This page provides an overview of Vertex AI Model Monitoring.
Monitoring overview
Vertex AI Model Monitoring lets you run monitoring jobs as needed or on a regular schedule to track the quality of your tabular models. If you've set alerts, Vertex AI Model Monitoring informs you when metrics surpass a specified threshold.
For example, assume that you have a model that predicts customer lifetime value. As customer habits change, the factors that predict customer spending also change. Consequently, the features and feature values that you used to train your model before might not be relevant for making inferences today. This deviation in the data is known as drift.
Vertex AI Model Monitoring can track and alert you when deviations exceed a specified threshold. You can then re-evaluate or retrain your model to ensure the model is behaving as intended.
For example, Vertex AI Model Monitoring can provide visualizations like in the following figure, which overlays two graphs from two datasets. This visualization lets you quickly compare and see deviations between the two sets of data.
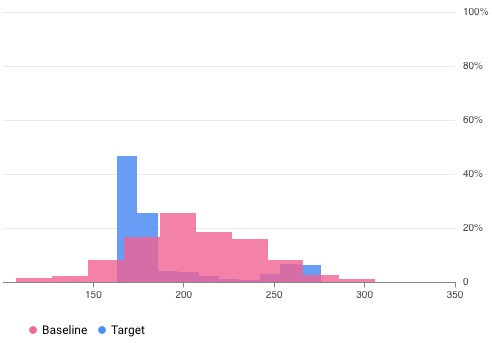
Vertex AI Model Monitoring versions
Vertex AI Model Monitoring provides two offerings: v2 and v1.
Model Monitoring v2 is in Preview and is the latest offering that associates all monitoring tasks with a model version. In contrast, Model Monitoring v1 is Generally Available and is configured on Vertex AI endpoints.
If you need production-level support and want to monitor a model that's deployed on a Vertex AI endpoint, use Model Monitoring v1. For all other use cases, use Model Monitoring v2, which provides all the capabilities of Model Monitoring v1 and more. For more information, see the overview for each version:
For existing Model Monitoring v1 users, Model Monitoring v1 is maintained as is. You aren't required to migrate to Model Monitoring v2. If you want to migrate, you can use both versions concurrently until you have fully migrated to Model Monitoring v2 to help you avoid monitoring gaps during your transition.
Model Monitoring v2 overview
Model Monitoring v2 lets you track metrics over time after you configure a model monitor and run monitoring jobs. You can run on-demand monitoring jobs or set up scheduled runs. By using scheduled runs, Model Monitoring automatically runs monitoring jobs based on a schedule that you define.
Monitoring objectives
The metrics and thresholds you monitor are mapped to monitoring objectives. For each model version, you can specify one or more monitoring objectives. The following table details each objective:
| Objective | Description | Feature data type | Supported metrics |
|---|---|---|---|
| Input feature data drift |
Measures the distribution of input feature values compared to a baseline data distribution. |
Categorical: boolean, string, categorical |
|
| Numerical: float, integer | Jensen Shannon Divergence | ||
| Output inference data drift |
Measures the model's inferences data distribution compared to a baseline data distribution. |
Categorical: boolean, string, categorical |
|
| Numerical: float, integer | Jensen Shannon Divergence | ||
| Feature attribution |
Measures the change in contribution of features to a model's inference compared to a baseline. For example, you can track if a highly important feature suddenly drops in importance. |
All data types | SHAP value (SHapley Additive exPlanations) |
Input feature and output inference drift
After a model is deployed in production, the input data can deviate from the data that was used to train the model or the distribution of feature data in production could shift significantly over time. Model Monitoring v2 can monitor changes in the distribution of production data compared to the training data or to track the evolution of production data distribution over time.
Similarly, for inference data, Model Monitoring v2 can monitor changes in the distribution of predicted outcomes compared to the training data or production data distribution over time.
Feature attribution
Feature attributions indicate how much each feature in your model contributed to the inferences for each given instance. Attribution scores are proportional to the contribution of the feature to a model's inference. They are typically signed, indicating whether a feature helps push the inference up or down. Attributions across all features must add up to the model's inference score.
By monitoring feature attributions, Model Monitoring v2 tracks changes in a feature's contributions to a model's inferences over time. A change in a key feature's attribution score often signals that the feature has changed in a way that can impact the accuracy of the model's inferences.
For more information about feature attributions and metrics, see Feature-based explanations and Sampled Shapley method.
How to set up Model Monitoring v2
You must first register your models in Vertex AI Model Registry. If you are serving models outside of Vertex AI, you don't need to upload the model artifact. You then create a model monitor, which you associate with a model version, and define your model schema. For some models, such as AutoML models, the schema is provided for you.
In the model monitor, you can optionally specify default configurations such as monitoring objectives, a training dataset, monitoring output location, and notification settings. For more information, see Set up model monitoring.
After you create a model monitor, you can run a monitoring job on demand or schedule regular jobs for continuous monitoring. When you run a job, Model Monitoring uses the default configuration set in the model monitor unless you provide a different monitoring configuration. For example, if you provide different monitoring objectives or a different comparison dataset, Model Monitoring uses the job's configurations instead of the default configuration from the model monitor. For more information, see Run a monitoring job.
Pricing
You are not charged for Model Monitoring v2 during the Preview. You are still charged for the usage of other services, such as Cloud Storage, BigQuery, Vertex AI batch inferences, Vertex Explainable AI, and Cloud Logging.
Notebook tutorials
The following tutorials demonstrate how to use the Vertex AI SDK for Python to set up Model Monitoring v2 for your model.
Model Monitoring v2: Custom model batch inference job
Model Monitoring v2: Custom model online inference
Model Monitoring v2: Models outside Vertex AI
Model Monitoring v1 overview
To help you maintain a model's performance, Model Monitoring v1 monitors the model's inference input data for feature skew and drift:
Training-serving skew occurs when the feature data distribution in production deviates from the feature data distribution used to train the model. If the original training data is available, you can enable skew detection to monitor your models for training-serving skew.
Inference drift occurs when feature data distribution in production changes significantly over time. If the original training data isn't available, you can enable drift detection to monitor the input data for changes over time.
You can enable both skew and drift detection.
Model Monitoring v1 supports feature skew and drift detection for categorical and numerical features:
Categorical features are data limited by number of possible values, typically grouped by qualitative properties. For example, categories such as product type, country, or customer type.
Numerical features are data that can be any numeric value. For example, weight and height.
Once the skew or drift for a model's feature exceeds an alerting threshold that you set, Model Monitoring v1 sends you an email alert. You can also view the distributions for each feature over time to evaluate whether you need to retrain your model.
Calculate drift
To detect drift for v1, Vertex AI Model Monitoring uses TensorFlow Data Validation (TFDV) to calculate the distributions and distance scores.
Calculate the baseline statistical distribution:
For skew detection, the baseline is the statistical distribution of the feature's values in the training data.
For drift detection, the baseline is the statistical distribution of the feature's values seen in production in the past.
The distributions for categorical and numerical features are calculated as follows:
For categorical features, the computed distribution is the number or percentage of instances of each possible value of the feature.
For numerical features, Vertex AI Model Monitoring divides the range of possible feature values into equal intervals and computes the number or percentage of feature values that falls in each interval.
The baseline is calculated when you create a Vertex AI Model Monitoring job, and is only recalculated if you update the training dataset for the job.
Calculate the statistical distribution of the latest feature values seen in production.
Compare the distribution of the latest feature values in production against the baseline distribution by calculating a distance score:
For categorical features, the distance score is calculated using the L-infinity distance.
For numerical features, the distance score is calculated using the Jensen-Shannon divergence.
When the distance score between two statistical distributions exceeds the threshold you specify, Vertex AI Model Monitoringidentifies the anomaly as skew or drift.
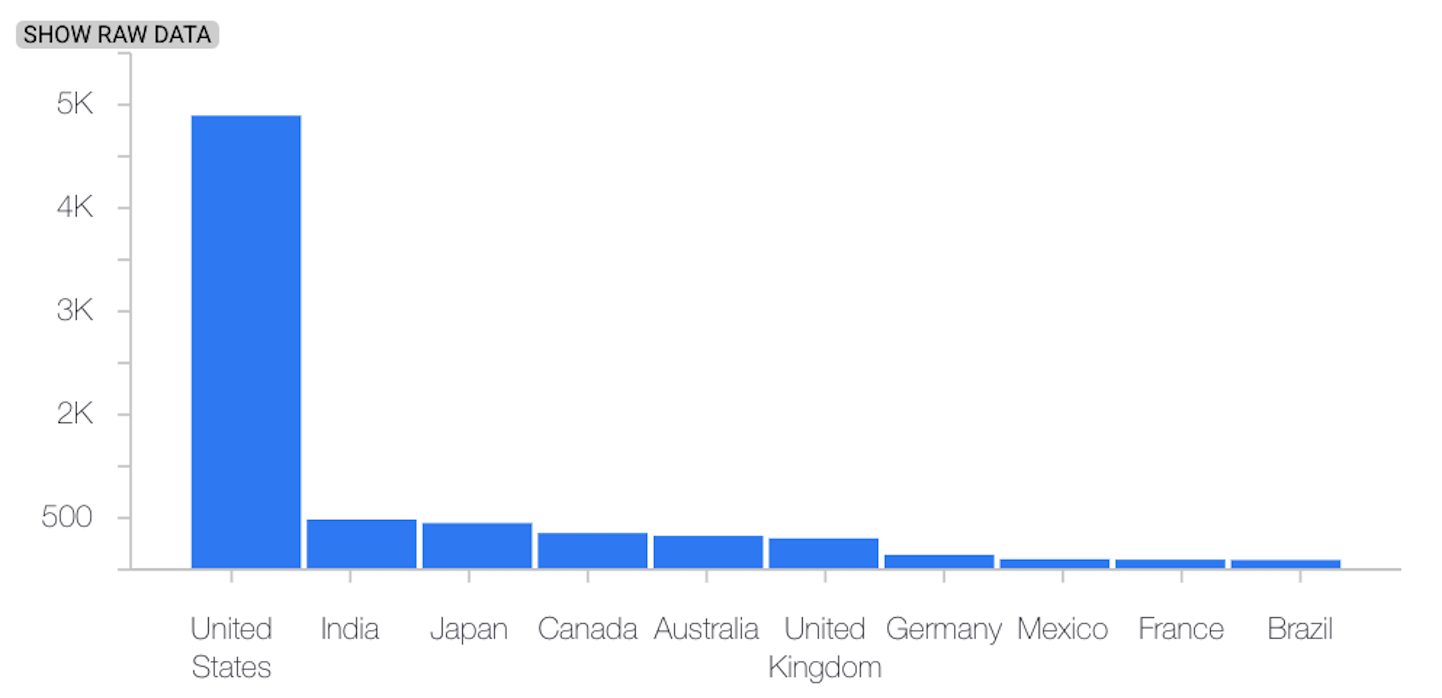
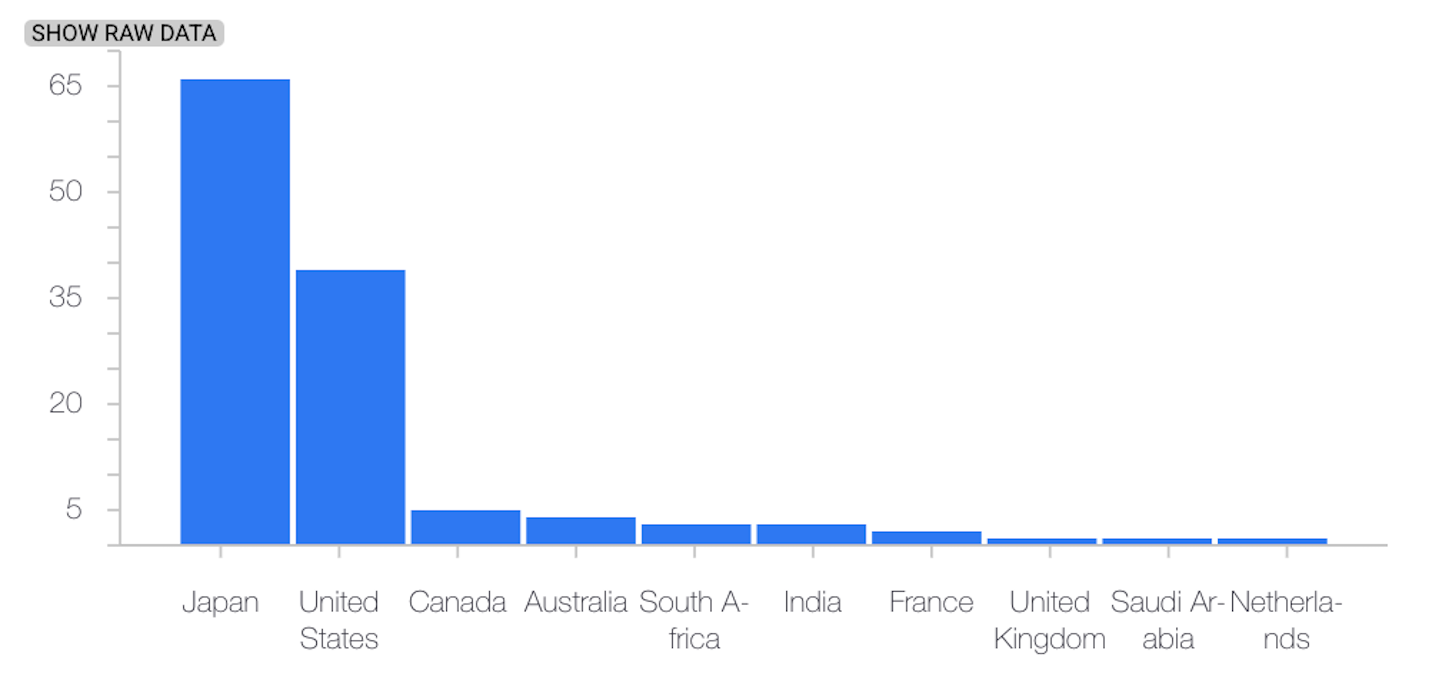
The following example shows skew or drift between the baseline and latest distributions of a categorical feature:
Baseline distribution
Latest distribution
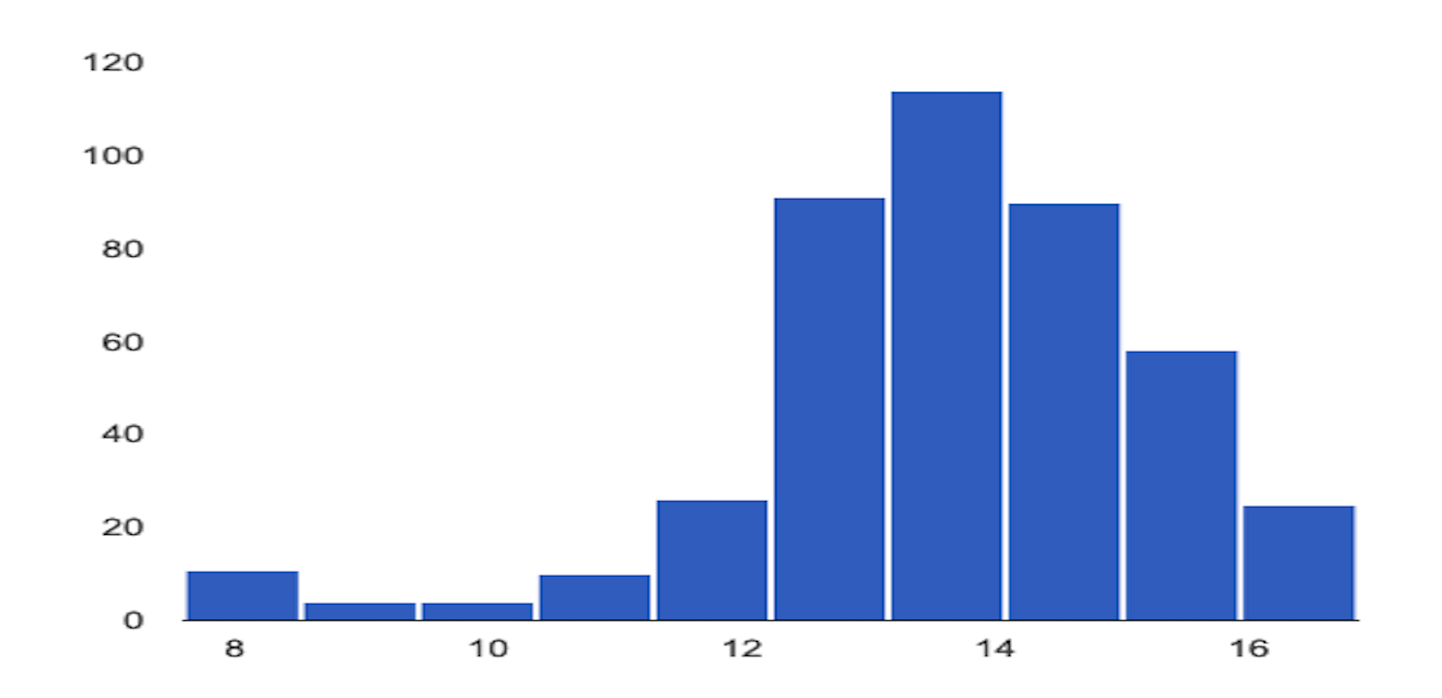
The following example shows skew or drift between the baseline and latest distributions of a numerical feature:
Baseline distribution
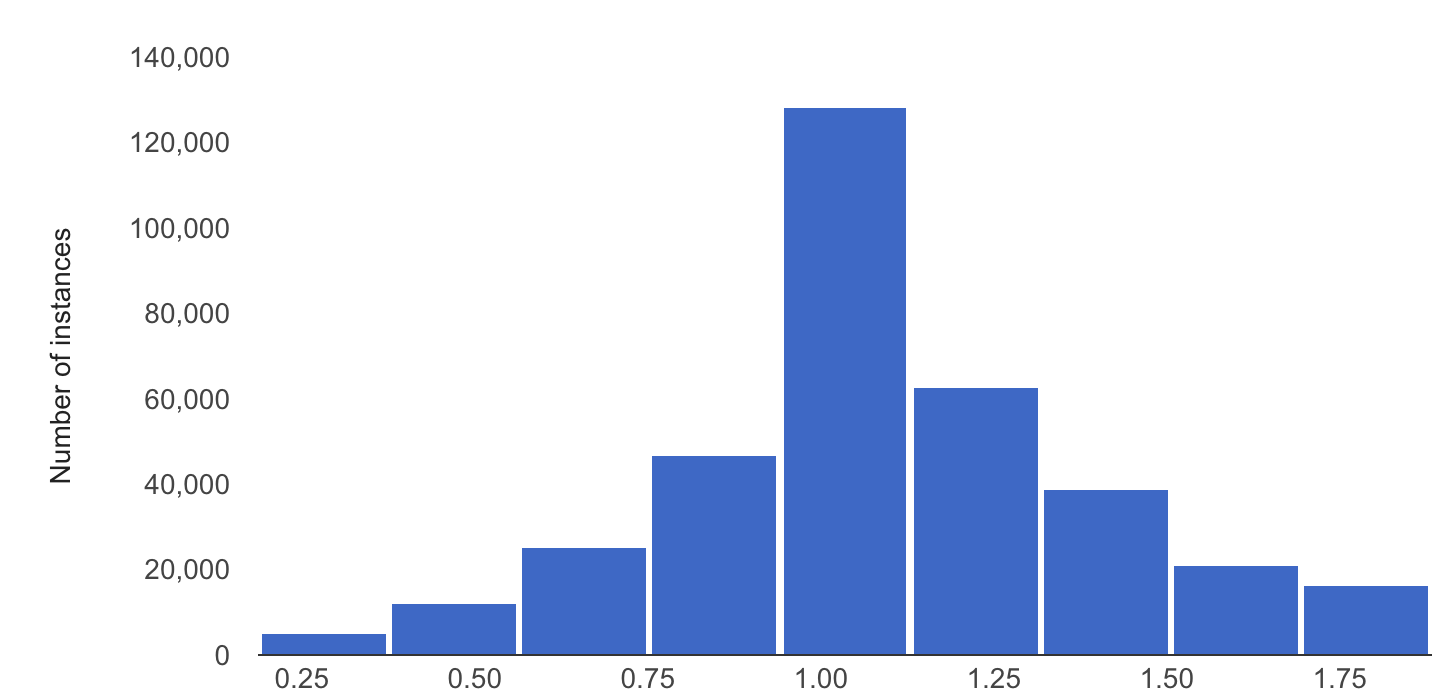
Latest distribution
Considerations when using Model Monitoring
For cost efficiency, you can set a inference request sampling rate to monitor a subset of the production inputs to a model.
You can set a frequency at which a deployed model's recently logged inputs are monitored for skew or drift. Monitoring frequency determines the timespan, or monitoring window size, of logged data that is analyzed in each monitoring run.
You can specify alerting thresholds for each feature you want to monitor. An alert is logged when the statistical distance between the input feature distribution and its corresponding baseline exceeds the specified threshold. By default, every categorical and numerical feature is monitored, with threshold values of 0.3.
An online inference endpoint can host multiple models. When you enable skew or drift detection on an endpoint, the following configuration parameters are shared across all models hosted in that endpoint:
- Type of detection
- Monitoring frequency
- Fraction of input requests monitored
For the other configuration parameters, you can set different values for each model.