本页面介绍了如何配置批量推理作业请求以包含一次性 Model Monitoring 分析。对于批量推理,Model Monitoring 支持分类和数值输入特征的特征偏差检测。
如需使用 Model Monitoring 偏差分析创建批量推理作业,您必须在请求中同时包含模型的批量推理输入数据和原始训练数据。您只能在创建新的批量推理作业时添加 Model Monitoring 分析。
如需详细了解偏差,请参阅 Model Monitoring 简介。
如需了解如何为在线(实时)推理设置 Model Monitoring,请参阅使用 Model Monitoring。
前提条件
如需将 Model Monitoring 与批量推理搭配使用,请完成以下操作:
在 Vertex AI Model Registry 中准备好可用的模型,可以是表格 AutoML 或表格自定义训练类型。
将您的训练数据上传到 Cloud Storage 或 BigQuery,并获取数据的 URI 链接。
- 对于使用 AutoML 训练的模型,您可以使用训练数据集的数据集 ID。
Model Monitoring 会将训练数据与批量推理输出进行比较。请确保为训练数据和批量推理输出使用受支持的文件格式:
模型类型 训练数据 批量推理输出 自定义训练 CSV、JSONL、BigQuery、TfRecord(tf.train.Example) JSONL AutoML 表格 CSV、JSONL、BigQuery、TfRecord(tf.train.Example) CSV、JSONL、BigQuery、TfRecord(Protobuf.Value) 可选:对于自定义训练模型,请将模型的架构上传到 Cloud Storage。模型监控要求架构计算基准分布以进行偏差检测。
请求批量推理
您可以使用以下方法将 Model Monitoring 配置添加到批量推理作业:
控制台
按照相关说明在启用 Model Monitoring 的情况下发出批量推理请求:
REST API
按照相关说明使用 REST API 发出批量推理请求:
创建批量推理请求时,请将以下模型监控配置添加到请求 JSON 正文:
"modelMonitoringConfig": {
"alertConfig": {
"emailAlertConfig": {
"userEmails": "EMAIL_ADDRESS"
},
"notificationChannels": [NOTIFICATION_CHANNELS]
},
"objectiveConfigs": [
{
"trainingDataset": {
"dataFormat": "csv",
"gcsSource": {
"uris": [
"TRAINING_DATASET"
]
}
},
"trainingPredictionSkewDetectionConfig": {
"skewThresholds": {
"FEATURE_1": {
"value": VALUE_1
},
"FEATURE_2": {
"value": VALUE_2
}
}
}
}
]
}
其中:
EMAIL_ADDRESS 是您用于接收 Model Monitoring 提醒的电子邮件地址。例如
example@example.com。NOTIFICATION_CHANNELS:您要在其中接收模型监控提醒的 Cloud Monitoring 通知渠道列表。使用通知渠道的资源名称,您可以通过列出项目中的通知渠道进行检索。例如
"projects/my-project/notificationChannels/1355376463305411567", "projects/my-project/notificationChannels/1355376463305411568"。TRAINING_DATASET 是存储在 Cloud Storage 中的训练数据集的链接。
- 如需使用 BigQuery 训练数据集的链接,请将
gcsSource字段替换为以下内容:
"bigquerySource": { { "inputUri": "TRAINING_DATASET" } }- 如需使用 AutoML 模型的链接,请将
gcsSource字段替换为以下内容:
"dataset": "TRAINING_DATASET"
- 如需使用 BigQuery 训练数据集的链接,请将
FEATURE_1:VALUE_1 和 FEATURE_2:VALUE_2 是您要监控的每个特征的提醒阈值。例如,如果您指定
Age=0.4,当Age特征的输入分布和基准分布之间的统计距离超过 0.4 时,Model Monitoring 会记录提醒。默认情况下,每个分类和数值特征都会受监控,并且阈值为 0.3。
如需详细了解 Model Monitoring 配置,请参阅 Monitoring 作业参考。
Python
如需使用 Model Monitoring 针对自定义表格模型运行批量推理作业,请参阅示例笔记本。
Model Monitoring 会自动通过电子邮件通知您作业更新和提醒。
访问偏差指标
您可以使用以下方法访问批量推理作业的偏差指标:
控制台(直方图)
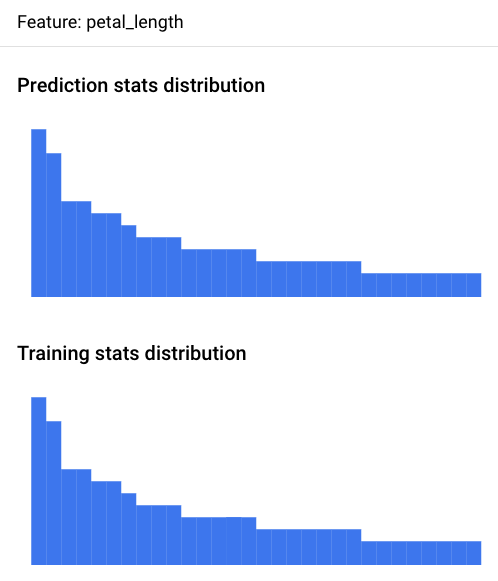
使用 Google Cloud 控制台查看每个受监控特征的特征分布直方图,并了解哪些更改随时间变化会导致偏差:
前往批量预测页面:
在批量预测页面上,点击要分析的批量推理作业。
点击 Model Monitoring 提醒标签页以查看模型的输入特征列表以及相关信息(例如每个特征的提醒阈值)。
如需分析特征,请点击特征的名称。此时会显示一个页面,其中显示该特征的特征分布直方图。
通过以直方图的形式直观呈现数据分布,您可以快速关注数据中发生的变化。之后,您可以决定调整特征生成流水线或重新训练模型。
控制台(JSON 文件)
使用 Google Cloud 控制台以 JSON 格式访问指标:
前往批量预测页面:
点击相应批量推理监控作业的名称。
点击 Monitoring 属性标签页。
点击 Monitoring 输出目录链接,这会将您转到 Cloud Storage 存储桶。
点击
metrics/文件夹。点击
skew/文件夹。点击
feature_skew.json文件,即可进入对象详细信息页面。使用以下任一选项打开 JSON 文件:
点击下载,然后在本地文本编辑器中打开该文件。
使用 gsutil URI 路径在 Cloud Shell 或本地终端中运行
gcloud storage cat gsutil_URI。
feature_skew.json 文件包含一个字典,其中键是特征名称,值是特征偏差。例如:
{
"cnt_ad_reward": 0.670936,
"cnt_challenge_a_friend": 0.737924,
"cnt_completed_5_levels": 0.549467,
"month": 0.293332,
"operating_system": 0.05758,
"user_pseudo_id": 0.1
}
Python
如需在使用 Model Monitoring 运行批量推理作业后访问自定义表格模型的偏差指标,请参阅示例笔记本
调试批量推理监控失败
如果批量推理监控作业失败,您可以在 Google Cloud 控制台中找到调试日志:
前往批量预测页面。
点击失败的批量推理监控作业的名称。
点击 Monitoring 属性标签页。
点击 Monitoring 输出目录链接,这会将您转到 Cloud Storage 存储桶。
点击
logs/文件夹。点击任一
.INFO文件,即可前往对象详细信息页面。使用以下任一选项打开日志文件:
点击下载,然后在本地文本编辑器中打开该文件。
使用 gsutil URI 路径在 Cloud Shell 或本地终端中运行
gcloud storage cat gsutil_URI。
笔记本教程
详细了解如何使用 Vertex AI Model Monitoring 通过这些端到端教程获取模型的可视化内容和统计信息。
AutoML
- 适用于 AutoML 表格模型的 Vertex AI Model Monitoring
- 适用于 AutoML 图片模型中的批量预测的 Vertex AI Model Monitoring
- 适用于 AutoML 图片模型中的在线预测的 Vertex AI Model Monitoring
自定义
- 适用于自定义表格模型的 Vertex AI Model Monitoring
- 适用于具有 TensorFlow Serving 容器的自定义表格模型的 Vertex AI Model Monitoring
XGBoost 模型
Vertex Explainable AI 特征归因
批量推理
表格模型的设置
后续步骤
- 了解如何使用 Model Monitoring。
- 了解 Model Monitoring 如何计算训练-应用偏差和推理偏移。