Vertex ML Metadata organizza le risorse in modo gerarchico, dove ogni risorsa appartiene a un MetadataStore. Prima di poter creare risorse di metadati, devi disporre di un MetadataStore.
Terminologia di Vertex ML Metadata
Di seguito vengono presentati il modello dei dati e la terminologia utilizzati per descrivere le risorse e i componenti di Vertex ML Metadata.
MetadataStore
- Un MetadataStore è il container di primo livello per le risorse di metadati. Metadata Store è regionalizzato e associato a un progetto Google Cloud specifico. In genere, un'organizzazione utilizza un MetadataStore condiviso per le risorse di metadati all'interno di ogni progetto.
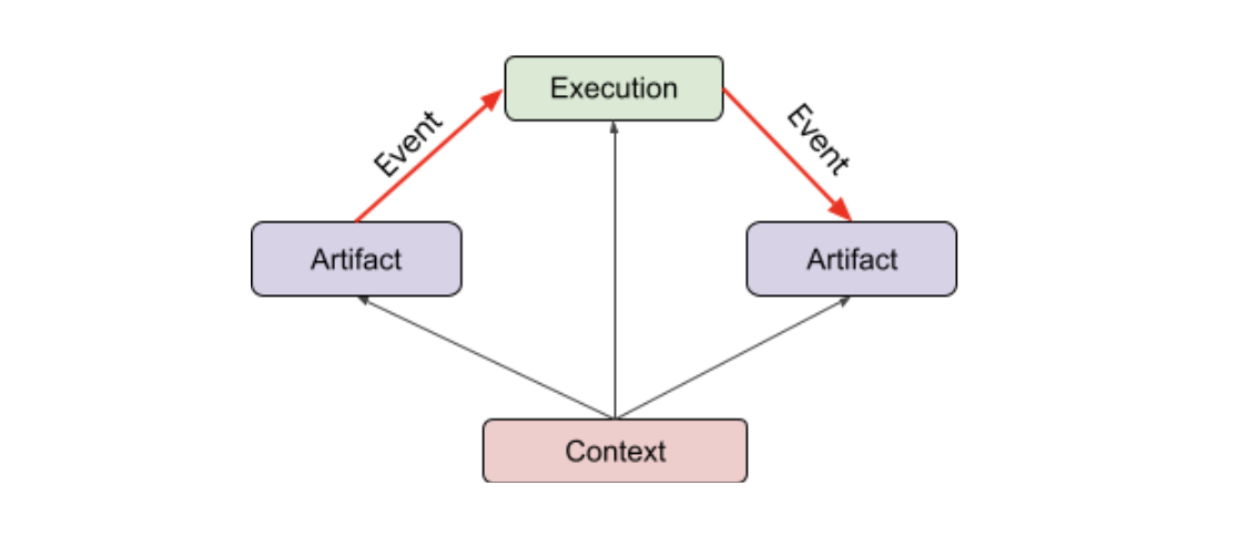
artifact
- Un artefatto è un'entità discreta o un insieme di dati prodotti e utilizzati da un flusso di lavoro di machine learning. Esempi di artefatti includono set di dati, modelli, file di input e log di addestramento.
context
- Un contesto viene utilizzato per raggruppare artefatti ed esecuzioni in una singola categoria interrogabile e digitata. I contesti possono essere utilizzati per rappresentare insiemi di metadati. Un esempio di contesto è l'esecuzione di una pipeline di machine learning.
Un'esecuzione della pipeline Vertex AI Pipelines. In questo caso, il contesto rappresenta un'esecuzione e ogni esecuzione rappresenta un passaggio della pipeline ML.
Un esperimento eseguito da un notebook. In questo caso, il contesto potrebbe rappresentare il notebook e ogni esecuzione potrebbe rappresentare una cella del notebook.
event
- Un evento descrive la relazione tra artefatti ed esecuzioni. Ogni artefatto può essere prodotto da un'esecuzione e utilizzato da altre esecuzioni. Gli eventi ti aiutano a determinare la provenienza degli artefatti nei workflow ML concatenando artefatti ed esecuzioni.
esecuzione
- Un'esecuzione è un record di un singolo passaggio del flusso di lavoro di machine learning, in genere annotato con i relativi parametri di runtime. Esempi di esecuzioni includono l'importazione dati, la convalida dei dati, l'addestramento del modello, la valutazione del modello e il deployment del modello.
MetadataSchema
- Un MetadataSchema descrive lo schema per particolari tipi di artefatti, esecuzioni o contesti. MetadataSchema vengono utilizzati per convalidare le coppie chiave-valore durante la creazione delle risorse Metadata corrispondenti. La convalida dello schema viene eseguita solo sui campi corrispondenti tra la risorsa e MetadataSchema. Gli schemi di tipo sono rappresentati utilizzando oggetti schema OpenAPI, che devono essere descritti utilizzando YAML.
Esempio di MetadataSchema
Gli schemi dei tipi sono rappresentati utilizzando oggetti schema OpenAPI, che devono essere descritti utilizzando YAML.
Di seguito è riportato un esempio di come viene specificato il tipo di sistema Model predefinito in formato YAML.
title: system.Model
type: object
properties:
framework:
type: string
description: "The framework type, for example 'TensorFlow' or 'Scikit-Learn'."
framework_version:
type: string
description: "The framework version, for example '1.15' or '2.1'"
payload_format:
type: string
description: "The format of the Model payload, for example 'SavedModel' or 'TFLite'"
Il titolo dello schema deve utilizzare il formato <namespace>.<type name>.
Vertex ML Metadata pubblica e gestisce schemi definiti dal sistema per rappresentare i tipi comuni ampiamente utilizzati nei workflow ML. Questi schemi si trovano nello spazio dei nomi system e sono accessibili come risorse MetadataSchema nell'API. Gli schemi sono sempre versionati.
Per scoprire di più sugli schemi, consulta la sezione Schemi di sistema. Inoltre, Vertex ML Metadata ti consente di creare schemi personalizzati definiti dall'utente. Per scoprire di più sugli schemi di sistema, consulta Come registrare schemi personalizzati.
Le risorse dei metadati esposte rispecchiano fedelmente quelle dell'implementazione open source di ML Metadata (MLMD).