Bagian tujuan berikut berisi informasi tentang persyaratan data, file skema input/output, dan format file impor data (JSON Lines & CSV) yang ditentukan oleh skemanya.
Deteksi objek
Persyaratan data
| Persyaratan gambar umum | |
|---|---|
| Jenis file yang didukung |
|
| Jenis gambar | Model AutoML dioptimalkan untuk foto objek di dunia nyata. |
| Ukuran file gambar pelatihan (MB) | Ukuran maksimum 30 MB |
| Ukuran file* gambar prediksi (MB) | Ukuran maksimum 1,5 MB |
| Ukuran gambar (piksel) | Maksimum yang disarankan adalah 1024 piksel x 1024 piksel. Untuk gambar yang jauh lebih besar dari 1024 piksel x 1024 piksel, beberapa kualitas image mungkin hilang selama proses normalisasi gambar Vertex AI. |
| Persyaratan label dan kotak pembatas | |
|---|---|
| Persyaratan berikut berlaku untuk set data yang digunakan untuk melatih model AutoML. | |
| Instance label untuk pelatihan | Minimum 10 anotasi (instance). |
| Persyaratan anotasi | Untuk setiap label, Anda harus memiliki minimal 10 gambar, masing-masing dengan setidaknya satu anotasi (kotak pembatas dan label). Namun, untuk tujuan pelatihan model, sebaiknya Anda menggunakan sekitar 1.000 anotasi per label. Secara umum, semakin banyak gambar per label yang Anda miliki, semakin baik performa model Anda. |
| Rasio label (label paling umum ke label yang paling tidak umum): | Model akan berfungsi optimal jika ada gambar 100x lebih banyak untuk label yang paling umum daripada label yang paling tidak umum. Untuk performa model, sebaiknya Anda menghapus label frekuensi sangat rendah. |
| Panjang tepi kotak pembatas | Memiliki minimal panjang sisi 0,01 * gambar. Misalnya, gambar berukuran 1000 * 900 piksel akan memerlukan kotak pembatas yang berukuran minimal 10 * 9 piksel. Ukuran mini kotak batas: 8 piksel x 8 piksel. |
| Persyaratan berikut berlaku untuk set data yang digunakan untuk melatih model AutoML atau model yang dilatih kustom. | |
| Kotak pembatas per gambar berbeda | Maksimum 500. |
| Kotak pembatas yang ditampilkan dari permintaan prediksi | 100 (default), maksimum 500. |
| Persyaratan set data dan data pelatihan | |
|---|---|
| Persyaratan berikut berlaku untuk set data yang digunakan untuk melatih model AutoML. | |
| Karakteristik gambar pelatihan | Data pelatihan harus semirip mungkin dengan data yang menjadi dasar prediksi. Misalnya, jika dalam kasus penggunaan Anda terdapat gambar buram dengan resolusi rendah (seperti dari kamera keamanan), data pelatihan Anda harus terdiri dari gambar buram dengan resolusi rendah. Secara umum, Anda juga harus mempertimbangkan untuk menyediakan beberapa sudut, resolusi, dan latar belakang untuk gambar pelatihan Anda. Model Vertex AI umumnya tidak dapat memprediksi label yang tidak dapat ditetapkan oleh manusia. Jadi, jika manusia tidak dapat menetapkan label dengan melihat gambar selama 1-2 detik, model tersebut kemungkinan tidak dapat dilatih untuk melakukan hal yang sama. |
| Pra-pemrosesan gambar internal | Setelah gambar diimpor, Vertex AI akan melakukan pra-pemrosesan pada data tersebut. Gambar yang telah diproses sebelumnya adalah data aktual yang digunakan untuk melatih model. Pra-pemrosesan gambar (perubahan ukuran) terjadi jika tepi terkecil gambar lebih besar dari 1024 piksel. Jika sisi yang lebih kecil gambar lebih besar dari 1024 piksel, sisi yang lebih kecil tersebut diperkecil menjadi 1024 piksel. Sisi yang lebih besar dan kotak pembatas yang ditentukan, keduanya diperkecil dengan jumlah yang sama seperti sisi yang lebih kecil. Akibatnya, semua anotasi yang diperkecil (kotak pembatas dan label) akan dihapus jika ukurannya kurang dari 8 piksel kali 8 piksel. Gambar dengan sisi yang lebih kecil kurang dari atau sama dengan 1024 piksel tidak akan melalui pengubahan ukuran pra-pemrosesan. |
| Persyaratan berikut berlaku untuk set data yang digunakan untuk melatih model AutoML atau model yang dilatih kustom. | |
| Gambar di setiap set data | Maksimum 150.000 |
| Total kotak pembatas beranotasi di setiap set data | Maksimum 1.000.000 |
| Jumlah label di setiap set data | minimum 1, maksimum 1.000 |
File skema YAML
Gunakan file skema yang dapat diakses secara publik berikut untuk mengimpor anotasi deteksi objek gambar (kotak pembatas dan label). File skema ini menentukan format file input data. Struktur file ini mengikuti skema OpenAPI.
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_bounding_box_io_format_1.0.0.yaml
File skema lengkap
title: ImageBoundingBox description: > Import and export format for importing/exporting images together with bounding box annotations. Can be used in Dataset.import_schema_uri field. type: object required: - imageGcsUri properties: imageGcsUri: type: string description: > A Cloud Storage URI pointing to an image. Up to 30MB in size. Supported file mime types: `image/jpeg`, `image/gif`, `image/png`, `image/webp`, `image/bmp`, `image/tiff`, `image/vnd.microsoft.icon`. boundingBoxAnnotations: type: array description: Multiple bounding box Annotations on the image. items: type: object description: > Bounding box anntoation. `xMin`, `xMax`, `yMin`, and `yMax` are relative to the image size, and the point 0,0 is in the top left of the image. properties: displayName: type: string description: > It will be imported as/exported from AnnotationSpec's display name, i.e. the name of the label/class. xMin: description: The leftmost coordinate of the bounding box. type: number format: double xMax: description: The rightmost coordinate of the bounding box. type: number format: double yMin: description: The topmost coordinate of the bounding box. type: number format: double yMax: description: The bottommost coordinate of the bounding box. type: number format: double annotationResourceLabels: description: Resource labels on the Annotation. type: object additionalProperties: type: string dataItemResourceLabels: description: Resource labels on the DataItem. type: object additionalProperties: type: string
File input
JSON Lines
JSON di setiap baris:
{
"imageGcsUri": "gs://bucket/filename.ext",
"boundingBoxAnnotations": [
{
"displayName": "OBJECT1_LABEL",
"xMin": "X_MIN",
"yMin": "Y_MIN",
"xMax": "X_MAX",
"yMax": "Y_MAX",
"annotationResourceLabels": {
"aiplatform.googleapis.com/annotation_set_name": "displayName",
"env": "prod"
}
},
{
"displayName": "OBJECT2_LABEL",
"xMin": "X_MIN",
"yMin": "Y_MIN",
"xMax": "X_MAX",
"yMax": "Y_MAX"
}
],
"dataItemResourceLabels": {
"aiplatform.googleapis.com/ml_use": "test/train/validation"
}
}Catatan kolom:
imageGcsUri- Satu-satunya kolom yang wajib diisi.annotationResourceLabels- Dapat berisi berapa pun pasangan string nilai kunci. Satu-satunya pasangan nilai kunci yang dicadangkan oleh sistem adalah sebagai berikut:- "aiplatform.googleapis.com/annotation_set_name" : "value"
Dengan value adalah salah satu nama tampilan dari kumpulan anotasi yang ada dalam set data.
dataItemResourceLabels- Dapat berisi berapa pun pasangan string nilai kunci. Satu-satunya pasangan nilai kunci yang dicadangkan oleh sistem adalah berikut ini, yang menentukan kumpulan penggunaan machine learning dari item data:- "aiplatform.googleapis.com/ml_use" : "training/test/validation"
Contoh JSON Lines - object_detection.jsonl:
{"imageGcsUri": "gs://bucket/filename1.jpeg", "boundingBoxAnnotations": [{"displayName": "Tomato", "xMin": "0.3", "yMin": "0.3", "xMax": "0.7", "yMax": "0.6"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "test"}}
{"imageGcsUri": "gs://bucket/filename2.gif", "boundingBoxAnnotations": [{"displayName": "Tomato", "xMin": "0.8", "yMin": "0.2", "xMax": "1.0", "yMax": "0.4"},{"displayName": "Salad", "xMin": "0.0", "yMin": "0.0", "xMax": "1.0", "yMax": "1.0"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "training"}}
{"imageGcsUri": "gs://bucket/filename3.png", "boundingBoxAnnotations": [{"displayName": "Baked goods", "xMin": "0.5", "yMin": "0.7", "xMax": "0.8", "yMax": "0.8"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "training"}}
{"imageGcsUri": "gs://bucket/filename4.tiff", "boundingBoxAnnotations": [{"displayName": "Salad", "xMin": "0.1", "yMin": "0.2", "xMax": "0.8", "yMax": "0.9"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "validation"}}
...CSV
Format CSV:
[ML_USE],GCS_FILE_PATH,[LABEL],[BOUNDING_BOX]*
ML_USE(Opsional). Untuk tujuan pemisahan data saat melatih model. Gunakan TRAINING, TEST, atau VALIDATION. Untuk mengetahui informasi selengkapnya tentang pembagian data secara manual, lihat Tentang pemisahan data untuk model AutoML.GCS_FILE_PATH. Kolom ini berisi Cloud Storage URI untuk image. URI Cloud Storage peka huruf besar/kecil.LABEL. Label harus diawali dengan huruf dan hanya berisi huruf, angka, serta garis bawah.BOUNDING_BOX. Kotak pembatas untuk objek dalam gambar. Penentuan kotak pembatas melibatkan lebih dari satu kolom.
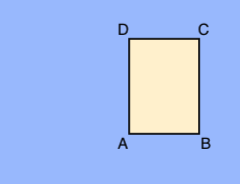
A.X_MIN,Y_MIN
B.X_MAX,Y_MIN
C.X_MAX,Y_MAX
D.X_MIN,Y_MAX
Setiap verteks ditentukan dengan nilai koordinat x, y. Koordinat adalah nilai float yang dinormalisasi [0,1]; 0.0 adalah X_MIN atau Y_MIN, 1.0 adalah X_MAX atau Y_MAX.
Misalnya, kotak pembatas untuk keseluruhan gambar dinyatakan sebagai (0.0,0.0,,,1.0,1.0,), atau (0.0,0.0,1.0,0.0,1.0,1.0,0.0,1.0).
Kotak pembatas untuk objek dapat ditentukan melalui salah satu dari dua cara berikut:
- Dua verteks (dua kumpulan koordinat x,y) yang secara diagonal berlawanan dengan titik
persegi panjang:
A.X_MIN,Y_MIN
C.X_MAX,Y_MAX
seperti yang ditunjukkan dalam contoh ini:
A,,C,
X_MIN,Y_MIN,,,X_MAX,Y_MAX,, - Keempat verteks yang ditentukan seperti yang ditunjukkan dalam:
X_MIN,Y_MIN,X_MAX,Y_MIN, X_MAX,Y_MAX,X_MIN,Y_MAX,
Jika keempat verteks yang ditentukan tidak membentuk persegi panjang yang sejajar dengan tepi gambar, Vertex AI menentukan verteks yang memang membentuk persegi panjang tersebut.
- Dua verteks (dua kumpulan koordinat x,y) yang secara diagonal berlawanan dengan titik
persegi panjang:
Contoh CSV - object_detection.csv:
test,gs://bucket/filename1.jpeg,Tomato,0.3,0.3,,,0.7,0.6,,
training,gs://bucket/filename2.gif,Tomato,0.8,0.2,,,1.0,0.4,,
gs://bucket/filename2.gif
gs://bucket/filename3.png,Baked goods,0.5,0.7,0.8,0.7,0.8,0.8,0.5,0.8
validation,gs://bucket/filename4.tiff,Salad,0.1,0.2,,,0.8,0.9,,
...