Vector Search adalah mesin telusur vektor yang canggih dan dibuat berdasarkan teknologi inovatif yang dikembangkan oleh Tim Riset Google. Dengan memanfaatkan algoritma ScaNN, Vector Search memungkinkan Anda membuat sistem penelusuran dan rekomendasi generasi berikutnya serta aplikasi AI generatif.
Anda dapat memanfaatkan riset dan teknologi yang sama yang mendukung produk Google inti, termasuk Google Penelusuran, YouTube, dan Google Play. Artinya, Anda mendapatkan skalabilitas, ketersediaan, dan performa yang tepercaya untuk menangani set data besar dan memberikan hasil secepat kilat pada skala global. Dengan Penelusuran Vektor, Anda memiliki solusi tingkat perusahaan untuk menerapkan kemampuan penelusuran semantik canggih di aplikasi Anda sendiri.
|
|
Infinite Fleurs: Temukan kreativitas yang didukung AI dalam kejayaannya |

Mengeksperimen dengan AI multimodal menggunakan manga ONE PIECE |
Mulai
Demo interaktif Penelusuran Vektor: Lihat demo langsung untuk mengetahui contoh realistis tentang kemampuan teknologi penelusuran vektor dan dapatkan awalan dengan Penelusuran Vektor.
Panduan memulai Vector Search: Coba Vector Search dalam waktu 30 menit dengan mem-build, men-deploy, dan mengkueri indeks Vector Search menggunakan set data contoh. Tutorial ini membahas penyiapan, persiapan data, pembuatan indeks, deployment, kueri, dan pembersihan.
Sebelum memulai: Siapkan embedding dengan memilih dan melatih model, serta menyiapkan data. Kemudian, pilih endpoint publik atau pribadi untuk men-deploy indeks kueri Anda.
Harga dan kalkulator harga Vector Search: Harga Vector Search mencakup biaya virtual machine yang digunakan untuk menghosting indeks yang di-deploy, serta biaya untuk membuat dan mengupdate indeks. Bahkan penyiapan minimal (di bawah $100 per bulan) dapat mengakomodasi throughput tinggi untuk kasus penggunaan berukuran sedang. Untuk memperkirakan biaya bulanan Anda:
- Buka kalkulator harga Google Cloud.
- Klik Tambahkan ke estimasi.
- Telusuri Vertex AI.
- Klik tombol Vertex AI.
- Pilih Vertex AI Vector Search dari dropdown Service type.
- Simpan setelan default atau konfigurasikan setelan Anda sendiri. Estimasi biaya per bulan ditampilkan di panel Detail biaya.
Dokumentasi
Mengelola Indeks dan Endpoint
Topik lanjutan
Kasus penggunaan dan blog
Teknologi penelusuran vektor menjadi hub utama bagi bisnis yang menggunakan AI. Serupa dengan cara kerja database relasional dalam sistem IT, database ini menghubungkan berbagai elemen bisnis seperti dokumen, konten, produk, pengguna, peristiwa, dan entitas lainnya berdasarkan relevansinya. Selain menelusuri media konvensional seperti dokumen dan gambar, Penelusuran Vektor juga dapat mendukung rekomendasi cerdas, mencocokkan masalah bisnis dengan solusi, dan bahkan menautkan sinyal IoT ke pemberitahuan pemantauan. Ini adalah alat serbaguna yang penting untuk menavigasi lanskap data perusahaan yang semakin berkembang dan didukung AI.
|
Penelusuran / Pengambilan Informasi
Sistem |
Cara penelusuran vektor Vertex AI membantu membuka aplikasi AI generatif berperforma tinggi: Penelusuran Vektor mendukung berbagai aplikasi, termasuk e-commerce, sistem RAG, dan mesin rekomendasi, bersama dengan chatbot, penelusuran multimodal, dan lainnya. Penelusuran campuran lebih meningkatkan hasil untuk istilah khusus. Pelanggan seperti Bloomreach, eBay, dan Mercado Libre menggunakan Vertex AI karena performa, skalabilitas, dan efektivitas biayanya, sehingga memperoleh manfaat seperti penelusuran yang lebih cepat dan peningkatan konversi. eBay menggunakan Vector Search untuk rekomendasi: Menyoroti cara eBay menggunakan Vector Search untuk sistem rekomendasinya. Teknologi ini memungkinkan eBay menemukan produk serupa dalam katalognya yang luas, sehingga meningkatkan pengalaman pengguna. Mercari memanfaatkan teknologi penelusuran vektor Google untuk menciptakan marketplace baru: Menjelaskan cara Mercari menggunakan Penelusuran Vektor untuk meningkatkan platform marketplace barunya. Vector Search mendukung rekomendasi platform, membantu pengguna menemukan produk yang relevan dengan lebih efektif. Vertex AI Embeddings for Text: Cara mudah Grounding LLM: Berfokus pada grounding LLM menggunakan Vertex AI Embeddings untuk data teks. Penelusuran Vektor berperan penting dalam menemukan bagian teks yang relevan yang memastikan respons model didasarkan pada informasi faktual. Apa itu Penelusuran Multimodal: "LLM dengan visi" mengubah bisnis: Membahas Penelusuran Multimodal, yang menggabungkan LLM dengan pemahaman visual. Dokumen ini menjelaskan cara Vector Search memproses dan membandingkan data teks dan gambar, sehingga memungkinkan pengalaman penelusuran yang lebih komprehensif. Membuka penelusuran multimodal dalam skala besar: Menggabungkan kemampuan teks & gambar dengan Vertex AI: Menjelaskan cara membuat mesin telusur multimodal dengan Vertex AI yang menggabungkan penelusuran teks dan gambar menggunakan metode ensemble Rank Reciprocal Berbias Peringkat berbobot. Hal ini meningkatkan pengalaman pengguna dan memberikan hasil yang lebih relevan. Menskalakan deep retrieval dengan Pemberi Rekomendasi TensorFlow dan Vector Search: Menjelaskan cara membuat sistem rekomendasi playlist menggunakan Pemberi Rekomendasi TensorFlow dan Vector Search, yang mencakup model deep retrieval, pelatihan, deployment, dan penskalaan. |
|
AI generatif: pengambilan untuk RAG dan Agen |
Vertex AI dan Denodo membuka kunci data perusahaan dengan AI Generatif: Menunjukkan bagaimana integrasi Vertex AI dengan Denodo memungkinkan bisnis menggunakan AI generatif untuk mendapatkan insight dari data mereka. Penelusuran Vektor adalah kunci untuk mengakses dan menganalisis data yang relevan secara efisien dalam lingkungan perusahaan. Alam Tak Terbatas dan sifat industri: Demo 'liar' ini menunjukkan beragam kemungkinan AI: Menampilkan demo yang menggambarkan potensi AI di berbagai industri. Model ini menggunakan Vector Search untuk mendukung rekomendasi generatif dan penelusuran semantik multimodal. Infinite Fleurs: Temukan kreativitas yang dibantu AI dalam mekar penuh: Infinite Fleurs Google, sebuah eksperimen AI yang menggunakan model Vector Search, Gemini, dan Imagen, menghasilkan buket bunga unik berdasarkan perintah pengguna. Teknologi ini menunjukkan potensi AI untuk menginspirasi kreativitas di berbagai industri. LlamaIndex untuk RAG di Google Cloud: Menjelaskan cara menggunakan LlamaIndex untuk memfasilitasi Retrieval Augmented Generation (RAG) dengan model bahasa besar. LlamaIndex menggunakan Vector Search untuk mengambil informasi yang relevan dari pusat informasi, sehingga menghasilkan respons yang lebih akurat dan sesuai secara kontekstual. RAG dan grounding di Vertex AI: Memeriksa teknik RAG dan grounding di Vertex AI. Penelusuran Vektor membantu mengidentifikasi informasi dasar yang relevan selama pengambilan, sehingga konten yang dihasilkan lebih akurat dan andal. Vector Search di LangChain: memberikan panduan untuk menggunakan Vector Search dengan LangChain untuk membuat dan men-deploy indeks database vektor untuk data teks, termasuk menjawab pertanyaan dan pemrosesan PDF. |
|
BI, analisis data, pemantauan, dan lainnya |
Mengaktifkan AI real-time dengan Streaming Ingestion di Vertex AI: Menjelajahi Streaming Update di Vector Search dan cara menyediakan kemampuan AI real-time. Teknologi ini memungkinkan pemrosesan dan analisis streaming data yang masuk secara real-time. |
Referensi terkait
Anda dapat menggunakan referensi berikut untuk memulai Penelusuran Vektor:
Notebook dan solusi

|
|
|
Panduan Mulai Cepat Vertex AI Vector Search: Memberikan ringkasan tentang Vector Search. Fitur ini dirancang untuk pengguna yang baru menggunakan platform ini dan ingin memulai dengan cepat. |
Memulai Penggunaan Embedding Teks dan Penelusuran Vektor: Memperkenalkan embedding teks dan penelusuran vektor. Artikel ini menjelaskan cara kerja teknologi ini dan cara menggunakannya untuk meningkatkan hasil penelusuran. |

|
|
|
Menggabungkan Penelusuran Semantik & Kata Kunci: Tutorial Penelusuran Hybrid dengan Vertex AI Vector Search: Memberikan petunjuk tentang cara menggunakan Vector Search untuk penelusuran hybrid. Panduan ini membahas langkah-langkah yang diperlukan dalam menyiapkan dan mengonfigurasi sistem penelusuran campuran. |
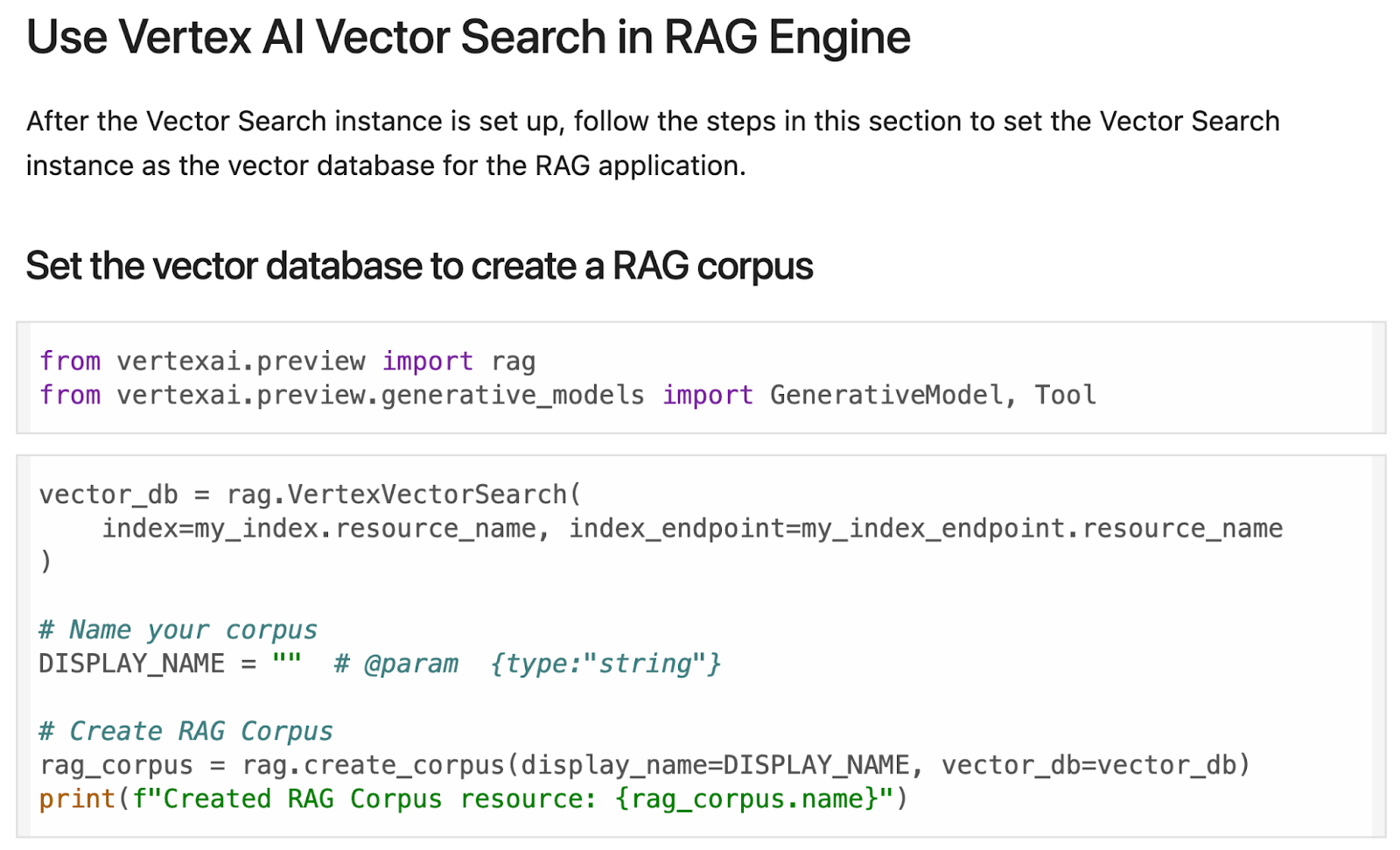
Mesin RAG Vertex AI dengan Penelusuran Vektor: Mempelajari penggunaan Mesin RAG Vertex AI dengan Penelusuran Vektor. Artikel ini membahas manfaat penggunaan kedua teknologi ini secara bersamaan dan memberikan contoh cara menggunakannya dalam aplikasi di dunia nyata. |
|
|
|
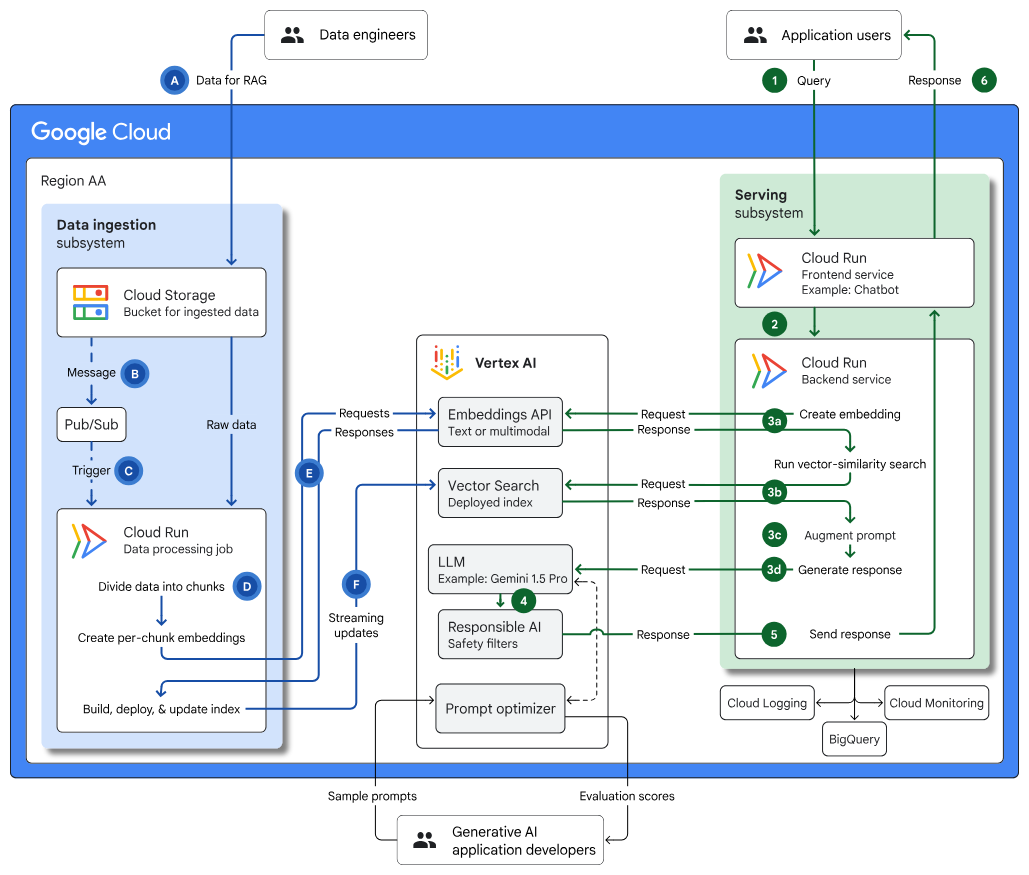
Infrastruktur untuk aplikasi AI generatif berkemampuan RAG menggunakan Vertex AI dan Penelusuran Vektor: Menjelaskan arsitektur untuk membuat aplikasi AI generatif dan RAG menggunakan Penelusuran Vektor, Cloud Run, dan Cloud Storage, yang mencakup kasus penggunaan, pilihan desain, dan pertimbangan utama. |
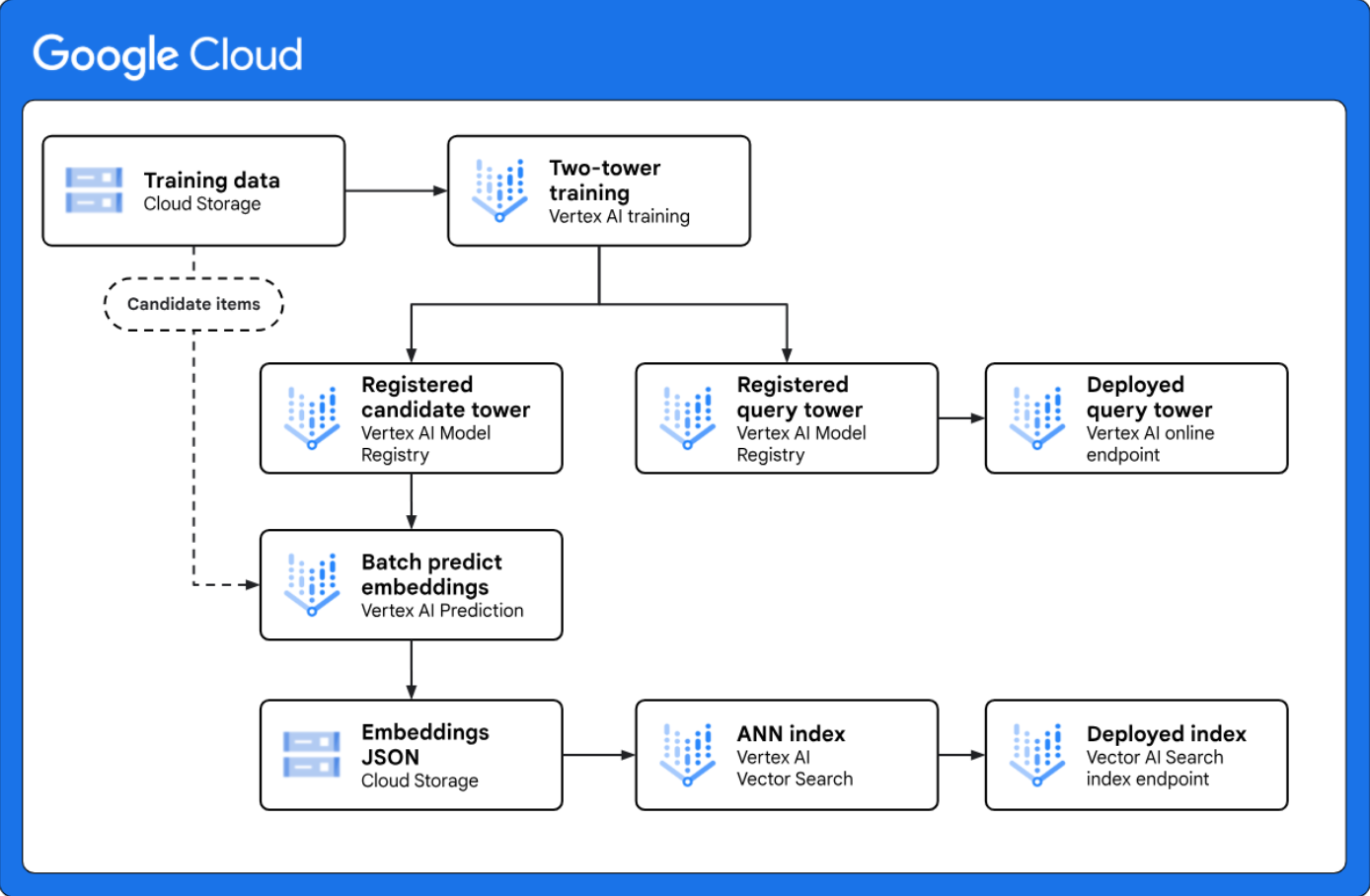
<p"> Menerapkan pengambilan dua menara untuk pembuatan kandidat skala besar: Memberikan arsitektur referensi yang menunjukkan cara menerapkan alur kerja pembuatan kandidat dua menara menyeluruh dengan Vertex AI. Framework pemodelan dua menara adalah teknik pengambilan yang efektif untuk kasus penggunaan personalisasi karena mempelajari kesamaan semantik antara dua entitas yang berbeda, seperti kueri web dan item kandidat. </p"> |
Pelatihan
Memulai Penelusuran Vektor dan Embeddings Penelusuran Vektor digunakan untuk menemukan item yang serupa atau terkait. Model ini dapat digunakan untuk rekomendasi, penelusuran, chatbot, dan klasifikasi teks. Proses ini meliputi pembuatan penyematan, menguploadnya ke Google Cloud, dan mengindeksnya untuk membuat kueri. Lab ini berfokus pada embedding teks menggunakan Vertex AI, tetapi embedding dapat dibuat untuk jenis data lainnya.
Penelusuran Vektor dan Embedding Kursus ini memperkenalkan Penelusuran Vektor dan menjelaskan cara menggunakannya untuk membuat aplikasi penelusuran dengan API model bahasa besar (LLM) untuk embedding. Kursus ini terdiri atas materi konseptual terkait Penelusuran Vektor dan embedding teks, demo praktis tentang cara membuat Penelusuran Vektor di Vertex AI, dan lab praktik.
Memahami dan Menerapkan Embedding Teks
Vertex AI Embeddings API menghasilkan embedding teks, yang merupakan
representasi numerik teks yang digunakan untuk tugas seperti mengidentifikasi item yang serupa.
Dalam kursus ini, Anda akan menggunakan embedding teks untuk tugas seperti klasifikasi dan penelusuran semantik, serta menggabungkan penelusuran semantik dengan LLM untuk membuat sistem menjawab pertanyaan menggunakan Vertex AI.
Kursus Singkat Machine Learning: Embedding Kursus ini memperkenalkan embedding kata, yang membedakannya dengan representasi jarang. Bagian ini membahas metode untuk mendapatkan penyematan dan membedakan antara penyematan statis dan kontekstual.
Produk terkait
Vertex AI Embeddings Memberikan ringkasan tentang Embeddings API. Kasus penggunaan penyematan teks dan multimodal, beserta link ke referensi tambahan dan layanan Google Cloud terkait.
API peringkat Aplikasi AI API peringkat mengurutkan ulang dokumen berdasarkan relevansinya dengan kueri menggunakan model bahasa terlatih, yang memberikan skor yang akurat. Hal ini ideal untuk meningkatkan hasil penelusuran dari berbagai sumber, termasuk Penelusuran Vektor.
Vertex AI Feature Store Memungkinkan Anda mengelola dan menyalurkan data fitur menggunakan BigQuery sebagai sumber data. Lapisan ini menyediakan resource untuk penayangan online, yang berfungsi sebagai lapisan metadata untuk menyalurkan nilai fitur terbaru langsung dari BigQuery. Feature Store memungkinkan pengambilan instan nilai fitur untuk item yang ditampilkan Vector Store untuk kueri.
Vertex AI Pipelines Vertex AI Pipelines memungkinkan otomatisasi, pemantauan, dan tata kelola sistem ML Anda tanpa server dengan mengorkestrasi alur kerja ML dengan pipeline ML. Anda dapat menjalankan pipeline ML yang ditentukan menggunakan Kubeflow Pipelines atau framework TensorFlow Extended (TFX) secara batch. Pipeline memungkinkan pembuatan pipeline otomatis untuk menghasilkan penyematan, membuat dan memperbarui indeks Vector Search, serta membentuk penyiapan MLOps untuk sistem penelusuran dan rekomendasi produksi.
Referensi pembahasan mendalam
Meningkatkan kasus penggunaan AI generatif Anda dengan jenis tugas dan penyematan Vertex AI Berfokus pada peningkatan aplikasi AI Generatif menggunakan jenis tugas dan Penyematan Vertex AI. Penelusuran Vektor dapat digunakan dengan penyematan jenis tugas untuk meningkatkan konteks dan akurasi konten yang dihasilkan dengan menemukan informasi yang lebih relevan.
TensorFlow Recommenders Library open source untuk membuat sistem rekomendasi. Hal ini menyederhanakan proses dari persiapan data hingga deployment dan mendukung pembuatan model yang fleksibel. TFRS menawarkan tutorial dan referensi serta memungkinkan pembuatan model rekomendasi yang canggih.
TensorFlow Ranking TensorFlow Ranking adalah library open source untuk membuat model neural learning-to-rank (LTR) yang skalabel. Library ini mendukung berbagai fungsi kerugian dan metrik peringkat, dengan aplikasi di penelusuran, rekomendasi, dan bidang lainnya. Library ini dikembangkan secara aktif oleh Google AI.
Pengumuman ScaNN: Efficient Vector Similarity Search ScaNN Google, algoritma untuk penelusuran kesamaan vektor yang efisien, menggunakan teknik baru untuk meningkatkan akurasi dan kecepatan dalam menemukan tetangga terdekat. Metode ini mengungguli metode yang ada dan memiliki aplikasi yang luas dalam tugas machine learning yang memerlukan penelusuran semantik. Upaya riset Google mencakup berbagai bidang, termasuk ML dasar dan dampak sosial AI.
SOAR: Algoritma baru untuk Penelusuran Vektor yang lebih cepat dengan ScaNN Algoritma SOAR Google meningkatkan efisiensi Penelusuran Vektor dengan memperkenalkan redundansi yang terkontrol, sehingga memungkinkan penelusuran yang lebih cepat dengan indeks yang lebih kecil. SOAR menetapkan vektor ke beberapa cluster, sehingga membuat jalur penelusuran "cadangan" untuk meningkatkan performa.
Video terkait
Mulai Menggunakan Vector Search dengan Vertex AI
Penelusuran Vektor adalah alat yang canggih untuk membuat aplikasi yang didukung AI. Video ini memperkenalkan teknologi tersebut dan memberikan panduan langkah demi langkah untuk memulainya.
Pelajari Penelusuran Hybrid dengan Penelusuran Vektor
Vector Search dapat digunakan untuk penelusuran campuran, sehingga Anda dapat menggabungkan kemampuan penelusuran vektor dengan fleksibilitas dan kecepatan mesin telusur konvensional. Video ini memperkenalkan penelusuran campuran dan menunjukkan cara menggunakan Penelusuran Vektor untuk penelusuran campuran.
Anda Sudah Menggunakan Penelusuran Vektor! Berikut Cara Menjadi Pakar
Tahukah Anda bahwa Anda mungkin menggunakan penelusuran vektor setiap hari tanpa menyadarinya? Mulai dari menemukan produk yang sulit ditemukan di media sosial hingga melacak lagu yang terus-menerus terngiang di kepala Anda, penelusuran vektor adalah keajaiban AI di balik pengalaman sehari-hari ini.
Embedding "jenis tugas" baru dari tim DeepMind meningkatkan kualitas penelusuran RAG
Tingkatkan akurasi dan relevansi sistem RAG Anda dengan penyematan jenis tugas baru yang dikembangkan oleh tim Google DeepMind. Tonton dan pelajari tantangan umum dalam kualitas penelusuran RAG dan cara embedding jenis tugas dapat menjembatani kesenjangan semantik antara pertanyaan dan jawaban secara efektif, sehingga menghasilkan pengambilan yang lebih efektif dan performa RAG yang lebih baik.
Terminologi Vector Search
Daftar ini berisi beberapa terminologi penting yang perlu Anda pahami untuk menggunakan Penelusuran Vektor:
Vektor: Vektor adalah daftar nilai float yang memiliki magnitudo dan arah. Atribut ini dapat digunakan untuk merepresentasikan jenis data apa pun, seperti angka, titik dalam ruang, dan arah.
Embedding: Embedding adalah jenis vektor yang digunakan untuk merepresentasikan data dengan cara menangkap makna semantiknya. Embedding biasanya dibuat menggunakan teknik machine learning, dan sering digunakan dalam natural language processing (NLP) dan aplikasi machine learning lainnya.
Embedding padat: Embedding padat merepresentasikan makna semantik teks, menggunakan array yang sebagian besar berisi nilai non-nol. Dengan penyematan yang padat, hasil penelusuran yang serupa dapat ditampilkan berdasarkan kemiripan semantik.
Embedding jarang: Embedding jarang mewakili sintaksis teks, menggunakan array berdimensi tinggi yang berisi sangat sedikit nilai non-nol dibandingkan dengan embedding rapat. Embed jarang digunakan untuk penelusuran kata kunci.
Penelusuran hybrid: Penelusuran hybrid menggunakan penyematan padat dan jarang, yang memungkinkan Anda melakukan penelusuran berdasarkan kombinasi penelusuran kata kunci dan penelusuran semantik. Penelusuran Vektor mendukung penelusuran berdasarkan embedding padat, embedding jarang, dan penelusuran campuran.
Indeks: Kumpulan vektor yang di-deploy secara bersamaan untuk penelusuran kemiripan. Vektor dapat ditambahkan ke atau dihapus dari indeks. Kueri penelusuran kemiripan dikeluarkan pada indeks tertentu dan menelusuri vektor dalam indeks tersebut.
Kebenaran nyata: Istilah yang mengacu pada verifikasi machine learning untuk memastikan akurasinya terhadap dunia nyata, seperti set data kebenaran nyata.
Perolehan: Persentase tetangga terdekat yang ditampilkan oleh indeks yang sebenarnya adalah tetangga terdekat sebenarnya. Misalnya, jika kueri tetangga terdekat untuk 20 tetangga terdekat menampilkan 19 tetangga terdekat dari kebenaran nyata, perolehannya adalah 19/20x100 = 95%.
Batasi: Fitur yang membatasi penelusuran ke sebagian indeks dengan menggunakan aturan Boolean. Membatasi disebut juga sebagai "pemfilteran". Dengan Vector Search, Anda dapat menggunakan pemfilteran numerik dan pemfilteran atribut teks.