Vertex ML Metadata는 리소스를 계층적으로 구성하며 모든 리소스는 MetadataStore에 속합니다. 메타데이터 리소스를 만들려면 먼저 MetadataStore가 있어야 합니다.
Vertex ML Metadata 용어
다음에서는 Vertex ML Metadata 리소스와 구성요소를 설명하는 데 사용되는 데이터 모델 및 용어를 소개합니다.
MetadataStore
- MetadataStore는 메타데이터 리소스의 최상위 컨테이너입니다. MetadataStore는 리전화되며 특정 Google Cloud 프로젝트와 연결됩니다. 일반적으로 조직은 각 프로젝트 내의 메타데이터 리소스에 공유 MetadataStore 하나를 사용합니다.
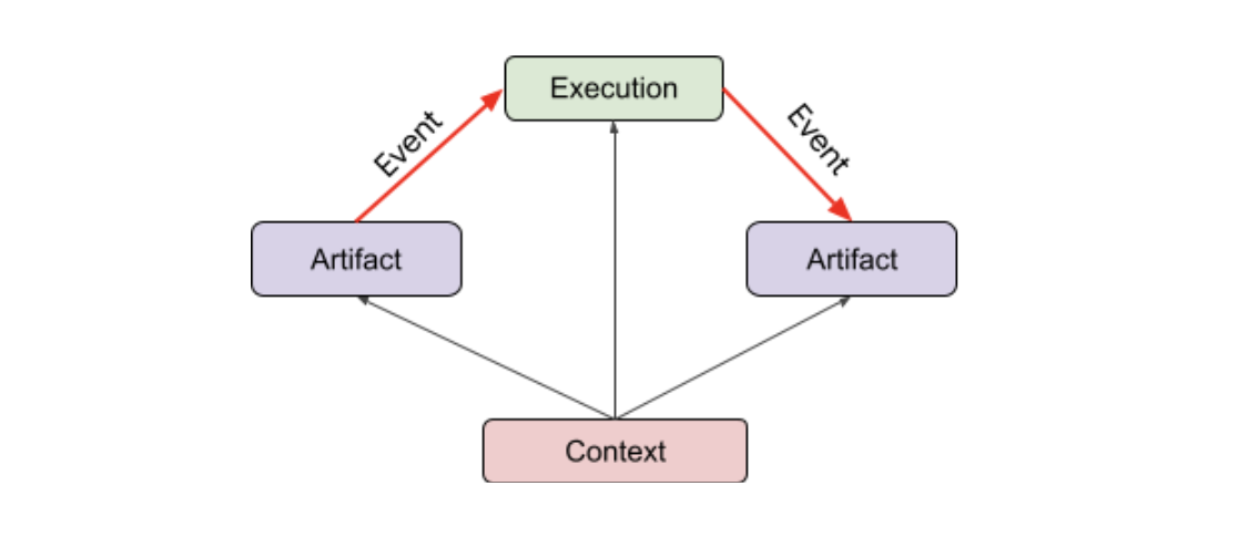
아티팩트
- 아티팩트는 머신러닝 워크플로에 의해 만들어지고 사용되는 개별 항목 또는 데이터입니다. 아티팩트의 예로는 데이터 세트, 모델, 입력 파일, 학습 로그가 포함됩니다.
context
- 컨텍스트는 쿼리가 가능하며 입력된 카테고리 하나에서 아티팩트와 실행을 그룹화하는 데 사용됩니다. 컨텍스트는 메타데이터 집합을 나타내는 데 사용될 수 있습니다. 컨텍스트의 예시로는 머신러닝 파이프라인 실행이 있습니다.
Vertex AI 파이프라인에서 파이프라인 실행. 이 경우 컨텍스트는 실행 하나를 나타내며 각 실행은 ML 파이프라인의 단계를 나타냅니다.
노트북에서 실행된 실험입니다. 이 경우 컨텍스트는 노트북을 나타내며 각 실행은 해당 노트북의 셀을 나타낼 수 있습니다.
이벤트
- 이벤트는 아티팩트와 실행 간의 관계를 설명합니다. 각 아티팩트는 실행 하나로 생성될 수 있으며 다른 실행에서 아티팩트를 사용할 수 있습니다. 이벤트는 아티팩트와 실행을 연결하여 ML 워크플로에서 아티팩트 출처를 확인하는 데 도움이 됩니다.
실행
- 실행은 일반적으로 런타임 매개변수로 주석이 추가된 개별 머신러닝 워크플로 단계를 기록한 것입니다. 실행의 예로는 데이터 수집, 데이터 검증, 모델 학습, 모델 평가, 모델 배포가 포함됩니다.
MetadataSchema
- MetadataSchema는 특정 유형의 아티팩트, 실행 또는 컨텍스트의 스키마를 설명합니다. MetadataSchema는 해당 메타데이터 리소스를 만드는 동안 키-값 쌍의 유효성을 검사하는 데 사용됩니다. 스키마 유효성 검사는 리소스와 MetadataSchema 간에 일치하는 필드에서만 수행됩니다. 유형 스키마는 YAML을 사용하여 설명해야 하는 OpenAPI 스키마 객체를 통해 표현됩니다.
MetadataSchema 예시
유형 스키마는 YAML을 사용하여 설명해야 하는 OpenAPI 스키마 객체를 통해 표현됩니다.
다음은 사전 정의된 Model 시스템 유형을 YAML 형식으로 지정하는 방법의 예시입니다.
title: system.Model
type: object
properties:
framework:
type: string
description: "The framework type, for example 'TensorFlow' or 'Scikit-Learn'."
framework_version:
type: string
description: "The framework version, for example '1.15' or '2.1'"
payload_format:
type: string
description: "The format of the Model payload, for example 'SavedModel' or 'TFLite'"
스키마의 제목은 <namespace>.<type name> 형식을 사용해야 합니다.
Vertex ML Metadata는 ML 워크플로에서 널리 사용되는 일반적인 유형을 나타내기 위한 시스템 정의 스키마를 게시하고 유지관리합니다. 이러한 스키마는 system 네임스페이스에 위치하며 API의 MetadataSchema 리소스로 액세스할 수 있습니다. 스키마는 항상 버전이 지정됩니다.
스키마에 대한 자세한 내용은 시스템 스키마를 참조하세요. 또한 Vertex ML Metadata를 사용하면 사용자 정의 커스텀 스키마를 만들 수 있습니다. 시스템 스키마에 대한 자세한 내용은 자체 커스텀 스키마를 등록하는 방법을 참조하세요.
노출된 메타데이터 리소스는 ML 메타데이터(MLMD)의 오픈소스 구현을 밀접하게 미러링합니다.