Die Vektorsuche ist eine leistungsstarke Vektorsuchmaschine, die auf der bahnbrechenden Technologie von Google Research basiert. Mit dem ScaNN-Algorithmus können Sie Such- und Empfehlungssysteme sowie generative KI-Anwendungen der nächsten Generation entwickeln.
Sie profitieren von denselben Forschungs- und Technologielösungen, die auch für die wichtigsten Google-Produkte wie die Google Suche, YouTube und Google Play verwendet werden. Das bedeutet, dass Sie die Skalierbarkeit, Verfügbarkeit und Leistung erhalten, die für die Verarbeitung riesiger Datenmengen und die Bereitstellung blitzschneller Ergebnisse in globalem Maßstab erforderlich sind. Mit der Vektorsuche haben Sie eine Lösung für Unternehmen, mit der Sie modernste semantische Suchfunktionen in Ihren eigenen Anwendungen implementieren können.
|
|
|

|
Jetzt starten
Interaktive Demo zur Vektorsuche: In der Live-Demo sehen Sie ein realistisches Beispiel für die Möglichkeiten der Vektorsuchtechnologie und erhalten einen Vorsprung bei der Vektorsuche.
Kurzanleitung zur Vektorsuche: In 30 Minuten können Sie die Vektorsuche ausprobieren, indem Sie einen Vektorsuchindex mit einem Beispieldatensatz erstellen, bereitstellen und abfragen. In diesem Tutorial werden die Einrichtung, die Datenvorbereitung, die Indexerstellung, die Bereitstellung, die Abfrage und die Bereinigung behandelt.
Vorbereitung: Bereiten Sie Ihre Einbettungen vor, indem Sie ein Modell auswählen und trainieren sowie Ihre Daten vorbereiten. Wählen Sie dann einen öffentlichen oder privaten Endpunkt aus, auf dem der Abfrageindex bereitgestellt werden soll.
Preise und Preisrechner für die Vektorsuche: Die Preise für die Vektorsuche umfassen die Kosten für virtuelle Maschinen, die zum Hosten bereitgestellter Indexe verwendet werden, sowie die Kosten für das Erstellen und Aktualisieren von Indexen. Selbst eine minimale Einrichtung (unter 100 $pro Monat) kann einen hohen Durchsatz für Anwendungsfälle mittlerer Größe bieten. So schätzen Sie Ihre monatlichen Kosten:
- Rufen Sie den Google Cloud-Preisrechner auf.
- Klicken Sie auf Der Schätzung hinzufügen.
- Suchen Sie nach „Vertex AI“.
- Klicken Sie auf die Schaltfläche Vertex AI.
- Wählen Sie im Drop-down-Menü Servicetyp die Option Vertex AI Vektorsuche aus.
- Sie können die Standardeinstellungen beibehalten oder eigene konfigurieren. Die geschätzten Kosten pro Monat werden im Bereich Kostendetails angezeigt.
Dokumentation
Indexe und Endpunkte verwalten
Erweiterte Themen
Anwendungsfälle und Blogs
Die Vektorsuchtechnologie wird zu einem zentralen Hub für Unternehmen, die KI einsetzen. Ähnlich wie relationale Datenbanken in IT-Systemen funktionieren, werden verschiedene Geschäftselemente wie Dokumente, Inhalte, Produkte, Nutzer, Ereignisse und andere Entitäten basierend auf ihrer Relevanz miteinander verknüpft. Neben der Suche in herkömmlichen Medien wie Dokumenten und Bildern kann die Vektorsuche auch intelligente Empfehlungen liefern, Geschäftsprobleme mit Lösungen abgleichen und sogar IoT-Signale mit Monitoring-Benachrichtigungen verknüpfen. Es ist ein vielseitiges Tool, das für die Navigation in der wachsenden Landschaft der KI-gestützten Unternehmensdaten unerlässlich ist.
|
Suche / Informationsabruf
Empfehlungs |
Mit der Vektorsuche von Vertex AI leistungsstarke Gen AI-Anwendungen entwickeln:Mit der Vektorsuche können Sie verschiedene Anwendungen erstellen, darunter E-Commerce-, RAG-Systeme und Empfehlungssysteme sowie Chatbots und multimodale Suche. Mit der Hybridsuche werden die Ergebnisse für Nischenbegriffe weiter verbessert. Kunden wie Bloomreach, eBay und Mercado Libre nutzen Vertex AI aufgrund seiner Leistung, Skalierbarkeit und Kosteneffizienz. So profitieren sie von Vorteilen wie einer schnelleren Suche und mehr Conversions. eBay verwendet die Vektorsuche für Empfehlungen:Hier erfahren Sie, wie eBay die Vektorsuche für sein Empfehlungssystem verwendet. Mit dieser Technologie kann eBay ähnliche Produkte in seinem umfangreichen Katalog finden und so die Nutzerfreundlichkeit verbessern. Mercari nutzt die Vektorsuchtechnologie von Google, um einen neuen Marktplatz zu erstellen: Hier erfahren Sie, wie Mercari die Vektorsuche verwendet, um seine neue Marktplatzplattform zu verbessern. Die Vektorsuche bildet die Grundlage für die Empfehlungen der Plattform und hilft Nutzern, relevante Produkte effektiver zu finden. Vertex AI Embeddings for Text: Grounding LLMs made easy:Im Mittelpunkt steht die Fundierung von LLMs mit Vertex AI-Embeddings für Textdaten. Die Vektorsuche spielt eine wichtige Rolle bei der Suche nach relevanten Textpassagen, die dafür sorgen, dass die Antworten des Modells auf Fakten basieren. What is Multimodal Search: "LLMs with vision" change businesses Hier erfahren Sie mehr über die multimodale Suche, bei der LLMs mit visuellem Verständnis kombiniert werden. Darin wird erläutert, wie die Vektorsuche sowohl Text- als auch Bilddaten verarbeitet und vergleicht, um eine umfassendere Suche zu ermöglichen. Multimodale Suche im großen Maßstab: Text- und Bildfunktionen mit Vertex AI kombinieren:Hier erfahren Sie, wie Sie mit Vertex AI eine multimodale Suchmaschine erstellen, die Text- und Bildsuche mithilfe einer Ensemblemethode mit gewichtetem gewichteten reziproken Rang kombiniert. Das verbessert die Nutzerfreundlichkeit und liefert relevantere Ergebnisse. Deep Retrieval mit TensorFlow Recommenders und der Vektorsuche skalieren:Hier erfahren Sie, wie Sie mit TensorFlow Recommenders und der Vektorsuche ein Empfehlungssystem für Playlists erstellen. Dabei werden Deep-Retrieval-Modelle, Training, Bereitstellung und Skalierung behandelt. |
|
Generative KI: Abruf für RAG und Kundenservicemitarbeiter |
Vertex AI und Denodo erschließen Unternehmensdaten mit Generative AI:Hier erfahren Sie, wie Unternehmen mit der Einbindung von Vertex AI in Denodo generative KI nutzen können, um Erkenntnisse aus ihren Daten zu gewinnen. Die Vektorsuche ist entscheidend für den effizienten Zugriff auf und die Analyse relevanter Daten in einer Unternehmensumgebung. Unendliche Natur und die Natur von Branchen: Diese „wilde“ Demo zeigt die vielfältigen Möglichkeiten von KI. Eine Demo, die das Potenzial von KI in verschiedenen Branchen veranschaulicht. Dabei wird die Vektorsuche für generative Empfehlungen und die multimodale semantische Suche genutzt. Infinite Fleurs: KI-gestützte Kreativität in voller Blüte:Mit Infinite Fleurs von Google, einem KI-Experiment mit Vector Search, Gemini und Imagen-Modellen, werden einzigartige Blumensträuße basierend auf Nutzervorschlägen erstellt. Diese Technologie zeigt das Potenzial von KI, die Kreativität in verschiedenen Branchen zu inspirieren. LlamaIndex für RAG in Google Cloud:Hier erfahren Sie, wie Sie LlamaIndex verwenden, um die Retrieval-Augmented Generation (RAG) mit Large Language Models zu ermöglichen. LlamaIndex nutzt die Vektorsuche, um relevante Informationen aus einer Wissensdatenbank abzurufen. Das führt zu genaueren und kontextbezogenen Antworten. RAG und Grounding in Vertex AI:In diesem Artikel werden RAG- und Grounding-Techniken in Vertex AI untersucht. Die Vektorsuche hilft dabei, relevante Informationen zur Fundierung während des Abrufs zu identifizieren, wodurch generierte Inhalte genauer und zuverlässiger werden. Vektorsuche in LangChain:Leitfaden zur Verwendung der Vektorsuche mit LangChain zum Erstellen und Bereitstellen eines Vektordatenbankindexes für Textdaten, einschließlich Fragebeantwortung und PDF-Verarbeitung. |
|
BI, Datenanalyse, Monitoring und mehr |
Echtzeit-KI mit Streamingaufnahme in Vertex AI aktivieren:Informationen zum Streaming-Update in der Vektorsuche und dazu, wie damit KI-Funktionen in Echtzeit bereitgestellt werden. Diese Technologie ermöglicht die Echtzeitverarbeitung und -analyse eingehender Datenstreams. |
Weitere Informationen
Die folgenden Ressourcen können Ihnen den Einstieg in die Vektorsuche erleichtern:
Notebooks und Lösungen

|
|
|
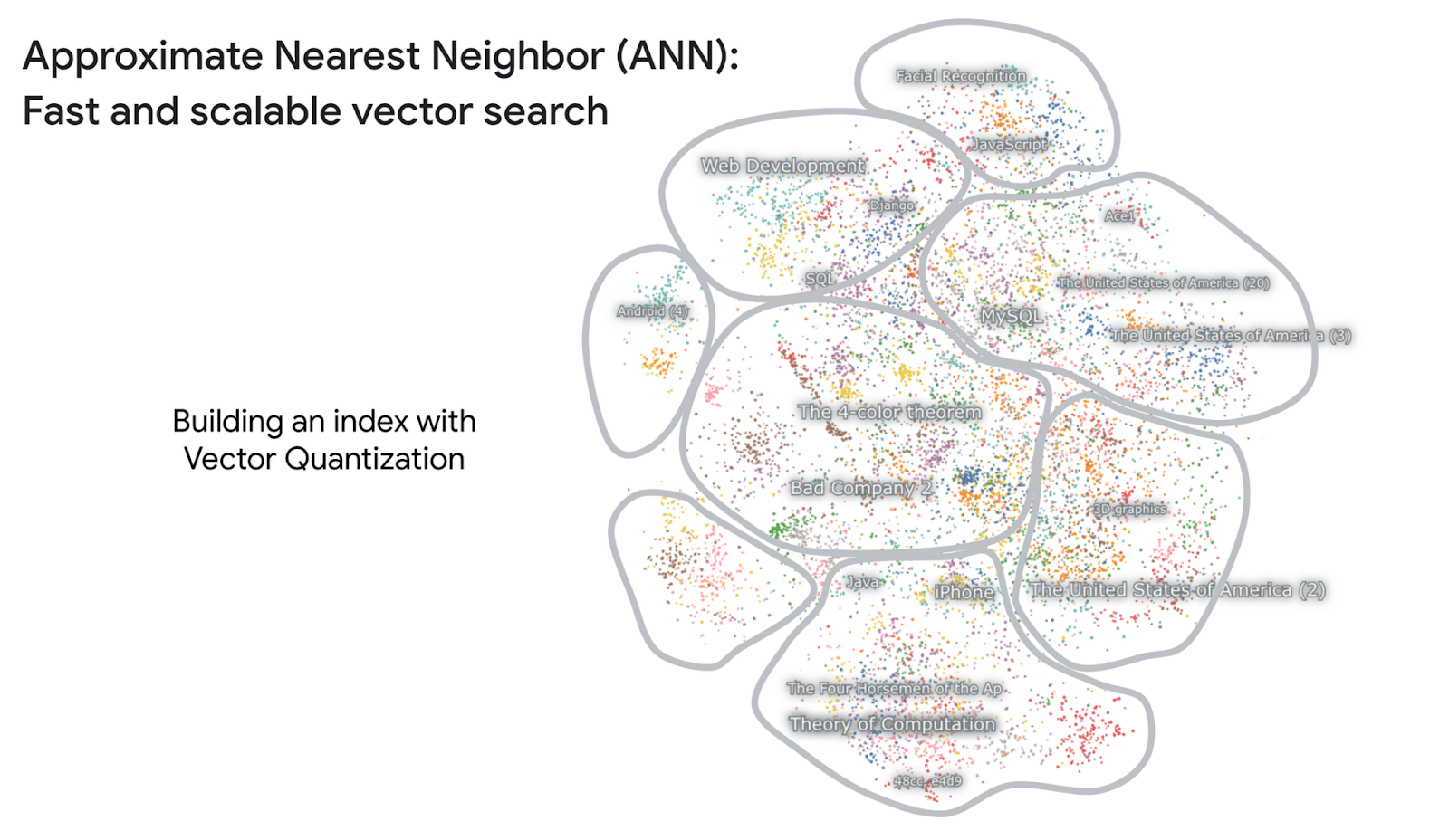
Schnellstart für die Vertex AI-Vektorsuche:Hier erhalten Sie einen Überblick über die Vektorsuche. Sie richtet sich an Nutzer, die neu auf der Plattform sind und schnell loslegen möchten. |
Erste Schritte mit Texteinbettungen und der Vektorsuche:Einführung in Texteinbettungen und die Vektorsuche. Darin wird erläutert, wie diese Technologien funktionieren und wie sie zur Verbesserung der Suchergebnisse eingesetzt werden können. |

|
|
|
Combining Semantic & Keyword Search: A Hybrid Search Tutorial with Vertex AI Vector Search: Anleitung zur Verwendung der Vektorsuche für die hybride Suche. Es werden die Schritte zur Einrichtung und Konfiguration eines hybriden Suchsystems beschrieben. |
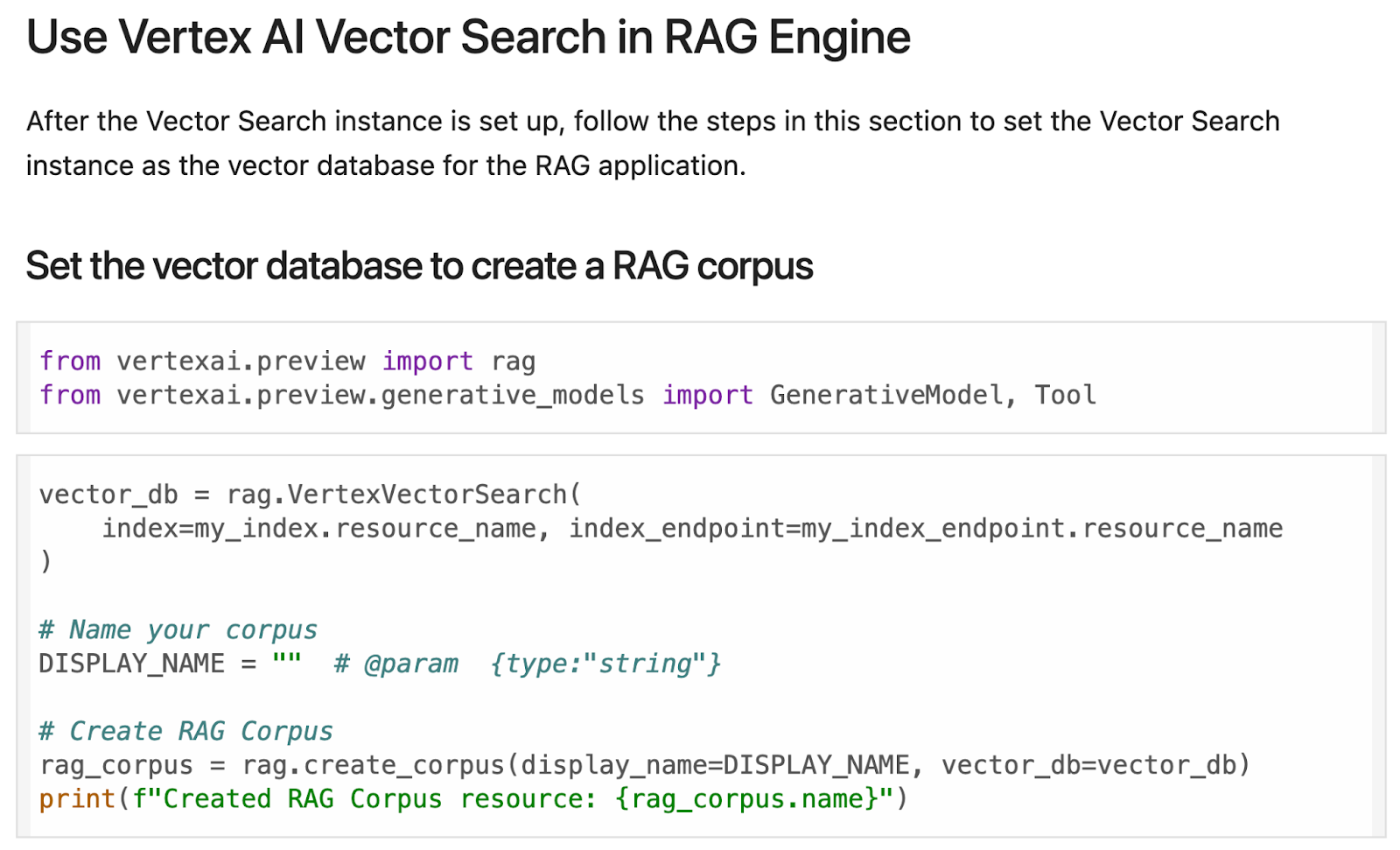
Vertex AI-RAG-Engine mit Vektorsuche:Informationen zur Verwendung der Vertex AI-RAG-Engine mit Vektorsuche. Darin werden die Vorteile der Kombination dieser beiden Technologien erläutert und Beispiele dafür gegeben, wie sie in der Praxis eingesetzt werden können. |
|
|
|
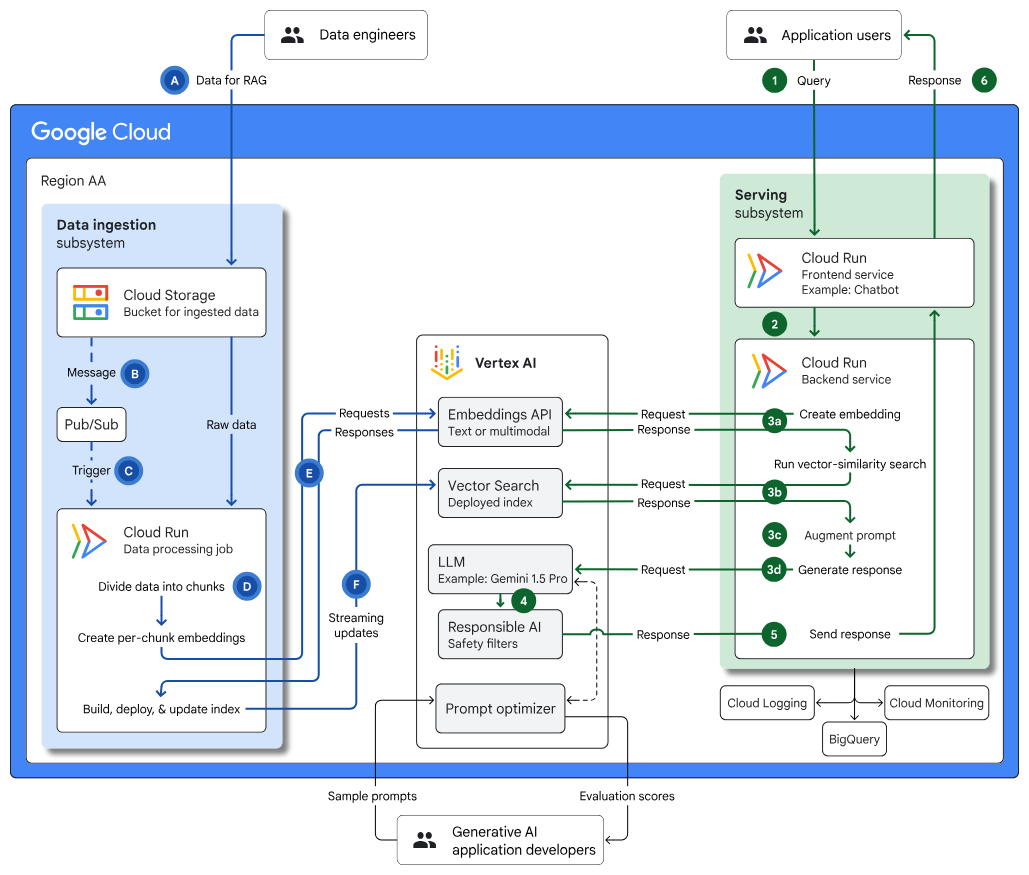
Infrastruktur für eine RAG-fähige generative KI-Anwendung mit Vertex AI und Vektorsuche:Hier erfahren Sie mehr über die Architektur zum Erstellen einer generativen KI-Anwendung und RAG mithilfe von Vektorsuche, Cloud Run und Cloud Storage. Außerdem werden Anwendungsfälle, Designentscheidungen und wichtige Überlegungen behandelt. |
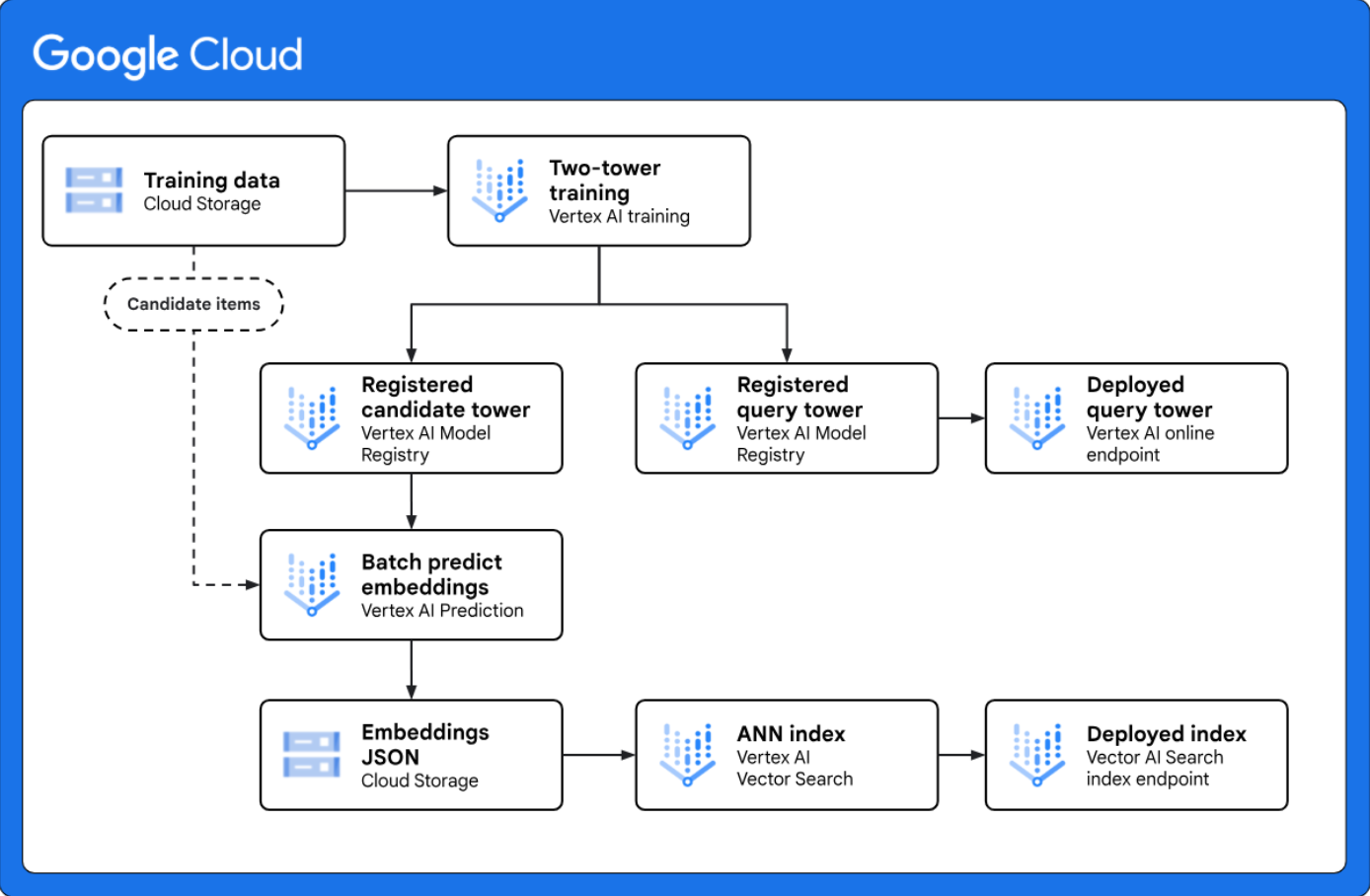
<p"> Two-Tower-Abruf für die groß angelegte Kandidatengenerierung implementieren: Eine Referenzarchitektur, die zeigt, wie Sie mit Vertex AI einen End-to-End-Two-Tower-Workflow für die Kandidatengenerierung implementieren. Das Two-Tower-Modell ist ein leistungsstarkes Abrufverfahren für Anwendungsfälle der Personalisierung, da es die semantische Ähnlichkeit zwischen zwei verschiedenen Entitäten lernt, z. B. zwischen Webanfragen und Kandidatenelementen. </p"> |
Training
Einstieg in die Vektorsuche und Einbettungen Mit der Vektorsuche können ähnliche oder verwandte Elemente gefunden werden. Sie kann für Empfehlungen, Suchanfragen, Chatbots und Textklassifizierung verwendet werden. Dazu müssen Sie Einbettungen erstellen, sie in Google Cloudhochladen und für Abfragen indexieren. In diesem Lab liegt der Schwerpunkt auf Texteinbettungen mit Vertex AI. Einbettungen können jedoch auch für andere Datentypen generiert werden.
Vektorsuche und Einbettungen In diesem Kurs wird die Vektorsuche vorgestellt und beschrieben, wie sie beim Erstellen einer Suchanwendung mit Large Language Model-APIs (LLM) für Einbettungen genutzt werden kann. Der Kurs besteht aus konzeptionellen Lektionen über die Vektorsuche und Texteinbettungen, praktischen Demos zum Erstellen einer Vektorsuche in Vertex AI und einem Übungs-Lab.
Text-Embeddings verstehen und anwenden
Die Vertex AI Embeddings API generiert Texteinbettungen,
also numerische Textdarstellungen, die für Aufgaben wie die Identifizierung ähnlicher Elemente verwendet werden.
In diesem Kurs verwenden Sie Texteinbettungen für Aufgaben wie Klassifizierung und semantische Suche und kombinieren die semantische Suche mit LLMs, um mit Vertex AI Systeme zur Beantwortung von Fragen zu erstellen.
Crashkurs „Maschinelles Lernen“: Embeddings In diesem Kurs werden Worteinbettungen vorgestellt und mit spärlichen Darstellungen verglichen. Es werden Methoden zum Erstellen von Einbettungen untersucht und zwischen statischen und kontextbezogenen Einbettungen unterschieden.
Ähnliche Produkte
Vertex AI Embeddings: Hier finden Sie eine Übersicht über die Embeddings API. Anwendungsfälle für Text- und multimodale Einbettung sowie Links zu zusätzlichen Ressourcen und zugehörigen Google Cloud Diensten.
Ranking API für KI-Anwendungen Mit der Ranking API werden Dokumente anhand der Relevanz für eine Suchanfrage mithilfe eines vorab trainierten Sprachmodells neu bewertet und präzise Bewertungen vergeben. Sie eignet sich ideal, um die Suchergebnisse aus verschiedenen Quellen zu verbessern, einschließlich der Vektorsuche.
Vertex AI Feature Store: Hiermit können Sie Feature-Daten mit BigQuery als Datenquelle verwalten und bereitstellen. Er stellt Ressourcen für die Onlinebereitstellung bereit und fungiert als Metadatenebene, um die neuesten Featurewerte direkt aus BigQuery bereitzustellen. Der Feature Store ermöglicht den sofortigen Abruf von Featurewerten für die Elemente, die der Vector Store für Abfragen zurückgegeben hat.
Vertex AI Pipelines Mit Vertex AI Pipelines können Sie Ihre ML-Systeme serverlos automatisieren, überwachen und verwalten. Dazu werden ML-Workflows mit ML-Pipelines orchestriert. Sie können ML-Pipelines, die mit Kubeflow Pipelines oder dem TensorFlow Extended (TFX)-Framework definiert wurden, im Batch ausführen. Mit Pipelines können Sie automatisierte Pipelines zum Generieren von Einbettungen, zum Erstellen und Aktualisieren von Vector Search-Indexen und zum Erstellen einer MLOps-Einrichtung für Produktionssuch- und Empfehlungssysteme erstellen.
Ressourcen für detaillierte Informationen
Generative AI-Anwendungsfall mit Vertex AI-Embeddings und Aufgabentypen verbessern Befasst sich mit der Verbesserung von Anwendungen mit generativer KI mithilfe von Vertex AI-Embeddings und Aufgabentypen. Die Vektorsuche kann mit Einbettungen von Aufgabentypen verwendet werden, um den Kontext und die Genauigkeit der generierten Inhalte zu verbessern, indem relevantere Informationen gefunden werden.
TensorFlow Recommenders: Eine Open-Source-Bibliothek zum Erstellen von Empfehlungssystemen. Es vereinfacht den Prozess von der Datenvorbereitung bis zur Bereitstellung und unterstützt die flexible Modellerstellung. TFRS bietet Tutorials und Ressourcen und ermöglicht die Erstellung ausgefeilter Empfehlungsmodelle.
TensorFlow Ranking TensorFlow Ranking ist eine Open-Source-Bibliothek zum Erstellen skalierbarer neuronaler LTR-Modelle (Learning-to-Rank). Sie unterstützt verschiedene Verlustfunktionen und Ranking-Messwerte, die in der Suche, bei Empfehlungen und in anderen Bereichen eingesetzt werden können. Die Bibliothek wird aktiv von Google AI entwickelt.
Announcing ScaNN: Efficient Vector Similarity Search ScaNN von Google ist ein Algorithmus für die effiziente Vektorähnlichkeitssuche, der eine neuartige Methode nutzt, um die Genauigkeit und Geschwindigkeit bei der Suche nach nächsten Nachbarn zu verbessern. Sie übertrifft bestehende Methoden und findet breite Anwendung bei Aufgaben des maschinellen Lernens, die eine semantische Suche erfordern. Die Forschungsaktivitäten von Google umfassen verschiedene Bereiche, darunter grundlegende ML und die gesellschaftlichen Auswirkungen von KI.
SOAR: Neue Algorithmen für eine noch schnellere Vektorsuche mit ScaNN Der SOAR-Algorithmus von Google verbessert die Effizienz der Vektorsuche durch kontrollierte Redundanz, was schnellere Suchanfragen mit kleineren Indexen ermöglicht. SOAR weist mehreren Clustern Vektoren zu und erstellt so „Back-up“-Suchpfade für eine bessere Leistung.
Ähnliche Videos
Einführung in die Vektorsuche mit Vertex AI
Die Vektorsuche ist ein leistungsstarkes Tool zum Erstellen von KI-gestützten Anwendungen. In diesem Video wird die Technologie vorgestellt und eine detaillierte Anleitung für den Einstieg gegeben.
Hybridsuche mit der Vektorsuche
Die Vektorsuche kann für die hybride Suche verwendet werden. So können Sie die Leistungsfähigkeit der Vektorsuche mit der Flexibilität und Geschwindigkeit einer herkömmlichen Suchmaschine kombinieren. In diesem Video wird die Hybridsuche vorgestellt und gezeigt, wie Sie die Vektorsuche für die Hybridsuche verwenden.
Sie nutzen die Vektorsuche bereits! So werden Sie zum Experten
Wussten Sie, dass Sie die Vektorsuche wahrscheinlich jeden Tag verwenden, ohne es zu merken? Ob Sie ein bestimmtes Produkt in den sozialen Medien finden oder einen Song finden möchten, der Ihnen nicht aus dem Kopf geht – die Vektorsuche ist die KI-Magie hinter diesen alltäglichen Dingen.
Neue Einbettung des „Aufgabentyps“ vom DeepMind-Team verbessert die Qualität der RAG-Suche
Verbessern Sie die Genauigkeit und Relevanz Ihrer RAG-Systeme mit neuen Aufgabentyp-Einbettungen, die vom Google DeepMind-Team entwickelt wurden. Sie erfahren, welche Herausforderungen bei der Qualität der RAG-Suche häufig auftreten und wie Einbettungen von Aufgabentypen die semantische Lücke zwischen Fragen und Antworten effektiv schließen können, was zu einer effektiveren Suche und einer verbesserten RAG-Leistung führt.
Terminologie der Vektorsuche
Diese Liste enthält einige wichtige Begriffe, die Sie für die Verwendung der Vektorsuche kennen sollten:
Vektor: Ein Vektor ist eine Liste von Gleitkommawerten mit Betrag und Richtung. Sie können damit alle Arten von Daten darstellen, z. B. Zahlen, Punkte im Raum und Richtungen.
Einbettung: Eine Einbettung ist ein Vektortyp, der zur Darstellung von Daten verwendet wird, um ihre semantische Bedeutung zu erfassen. Einbettungen werden meist mithilfe von Techniken des maschinellen Lernens erstellt und häufig in Natural Language Processing (NLP) und anderen ML-Anwendungen verwendet.
Dicht besetzen Einbettungen: Dichte Einbettungen stellen die semantische Bedeutung von Text dar, indem Arrays verwendet werden, die hauptsächlich Werte ungleich null enthalten. Mit dichten Einbettungen können ähnliche Suchergebnisse basierend auf semantischen Ähnlichkeiten zurückgegeben werden.
Dünnbesetzte Einbettungen: Dünnbesetzte Einbettungen stellen die Textsyntax dar und verwenden hochdimensionale Arrays, die im Vergleich zu dichten Einbettungen sehr wenige Werte ungleich null enthalten. Sparse Embeddings werden häufig für Suchanfragen verwendet.
Hybridsuche: Bei der Hybridsuche werden sowohl dichte als auch dünnbesetzte Einbettungen verwendet. So können Sie eine Kombination aus stichwortbasierter und semantischer Suche nutzen. Die Vektorsuche unterstützt die Suche auf der Grundlage enger und dünner Einbettungen sowie die Hybridsuche.
Index: Eine Sammlung von Vektoren, die gemeinsam für die Ähnlichkeitssuche bereitgestellt werden. Vektoren können einem Index hinzugefügt oder aus einem Index entfernt werden. Ähnlichkeitssuchanfragen werden an einen bestimmten Index gestellt und durchsuchen die Vektoren in diesem Index.
Ground Truth: Ein Begriff, bei dem das maschinelle Lernen auf Genauigkeit im echten Leben geprüft wird, z. B. ein Ground Truth-Dataset.
Recall: Der Prozentsatz der vom Index zurückgegebenen nächsten Nachbarn, die tatsächlich echte nächste Nachbarn sind. Wenn z. B. eine Abfrage nach 20 nächsten Nachbarn 19 der „grundlegend echten“ nächsten Nachbarn zurückgibt, beträgt der Recall 19/20x100 = 95 %.
Einschränken: Funktion, mit der Suchanfragen mithilfe von booleschen Regeln auf eine Teilmenge des Index beschränkt werden. „Einschränken“ wird auch als „Filter“ bezeichnet. Mit der Vektorsuche können Sie nach numerischen Werten und Textattributen filtern.