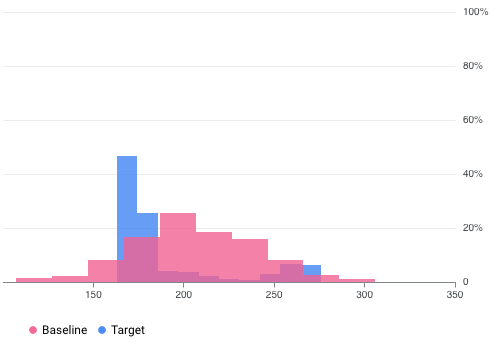
例如,Vertex AI Model Monitoring 可以提供如下图所示的可视化图表,下图叠加了来自两个数据集的两个图表。这种可视化图表可让您快速比较和查看两个数据集之间的差异。
Vertex AI Model Monitoring 版本
Vertex AI Model Monitoring 提供两个产品:v2 和 v1。
Model Monitoring v2 目前处于预览版阶段,是最新的产品,可将所有监控任务与模型版本相关联。相比之下,Model Monitoring v1 已正式发布,并在 Vertex AI 端点上进行了配置。
如果您需要生产级支持并希望监控部署在 Vertex AI 端点上的模型,请使用 Model Monitoring v1。对于所有其他应用场景,请使用 Model Monitoring v2,它可提供 Model Monitoring v1 的所有功能以及更多功能。如需了解详情,请参阅每个版本的概览:
对于现有的 Model Monitoring v1 用户,Model Monitoring v1 将保持原样。您无需迁移到 Model Monitoring v2。如果您想要迁移,则可以同时使用这两个版本,直到完全迁移到 Model Monitoring v2,这样有助于避免在转换期间出现监控间断。
Model Monitoring v2 概览
Model Monitoring v2 使您可以在配置模型监控并运行监控作业后,跟踪一段时间内的指标。您可以运行按需监控作业或设置安排的运行作业。使用安排的运行作业时,Model Monitoring 会根据您定义的时间表自动运行监控作业。
监控目标
您监控的指标和阈值会映射到监控目标。对于每个模型版本,您可以指定一个或多个监控目标。下表详细介绍了每个目标:
| 目标 | 说明 | 特征数据类型 | 支持的指标 |
|---|---|---|---|
| 输入特征数据偏移 |
与基准数据分布相比,衡量输入特征值的分布。 |
分类:布尔值、字符串、分类 |
|
| 数值:浮点数、整数 | Jensen Shannon 差异 | ||
| 输出预测数据偏移 |
与基准数据分布相比,衡量模型的预测数据分布。 |
分类:布尔值、字符串、分类 |
|
| 数值:浮点数、整数 | Jensen Shannon 差异 | ||
| 特征归因 |
与基准相比,衡量特征对模型预测结果的贡献变化。例如,您可以跟踪某个非常重要的特征的重要性是否突然降低。 |
所有数据类型 | SHAP 值 (SHapley Additive exPlanations) |
输入特征和输出预测偏移
在生产环境中部署模型后,输入数据可能会偏离用于训练模型的数据,或者生产环境中特征数据分布可能会随时间推移而发生显著变化。Model Monitoring v2 可以监控生产数据分布相对于训练数据的变化,或跟踪生产数据分布随时间的演变。
同样,对于预测数据,Model Monitoring v2 可以监控与训练数据或生产数据分布相比,预测结果分布随时间的变化。
特征归因
特征归因指出了模型中每个特征对每个给定实例的预测结果的影响程度。归因得分与特征对模型预测结果的贡献成正比。它们通常是有符号的,表明某个特征是否有助于提高或降低预测。所有特征的归因必须添加到模型的预测得分中。
通过监控特征归因,Model Monitoring v2 会跟踪特征对模型预测结果的贡献随时间的变化。关键特征的归因得分发生变化通常表明该特征发生了某种形式的变化,可能会影响模型预测结果的准确率。
如需详细了解特征归因和指标,请参阅基于特征的解释和采样 Shapley 方法。
如何设置 Model Monitoring v2
您必须先在 Vertex AI Model Registry 中注册模型。如果您要应用 Vertex AI 之外的模型,则无需上传模型工件。然后创建与模型版本关联的模型监控,并定义模型架构。对于某些模型(例如 AutoML 模型),系统会为您提供架构。
在模型监控中,您可以选择指定默认配置,例如监控目标、训练数据集、监控输出位置和通知设置。如需了解详情,请参阅设置模型监控。
创建模型监控后,您可以按需运行监控作业,或安排定期作业以进行持续监控。运行作业时,除非您提供其他监控配置,否则 Model Monitoring 会使用模型监控中设置的默认配置。例如,如果您提供不同的监控目标或不同的比较数据集,Model Monitoring 会使用作业的配置,而不是模型监控中的默认配置。如需了解详情,请参阅运行监控作业。
价格
在预览版期间,您无需为 Model Monitoring v2 付费。您仍然需要为其他服务(例如 Cloud Storage、BigQuery、Vertex AI 批量预测、Vertex Explainable AI 和 Cloud Logging)的使用付费。
笔记本教程
以下教程演示了如何使用 Vertex AI SDK for Python 为模型设置 Model Monitoring v2。
Model Monitoring v2:自定义模型批量预测作业
Model Monitoring v2:自定义模型在线预测
Model Monitoring v2:Vertex AI 之外的模型
Model Monitoring v1 概览
为了帮助您保持模型的性能,Model Monitoring v1 会监控模型的预测输入数据,以获取特征偏差和偏移:
当生产中的特征数据分布与用于训练模型的特征数据分布存在差异时,就会发生训练-应用偏差。如果原始训练数据可用,您可以启用偏差检测,监控模型以执行训练-应用偏差。
当生产环境中的特征数据分布随时间发生显著变化时发生预测偏移。如果原始训练数据不可用,您可以启用偏移检测来监控输入数据随时间的变化。
您可以同时启用偏差检测和偏移检测。
Model Monitoring v1 支持分类和数值特征的特征偏差和偏移检测。
分类特征是受可能值数量限制的数据,通常按定性属性分组。例如,商品类型、国家/地区或客户类型等类别。
数值特征是可为任何数值的数据。例如,重量和高度。
一旦模型特征的偏差或偏移超过您设置的提醒阈值,Model Monitoring v1 就会向您发送电子邮件提醒。您还可以查看每个特征在一段时间内的分布情况,以评估是否需要重新训练模型。
计算偏移
为了针对 v1 检测偏移,Vertex AI Model Monitoring 使用 TensorFlow Data Validation (TFDV) 来计算分布和距离得分。
计算基准统计分布:
对于偏差检测,基准是训练数据中特征值的统计分布。
对于偏移检测,基准是指过去生产中特征值的统计分布。
分类和数值特征的分布按如下方式计算:
对于分类特征,计算分布为特征每个可能值的实例数量或百分比。
对于数值特征,Vertex AI Model Monitoring 会将可能特征值的范围划分为等间隔,并计算每个间隔中的特征值的数量或百分比。
基准是在创建 Vertex AI Model Monitoring 作业时计算的,并且仅在您更新作业的训练数据集时才会重新计算。
计算生产环境中最新特征值的统计分布。
通过计算距离得分,将最新特征值在生产环境中的分布与基准分布进行比较:
对于分类特征,距离得分使用 L-无穷大距离计算得出。
对于数值特征,距离得分使用 Jensen-Shannon 差异计算得出。
当两个统计分布之间的距离得分超过您指定的阈值时,Vertex AI Model Monitoring 会将异常值标识为偏差或偏移。
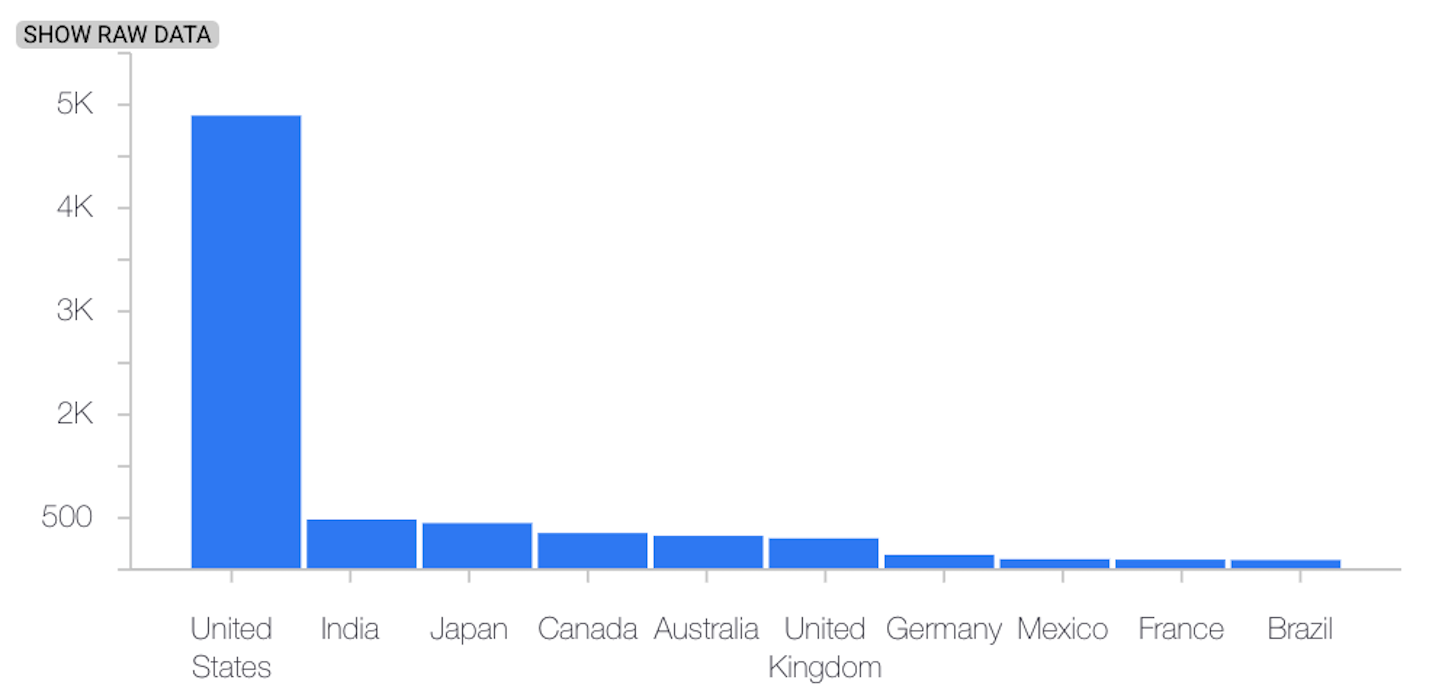
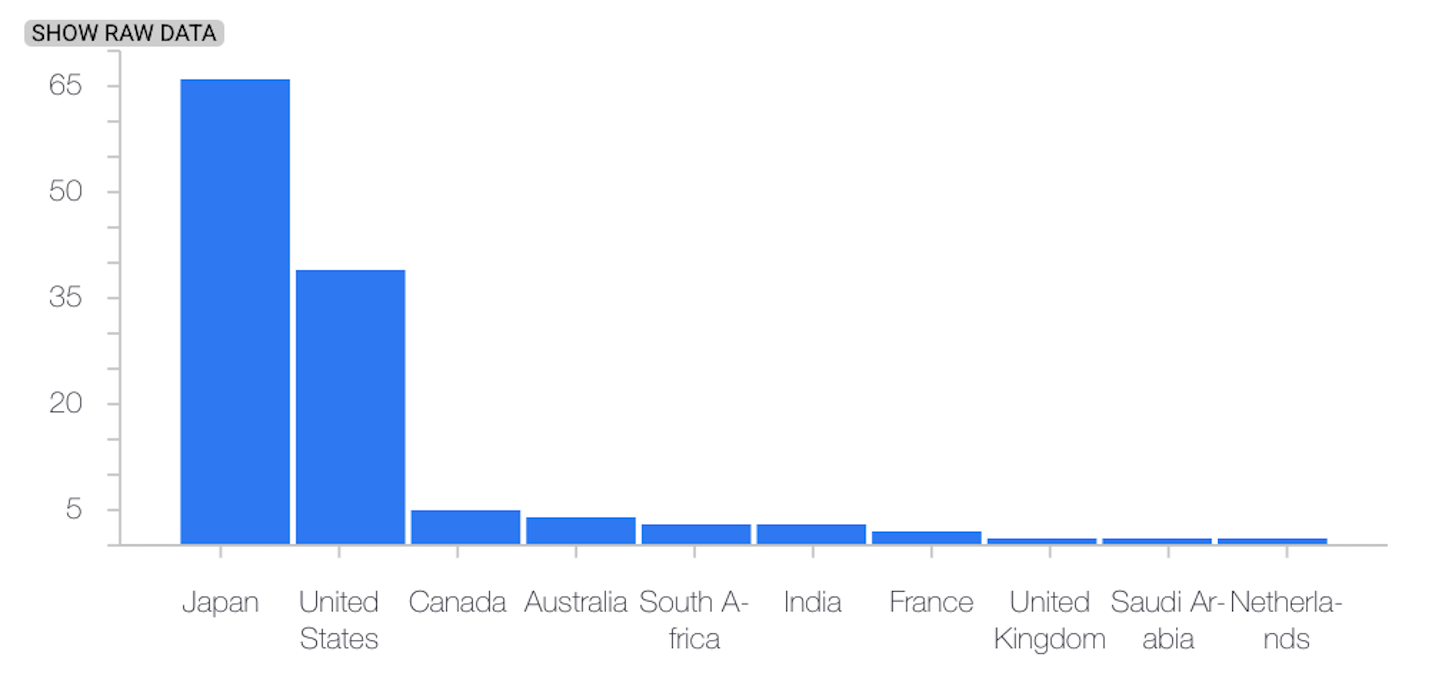
以下示例展示了分类特征的基准分布和最新分布之间的偏差或偏移:
基准分布
最新分布
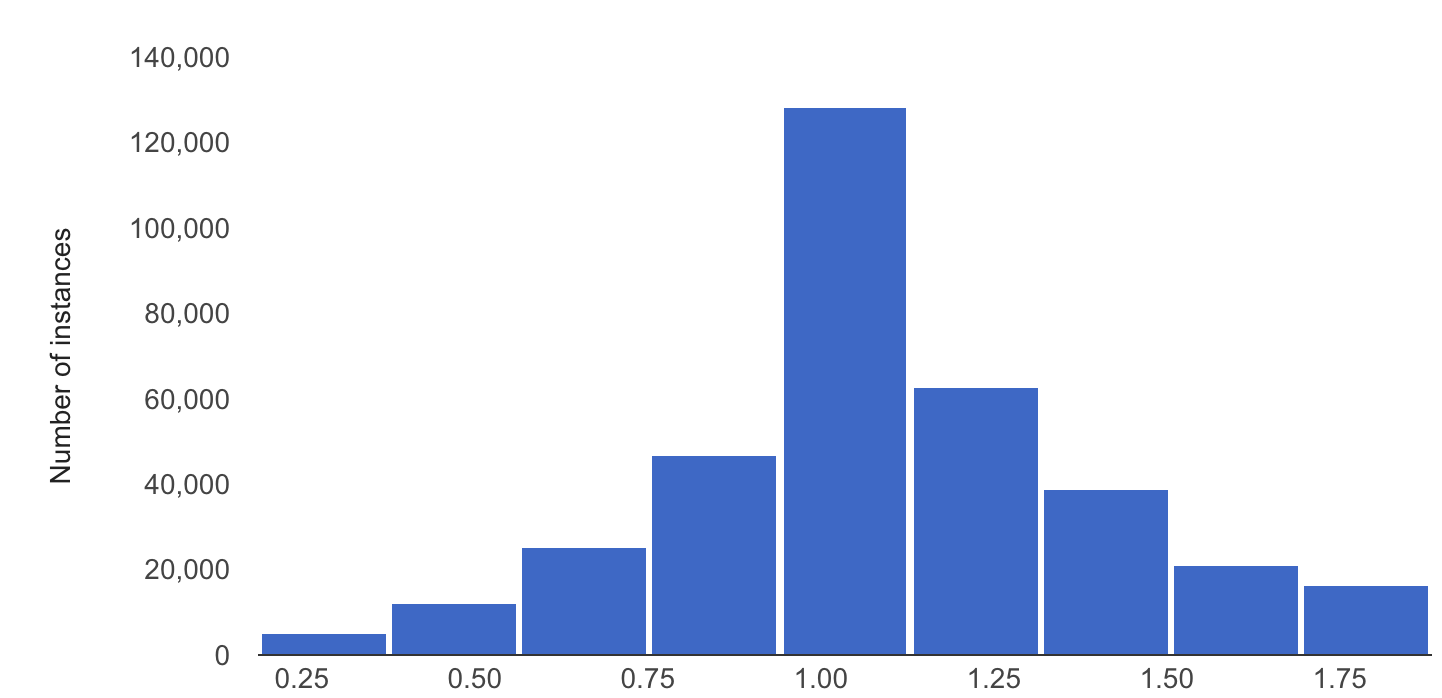
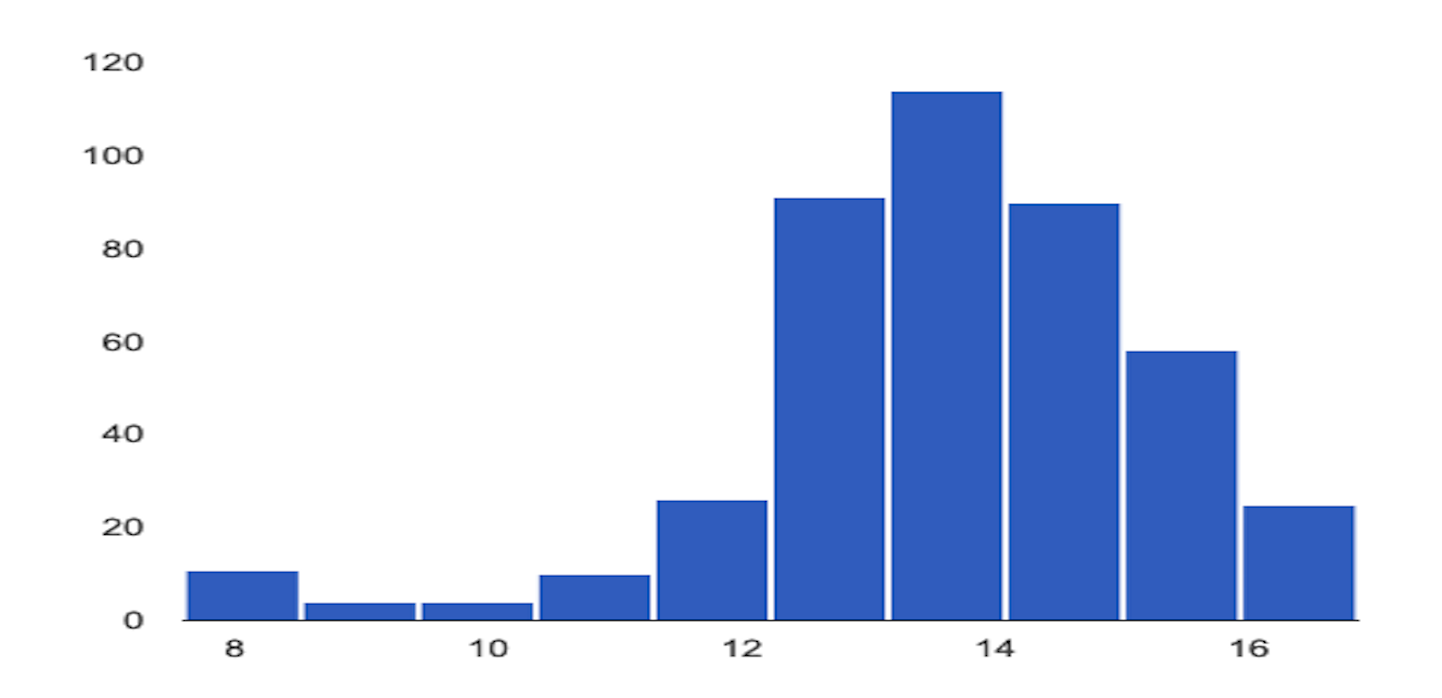
以下示例展示了数值特征的基准分布和最新分布之间的偏差或偏移:
基准分布
最新分布
使用模型监控时的注意事项
为了提高成本效益,您可以设置预测请求采样率,以监控模型的部分生产输入。
您可以设置监控已部署的模型最近记录的输入是否存在偏差或偏移的频率。监控频率决定了每次监控运行中分析的所记录数据的时间范围或监控窗口大小。
您可以为要监控的每个特征指定提醒阈值。当输入特征分布与其对应的基准之间的统计距离超过指定的阈值时,系统会记录提醒。默认情况下,每个分类和数值特征都会受监控,并且阈值为 0.3。
在线预测端点可以托管多个模型。如果您对某个端点启用偏差或偏移检测,则会在该端点上托管的所有模型之间共享以下配置参数:
- 检测类型
- 监控频率
- 监控输入请求的比例
对于其他配置参数,您可以为每个模型设置不同的值。