En esta página se ofrece una descripción general de Vertex AI Model Monitoring.
Información general sobre la monitorización
Vertex AI Model Monitoring te permite ejecutar trabajos de monitorización cuando lo necesites o de forma periódica para hacer un seguimiento de la calidad de tus modelos tabulares. Si has configurado alertas, Vertex AI Model Monitoring te informa cuando las métricas superan un umbral especificado.
Por ejemplo, supongamos que tienes un modelo que predice el valor del tiempo de vida del cliente. A medida que cambian los hábitos de los clientes, también lo hacen los factores que predicen su gasto. Por lo tanto, es posible que las características y los valores de las características que usaste para entrenar tu modelo antes no sean relevantes para hacer inferencias hoy. Esta desviación en los datos se conoce como deriva.
Vertex AI Model Monitoring puede hacer un seguimiento de las desviaciones y enviarte alertas cuando superen un umbral especificado. Después, puedes volver a evaluar o entrenar el modelo para asegurarte de que se comporta como esperabas.
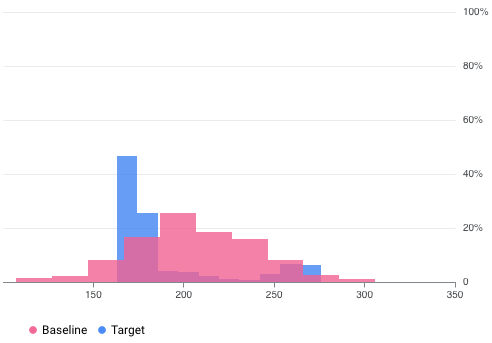
Por ejemplo, Vertex AI Model Monitoring puede proporcionar visualizaciones como la de la siguiente figura, que superpone dos gráficos de dos conjuntos de datos. Esta visualización te permite comparar rápidamente los dos conjuntos de datos y ver las desviaciones entre ellos.
Versiones de Vertex AI Model Monitoring
Vertex AI Model Monitoring ofrece dos versiones: v2 y v1.
La versión 2 de Monitorización de modelos está en vista previa y es la oferta más reciente que asocia todas las tareas de monitorización con una versión de un modelo. Por el contrario, la versión 1 de Model Monitoring está disponible para todos los usuarios y se configura en los endpoints de Vertex AI.
Si necesitas asistencia de nivel de producción y quieres monitorizar un modelo desplegado en un endpoint de Vertex AI, usa Model Monitoring v1. Para el resto de los casos prácticos, usa Model Monitoring v2, que ofrece todas las funciones de Model Monitoring v1 y más. Para obtener más información, consulta el resumen de cada versión:
Para los usuarios de Model Monitoring v1, esta versión se mantiene tal cual. No es necesario que migres a Model Monitoring v2. Si quieres migrar, puedes usar ambas versiones al mismo tiempo hasta que hayas completado la migración a Model Monitoring v2 para evitar que haya lagunas en la monitorización durante la transición.
Información general sobre la versión 2 de Monitorización de modelos
La versión 2 de Model Monitoring te permite hacer un seguimiento de las métricas a lo largo del tiempo después de configurar un monitor de modelos y ejecutar tareas de monitorización. Puedes ejecutar tareas de monitorización bajo demanda o programar ejecuciones. Si usas ejecuciones programadas, Model Monitoring ejecuta automáticamente tareas de monitorización según una programación que definas.
Objetivos de monitorización
Las métricas y los umbrales que monitorizas se asignan a objetivos de monitorización. En cada versión del modelo, puede especificar uno o varios objetivos de monitorización. En la tabla siguiente se detallan los objetivos:
| Objetivo | Descripción | Tipo de datos de la función | Métricas admitidas |
|---|---|---|---|
| Deriva de los datos de las funciones de entrada |
Mide la distribución de los valores de las características de entrada en comparación con una distribución de datos de referencia. |
Categórica: booleano, cadena, categórica |
|
| Numérico: float, integer | Divergencia de Jensen-Shannon | ||
| Deriva de los datos de inferencia de salida |
Mide la distribución de datos de las inferencias del modelo en comparación con una distribución de datos de referencia. |
Categórica: booleano, cadena, categórica |
|
| Numérico: float, integer | Divergencia de Jensen-Shannon | ||
| Atribución de funciones |
Mide el cambio en la contribución de las funciones a la inferencia de un modelo en comparación con un valor de referencia. Por ejemplo, puedes monitorizar si una función muy importante pierde importancia de repente. |
Todos los tipos de datos | Valor SHAP (explicaciones aditivas de Shapley) |
Deriva de las características de entrada y de las inferencias de salida
Una vez que se ha implementado un modelo en producción, los datos de entrada pueden desviarse de los datos que se usaron para entrenar el modelo, o bien la distribución de los datos de las características en producción puede cambiar significativamente con el tiempo. Model Monitoring v2 puede monitorizar los cambios en la distribución de los datos de producción en comparación con los datos de entrenamiento o hacer un seguimiento de la evolución de la distribución de los datos de producción a lo largo del tiempo.
Del mismo modo, en el caso de los datos de inferencia, Model Monitoring v2 puede monitorizar los cambios en la distribución de los resultados predichos en comparación con la distribución de los datos de entrenamiento o de producción a lo largo del tiempo.
Atribución de funciones
Las atribuciones de características indican cuánto ha contribuido cada característica de tu modelo a las inferencias de cada instancia. Las puntuaciones de atribución son proporcionales a la contribución de la característica a la inferencia de un modelo. Normalmente, se firman para indicar si una función ayuda a aumentar o reducir la inferencia. Las atribuciones de todas las funciones deben sumar la puntuación de inferencia del modelo.
Al monitorizar las atribuciones de las características, Model Monitoring v2 hace un seguimiento de los cambios en las contribuciones de una característica a las inferencias de un modelo a lo largo del tiempo. Un cambio en la puntuación de atribución de una función clave suele indicar que la función ha cambiado de forma que puede afectar a la precisión de las inferencias del modelo.
Para obtener más información sobre las atribuciones y las métricas de las funciones, consulte Explicaciones basadas en funciones y Método de Shapley muestreado.
Cómo configurar la monitorización de modelos (versión 2)
Primero debes registrar tus modelos en el registro de modelos de Vertex AI. Si sirves modelos fuera de Vertex AI, no es necesario que subas el artefacto del modelo. A continuación, crea un monitor de modelo, que asocias a una versión del modelo, y defines el esquema del modelo. En algunos modelos, como los de AutoML, el esquema se proporciona automáticamente.
En el monitor de modelos, puedes especificar de forma opcional configuraciones predeterminadas, como objetivos de monitorización, un conjunto de datos de entrenamiento, una ubicación de salida de monitorización y ajustes de notificaciones. Para obtener más información, consulta Configurar la monitorización de modelos.
Después de crear un monitor de modelo, puedes ejecutar un trabajo de monitorización bajo demanda o programar trabajos periódicos para monitorizar de forma continua. Cuando ejecutas un trabajo, Model Monitoring usa la configuración predeterminada definida en el monitor de modelos, a menos que proporciones otra configuración de monitorización. Por ejemplo, si proporcionas objetivos de monitorización diferentes o un conjunto de datos de comparación distinto, Monitorización de modelos usará las configuraciones del trabajo en lugar de la configuración predeterminada del monitor de modelos. Para obtener más información, consulta Ejecutar un trabajo de monitorización.
Precios
No se te cobrará por Model Monitoring v2 durante la vista previa. Seguirás pagando por el uso de otros servicios, como Cloud Storage, BigQuery, las inferencias por lotes de Vertex AI, Vertex Explainable AI y Cloud Logging.
Tutoriales de Notebook
En los siguientes tutoriales se muestra cómo usar el SDK de Vertex AI para Python para configurar la versión 2 de la monitorización de modelos en tu modelo.
Monitorización de modelos v2: tarea de inferencia por lotes de modelos personalizados
Monitorización de modelos v2: inferencia online de modelos personalizados
Model Monitoring v2: modelos fuera de Vertex AI
Descripción general de Model Monitoring v1
Para ayudarte a mantener el rendimiento de un modelo, Model Monitoring v1 monitoriza los datos de entrada de inferencia del modelo para detectar sesgos y derivas de las características:
La desviación entre el entrenamiento y el servicio se produce cuando la distribución de los datos de las funciones en producción se desvía de la distribución de los datos de las funciones que se han usado para entrenar el modelo. Si los datos de entrenamiento originales están disponibles, puedes habilitar la detección de sesgos para monitorizar los sesgos entre el entrenamiento y el servicio de tus modelos.
La desviación de la inferencia se produce cuando la distribución de los datos de las características en producción cambia significativamente con el tiempo. Si los datos de entrenamiento originales no están disponibles, puedes habilitar la detección de deriva para monitorizar los datos de entrada y detectar cambios a lo largo del tiempo.
Puedes habilitar la detección de inclinación y de deriva.
Model Monitoring v1 admite la detección de sesgo y deriva de características categóricas y numéricas:
Las funciones categóricas son datos limitados por el número de valores posibles, que suelen agruparse por propiedades cualitativas. Por ejemplo, categorías como tipo de producto, país o tipo de cliente.
Las funciones numéricas son datos que pueden ser cualquier valor numérico. Por ejemplo, el peso y la altura.
Cuando la desviación o el desfase de una característica de un modelo supera un umbral de alerta que has definido, Model Monitoring v1 te envía una alerta por correo electrónico. También puedes ver las distribuciones de cada función a lo largo del tiempo para evaluar si necesitas volver a entrenar tu modelo.
Calcular la deriva
Para detectar la deriva en la versión 1, Vertex AI Model Monitoring usa TensorFlow Data Validation (TFDV) para calcular las distribuciones y las puntuaciones de distancia.
Calcula la distribución estadística de la línea de base:
Para detectar sesgos, la base es la distribución estadística de los valores de la función en los datos de entrenamiento.
Para la detección de la deriva, la base es la distribución estadística de los valores de la función que se han observado en producción en el pasado.
Las distribuciones de las características categóricas y numéricas se calculan de la siguiente manera:
En el caso de las funciones categóricas, la distribución calculada es el número o el porcentaje de instancias de cada valor posible de la función.
En el caso de las características numéricas, Vertex AI Model Monitoring divide el intervalo de valores de características posibles en intervalos iguales y calcula el número o el porcentaje de valores de características que se incluyen en cada intervalo.
La línea de base se calcula cuando crea una tarea de Vertex AI Model Monitoring y solo se vuelve a calcular si actualiza el conjunto de datos de entrenamiento de la tarea.
Calcula la distribución estadística de los valores de las funciones más recientes que se han visto en producción.
Compara la distribución de los valores de la función más reciente en producción con la distribución de referencia calculando una puntuación de distancia:
En el caso de las características categóricas, la puntuación de distancia se calcula mediante la distancia L-infinito.
En el caso de las características numéricas, la puntuación de distancia se calcula mediante la divergencia de Jensen-Shannon.
Cuando la puntuación de distancia entre dos distribuciones estadísticas supera el umbral que especifiques, Vertex AI Model Monitoring identificará la anomalía como sesgo o deriva.
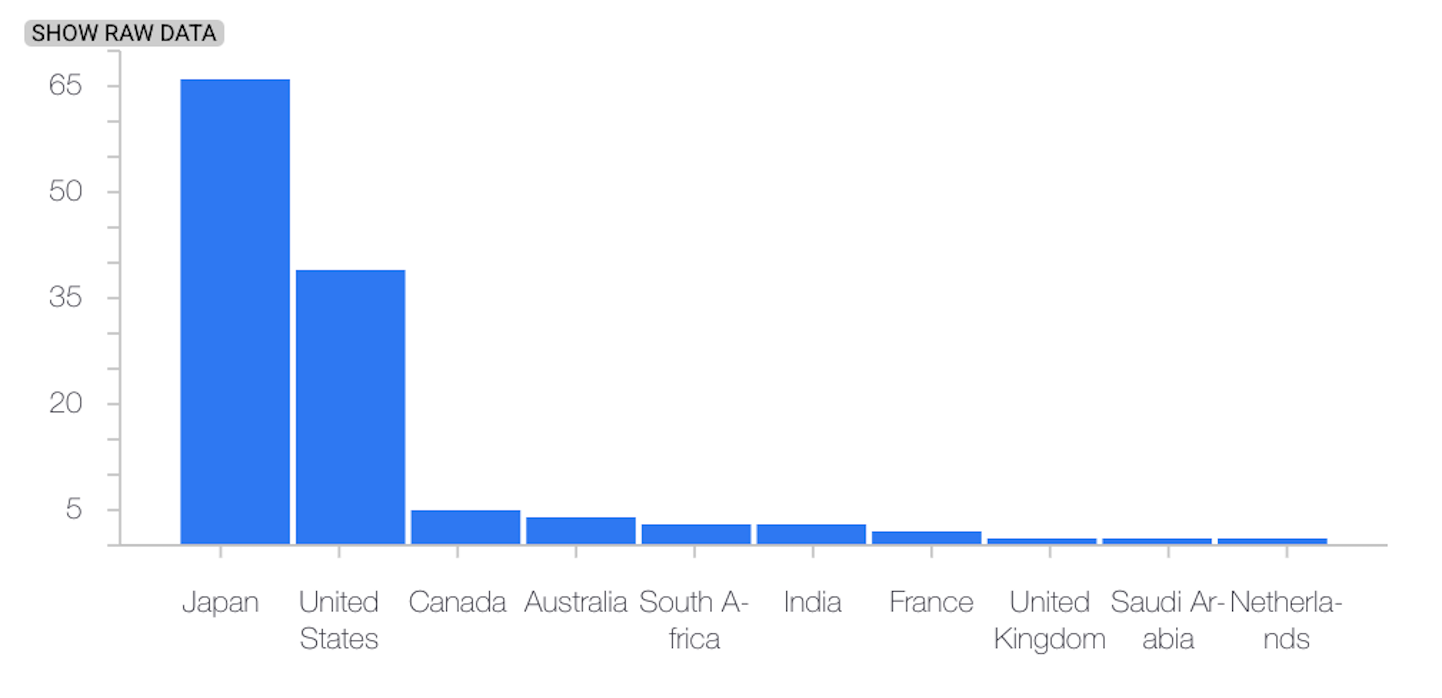
En el siguiente ejemplo se muestra la desviación entre las distribuciones de referencia y las más recientes de una función categórica:
Distribución de referencia
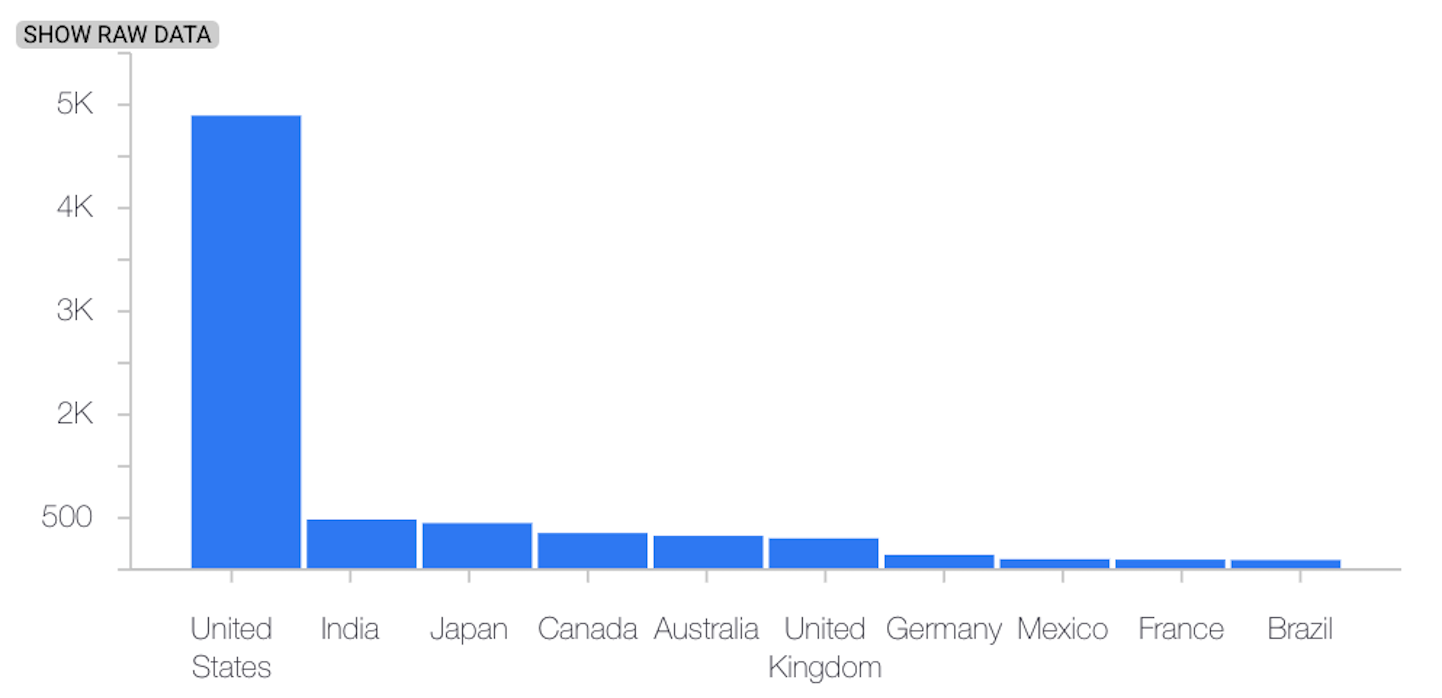
Última distribución
En el siguiente ejemplo se muestra la desviación o el desfase entre las distribuciones de referencia y las más recientes de una característica numérica:
Distribución de referencia
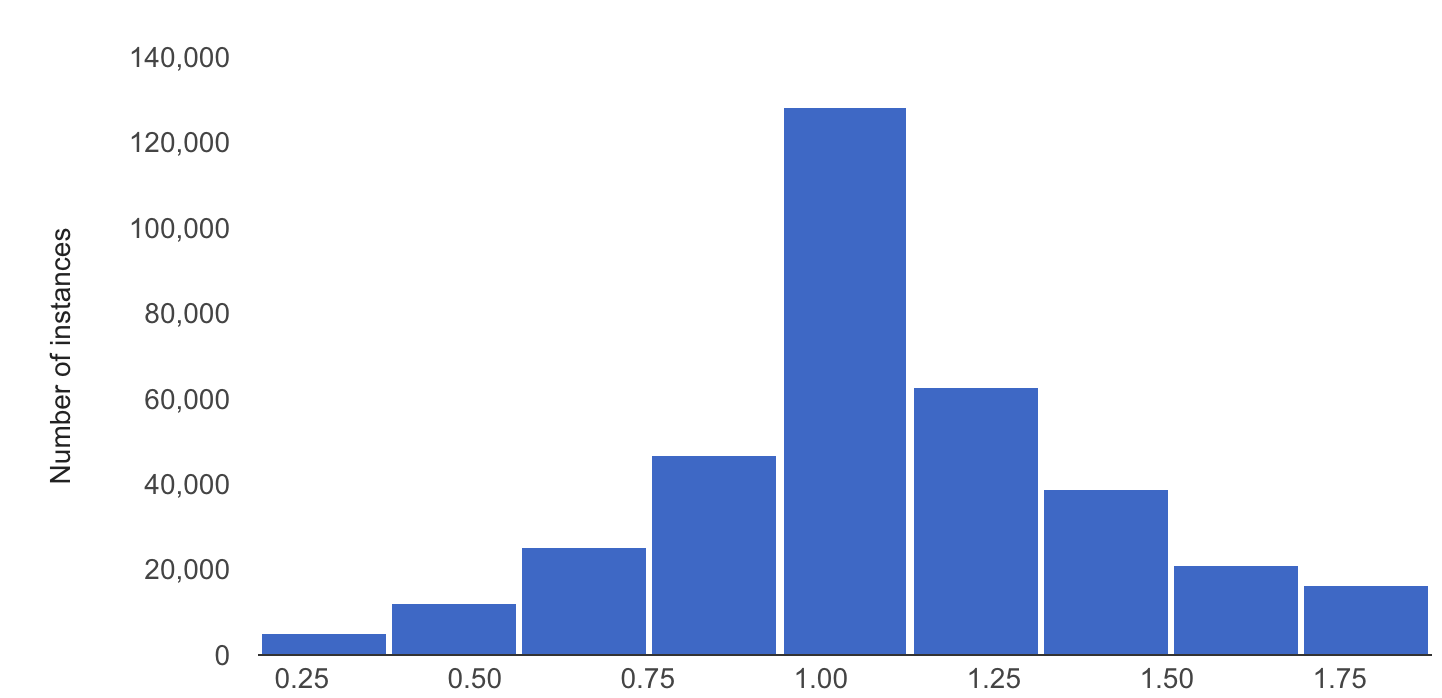
Última distribución
Consideraciones al usar Model Monitoring
Para optimizar los costes, puedes definir una frecuencia de muestreo de solicitudes de inferencia para monitorizar un subconjunto de las entradas de producción de un modelo.
Puede definir la frecuencia con la que se monitorizan las entradas registradas recientemente de un modelo implementado para detectar sesgos o desviaciones. La frecuencia de monitorización determina el intervalo o el tamaño de la ventana de monitorización de los datos registrados que se analizan en cada ejecución de la monitorización.
Puede especificar umbrales de alerta para cada función que quiera monitorizar. Se registra una alerta cuando la distancia estadística entre la distribución de la característica de entrada y su valor de referencia correspondiente supera el umbral especificado. De forma predeterminada, se monitorizan todas las funciones categóricas y numéricas, con valores de umbral de 0,3.
Un endpoint de inferencia online puede alojar varios modelos. Cuando habilitas la detección de sesgos o desviaciones en un endpoint, los siguientes parámetros de configuración se comparten entre todos los modelos alojados en ese endpoint:
- Tipo de detección
- Frecuencia de monitorización
- Fracción de solicitudes de entrada monitorizadas
En el caso de los demás parámetros de configuración, puede definir valores diferentes para cada modelo.
Siguientes pasos
- Empezar a usar la versión 2 de Monitorización de modelos
- Proporcionar un esquema a Model Monitoring v1