Vertex AI는 정밀도와 재현율 측정항목과 같은 모델의 성능을 결정하는 데 도움이 되는 모델 평가 측정항목을 제공합니다. Vertex AI는 테스트 세트를 사용하여 평가 측정항목을 계산합니다.
모델 평가 측정항목 사용 방법
모델 평가 측정항목은 테스트 세트에서 모델의 성능을 정량적으로 측정합니다. 이러한 측정항목을 해석하고 사용하는 방법은 비즈니스 니즈와 모델이 해결하도록 학습한 문제에 따라 달라집니다. 예를 들어 거짓음성보다 거짓양성의 톨러레이션(toleration)이 더 낮을 수도 있고 그 반대일 수도 있습니다. 이러한 유형의 질문은 집중해야 할 측정항목에 영향을 줍니다.
모델의 반복을 통해 성능을 개선하는 방법에 대한 자세한 내용은 모델의 반복을 참조하세요.
Vertex AI에서 반환하는 평가 측정항목
Vertex AI는 정밀도, 재현율, 신뢰도 기준점과 같은 여러 가지 평가 측정항목을 반환합니다. Vertex AI가 반환하는 측정항목은 모델의 목표에 따라 다릅니다. 예를 들어 Vertex AI는 이미지 객체 분류 모델과 비교해서 이미지 객체 감지 모델에 대한 다양한 평가 측정항목을 제공합니다.
Cloud Storage 위치에서 다운로드 가능한 스키마 파일은 Vertex AI가 각 목표에 제공하는 평가 측정항목을 결정합니다. 다음 탭에서는 스키마 파일의 링크를 제공하고 각 모델 목표에 대한 평가 측정항목을 설명합니다.
다음 Cloud Storage 위치에서 스키마 파일을 보고 다운로드할 수 있습니다.
gs://google-cloud-aiplatform/schema/modelevaluation/
- IoU 기준점: 반환할 추론을 결정하는 Intersection over union 기준점입니다. 모델이 이 값 이상인 추론을 반환합니다. 기준점이 높을수록 예측된 경계 상자 값이 실제 경계 상자 값에 더 근접해야 합니다.
- 평균 정밀도의 평균: 평균 정밀도라고도 합니다. 이 값의 범위는 0부터 1까지이며 값이 클수록 모델의 품질이 높습니다.
- 신뢰도 기준점: 반환할 추론을 결정하는 신뢰도 점수입니다. 모델이 이 값 이상인 추론을 반환합니다. 신뢰도 기준점이 높을수록 정밀도는 높아지지만 재현율이 낮아집니다. Vertex AI는 다양한 기준점으로 신뢰도 측정항목을 반환하여 기준점이 정밀도와 재현율에 미치는 영향을 보여줍니다.
- 재현율: 모델이 올바르게 예측한 이 클래스의 추론 비율입니다. 참양성률이라고도 합니다.
- 정밀도: 모델이 생성한 올바른 분류 추론의 비율입니다.
- F1 점수: 정밀도와 재현율의 조화 평균입니다. F1은 정밀도와 재현율 사이의 균형을 찾고 있고 클래스 분포가 균등하지 않을 때 유용한 측정항목입니다.
-
경계 상자 평균 정밀도의 평균: 경계 상자 평가의 단일 측정항목:
meanAveragePrecision은 모든boundingBoxMetrics에 대한 평균입니다.
평가 측정항목 가져오기
모델의 평가 측정항목 집계 집합과 일부 목표의 경우 특정 클래스 또는 라벨의 평가 측정항목을 가져올 수 있습니다. 특정 클래스 또는 라벨의 평가 측정항목을 평가 슬라이스라고도 합니다. 다음 콘텐츠에서는 Google Cloud 콘솔이나 API를 사용하여 집계 평가 측정항목과 평가 슬라이스를 가져오는 방법을 설명합니다.
Google Cloud 콘솔
Google Cloud 콘솔의 Vertex AI 섹션에서 모델 페이지로 이동합니다.
리전 드롭다운에서 모델이 있는 리전을 선택합니다.
모델 목록에서 모델을 클릭하여 모델의 평가 탭을 엽니다.
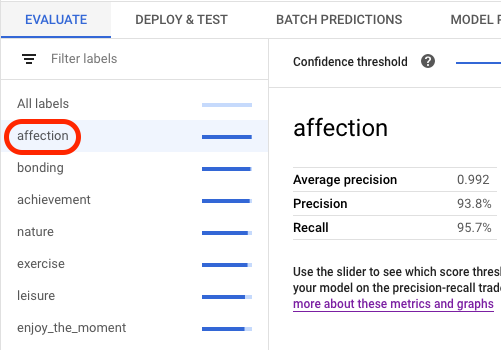
평가 탭에서 평균 정밀도 및 재현율과 같은 모델의 집계 평가 측정항목을 볼 수 있습니다.
모델 목표에 평가 슬라이스가 있으면 콘솔에 라벨 목록이 표시됩니다. 다음 예시와 같이 라벨을 클릭하여 해당 라벨의 평가 측정항목을 볼 수 있습니다.
API
평가 측정항목을 가져오기 위한 API 요청은 각 데이터 유형 및 목표마다 동일하지만 출력은 서로 다릅니다. 다음 샘플은 동일한 요청을 표시하지만 응답은 다릅니다.
집계 모델 평가 측정항목 가져오기
집계 모델 평가 측정항목은 모델 전체에 대한 정보를 제공합니다. 특정 슬라이스에 대한 정보를 보려면 모델 평가 슬라이스를 나열합니다.
집계 모델 평가 측정항목을 보려면 projects.locations.models.evaluations.get 메서드를 사용합니다.
경계 상자 측정항목의 경우 Vertex AI는 서로 다른 IoU 기준점(0~1)과 신뢰도 기준점(0~1)의 측정항목 값 배열을 반환합니다. 예를 들어 IoU 기준점 0.85 및 신뢰도 기준점 0.8228의 평가 측정항목 범위를 좁힐 수 있습니다. 이렇게 다른 기준점을 보면 해당 값이 정밀도와 재현율과 같은 다른 측정항목에 미치는 영향을 확인할 수 있습니다.
언어 또는 환경에 대한 탭을 선택합니다.
REST
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- LOCATION: 모델이 저장된 리전
- PROJECT: 프로젝트 ID
- MODEL_ID: 모델 리소스의 ID
- PROJECT_NUMBER: 프로젝트의 자동으로 생성된 프로젝트 번호
- EVALUATION_ID: 모델 평가의 ID(응답에 표시됨)
HTTP 메서드 및 URL:
GET https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations
요청을 보내려면 다음 옵션 중 하나를 선택합니다.
curl
다음 명령어를 실행합니다.
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations"
PowerShell
다음 명령어를 실행합니다.
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations" | Select-Object -Expand Content
다음과 비슷한 JSON 응답이 표시됩니다.
Java
이 샘플을 사용해 보기 전에 Vertex AI 빠른 시작: 클라이언트 라이브러리 사용의 Java 설정 안내를 따르세요. 자세한 내용은 Vertex AI Java API 참고 문서를 참조하세요.
Vertex AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Node.js
이 샘플을 사용해 보기 전에 Vertex AI 빠른 시작: 클라이언트 라이브러리 사용의 Node.js 설정 안내를 따르세요. 자세한 내용은 Vertex AI Node.js API 참고 문서를 참조하세요.
Vertex AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Python
Vertex AI SDK for Python을 설치하거나 업데이트하는 방법은 Vertex AI SDK for Python 설치를 참조하세요. 자세한 내용은 Python API 참고 문서를 참조하세요.
모든 평가 슬라이스 나열
projects.locations.models.evaluations.slices.list 메서드는 모델의 모든 평가 슬라이스를 나열합니다. 집계 평가 측정항목을 확인할 때 가져올 수 있는 모델의 평가 ID가 있어야 합니다.
모델 평가 슬라이스를 사용하여 특정 라벨에서 모델의 성능을 확인할 수 있습니다. value 필드는 측정항목의 라벨을 나타냅니다.
경계 상자 측정항목의 경우 Vertex AI는 서로 다른 IoU 기준점(0~1)과 신뢰도 기준점(0~1)의 측정항목 값 배열을 반환합니다. 예를 들어 IoU 기준점 0.85 및 신뢰도 기준점 0.8228의 평가 측정항목 범위를 좁힐 수 있습니다. 이렇게 다른 기준점을 보면 해당 값이 정밀도와 재현율과 같은 다른 측정항목에 미치는 영향을 확인할 수 있습니다.
REST
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- LOCATION: 모델이 있는 리전. 예를 들면
us-central1입니다. - PROJECT: .
- MODEL_ID: 모델의 ID
- EVALUATION_ID: 나열할 평가 슬라이스가 포함된 모델 평가의 ID
HTTP 메서드 및 URL:
GET https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices
요청을 보내려면 다음 옵션 중 하나를 선택합니다.
curl
다음 명령어를 실행합니다.
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices"
PowerShell
다음 명령어를 실행합니다.
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices" | Select-Object -Expand Content
다음과 비슷한 JSON 응답이 표시됩니다.
Java
이 샘플을 사용해 보기 전에 Vertex AI 빠른 시작: 클라이언트 라이브러리 사용의 Java 설정 안내를 따르세요. 자세한 내용은 Vertex AI Java API 참고 문서를 참조하세요.
Vertex AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Node.js
이 샘플을 사용해 보기 전에 Vertex AI 빠른 시작: 클라이언트 라이브러리 사용의 Node.js 설정 안내를 따르세요. 자세한 내용은 Vertex AI Node.js API 참고 문서를 참조하세요.
Vertex AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Python
Vertex AI SDK for Python을 설치하거나 업데이트하는 방법은 Vertex AI SDK for Python 설치를 참조하세요. 자세한 내용은 Python API 참고 문서를 참조하세요.
단일 슬라이스의 측정항목 가져오기
단일 슬라이스의 평가 측정항목을 보려면 projects.locations.models.evaluations.slices.get 메서드를 사용합니다. 모든 슬라이스를 나열할 때 제공되는 슬라이스 ID가 있어야 합니다. 다음 샘플은 모든 데이터 유형 및 목표에 적용됩니다.
REST
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- LOCATION: 모델이 있는 리전. 예를 들면 us-central1입니다.
- PROJECT: .
- MODEL_ID: 모델의 ID
- EVALUATION_ID: 검색할 평가 슬라이스가 포함된 모델 평가의 ID
- SLICE_ID: 가져올 평가 슬라이스의 ID
- PROJECT_NUMBER: 프로젝트의 자동으로 생성된 프로젝트 번호
- EVALUATION_METRIC_SCHEMA_FILE_NAME:
classification_metrics_1.0.0과 같이 반환할 평가 측정항목을 정의하는 스키마 파일의 이름
HTTP 메서드 및 URL:
GET https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices/SLICE_ID
요청을 보내려면 다음 옵션 중 하나를 선택합니다.
curl
다음 명령어를 실행합니다.
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices/SLICE_ID"
PowerShell
다음 명령어를 실행합니다.
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices/SLICE_ID" | Select-Object -Expand Content
다음과 비슷한 JSON 응답이 표시됩니다.
Java
이 샘플을 사용해 보기 전에 Vertex AI 빠른 시작: 클라이언트 라이브러리 사용의 Java 설정 안내를 따르세요. 자세한 내용은 Vertex AI Java API 참고 문서를 참조하세요.
Vertex AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Node.js
이 샘플을 사용해 보기 전에 Vertex AI 빠른 시작: 클라이언트 라이브러리 사용의 Node.js 설정 안내를 따르세요. 자세한 내용은 Vertex AI Node.js API 참고 문서를 참조하세요.
Vertex AI에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Python
Vertex AI SDK for Python을 설치하거나 업데이트하는 방법은 Vertex AI SDK for Python 설치를 참조하세요. 자세한 내용은 Python API 참고 문서를 참조하세요.
모델 반복 학습
모델 평가 측정항목은 모델이 기대에 미치지 못하는 경우 모델을 디버깅하기 위한 시작점을 제공합니다. 예를 들어 정밀도/재현율 점수가 낮다면 모델에 학습 데이터가 더 많이 필요하거나 라벨이 일관되지 않은 경우일 수 있습니다. 정밀도와 재현율이 완벽하다면 테스트 데이터가 너무 쉬워서 예측할 수 없고 일반화가 잘 되지 않는 경우일 수 있습니다.
학습 데이터를 반복하고 새 모델을 만들 수 있습니다. 새 모델을 만든 후에는 기존 모델과 새 모델 간에 평가 측정항목을 비교할 수 있습니다.
다음 권장사항은 객체 감지 또는 감지 모델과 같은 항목에 라벨을 지정하는 모델을 개선하는 데 도움이 됩니다.
- 학습 데이터에 예시를 추가하거나 더욱 광범위한 예시를 추가해 보세요. 예를 들어 이미지 객체 감지 모델의 경우 더 넓은 각도 이미지, 고해상도 또는 저해상도 이미지 또는 다른 시점을 포함할 수 있습니다. 자세한 안내는 데이터 준비를 참조하세요.
- 예시가 많지 않은 클래스나 라벨은 삭제하는 것이 좋습니다. 예시가 충분하지 않으면 모델이 이러한 클래스 또는 라벨에 대해 일관되고 확실하게 예측할 수 없습니다.
- 머신은 클래스 또는 라벨의 이름을 해석할 수 없으며 예를 들어 'door' 및 'door_with_knob' 사이의 미묘한 차이를 이해하지 못합니다. 머신이 이러한 미묘한 차이를 인식할 수 있도록 데이터를 제공해야 합니다.
- 참양성, 참음성의 예시를 더 많이 추가하여 데이터를 보강합니다. 특히 모델 혼동 완화를 위해 결정 경계에 가까운 예시를 추가합니다.
- 자체 데이터 분할(학습, 검증, 테스트)을 지정하세요. Vertex AI는 항목을 각 세트에 무작위로 할당합니다. 따라서 학습 및 검증 세트에 거의 비슷한 항목을 할당하게 되면 과적합이 발생하여 테스트 세트의 성능이 저하될 수 있습니다. 자체 데이터 분할을 설정하는 방법에 대한 자세한 내용은 AutoML 모델의 데이터 분할 정보를 참조하세요.
- 모델의 평가 측정항목에 혼동 행렬이 포함된 경우 모델이 두 라벨을 혼동하는지 여부를 확인할 수 있습니다. 여기서 모델이 실제 라벨보다 특정 라벨을 훨씬 더 많이 예측합니다. 데이터를 검토하고 예시에서 라벨이 올바르게 지정되어 있는지 확인합니다.
- 학습 시간이 짧았다면(낮은 최대 노드 시간 수) 더 긴 시간(높은 최대 노드 시간 수) 동안 학습하도록 허용하여 고품질 모델을 얻을 수 있습니다.