Les sections suivantes portent sur ces différents objectifs et contiennent des informations sur les exigences applicables aux données, le fichier de schéma d'entrée/sortie et le format des fichiers d'importation de données (JSON Lines et CSV) définis par le schéma.
Détection d'objets
Exigences en matière de données
| Conditions générales requises pour les images | |
|---|---|
| Types de fichiers compatibles |
|
| Types d'images | Les modèles AutoML sont optimisés pour les photographies d'objets dans le monde réel. |
| Taille du fichier image d'entraînement (Mo) | Taille maximale : 30 Mo |
| Taille du fichier image de prédiction* (Mo) | Taille maximale : 1,5 Mo |
| Taille de l'image (pixels) | Résolution maximale suggérée : 1 024 pixels par 1 024 pixels Les images dont la résolution est largement supérieure à 1 024 pixels par 1 024 pixels peuvent perdre en qualité lors du processus de normalisation des images de Vertex AI. |
| Conditions requises pour les étiquettes et le cadre de délimitation | |
|---|---|
| Les exigences suivantes s'appliquent aux ensembles de données utilisés pour entraîner les modèles AutoML. | |
| Instances d'étiquettes pour l'entraînement | 10 annotations (instances) au minimum |
| Conditions requises pour les annotations | Vous devez au moins disposer de 10 images par étiquette, chacune contenant au minimum une annotation (cadre de délimitation et étiquette). Cependant, il est recommandé d'utiliser environ 1 000 annotations par étiquette pour l'entraînement de modèle. En général, plus le nombre d'images par étiquette est élevé, plus le modèle est performant. |
| Ratio d'étiquettes (étiquette la plus courante par rapport à l'étiquette la plus rare) : | Le modèle fonctionne mieux lorsqu'il existe au maximum 100 fois plus d'images pour l'étiquette la plus courante que pour la plus rare. Pour optimiser les performances du modèle, nous vous recommandons de supprimer les étiquettes les moins fréquentes. |
| Longueur des bords du cadre de délimitation | Au moins 0,01 x longueur d'un côté d'une image. Par exemple, une image de 1 000 x 900 pixels nécessite des cadres de délimitation d'au minimum 10 x 9 pixels. Taille minimale du cadre de délimitation : 8 pixels par 8 pixels. |
| Les exigences suivantes s'appliquent aux ensembles de données utilisés pour entraîner des modèles AutoML ou des modèles personnalisés. | |
| Cadres de délimitation par image | 500 au maximum |
| Cadres de délimitation renvoyés par une requête de prédiction | 100 (par défaut), 500 au maximum |
| Conditions requises pour les données et l'ensemble de données d'entraînement | |
|---|---|
| Les exigences suivantes s'appliquent aux ensembles de données utilisés pour entraîner les modèles AutoML. | |
| Caractéristiques des images d'entraînement | Les données d'entraînement doivent être aussi proches que possible des données sur lesquelles les prédictions sont fondées. Par exemple, si votre cas d'utilisation implique des images floues en basse résolution (comme celles d'une caméra de sécurité), vos données d'entraînement doivent être composées d'images floues à basse résolution. En général, il est recommandé de fournir également différents angles, résolutions et arrière-plans pour vos images d'entraînement. Les modèles Vertex AI ne sont généralement pas capables de prédire les étiquettes qu'un humain ne serait pas en mesure d'attribuer. Ainsi, si un humain ne peut pas apprendre à attribuer des étiquettes en regardant l'image pendant 1 à 2 secondes, le modèle ne pourra probablement pas être entraîné à le faire non plus. |
| Prétraitement interne des images | Une fois les images importées, Vertex AI effectue le prétraitement des données. Les images prétraitées sont les véritables données utilisées pour entraîner le modèle. Le prétraitement (redimensionnement) est appliqué lorsque le plus petit côté de l'image est supérieur à 1024 pixels. Si le plus petit côté de l'image est supérieur à 1024 pixels, ce côté est réduit à 1024 pixels. Le côté le plus grand et les cadres de délimitation sont tous deux réduit du même nombre de pixels que le plus petit côté. Par conséquent, toute annotation réduite (cadres de délimitation et étiquettes) est supprimée si sa taille est inférieure à 8 pixels par 8 pixels. Les images dont le côté le plus petit est inférieur ou égal à 1024 pixels ne sont pas soumises au redimensionnement du prétraitement. |
| Les exigences suivantes s'appliquent aux ensembles de données utilisés pour entraîner des modèles AutoML ou des modèles personnalisés. | |
| Images dans chaque ensemble de données | 150 000 au maximum |
| Nombre total de cadres de délimitation annotés dans chaque ensemble de données | 1 000 000 au maximum |
| Nombre d'étiquettes dans chaque ensemble de données | 2 au minimum, 1 000 au maximum |
Fichier de schéma YAML
Utilisez le fichier de schéma suivant accessible au public pour importer des annotations de détection d'objets au sein d'images (cadres de délimitation et étiquettes). Ce fichier de schéma détermine le format des fichiers de données d'entrée. La structure de ce fichier suit le schéma OpenAPI.
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_bounding_box_io_format_1.0.0.yaml
Fichier de schéma complet
title: ImageBoundingBox description: > Import and export format for importing/exporting images together with bounding box annotations. Can be used in Dataset.import_schema_uri field. type: object required: - imageGcsUri properties: imageGcsUri: type: string description: > A Cloud Storage URI pointing to an image. Up to 30MB in size. Supported file mime types: `image/jpeg`, `image/gif`, `image/png`, `image/webp`, `image/bmp`, `image/tiff`, `image/vnd.microsoft.icon`. boundingBoxAnnotations: type: array description: Multiple bounding box Annotations on the image. items: type: object description: > Bounding box anntoation. `xMin`, `xMax`, `yMin`, and `yMax` are relative to the image size, and the point 0,0 is in the top left of the image. properties: displayName: type: string description: > It will be imported as/exported from AnnotationSpec's display name, i.e. the name of the label/class. xMin: description: The leftmost coordinate of the bounding box. type: number format: double xMax: description: The rightmost coordinate of the bounding box. type: number format: double yMin: description: The topmost coordinate of the bounding box. type: number format: double yMax: description: The bottommost coordinate of the bounding box. type: number format: double annotationResourceLabels: description: Resource labels on the Annotation. type: object additionalProperties: type: string dataItemResourceLabels: description: Resource labels on the DataItem. type: object additionalProperties: type: string
Fichiers d'entrée
JSON Lines
JSON sur chaque ligne :
{
"imageGcsUri": "gs://bucket/filename.ext",
"boundingBoxAnnotations": [
{
"displayName": "OBJECT1_LABEL",
"xMin": "X_MIN",
"yMin": "Y_MIN",
"xMax": "X_MAX",
"yMax": "Y_MAX",
"annotationResourceLabels": {
"aiplatform.googleapis.com/annotation_set_name": "displayName",
"env": "prod"
}
},
{
"displayName": "OBJECT2_LABEL",
"xMin": "X_MIN",
"yMin": "Y_MIN",
"xMax": "X_MAX",
"yMax": "Y_MAX"
}
],
"dataItemResourceLabels": {
"aiplatform.googleapis.com/ml_use": "test/train/validation"
}
}Remarques sur les champs :
imageGcsUri: seul champ obligatoire.annotationResourceLabels: peut contenir un nombre indéfini de paires clé/valeur. La seule paire clé-valeur réservée par le système est la suivante :- "aiplatform.googleapis.com/annotation_set_name" : "value"
où value est l'un des noms à afficher des ensembles d'annotations existants dans l'ensemble de données.
dataItemResourceLabels: peut contenir un nombre indéfini de paires clé/valeur. La seule paire clé-valeur réservée par le système est la suivante, qui spécifie l'ensemble d'utilisation de machine learning de l'élément de données :- "aiplatform.googleapis.com/ml_use" : "training/test/validation"
Exemple JSON Lines – object_detection.jsonl :
{"imageGcsUri": "gs://bucket/filename1.jpeg", "boundingBoxAnnotations": [{"displayName": "Tomato", "xMin": "0.3", "yMin": "0.3", "xMax": "0.7", "yMax": "0.6"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "test"}}
{"imageGcsUri": "gs://bucket/filename2.gif", "boundingBoxAnnotations": [{"displayName": "Tomato", "xMin": "0.8", "yMin": "0.2", "xMax": "1.0", "yMax": "0.4"},{"displayName": "Salad", "xMin": "0.0", "yMin": "0.0", "xMax": "1.0", "yMax": "1.0"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "training"}}
{"imageGcsUri": "gs://bucket/filename3.png", "boundingBoxAnnotations": [{"displayName": "Baked goods", "xMin": "0.5", "yMin": "0.7", "xMax": "0.8", "yMax": "0.8"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "training"}}
{"imageGcsUri": "gs://bucket/filename4.tiff", "boundingBoxAnnotations": [{"displayName": "Salad", "xMin": "0.1", "yMin": "0.2", "xMax": "0.8", "yMax": "0.9"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "validation"}}
...CSV
Format CSV :
[ML_USE],GCS_FILE_PATH,[LABEL],[BOUNDING_BOX]*
ML_USE(Facultatif). Pour la répartition des données lors de l'entraînement d'un modèle. Utilisez TRAINING (entraînement), TEST ou VALIDATION. Pour en savoir plus sur la répartition manuelle des données, consultez la page À propos de la répartition des données pour les modèles AutoML.GCS_FILE_PATH. Ce champ contient l'URI Cloud Storage de l'image. Les URI Cloud Storage sont sensibles à la casse.LABEL. Les libellés doivent commencer par une lettre et ne contenir que des lettres, des chiffres et des traits de soulignement.BOUNDING_BOX. Cadre de délimitation pour un objet dans l'image. Plusieurs colonnes sont nécessaires pour spécifier un cadre de délimitation.
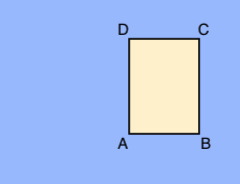
A.X_MIN,Y_MIN
B.X_MAX,Y_MIN
C.X_MAX,Y_MAX
D.X_MIN,Y_MAX
Chaque sommet est spécifié par des valeurs de coordonnées x et y. Les coordonnées sont des valeurs flottantes normalisées au format [0,1]. 0.0 correspond à X_MIN ou Y_MIN et 1.0 correspond à X_MAX ou Y_MAX.
Par exemple, un cadre de délimitation pour l'intégralité d'une image s'exprime sous la forme (0.0,0.0,,,1.0,1.0,,) ou (0.0,0.0,1.0,0.0,1.0,1.0,0.0,1.0).
Le cadre de délimitation d'un objet peut être spécifié de deux manières :
- Deux sommets (deux ensembles de coordonnées x et y) qui sont des points diagonalement opposés
du rectangle :
A.X_MIN,Y_MIN
C.X_MAX,Y_MAX
comme indiqué dans cet exemple :
A,,C,
X_MIN,Y_MIN,,,X_MAX,Y_MAX,, - Les quatre sommets spécifiés comme illustré dans :
X_MIN,Y_MIN,X_MAX,Y_MIN, X_MAX,Y_MAX,X_MIN,Y_MAX,
Si les quatre sommets spécifiés ne forment pas un rectangle parallèle aux bords de l'image, Vertex AI spécifie des sommets qui forment un tel rectangle.
- Deux sommets (deux ensembles de coordonnées x et y) qui sont des points diagonalement opposés
du rectangle :
Exemple de fichier CSV - object_detection.csv :
test,gs://bucket/filename1.jpeg,Tomato,0.3,0.3,,,0.7,0.6,,
training,gs://bucket/filename2.gif,Tomato,0.8,0.2,,,1.0,0.4,,
gs://bucket/filename2.gif
gs://bucket/filename3.png,Baked goods,0.5,0.7,0.8,0.7,0.8,0.8,0.5,0.8
validation,gs://bucket/filename4.tiff,Salad,0.1,0.2,,,0.8,0.9,,
...