本頁面說明如何搭配使用 Vertex AI Model Monitoring 和 Vertex Explainable AI,偵測類別和數值輸入特徵的特徵歸因偏差和偏移。
根據特徵歸因進行監控總覽
特徵歸因會指出模型中的各項特徵對每個指定執行個體預測結果的影響程度。提出預測要求時,系統會根據模型提供適當的預測值。要求說明時,您會收到預測結果和特徵歸因資訊。
歸因分數與特徵對模型預測結果的貢獻度成正比。這些值通常會加上正負號,表示某項特徵是否會提高或降低預測值。所有特徵的歸因加總必須等於模型的預測分數。
透過監控特徵歸因,模型監控功能會追蹤特徵對模型預測結果的貢獻度隨時間的變化。如果重要特徵的歸因分數有變,通常表示該特徵已發生變化,可能會影響模型預測的準確度。
如要瞭解如何計算特徵歸因分數,請參閱「特徵歸因方法」。
特徵歸因訓練/服務偏差和預測偏移
為啟用 Vertex Explainable AI 的模型建立監控工作時,Model Monitoring 會監控特徵分布和特徵歸因的偏差或偏移情形。如要瞭解特徵分布偏差和偏移情形,請參閱「Vertex AI Model Monitoring 簡介」。
特徵歸因:
訓練/應用偏差是指特徵在正式環境中的歸因分數,與原始訓練資料中的歸因分數不同。
如果正式環境中特徵的歸因分數隨時間大幅變動,就會發生預測偏移。
如果您提供模型的原始訓練資料集,可以啟用偏差偵測功能;否則,請啟用偏移偵測功能。您也可以同時啟用偏差和偏移偵測功能。
必要條件
如要搭配使用模型監控與 Vertex Explainable AI,請完成下列步驟:
如要啟用偏斜偵測功能,請將訓練資料或批次說明工作的輸出內容上傳至 Cloud Storage 或 BigQuery。取得資料的 URI 連結。如要偵測偏移,不需要訓練資料或說明基準。
在 Vertex AI 中提供可用的模型,該模型必須是表格 AutoML 或匯入的表格自訂訓練類型:
AutoML 表格模型會自動設定 Vertex Explainable AI,因此您可以直接啟用偏斜或漂移偵測。注意: 僅支援分類和迴歸模型。
匯入自訂訓練模型時,您必須在建立、匯入或部署模型時,設定 Vertex Explainable AI。
建立、匯入或部署模型時,設定模型使用 Vertex Explainable AI。模型的
ExplanationSpec.ExplanationParameters欄位必須填入資料。選用:如果是自訂訓練模型,請將模型的分析執行個體結構定義上傳至 Cloud Storage。 模型監控需要結構定義才能開始監控程序,並計算偏差偵測的基準分布。如果在建立工作時未提供結構定義,工作會處於待處理狀態,直到模型監控功能從模型收到的前 1000 個預測要求中,自動剖析結構定義為止。
啟用偏差或漂移偵測功能
如要設定偏差偵測或偏移偵測,請建立模型部署監控工作:
控制台
如要使用Google Cloud 控制台建立模型部署監控工作,請建立端點:
前往 Google Cloud 控制台的「Vertex AI Endpoints」頁面。
按一下「建立端點」。
在「New endpoint」(新增端點) 窗格中,為端點命名並設定區域。
按一下「繼續」。
在「模型名稱」欄位中,選取匯入的自訂訓練或表格 AutoML 模型。
在「版本」欄位中,選取模型版本。
按一下「繼續」。
在「模型監控」窗格中,確認已開啟「為這個端點啟用模型監控功能」。您設定的任何監控設定,都會套用至部署到端點的所有模型。
輸入監控工作顯示名稱。
輸入「監控期間長度」。
在「通知電子郵件」部分,輸入一或多個以半形逗號分隔的電子郵件地址,以便在模型超過快訊門檻時收到通知。
(選用) 在「通知管道」中,選取「Cloud Monitoring」管道,以便在模型超出快訊門檻時接收快訊。您可以選取現有的 Cloud Monitoring 管道,也可以按一下「管理通知管道」建立新管道。主控台支援 PagerDuty、Slack 和 Pub/Sub 通知管道。
輸入「取樣率」。
選用:輸入「預測輸入結構定義」和「分析輸入結構定義」。
按一下「繼續」。「監控目標」窗格隨即開啟,並顯示偏差或偏移偵測選項:
偏斜偵測
- 選取「訓練/應用偏差偵測」。
- 在「訓練資料來源」下方,提供訓練資料來源。
- 在「目標資料欄」下方,輸入訓練資料中的資料欄名稱,訓練後的模型會預測這些訓練資料。監控分析會排除這個欄位。
- 選用:在「警告門檻」下方,指定觸發警告的門檻。如要瞭解如何設定門檻格式,請將指標懸停在「說明」圖示上。
- 點選「建立」。
偏移偵測
- 選取「預測偏移偵測」。
- 選用:在「警告門檻」下方,指定觸發警告的門檻。如要瞭解如何設定門檻格式,請將指標懸停在「說明」圖示上。
- 點選「建立」。
gcloud
如要使用 gcloud CLI 建立模型部署監控工作,請先將模型部署至端點。
監控工作設定適用於端點下的所有已部署模型。
執行 gcloud ai model-monitoring-jobs create 指令:
gcloud ai model-monitoring-jobs create \ --project=PROJECT_ID \ --region=REGION \ --display-name=MONITORING_JOB_NAME \ --emails=EMAIL_ADDRESS_1,EMAIL_ADDRESS_2 \ --endpoint=ENDPOINT_ID \ --feature-thresholds=FEATURE_1=THRESHOLD_1,FEATURE_2=THRESHOLD_2 \ --prediction-sampling-rate=SAMPLING_RATE \ --monitoring-frequency=MONITORING_FREQUENCY \ --target-field=TARGET_FIELD \ --bigquery-uri=BIGQUERY_URI
其中:
PROJECT_ID 是 Google Cloud 專案 ID。例如:
my-project。REGION 是監控工作的位置。例如:
us-central1。MONITORING_JOB_NAME 是監控工作的名稱。例如:
my-job。EMAIL_ADDRESS 是您要接收模型監控快訊的電子郵件地址。例如:
example@example.com。ENDPOINT_ID 是部署模型的端點 ID。例如:
1234567890987654321。選用:FEATURE_1=THRESHOLD_1 是要監控的每項特徵的快訊門檻。舉例來說,如果您指定
Age=0.4,當Age特徵的輸入和基準分布之間的 [統計距離][stat-distance] 超過 0.4 時,模型監控就會記錄快訊。選用:SAMPLING_RATE 是您要記錄的預測要求分數。例如,
0.5。如未指定,模型監控功能會記錄所有預測要求。選用:MONITORING_FREQUENCY 是您希望監控工作在最近記錄的輸入內容上執行的頻率。最小時間間隔為 1 小時。預設值為 24 小時。例如:
2。(僅限偏差偵測) TARGET_FIELD 是模型預測的欄位。這個欄位不會納入監控分析。例如:
housing-price。(僅限偏差偵測) BIGQUERY_URI 是儲存在 BigQuery 中的訓練資料集連結,格式如下:
bq://\PROJECT.\DATASET.\TABLE
例如
bq://\my-project.\housing-data.\san-francisco。您可以將
bigquery-uri標記替換為訓練資料集的替代連結:如要使用儲存在 Cloud Storage bucket 中的 CSV 檔案,請使用
--data-format=csv --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME。如要使用儲存在 Cloud Storage bucket 中的 TFRecord 檔案,請使用
--data-format=tf-record --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME。如為 [表格 AutoML 代管資料集][dataset-id],請使用
--dataset=DATASET_ID。
Python SDK
如要瞭解完整的端對端模型監控 API 工作流程,請參閱範例筆記本。
REST API
如果尚未部署模型,請將模型部署至端點。
如要擷取模型的已部署模型 ID,請取得端點資訊。請注意 DEPLOYED_MODEL_ID,這是回應中的
deployedModels.id值。建立模型監控工作要求。以下操作說明將示範如何建立基本監控工作,以偵測屬性偏移。如要偵測傾斜,請將
explanationBaseline物件新增至要求 JSON 主體中的explanationConfig欄位,並提供下列其中一項:訓練資料集的批次說明工作輸出內容。
服務會在
TrainingDataset上執行BatchExplain工作,產生基準。
詳情請參閱「監控工作參考資料」。
使用任何要求資料之前,請先替換以下項目:
- PROJECT_ID:是您的 Google Cloud 專案 ID。例如:
my-project。 - LOCATION:是監控工作的地點。例如:
us-central1。 - MONITORING_JOB_NAME:是監控作業的名稱。例如:
my-job。 - PROJECT_NUMBER:是 Google Cloud 專案的編號。例如:
1234567890。 - ENDPOINT_ID 是模型部署到的端點 ID。例如:
1234567890。 - DEPLOYED_MODEL_ID:是已部署模型的 ID。
- FEATURE:VALUE 是要監控的各項功能的警示門檻。例如:
"housing-latitude": {"value": 0.4}。當輸入特徵分布情形與相應基準之間的統計距離超過指定門檻時,系統就會記錄快訊。根據預設,系統會監控每個類別和數值特徵,門檻值為 0.3。 - EMAIL_ADDRESS:您要用來接收模型監控快訊的電子郵件地址。例如:
example@example.com。 - NOTIFICATION_CHANNELS:
您要接收模型監控快訊的Cloud Monitoring 通知管道清單。使用通知管道的資源名稱,您可以列出專案中的通知管道來擷取這些名稱。例如:
"projects/my-project/notificationChannels/1355376463305411567", "projects/my-project/notificationChannels/1355376463305411568"。
JSON 要求主體:
{ "displayName":"MONITORING_JOB_NAME", "endpoint":"projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID", "modelDeploymentMonitoringObjectiveConfigs": { "deployedModelId": "DEPLOYED_MODEL_ID", "objectiveConfig": { "predictionDriftDetectionConfig": { "driftThresholds": { "FEATURE_1": { "value": VALUE_1 }, "FEATURE_2": { "value": VALUE_2 } } }, "explanationConfig": { "enableFeatureAttributes": true } } }, "loggingSamplingStrategy": { "randomSampleConfig": { "sampleRate": 0.5, }, }, "modelDeploymentMonitoringScheduleConfig": { "monitorInterval": { "seconds": 3600, }, }, "modelMonitoringAlertConfig": { "emailAlertConfig": { "userEmails": ["EMAIL_ADDRESS"], }, "notificationChannels": [NOTIFICATION_CHANNELS] } }如要傳送要求,請展開以下其中一個選項:
您應該會收到如下的 JSON 回應:
{ "name": "projects/PROJECT_NUMBER/locations/LOCATION/modelDeploymentMonitoringJobs/MONITORING_JOB_NUMBER", ... "state": "JOB_STATE_PENDING", "scheduleState": "OFFLINE", ... "bigqueryTables": [ { "logSource": "SERVING", "logType": "PREDICT", "bigqueryTablePath": "bq://PROJECT_ID.model_deployment_monitoring_8451189418714202112.serving_predict" } ], ... }
建立監控工作後,模型監控功能會將傳入的預測要求記錄到名為 PROJECT_ID.model_deployment_monitoring_ENDPOINT_ID.serving_predict 的 BigQuery 資料表中。如果啟用要求/回應記錄,模型監控功能會將傳入的要求記錄到用於要求/回應記錄的同一個 BigQuery 資料表。
如要瞭解如何執行下列選用工作,請參閱「使用模型監控」:
更新模型監控工作。
設定模型監控工作的快訊
設定異常狀況快訊。
分析特徵歸因偏移與偏差資料
您可以使用 Google Cloud 控制台,以視覺化方式呈現每個監控特徵的特徵歸因,並瞭解哪些變更導致偏移或偏差。如要瞭解如何分析特徵分布資料,請參閱「分析偏斜和漂移資料」。
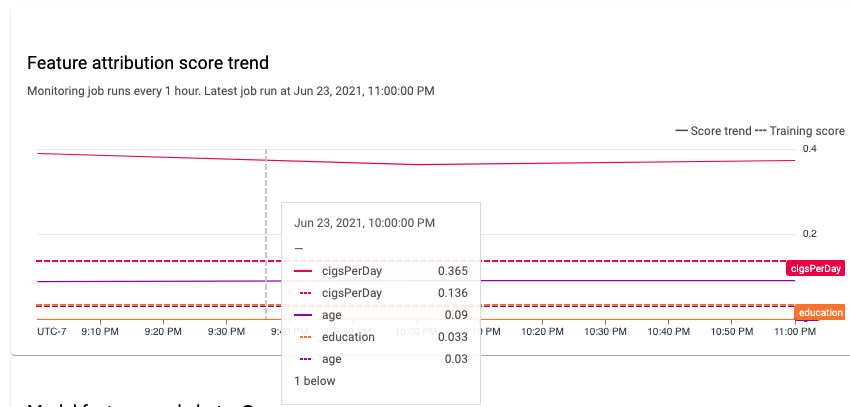
在穩定的機器學習系統中,特徵的相對重要性通常會隨著時間保持相對穩定。如果重要特徵的重要性降低,可能表示該特徵的某些方面發生變化。特徵重要性漂移或偏斜的常見原因包括:
- 資料來源變更。
- 資料結構定義和記錄變更。
- 使用者組合或行為發生變化 (例如季節性變化或離群事件)。
- 由其他機器學習模型產生的特徵上游變更。
舉例如下:
- 模型更新導致涵蓋範圍增加或減少 (整體或個別分類值)。
- 模型效能有所變化 (這會改變功能的意義)。
- 資料管道更新,可能導致整體涵蓋範圍縮減。
此外,分析特徵歸因偏移與偏差資料時,請注意下列事項:
追蹤最重要的功能。如果特徵的歸因有大幅變動,表示該特徵對預測結果的影響力已改變。由於預測分數等於特徵貢獻的總和,因此最重要特徵的歸因值大幅偏移,通常表示模型預測值大幅偏移。
監控所有特徵表示法。無論基礎特徵類型為何,特徵出處一律為數值。由於嵌入等多元特徵的歸因具有加總性質,因此只要加總各維度的歸因,即可將這類歸因縮減為單一數值。這樣一來,您就能對所有特徵類型使用標準單變數偏移偵測方法。
考量功能互動。特徵歸因會考量特徵對預測結果的影響,包括單獨影響以及與其他特徵互動時的影響。如果某項功能與其他功能的互動方式改變,即使該功能的邊際分配維持不變,歸因分配也會隨之改變。
監控特徵群組。由於屬性是累加的,因此您可以將屬性加到相關功能,取得功能群組的屬性。舉例來說,在信用貸款模式中,將與貸款類型相關的所有特徵 (例如「等級」、「子等級」、「用途」) 歸因合併,即可取得單一貸款歸因。接著,您就能追蹤這項群組層級的歸因,監控特徵群組的變化。
後續步驟
- 請參閱 API 說明文件,瞭解如何使用模型監控功能。
- 請按照 gcloud CLI 文件操作,使用模型監控功能。
- 請在 Colab 中試用範例筆記本,或在 GitHub 上查看。
- 瞭解模型監控功能如何計算訓練/應用偏差和預測偏移。